翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
Amazon SageMaker HyperPod での Elastic Training の使用
Elastic Training は、コンピューティングリソースの可用性とワークロードの優先度に基づいてトレーニングジョブを自動的にスケーリングする新しい Amazon SageMaker HyperPod 機能です。Elastic Training ジョブは、モデルトレーニングに必要な最小限のコンピューティングリソースから開始し、さまざまなノード設定 (ワールドサイズ) にわたる自動チェックポイントと再開を通じて動的にスケールアップまたはスケールダウンできます。スケーリングは、データ並列レプリカの数を自動的に調整することで実現されます。クラスター使用率が高い期間中、優先度の高いジョブからのリソースリクエストに応じて Elastic Training ジョブを自動的にスケールダウンするように設定して、重要なワークロードのコンピューティングを解放できます。オフピーク期間中にリソースが解放されると、Elastic Training Jobs は自動的にスケールアップしてトレーニングを高速化し、優先度の高いワークロードがリソースを再度必要とするときにスケールダウンします。
Elastic Training は HyperPod トレーニングオペレーター上に構築され、次のコンポーネントを統合します。
-
ジョブキューイング、優先順位付け、スケジューリングのための Amazon SageMaker HyperPod タスクガバナンス
-
DCP などのスケーラブルな状態とチェックポイント管理のための PyTorch Distributed Checkpoint (DCP)
サポートされているフレームワーク
-
PyTorch with Distributed Data Parallel (DDP) と Fully Sharded Data Parallel (FSDP)
-
PyTorch 分散チェックポイント (DCP)
前提条件
SageMaker HyperPod EKS クラスター
Amazon EKS オーケストレーションで実行中の SageMaker HyperPod クラスターが必要です。HyperPod EKS クラスターの作成については、以下を参照してください。
SageMaker HyperPod トレーニングオペレーター
Elastic Training は、トレーニングオペレーター v. 1.2 以降でサポートされています。
トレーニングオペレーターを EKS アドオンとしてインストールするには、https://docs.aws.amazon.com/sagemaker/latest/dg/sagemaker-eks-operator-install.html を参照してください。
(推奨) Task Governance と Kueue をインストールして設定する
HyperPod タスクガバナンスを介して Kueue をインストールして設定し、伸縮自在なトレーニングでワークロードの優先順位を指定することをお勧めします。Kueue は、キューイング、優先順位付け、ギャングスケジューリング、リソース追跡、およびマルチテナントトレーニング環境での運用に不可欠な適切なプリエンプションにより、より強力なワークロード管理を提供します。
-
ギャングスケジューリングにより、トレーニングジョブに必要なすべてのポッドが一緒に開始されます。これにより、一部のポッドが開始し、他のポッドが保留中のままになる状況が防止され、リソースが無駄になる可能性があります。
-
穏やかなプリエンプションにより、優先度の低いエラスティックジョブは優先度の高いワークロードにリソースを生成できます。Elastic ジョブは強制的に削除されることなく適切にスケールダウンできるため、クラスター全体の安定性が向上します。
次の Kueue コンポーネントを設定することをお勧めします。
-
相対的なジョブ重要度を定義する PriorityClasses
-
チームまたはワークロード間でグローバルリソース共有とクォータを管理する ClusterQueues
-
個々の名前空間から適切な ClusterQueue にジョブをルーティングする LocalQueues
より高度なセットアップのために、以下を組み込むこともできます。
-
複数のチーム間でリソース使用量のバランスを取るための公平配分ポリシー
-
組織の SLAs またはコストコントロールを適用するためのカスタムプリエンプションルール
以下を参照してください。
(推奨) ユーザー名前空間とリソースクォータを設定する
Amazon EKS にこの機能をデプロイする場合は、一連の基本的なクラスターレベルの設定を適用して、チーム間の分離、リソースの公平性、運用の一貫性を確保することをお勧めします。
名前空間とアクセス設定
チームまたはプロジェクトごとに個別の名前空間を使用してワークロードを整理します。これにより、きめ細かな分離とガバナンスを適用できます。また、個々の AWS IAM ユーザーまたはロールを対応する名前空間に関連付けるように IAM から Kubernetes RBAC へのマッピングを設定することをお勧めします。
主なプラクティスは次のとおりです。
-
ワークロードにアクセス許可が必要な場合は AWS 、サービスアカウントの IAM ロール (IRSA) を使用して IAM ロールを Kubernetes サービスアカウントにマッピングします。https://docs.aws.amazon.com/eks/latest/userguide/access-entries.html
-
RBAC ポリシーを適用して、ユーザーを指定された名前空間 (クラスター全体のアクセス許可ではなく
Role/RoleBindingなど) のみに制限します。
リソースとコンピューティングの制限
リソースの競合を防ぎ、チーム間で公平なスケジューリングを行うには、名前空間レベルでクォータと制限を適用します。
-
集計 CPU、メモリ、ストレージ、オブジェクト数 (ポッド、PVCs、サービスなど) を制限する ResourceQuotas。
-
LimitRanges は、ポッドごと、またはコンテナごとの CPU とメモリの制限をデフォルトと最大に強制します。
-
PodDisruptionBudgets (PDBs) 必要に応じて障害耐性の期待値を定義します。
-
オプション: ユーザーがジョブを過剰に送信できないようにするための名前空間レベルのキューイング制約 (Task Governance や Kueue 経由など)。
これらの制約は、クラスターの安定性を維持し、分散トレーニングワークロードの予測可能なスケジューリングをサポートするのに役立ちます。
Auto-scaling
EKS 上の SageMaker HyperPod は、Karpenter によるクラスターの自動スケーリングをサポートしています。Karpenter または同様のリソースプロビジョナーを伸縮自在なトレーニングと一緒に使用すると、伸縮自在なトレーニングジョブが送信されると、クラスターと伸縮自在なトレーニングジョブが自動的にスケールアップすることがあります。これは、伸縮自在なトレーニングオペレーターが貪欲なアプローチを取るため、 は、ジョブによって設定された最大制限に達するまで、常に利用可能なコンピューティングリソースよりも多くを尋ねます。これは、伸縮自在なトレーニングオペレーターが伸縮自在なジョブ実行の一部として追加のリソースを継続的にリクエストするためです。これにより、ノードのプロビジョニングがトリガーされる可能性があります。Karpenter などの継続的なリソースプロビジョナーは、コンピューティングクラスターをスケールアップしてリクエストを処理します。
これらのスケールアップを予測可能にし、制御できるようにするには、Elastic Training Jobs が作成される名前空間に名前空間レベルの ResourceQuotas を設定することをお勧めします。ResourceQuotas は、ジョブがリクエストできる最大リソースを制限し、定義された制限内で伸縮自在な動作を許可しながら、無制限のクラスターの増加を防ぐのに役立ちます。
たとえば、8 ml.p5.48xlarge インスタンスの ResourceQuota は、次の形式になります。
apiVersion: v1 kind: ResourceQuota metadata: name: <quota-name> namespace: <namespace-name> spec: hard: nvidia.com/gpu: "64" vpc.amazonaws.com/efa: "256" requests.cpu: "1536" requests.memory: "5120Gi" limits.cpu: "1536" limits.memory: "5120Gi"
トレーニングコンテナを構築する
HyperPod トレーニングオペレーターは、HyperPod Elastic Agent Python パッケージ (https://www.piwheels.org/project/hyperpod-elastic-agent/torchrun コマンドを に置き換えhyperpodrunてトレーニングを起動する必要があります。詳細については、以下を参照してください。
トレーニングコンテナの例:
FROM ... ... RUN pip install hyperpod-elastic-agent ENTRYPOINT ["entrypoint.sh"] # entrypoint.sh ... hyperpodrun --nnodes=node_count --nproc-per-node=proc_count \ --rdzv-backend hyperpod \ # Optional ... # Other torchrun args # pre-traing arg_group --pre-train-script pre.sh --pre-train-args "pre_1 pre_2 pre_3" \ # post-train arg_group --post-train-script post.sh --post-train-args "post_1 post_2 post_3" \ training.py --script-args
トレーニングコードの変更
SageMaker HyperPod には、Elastic Policy で実行するように設定されている一連のレシピが用意されています。
カスタム PyTorch トレーニングスクリプトの Elastic Training を有効にするには、トレーニングループに軽微な変更を加える必要があります。このガイドでは、コンピューティングリソースの可用性が変化したときに発生する Elastic Scaling イベントにトレーニングジョブが応答するために必要な変更について説明します。すべての Elastic イベント (ノードが利用可能である、またはノードが優先されるなど) 中に、トレーニングジョブは、チェックポイントを保存して正常なシャットダウンを調整するために使用される Elastic イベントシグナルを受信し、その保存されたチェックポイントから新しいワールド設定で再開してトレーニングを再開します。カスタムトレーニングスクリプトで Elastic Training を有効にするには、以下を実行する必要があります。
Elastic Scaling イベントを検出する
トレーニングループで、各イテレーション中に Elastic イベントを確認します。
from hyperpod_elastic_agent.elastic_event_handler import elastic_event_detected def train_epoch(model, dataloader, optimizer, args): for batch_idx, batch_data in enumerate(dataloader): # Forward and backward pass loss = model(batch_data).loss loss.backward() optimizer.step() optimizer.zero_grad() # Handle checkpointing and elastic scaling should_checkpoint = (batch_idx + 1) % args.checkpoint_freq == 0 elastic_event = elastic_event_detected() # Save checkpoint if scaling-up or scaling down job if should_checkpoint or elastic_event: save_checkpoint(model, optimizer, scheduler, checkpoint_dir=args.checkpoint_dir, step=global_step) if elastic_event: print("Elastic scaling event detected. Checkpoint saved.") return
チェックポイントの保存とチェックポイントのロードの実装
注: DCP はワールドサイズが異なるチェックポイントからの再開をサポートしているため、モデルとオプティマイザの状態を保存するために PyTorch Distributed Checkpoint (DCP) を使用することをお勧めします。他のチェックポイント形式は、異なるワールドサイズでのチェックポイントロードをサポートしていない場合があります。その場合、動的なワールドサイズ変更を処理するカスタムロジックを実装する必要があります。
import torch.distributed.checkpoint as dcp from torch.distributed.checkpoint.state_dict import get_state_dict, set_state_dict def save_checkpoint(model, optimizer, lr_scheduler, user_content, checkpoint_path): """Save checkpoint using DCP for elastic training.""" state_dict = { "model": model, "optimizer": optimizer, "lr_scheduler": lr_scheduler, **user_content } dcp.save( state_dict=state_dict, storage_writer=dcp.FileSystemWriter(checkpoint_path) ) def load_checkpoint(model, optimizer, lr_scheduler, checkpoint_path): """Load checkpoint using DCP with automatic resharding.""" state_dict = { "model": model, "optimizer": optimizer, "lr_scheduler": lr_scheduler } dcp.load( state_dict=state_dict, storage_reader=dcp.FileSystemReader(checkpoint_path) ) return model, optimizer, lr_scheduler
(オプション) ステートフルデータローダーを使用する
単一エポック (つまり、データセット全体を 1 回通過する) に対してのみトレーニングを行う場合、モデルは各データサンプルを 1 回だけ確認する必要があります。トレーニングジョブがエポックの途中で停止し、別のワールドサイズで再開された場合、データローダーの状態が保持されていない場合、以前に処理されたデータサンプルが繰り返されます。ステートフルデータローダーは、データローダーの位置を保存して復元することでこれを防ぎ、再開された実行がサンプルを再処理することなく Elastic Scaling イベントから継続されるようにします。StatefulDataLoaderstate_dict()メソッドと torch.utils.data.DataLoader load_state_dict()メソッドを追加する のドロップインリプレースメントであり、データロードプロセスの中間エポックチェックポイントを有効にします。
Elastic トレーニングジョブの送信
HyperPod トレーニングオペレーターは、新しいリソースタイプ - を定義しますhyperpodpytorchjob。Elastic Training はこのリソースタイプを拡張し、以下の強調表示されたフィールドを追加します。
apiVersion: sagemaker.amazonaws.com/v1 kind: HyperPodPyTorchJob metadata: name: elastic-training-job spec: elasticPolicy: minReplicas: 1 maxReplicas: 4 # Increment amount of pods in fixed-size groups # Amount of pods will be equal to minReplicas + N * replicaIncrementStep replicaIncrementStep: 1 # ... or Provide an exact amount of pods that required for training replicaDiscreteValues: [2,4,8] # How long traing operator wait job to save checkpoint and exit during # scaling events. Job will be force-stopped after this period of time gracefulShutdownTimeoutInSeconds: 600 # When scaling event is detected: # how long job controller waits before initiate scale-up. # Some delay can prevent from frequent scale-ups and scale-downs scalingTimeoutInSeconds: 60 # In case of faults, specify how long elastic training should wait for # recovery, before triggering a scale-down faultyScaleDownTimeoutInSeconds: 30 ... replicaSpecs: - name: pods replicas: 4 # Initial replica count maxReplicas: 8 # Max for this replica spec (should match elasticPolicy.maxReplicas) ...
kubectl を使用する
その後、次のコマンドを使用して Elastic Training を起動できます。
kubectl apply -f elastic-training-job.yaml
SageMaker レシピの使用
Elastic トレーニングジョブは、SageMaker HyperPod レシピ
注記
Hyperpod Recipe には、SFO ジョブと DPO ジョブ用の 46 個の Elastic recipe が含まれています。ユーザーは、既存の静的ランチャースクリプトに加えて 1 行の変更でこれらのジョブを起動できます。
++recipes.elastic_policy.is_elastic=true
静的レシピに加えて、Elastic レシピは次のフィールドを追加して Elastic の動作を定義します。
Elastic ポリシー
elastic_policy フィールドは、Elastic Training ジョブのジョブレベル設定を定義します。次の設定があります。
-
is_elastic:bool- このジョブが Elastic ジョブの場合 -
min_nodes:int- エラスティックトレーニングに使用されるノードの最小数 -
max_nodes:int- エラスティックトレーニングに使用されるノードの最大数 -
replica_increment_step:int- 固定サイズのグループ内のポッドの増分量。このフィールドは、後で定義する と相互に排他的scale_configです。 -
use_graceful_shutdown:bool- スケーリングイベント中に正常なシャットダウンを使用する場合は、デフォルトで になりますtrue。 -
scaling_timeout:int- タイムアウト前のスケーリングイベント中の秒単位の待機時間 -
graceful_shutdown_timeout:int- 正常なシャットダウンの待機時間
以下は、このフィールドの定義例です。レシピの「Hyperpod Recipe repo」でも確認できます。 recipes_collection/recipes/fine-tuning/llama/llmft_llama3_1_8b_instruct_seq4k_gpu_sft_lora.yaml
<static recipe> ... elastic_policy: is_elastic: true min_nodes: 1 max_nodes: 16 use_graceful_shutdown: true scaling_timeout: 600 graceful_shutdown_timeout: 600
スケール設定
scale_config フィールドは、特定のスケールごとにオーバーライド設定を定義します。これはキーと値のディクショナリで、key はターゲットスケールを表す整数、value は基本レシピのサブセットです。<key> 大規模には、 を使用してベース/静的レシピの特定の設定<value>を更新します。このフィールドの例を次に示します。
scale_config: ... 2: trainer: num_nodes: 2 training_config: training_args: train_batch_size: 128 micro_train_batch_size: 8 learning_rate: 0.0004 3: trainer: num_nodes: 3 training_config: training_args: train_batch_size: 128 learning_rate: 0.0004 uneven_batch: use_uneven_batch: true num_dp_groups_with_small_batch_size: 16 small_local_batch_size: 5 large_local_batch_size: 6 ...
上記の設定は、スケール 2 および 3 のトレーニング設定を定義します。どちらの場合も、学習レート 4e-4、バッチサイズ を使用します128。ただし、スケール 2 では 8 micro_train_batch_sizeの を使用し、スケール 3 では不均等なバッチサイズを使用します。これは、トレーニングバッチサイズを 3 つのノード間で均等に分割できないためです。
バッチサイズが不均一
これは、グローバルバッチサイズをランク数で均等に分割できない場合のバッチ分散動作を定義するフィールドです。伸縮自在なトレーニングに固有ではありませんが、よりきめ細かなスケーリングを実現するイネーブラーです。
-
use_uneven_batch:bool- 不均等なバッチディストリビューションを使用する場合 -
num_dp_groups_with_small_batch_size:int- 不均等なバッチ分散では、一部のランクはローカルバッチサイズを小さくし、他のランクはより大きなバッチサイズを使用します。グローバルバッチサイズは に等しくなければなりませんsmall_local_batch_size * num_dp_groups_with_small_batch_size + (world_size-num_dp_groups_with_small_batch_size) * large_local_batch_size -
small_local_batch_size:int- この値はより小さいローカルバッチサイズです -
large_local_batch_size:int- この値はローカルバッチサイズが大きいです
MLFlow でのトレーニングのモニタリング
Hyperpod レシピジョブは、MLFlow によるオブザーバビリティをサポートします。ユーザーは recipe で MLFlow 設定を指定できます。
training_config: mlflow: tracking_uri: "<local_file_path or MLflow server URL>" run_id: "<MLflow run ID>" experiment_name: "<MLflow experiment name, e.g. llama_exps>" run_name: "<run name, e.g. llama3.1_8b>"
これらの設定は、対応する MLFlow セットアップ
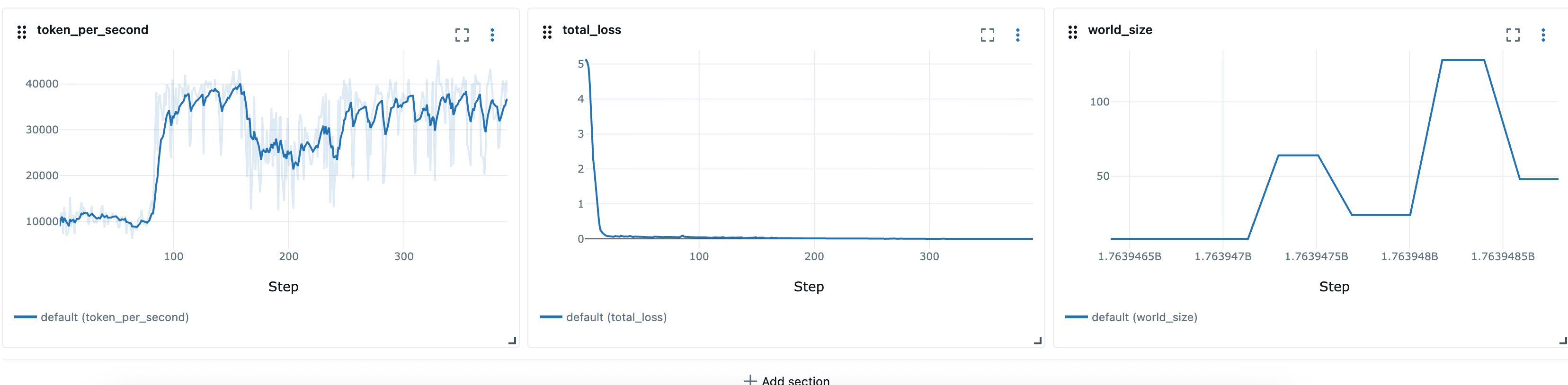
伸縮自在なレシピを定義したら、 などのランチャースクリプトを使用して伸縮自在なトレーニングジョブlauncher_scripts/llama/run_llmft_llama3_1_8b_instruct_seq4k_gpu_sft_lora.shを起動できます。これは、Hyperpod レシピを使用して静的ジョブを起動する場合と似ています。
注記
レシピサポートからの Elastic トレーニングジョブは、最新のチェックポイントから自動的に再開されますが、デフォルトでは、再起動するたびに新しいトレーニングディレクトリが作成されます。最後のチェックポイントからの再開を正しく有効にするには、同じトレーニングディレクトリが再利用されていることを確認する必要があります。これを行うには、 を設定します。
recipes.training_config.training_args.override_training_dir=true
ユースケースの例と制限事項
より多くのリソースが利用可能な場合にスケールアップする
クラスターでより多くのリソースが利用可能になったとき (他のワークロードが完了したなど)。このイベント中、トレーニングコントローラーはトレーニングジョブを自動的にスケールアップします。この動作については、以下で説明します。
より多くのリソースが利用可能になった状況をシミュレートするには、優先度の高いジョブを送信し、優先度の高いジョブを削除してリソースを解放します。
# Submit a high-priority job on your cluster. As a result of this command # resources will not be available for elastic training kubectl apply -f high_prioriy_job.yaml # Submit an elastic job with normal priority kubectl apply -f hyperpod_job_with_elasticity.yaml # Wait for training to start.... # Delete high priority job. This command will make additional resources available for # elastic training kubectl delete -f high_prioriy_job.yaml # Observe the scale-up of elastic job
予想される動作:
-
トレーニングオペレーターは Kueue ワークロードを作成します。Elastic トレーニングジョブがワールドサイズの変更をリクエストすると、トレーニングオペレーターは新しいリソース要件を表す追加の Kueue ワークロードオブジェクトを生成します。
-
Kueue はワークロード Kueue を承認し、利用可能なリソース、優先順位、キューポリシーに基づいてリクエストを評価します。承認されると、ワークロードは許可されます。
-
トレーニングオペレーターは追加の Pod を作成します。アドミッション時に、オペレーターは新しいワールドサイズに到達するために必要な追加のポッドを起動します。
-
新しいポッドの準備ができると、トレーニングオペレーターはトレーニングスクリプトに特別な Elastic イベントシグナルを送信します。
-
トレーニングジョブはチェックポイントを実行して、正常なシャットダウンに備えます。トレーニングプロセスは elastic_event_detected() 関数を呼び出して、Elastic イベントシグナルを定期的にチェックします。検出されると、チェックポイントが開始されます。チェックポイントが正常に完了すると、トレーニングプロセスはクリーンに終了します。
-
トレーニングオペレーターは、新しいワールドサイズでジョブを再起動します。オペレーターは、すべてのプロセスが終了するのを待ってから、更新されたワールドサイズと最新のチェックポイントを使用してトレーニングジョブを再起動します。
注: Kueue を使用しない場合、トレーニングオペレーターは最初の 2 つのステップをスキップします。新しいワールドサイズに必要な追加のポッドをすぐに作成しようとします。クラスターで十分なリソースが利用できない場合、これらのポッドは容量が利用可能になるまで保留状態のままになります。

優先度の高いジョブによるプリエンプション
優先度の高いジョブにリソースが必要な場合、Elastic ジョブを自動的にスケールダウンできます。この動作をシミュレートするには、高優先度のジョブを送信するよりも、トレーニングの開始から使用可能なリソースの最大数を使用する Elastic トレーニングジョブを送信し、プリエンプション動作を監視できます。
# Submit an elastic job with normal priority kubectl apply -f hyperpod_job_with_elasticity.yaml # Submit a high-priority job on your cluster. As a result of this command # some amount of resources will be kubectl apply -f high_prioriy_job.yaml # Observe scale-down behaviour
優先度の高いジョブにリソースが必要な場合、Kueue は優先度の低い Elastic Training ワークロードを優先できます (Elastic Training ジョブに関連付けられたワークロードオブジェクトが複数存在する可能性があります)。プリエンプションプロセスは、次のシーケンスに従います。
-
優先度の高いジョブが送信されました ジョブは新しい Kueue ワークロードを作成しますが、クラスターリソースが不足しているためワークロードを許可できません。
-
Kueue は、Elastic Training ジョブのワークロード Elastic ジョブの 1 つに複数のアクティブなワークロード (ワールドサイズ設定ごとに 1 つ) を優先します。Kueue は、優先度ポリシーとキューポリシーに基づいて、優先するポリシーを選択します。
-
トレーニングオペレーターは Elastic イベントシグナルを送信します。プリエンプションがトリガーされると、トレーニングオペレーターは実行中のトレーニングプロセスに正常に停止するよう通知します。
-
トレーニングプロセスはチェックポイントを実行します。トレーニングジョブは、Elastic Event シグナルを定期的にチェックします。検出されると、調整されたチェックポイントが開始され、シャットダウンする前に進行状況が保持されます。
-
トレーニングオペレーターはポッドとワークロードをクリーンアップします。オペレーターはチェックポイントの完了を待ってから、プリエンプションされたワークロードの一部であったトレーニングポッドを削除します。また、対応するワークロードオブジェクトを Kueue から削除します。
-
優先度の高いワークロードは許可されます。リソースが解放されると、Kueue は優先度の高いジョブを承認し、実行を開始できるようにします。

プリエンプションにより、トレーニングジョブ全体が一時停止する可能性があります。これは、すべてのワークフローにとって望ましくない場合があります。Elastic Scaling を許可しながらフルジョブの停止を回避するには、2 つのreplicaSpecセクションを定義することで、同じトレーニングジョブ内で 2 つの異なる優先度レベルを設定できます。
-
標準または高優先度のプライマリ (固定) replicaSpec
-
トレーニングジョブの実行を維持するために最低限必要な数のレプリカが含まれます。
-
より高い PriorityClass を使用し、これらのレプリカが優先されないようにします。
-
クラスターがリソース負荷を受けている場合でも、ベースラインの進行状況を維持します。
-
-
優先度の低いエラスティック (スケーラブル) replicaSpec
-
Elastic Scaling 中に追加のコンピューティングを提供する追加のオプションのレプリカが含まれています。
-
より低い PriorityClass を使用し、優先度の高いジョブにリソースが必要な場合に Kueue がこれらのレプリカを優先できるようにします。
-
コアトレーニングが中断されることなく、伸縮自在な部分のみが再利用されるようにします。
-
この設定により、Elastic 容量のみが再利用される部分的なプリエンプションが可能になり、マルチテナント環境で公平なリソース共有をサポートしながら、トレーニングの継続性が維持されます。例:
apiVersion: sagemaker.amazonaws.com/v1 kind: HyperPodPyTorchJob metadata: name: elastic-training-job spec: elasticPolicy: minReplicas: 2 maxReplicas: 8 replicaIncrementStep: 2 ... replicaSpecs: - name: base replicas: 2 template: spec: priorityClassName: high-priority # set high-priority to avoid evictions ... - name: elastic replicas: 0 maxReplicas: 6 template: spec: priorityClassName: low-priority. # Set low-priority for elastic part ...
ポッドエビクション、ポッドクラッシュ、ハードウェア劣化の処理:
HyperPod トレーニングオペレーターには、トレーニングプロセスが予期せず中断されたときに復旧するための組み込みメカニズムが含まれています。中断は、トレーニングコードの障害、ポッドのエビクション、ノードの障害、ハードウェアの劣化、その他のランタイムの問題など、さまざまな理由で発生する可能性があります。
この場合、オペレーターは自動的に影響を受けるポッドを再作成し、最新のチェックポイントからトレーニングを再開しようとします。たとえば、予備の容量が不足しているなどしてすぐに復旧できない場合、オペレーターは一時的にワールドサイズを縮小し、伸縮自在なトレーニングジョブをスケールダウンすることで、進行を続けることができます。
伸縮自在なトレーニングジョブがクラッシュしたり、レプリカが失われたりすると、システムは次のように動作します。
-
復旧フェーズ (スペアノードを使用) Training Controller は、
faultyScaleDownTimeoutInSecondsリソースが利用可能になるまで最大 まで待機し、スペア容量にポッドを再デプロイして、障害が発生したレプリカの復旧を試みます。 -
Elastic scale-down タイムアウトウィンドウ内で復旧できない場合、トレーニングオペレーターはジョブをより小さなワールドサイズにスケールダウンします (ジョブの Elastic ポリシーで許可されている場合)。その後、トレーニングはより少ないレプリカで再開されます。
-
Elastic scale-up 追加のリソースが再び利用可能になると、オペレーターはトレーニングジョブを任意のワールドサイズに自動的にスケールアップします。
このメカニズムにより、リソースの負荷やインフラストラクチャの部分的な障害が発生しても、トレーニングを最小限のダウンタイムで継続しながら、Elastic Scaling を活用できます。
Elastic Training を他の HyperPod 機能で使用する
Elastic Training は現在、チェックポイントレストレーニング機能、HyperPod マネージド階層型チェックポイント、またはスポットインスタンスをサポートしていません。
注記
当社は、重要なサービスの可用性を提供するために、特定の日常的な集約および匿名化された運用メトリクスを収集します。これらのメトリクスの作成は完全に自動化されており、基盤となるモデルトレーニングワークロードの人間によるレビューは含まれません。これらのメトリクスは、ジョブおよびスケーリングオペレーション、リソース管理、重要なサービス機能に関連しています。
