翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
SageMaker Neo によるモデルパフォーマンスの最適化
Neo は、機械学習モデルを一度トレーニングするだけで、クラウド内やエッジのどこでも実行することを可能にする Amazon SageMaker AI の機能です。
SageMaker Neo を初めて使う方は、「エッジデバイスのご利用開始にあたって」セクションを確認してコンパイルして、エッジデバイスにデプロイする方法のステップバイステップの手順を参照してください。
SageMaker Neo とは
通常、複数のプラットフォームで推論を実行する機械学習モデルの最適化は難しいものです。これは、各プラットフォームに固有のハードウェア/ソフトウェア構成に合わせてモデルを手動でチューニングする必要があるためです。特定のワークロードに対して最適なパフォーマンスを得るには、ハードウェアアーキテクチャ、命令セット、メモリアクセスパターン、入力データの形状を特に知っておく必要があります。従来のソフトウェア開発では、コンパイラやプロファイラなどのツールを使用するとプロセスが簡単になります。Machine Learning の場合、ほとんどのツールはフレームワークまたはハードウェアに固有のものです。このため、手動による試行錯誤のプロセスが必要になり、信頼性と生産性が低下します。
Neo は、Ambarella、ARM、Intel、Nvidia、NXP、Qualcomm、Texas Instruments、Xilinx のプロセッサをベースとする Android、Linux、Windows マシンで推論を行うために、Gluon、Keras、MXNet、PyTorch、TensorFlow-Lite、ONNX モデルを自動的に最適化しています。Neoは、フレームワーク間の Model Zoo で利用可能なコンピュータビジョンモデルでテストされています。SageMaker Neo は、2 つの主要なプラットフォームであるクラウドインスタンス (Inferentia を含む) とエッジデバイスに対するコンパイルとデプロイをサポートしています。
デプロイ先としてサポートされているフレームワークとクラウドインスタンスタイプの詳細については、クラウドインスタンスの「サポートされるインスタンスタイプとフレームワーク」を参照してください。
サポートされているフレームワーク、エッジデバイス、オペレーティングシステム、チップアーキテクチャ、SageMaker AI Neo がエッジデバイス向けにテストした一般的な機械学習モデルの詳細については、エッジデバイスの「サポートされているフレームワーク、デバイス、システム、アーキテクチャ」を参照してください。
仕組み
Neo は、コンパイラとランタイムで構成されています。まず、Neo コンパイル API はさまざまなフレームワークからエクスポートされたモデルを読み込みます。フレームワーク固有の機能とオペレーションをフレームワークにとらわれない中間表現に変換します。次に、一連の最適化を実行します。次に、最適化されたオペレーション用のバイナリコードを生成して、それらを共有オブジェクトライブラリに記述し、モデル定義とパラメータを別々のファイルに保存します。Neo は、コンパイルされたモデルをロードして実行する各ターゲットプラットフォーム用のランタイムも提供します。
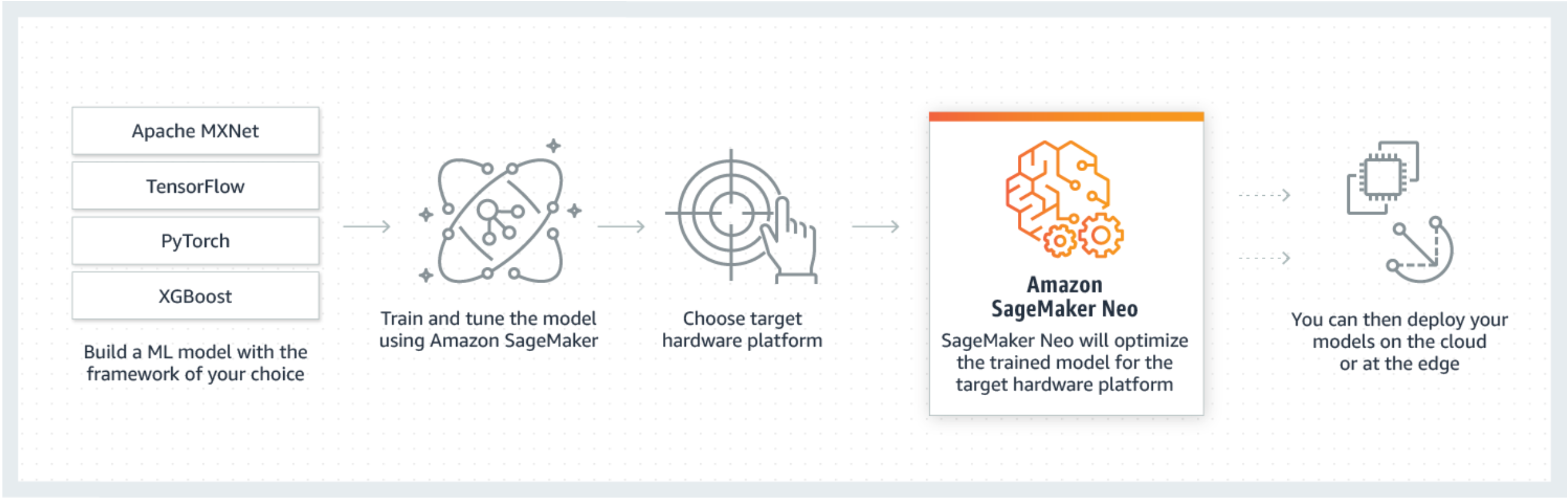
Neo コンパイルジョブは、SageMaker AI コンソール、 AWS Command Line Interface (AWS CLI)、Python ノートブック、または SageMaker AI SDK のいずれかを使って作成できます。モデルをコンパイルする方法については、「Neo によるモデルコンパイル」を参照してください。いくつかの CLI コマンド、API の呼び出し、または数回のクリックで、選択したプラットフォーム用にモデルを変換できます。モデルは SageMaker AI エンドポイントまたは AWS IoT Greengrass デバイスにすばやくデプロイできます。
Neo は、FP32 や、INT8 または FP16 ビット幅に量子化されたパラメータを使用してモデルを最適化することができます。
