翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
ヘルスモニタリングシステム
SageMaker HyperPod ヘルスモニタリングシステムには 2 つのコンポーネントが含まれています
-
ノードにインストールされているエージェントのモニタリング。これには、オンホストヘルスモニターとして機能する Health Monitoring Agent (HMA) とout-of-node一連のヘルスモニターが含まれます。
-
SageMaker HyperPod によって管理されるノード復旧システム。ヘルスモニタリングシステムは、モニタリングエージェントを介してノードのヘルスステータスを継続的にモニタリングし、Node Recovery System を使用して障害が検出されると自動的にアクションを実行します。

SageMaker HyperPod ヘルスモニタリングエージェントが行うヘルスチェック
SageMaker HyperPod ヘルスモニタリングエージェントは以下をチェックします。
NVIDIA GPU
-
nvidia-smi出力のエラー -
Amazon Elastic Compute Cloud (EC2) プラットフォームによって生成されたログのさまざまなエラー
-
GPU カウントの検証 — 特定のインスタンスタイプ (例: ml.p5.48xlarge インスタンスタイプの 8 GPUs) で予想される GPUs 数と によって返される数が一致しない場合
nvidia-smi、HMA はノードを再起動します。
AWSTrainium
-
AWS Neuron モニター
からの出力のエラー -
Neuron ノード問題ディテクターによって生成された出力 (AWSNeuron ノード問題ディテクターの詳細については、「Amazon EKS クラスター内の AWSNeuron ノードのノード問題の検出と復旧
」を参照してください)。 -
Amazon EC2 プラットフォームによって生成されたログのさまざまなエラー
-
Neuron Device Count validation — 特定のインスタンスタイプの実際のニューロンデバイス数と によって返される数が一致しない場合
neuron-ls、HMA はノードを再起動します。
上記のチェックはパッシブなバックグラウンドヘルスチェックであり、HyperPod はノードで継続的に実行されます。これらのチェックに加えて、HyperPod は HyperPod クラスターの作成および更新中にディープ (またはアクティブ) HyperPod ヘルスチェックも実行します。Deep ヘルスチェックの詳細をご覧ください。
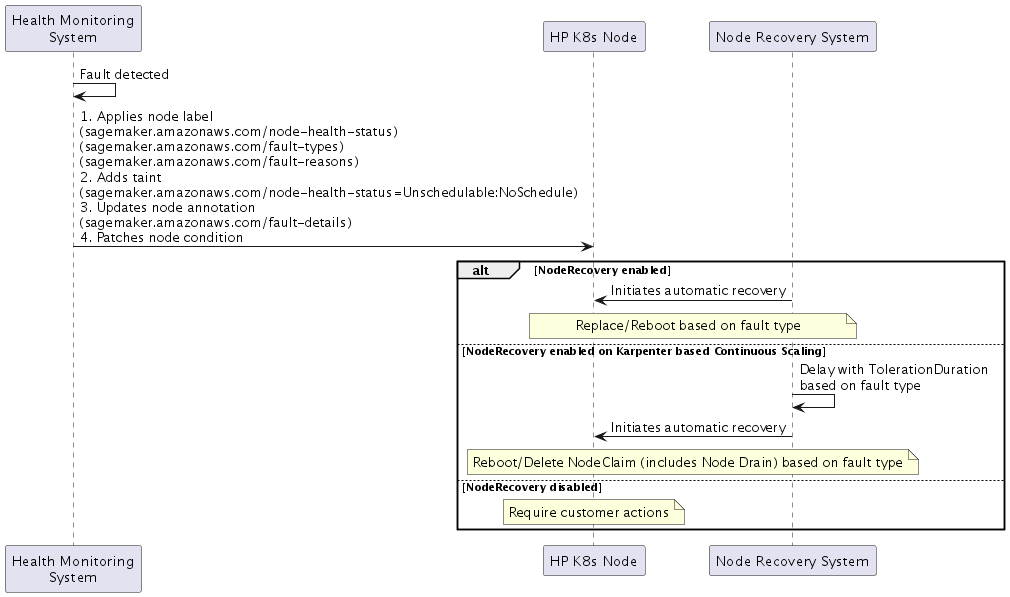
障害検出
SageMaker HyperPod が障害を検出すると、次の 4 つの部分からなるレスポンスが実装されます。
-
ノードラベル
-
ヘルスステータス:
sagemaker.amazonaws.com/node-health-status -
障害タイプ: 高レベル分類の
sagemaker.amazonaws.com/fault-typesラベル -
障害の理由: 詳細な障害情報の
sagemaker.amazonaws.com/fault-reasonsラベル
-
-
ノードテイント
-
sagemaker.amazonaws.com/node-health-status=Unschedulable:NoSchedule
-
-
ノード注釈
-
障害の詳細:
sagemaker.amazonaws.com/fault-details -
ノードで発生したタイムスタンプで最大 20 個の障害を記録します
-
-
ノード条件 (Kubernetes ノード条件
) -
現在のヘルスステータスをノード条件に反映します。
-
タイプ: 障害タイプと同じ
-
ステータス:
True -
理由: 障害の理由と同じ
-
LastTransitionTime: 障害発生時刻
-
-
SageMaker HyperPod ヘルスモニタリングエージェントによって生成されたログ
SageMaker HyperPod ヘルスモニタリングエージェントは、すぐに使用可能なヘルスチェック機能であり、すべての HyperPod クラスターで継続的に実行されます。ヘルスモニタリングエージェントは、検出されたヘルスイベントを GPU または Trn インスタンスでクラスターロググループ /aws/sagemaker/Clusters/ の CloudWatch に発行します。
HyperPod ヘルスモニタリングエージェントの検出ログは、ノードごとに SagemakerHealthMonitoringAgent という名前の別個のログストリームとして作成されます。CloudWatch ログインサイトを使用して、次のように検出ログをクエリできます。
fields @timestamp, @message | filter @message like /HealthMonitoringAgentDetectionEvent/
これにより、次のような出力が返されます。
2024-08-21T11:35:35.532-07:00 {"level":"info","ts":"2024-08-21T18:35:35Z","msg":"NPD caught event: %v","details: ":{"severity":"warn","timestamp":"2024-08-22T20:59:29Z","reason":"XidHardwareFailure","message":"Node condition NvidiaErrorReboot is now: True, reason: XidHardwareFailure, message: \"NVRM: Xid (PCI:0000:b9:00): 71, pid=<unknown>, name=<unknown>, NVLink: fatal error detected on link 6(0x10000, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0)\""},"HealthMonitoringAgentDetectionEvent":"HealthEvent"} 2024-08-21T11:35:35.532-07:00 {"level":"info","ts":"2024-08-21T18:35:35Z","msg":"NPD caught event: %v","details: ":{"severity":"warn","timestamp":"2024-08-22T20:59:29Z","reason":"XidHardwareFailure","message":"Node condition NvidiaErrorReboot is now: True, reason: XidHardwareFailure, message: \"NVRM: Xid (PCI:0000:b9:00): 71, pid=<unknown>, name=<unknown>, NVLink: fatal error detected on link 6(0x10000, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0)\""},"HealthMonitoringAgentDetectionEvent":"HealthEvent"}
