翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
シャーディングデータ並列処理
シャーディングデータ並列処理は、メモリを節約する分散トレーニング手法で、モデルの状態 (モデルパラメータ、勾配、およびオプティマイザの状態) をデータ並列グループ内の GPU 間で分割します。
注記
シャーディングデータ並列処理は、SageMaker モデル並列処理ライブラリ v1.11.0 以降の PyTorch で使用できます。
トレーニングジョブを大規模な GPU クラスターにスケールアップする場合、モデルのトレーニング状態を複数の GPU にシャーディングすることで、モデルの GPU ごとのメモリフットプリントを削減できます。これには 2 つのメリットがあります。1 つは、標準のデータ並列処理ではメモリが不足する大規模なモデルに対応できること、もう 1 つは、解放された GPU メモリを使用してバッチサイズを増やせることです。
標準のデータ並列処理手法は、データ並列グループ内の GPU 全体でトレーニング状態を複製し、AllReduce オペレーションに基づいて勾配集計を実行します。シャーディングデータ並列処理は、オプティマイザ状態のシャーディングの性質を考慮して、標準のデータ並列分散トレーニング手順を変更します。モデル状態とオプティマイザ状態がシャーディングされるランクのグループは、シャーディンググループと呼ばれます。シャーディングデータ並列処理手法では、モデルのトレーニング可能なパラメータと、それに対応する勾配とオプティマイザ状態をシャーディンググループ内の GPU 全体でシャーディングします。
SageMaker AI は、 AWS ブログ記事「巨大モデルトレーニングのほぼ線形スケーリング AWSAllGather オペレーションを通じてすべての GPU のモデルパラメータを一時的に再結合します。各レイヤーのフォワードパスまたはバックワードパスの後、MiCS はパラメータを再度シャーディングして GPU メモリを節約します。バックワードパス中、MiCS は勾配を縮小し、同時に ReduceScatter オペレーションを通じて GPU 間で勾配をシャーディングします。最後に、MiCS は、オプティマイザ状態のローカルシャードを使用して、ローカルの縮小勾配とシャーディング勾配を対応するローカルパラメータシャードに適用します。通信オーバーヘッドを減らすために、SageMaker モデル並列処理ライブラリは、フォワードパスまたはバックワードパスで次のレイヤーをプリフェッチし、ネットワーク通信と計算を重複させます。
モデルのトレーニング状態はシャーディンググループ全体で複製されます。つまり、勾配をパラメータに適用する前に、シャーディンググループ内で行われる ReduceScatter オペレーションに加えて、シャーディンググループ全体で AllReduce オペレーションを実行する必要があります。
事実上、シャーディングデータ並列処理では、通信オーバーヘッドと GPU メモリ効率の間にトレードオフが生じます。シャーディングデータ並列処理を使用すると、通信コストは増加しますが、GPU あたりのメモリ使用量 (アクティベーションによるメモリ使用量を除く) はシャーディングデータ並列処理度で分割するため、より大きなモデルを GPU クラスターに収めることができます。
シャーディングデータ並列処理度の選択
シャーディングデータ並列処理度の値を選択するとき、その値によってデータ並列処理度を均等に分割する必要があります。例えば、8 方向データ並列処理ジョブの場合、シャーディングデータ並列処理度に 2、4、または 8 を選択します。シャーディングデータ並列処理度を選択するときは、小さい数値から始め、モデルが目的のバッチサイズとともにメモリに収まるまで徐々に増やすことをお勧めします。
バッチサイズの選択
シャーディングデータ並列処理を設定したら、GPU クラスターで正常に実行できる最適なトレーニング設定を見つけます。大規模言語モデル (LLM) をトレーニングする場合は、バッチサイズ 1 から始めて、メモリ不足 (OOM) エラーが発生するポイントに達するまで徐々に大きくします。最小のバッチサイズでも OOM エラーが発生する場合は、より高度なシャーディングデータ並列処理を適用するか、シャーディングデータ並列処理とテンソル並列処理を組み合わせて適用します。
トピック
シャーディングデータ並列処理をトレーニングジョブに適用する方法
シャーディングデータ並列処理を開始するには、トレーニングスクリプトに必要な変更を適用し、シャーディングデータ並列処理固有のパラメータを使用して SageMaker PyTorch 推定器を設定します。また、開始点として、参照値とサンプルノートブックを使用することも検討してください。
PyTorch トレーニングスクリプトを適合させる
「ステップ 1: PyTorch トレーニングスクリプトを変更する」の指示に従って、モデルオブジェクトとオプティマイザオブジェクトをtorch.nn.parallel および torch.distributed のモジュールの smdistributed.modelparallel.torch ラッパーでラップします。
(オプション) 外部モデルパラメータを登録するための追加変更
モデルが torch.nn.Module で構築されており、モジュールクラス内で定義されていないパラメータを使用する場合、SMP がすべてのパラメータを収集できるように、それらのパラメータを手動でモジュールに登録する必要があります。パラメータをモジュールに登録するには、「smp.register_parameter(module,
parameter)」を使用してください。
class Module(torch.nn.Module): def __init__(self, *args): super().__init__(self, *args) self.layer1 = Layer1() self.layer2 = Layer2() smp.register_parameter(self, self.layer1.weight) def forward(self, input): x = self.layer1(input) # self.layer1.weight is required by self.layer2.forward y = self.layer2(x, self.layer1.weight) return y
SageMaker PyTorch 推定器のセットアップ
ステップ 2: SageMaker Python SDK を使用してトレーニングジョブを起動する で SageMaker PyTorch 推定器を設定するときは、シャーティングデータ並列処理用のパラメータを追加します。
シャードディングデータ並列処理を有効にするには、SageMaker PyTorch 推定器に sharded_data_parallel_degree パラメータを追加します。このパラメータは、トレーニング状態をシャーディングする GPU の数を指定します。sharded_data_parallel_degree の値は、1 とデータ並列処理度の間の整数で、データ並列処理度を均等に割る必要があります。ライブラリは GPU の数を自動的に検出するため、データ並列度も検出されることに注意してください。シャーディングデータ並列処理には、次の追加パラメータが利用できます。
-
"sdp_reduce_bucket_size"(int、デフォルト: 5e8) — PyTorch DDP 勾配バケットのサイズをデフォルトの dtype の要素の数で指定します。 -
"sdp_param_persistence_threshold"(int、デフォルト: 1e6) — 各 GPU で保持できる要素の数でパラメータテンソルのサイズを指定します。シャーディングデータ並列処理は、各パラメータテンソルをデータ並列グループの GPU 間で分割します。パラメータテンソルの要素の数がこのしきい値よりも小さい場合、パラメータテンソルは分割されません。パラメータテンソルは、データ並列 GPU 間で複製されるため、通信オーバーヘッドを削減できます。 -
"sdp_max_live_parameters"(int、デフォルト: 1e9) — フォワードパスとバックワードパス中に再結合されたトレーニング状態に同時に配置できるパラメータの最大数を指定します。アクティブなパラメータの数が所定のしきい値に達すると、AllGatherオペレーションによるパラメータの取得は一時停止します。このパラメータをの数を増加すると、メモリ使用量が増えることに注意してください。 -
"sdp_hierarchical_allgather"(bool、デフォルト: True) —Trueに設定すると、AllGatherオペレーションは階層的に実行されます。最初に各ノード内で実行され、次にノード間で実行されます。複数ノードの分散型トレーニングジョブでは、階層型AllGatherオペレーションが自動的に有効になります。 -
"sdp_gradient_clipping"(float、デフォルト: 1.0) — モデルパラメータを介して逆方向に伝播する前に、勾配の L2 ノルムを勾配クリッピングするしきい値を指定します。シャーディングデータ並列処理を有効にすると、勾配クリッピングも有効になります。デフォルトのしきい値は1.0です。勾配が爆発的に増加する問題がある場合は、このパラメータを調整してください。
次のコードには、シャーディングデータ並列処理の例が示されています。
import sagemaker from sagemaker.pytorch import PyTorch smp_options = { "enabled": True, "parameters": { # "pipeline_parallel_degree": 1, # Optional, default is 1 # "tensor_parallel_degree": 1, # Optional, default is 1 "ddp": True, # parameters for sharded data parallelism "sharded_data_parallel_degree":2, # Add this to activate sharded data parallelism "sdp_reduce_bucket_size": int(5e8), # Optional "sdp_param_persistence_threshold": int(1e6), # Optional "sdp_max_live_parameters": int(1e9), # Optional "sdp_hierarchical_allgather":True, # Optional "sdp_gradient_clipping":1.0# Optional } } mpi_options = { "enabled" : True, # Required "processes_per_host" :8# Required } smp_estimator = PyTorch( entry_point="your_training_script.py", # Specify your train script role=sagemaker.get_execution_role(), instance_count=1, instance_type='ml.p3.16xlarge', framework_version='1.13.1', py_version='py3', distribution={ "smdistributed": {"modelparallel": smp_options}, "mpi": mpi_options }, base_job_name="sharded-data-parallel-job" ) smp_estimator.fit('s3://my_bucket/my_training_data/')
リファレンス設定
SageMaker の分散トレーニングチームには、開始点として利用できる次のリファレンス設定が提供されています。次の設定から外挿して、モデル設定の GPU メモリ使用量を推定できます。
SMDDP Collectives によるシャーディングデータ並列処理
| モデル/パラメータの数 | Num インスタンス | インスタンスタイプ | シーケンスの長さ | グローバルバッチサイズ | ミニバッチサイズ | シャーディングデータ並列度 |
|---|---|---|---|---|---|---|
| GPT-NEOX-20B | 2 | ml.p4d.24xlarge | 2048 | 64 | 4 | 16 |
| GPT-NEOX-20B | 8 | ml.p4d.24xlarge | 2048 | 768 | 12 | 32 |
例えば、200 億パラメータのモデルのシーケンス長を増やしたり、モデルのサイズを 650 億パラメータに増やす場合は、最初にバッチサイズを減少させる必要があります。それでもモデルが最小のバッチサイズ (バッチサイズ 1) に収まらない場合は、モデルの並列処理度を上げてみます。
テンソル並列処理と NCCL Collectives によるシャーディングデータ並列処理
| モデル/パラメータの数 | Num インスタンス | インスタンスタイプ | シーケンスの長さ | グローバルバッチサイズ | ミニバッチサイズ | シャーディングデータ並列度 | テンソル並列度 | アクティベーションオフロード |
|---|---|---|---|---|---|---|---|---|
| GPT-NEOX-65B | 64 | ml.p4d.24xlarge | 2048 | 512 | 8 | 16 | 8 | はい |
| GPT-NEOX-65B | 64 | ml.p4d.24xlarge | 4096 | 512 | 2 | 64 | 2 | はい |
シャーディングデータ並列処理とテンソル並列処理を組み合わせて使用すると、大規模言語モデル (LLM) を大規模なクラスターに適合させ、一方でシーケンス長の長いテキストデータを使用し (この場合、バッチサイズが小さくなります)、結果として長いテキストシーケンスに対して LLM をトレーニングするために GPU メモリ使用量を処理する場合に役立ちます。詳細についてはテンソル並列処理と NCCL Collectives によるシャーディングデータ並列処理を参照してください。
導入事例、ベンチマーク、その他の設定例については、ブログ記事「New performance improvements in Amazon SageMaker AI model parallel library
SMDDP Collectives によるシャーディングデータ並列処理
SageMaker データ並列処理ライブラリは、 AWS インフラストラクチャに最適化された集合通信プリミティブ (SMDDP 集合) を提供します。Elastic Fabric Adapter (EFA)
注記
SMDDP Collectives によるシャーディングデータ並列処理は、SageMaker モデル並列処理ライブラリ v1.13.0 以降、および SageMaker データ並列処理ライブラリ v1.6.0 以降で使用できます。SMDDP Collectives でシャーディングデータ並列処理を使用するには、「Supported configurations」も参照してください。
大規模な分散トレーニングで一般的に使用される手法であるシャーディングデータ並列処理では、AllGather 集合体を使用して、GPU 計算と並列して、フォワードパス計算とバックワードパス計算のシャーディングレイヤーパラメータを再構成します。大規模なモデルでは、GPU のボトルネックの問題やトレーニング速度の低下を回避するために、AllGather オペレーションを効率的に実行することが重要です。シャーディングデータ並列処理を有効にすると、SMDDP Collectives はパフォーマンスが重要な AllGather 集合体にまとめられ、トレーニングのスループットが向上します。
SMDDP Collectives によるトレーニング
トレーニングジョブでシャーディングデータ並列処理が有効になっていて、Supported configurations を満たすと、SMDDP Collectives が自動的に有効になります。内部的には、SMDDP Collectives は AWS 、インフラストラクチャでパフォーマンスを発揮するようにAllGather集合体を最適化し、他のすべての集合体の NCCL にフォールバックします。さらに、サポートされていない設定では、AllGather を含むすべての集合体が自動的に NCCL バックエンドを使用します。
SageMaker モデル並列処理ライブラリバージョン 1.13.0 以降、"ddp_dist_backend" パラメータは modelparallel オプションに追加されています。この設定パラメータのデフォルト値は "auto" で、可能な限り SMDDP Collectives を使用し、それ以外の場合は NCCL にフォールバックします。ライブラリが常に NCCL を使用するように強制するには、"ddp_dist_backend" 設定パラメータに "nccl" を指定します。
次のコード例は、シャーディングデータ並列処理と "ddp_dist_backend" パラメータを使用して PyTorch 推定器を設定する方法を示しています。このパラメータはデフォルトで "auto" に設定されているため、オプションで追加できます。
import sagemaker from sagemaker.pytorch import PyTorch smp_options = { "enabled":True, "parameters": { "partitions": 1, "ddp": True, "sharded_data_parallel_degree":64"bf16": True, "ddp_dist_backend": "auto" # Specify "nccl" to force to use NCCL. } } mpi_options = { "enabled" : True, # Required "processes_per_host" : 8 # Required } smd_mp_estimator = PyTorch( entry_point="your_training_script.py", # Specify your train script source_dir="location_to_your_script", role=sagemaker.get_execution_role(), instance_count=8, instance_type='ml.p4d.24xlarge', framework_version='1.13.1', py_version='py3', distribution={ "smdistributed": {"modelparallel": smp_options}, "mpi": mpi_options }, base_job_name="sharded-data-parallel-demo", ) smd_mp_estimator.fit('s3://my_bucket/my_training_data/')
サポートされている設定
SMDDP Collectives の AllGather オペレーションは、以下の設定要件がすべて満たされるとトレーニングジョブで有効になります。
-
シャーディングデータ並列処理度が 1 を超えている。
-
Instance_countが 1 より大きい -
Instance_typeがml.p4d.24xlargeに等しい -
PyTorch v1.12.1 以降の SageMaker トレーニングコンテナ
-
SageMaker データ並列処理ライブラリ v1.6.0 またはそれ以降
-
SageMaker モデルの並列処理ライブラリ v1.13.0 またはそれ以降
パフォーマンスとメモリのチューニング
SMDDP Collectives は追加の GPU メモリを使用します。モデルトレーニングのさまざまなユースケースに応じて、GPU メモリ使用量を設定する環境変数が 2 つあります。
-
SMDDP_AG_SCRATCH_BUFFER_SIZE_BYTES— SMDDPAllGatherオペレーション中、AllGather入力バッファはノード間通信用の一時バッファにコピーされます。SMDDP_AG_SCRATCH_BUFFER_SIZE_BYTES変数は、この一時バッファのサイズ (バイト単位) を制御します。一時バッファのサイズがAllGather入力バッファサイズよりも小さい場合、AllGather集合体は NCCL を使用するようにフォールバックします。-
デフォルト値: 16 * 1024 * 1024 (16 MB)
-
許容値: 8192 の任意の倍数
-
-
SMDDP_AG_SORT_BUFFER_SIZE_BYTES—SMDDP_AG_SORT_BUFFER_SIZE_BYTES変数は、ノード間通信から収集されたデータを格納するための一時バッファのサイズを (バイト単位で) 設定します。この一時バッファのサイズが1/8 * sharded_data_parallel_degree * AllGather input sizeよりも小さい場合、AllGather集合体は NCCL を使用するようにフォールバックします。-
デフォルト値: 128 * 1024 * 1024 (128 MB)
-
許容値: 8192 の任意の倍数
-
バッファサイズ変数に関するチューニングガイダンス
環境変数のデフォルト値は、ほとんどのユースケースで適切に機能します。これらの変数は、トレーニングでメモリ不足 (OOM) エラーが発生した場合にのみ調整することをお勧めします。
以下のリストでは、SMDDP Collectives によるパフォーマンスの向上を維持しながら、その GPU メモリ使用量を削減するためのチューニングのヒントをいくつか紹介します。
-
SMDDP_AG_SCRATCH_BUFFER_SIZE_BYTESのチューニング-
AllGather入力バッファのサイズは、モデルが小さいほど小さくなります。したがって、パラメータの数が少ないモデルでは、SMDDP_AG_SCRATCH_BUFFER_SIZE_BYTESに必要なサイズを小さくすることができます。 -
モデルは多くの GPU にシャーディングされるため、
AllGather入力バッファサイズはsharded_data_parallel_degreeが大きくなるにつれて小さくなります。そのため、sharded_data_parallel_degreeの値が大きいトレーニングジョブでは、SMDDP_AG_SCRATCH_BUFFER_SIZE_BYTESに必要なサイズを小さくすることができます。
-
-
SMDDP_AG_SORT_BUFFER_SIZE_BYTESのチューニング-
ノード間通信から収集されるデータ量は、パラメータの数が少ないモデルほど少なくなります。したがって、パラメータの数が少ないこうしたモデルでは、
SMDDP_AG_SORT_BUFFER_SIZE_BYTESに必要なサイズを小さくすることができます。
-
一部の集合体は NCCL を使用するようフォールバックする場合があるため、最適化された SMDDP Collectives ではパフォーマンスが向上しない場合があります。追加の GPU メモリを使用できる場合は、SMDDP_AG_SCRATCH_BUFFER_SIZE_BYTES および SMDDP_AG_SORT_BUFFER_SIZE_BYTES の値を増やしてパフォーマンスを向上させることを検討してください。
次のコードは、PyTorch 推定器の分散パラメータの mpi_options に環境変数を追加して設定する方法を示しています。
import sagemaker from sagemaker.pytorch import PyTorch smp_options = { .... # All modelparallel configuration options go here } mpi_options = { "enabled" : True, # Required "processes_per_host" : 8 # Required } # Use the following two lines to tune values of the environment variables for buffer mpioptions += " -x SMDDP_AG_SCRATCH_BUFFER_SIZE_BYTES=8192" mpioptions += " -x SMDDP_AG_SORT_BUFFER_SIZE_BYTES=8192" smd_mp_estimator = PyTorch( entry_point="your_training_script.py", # Specify your train script source_dir="location_to_your_script", role=sagemaker.get_execution_role(), instance_count=8, instance_type='ml.p4d.24xlarge', framework_version='1.13.1', py_version='py3', distribution={ "smdistributed": {"modelparallel": smp_options}, "mpi": mpi_options }, base_job_name="sharded-data-parallel-demo-with-tuning", ) smd_mp_estimator.fit('s3://my_bucket/my_training_data/')
シャーディングデータ並列処理による混合精度トレーニング
半精度浮動小数点数とシャーディングデータ並列処理で GPU メモリをさらに節約するには、分散トレーニング設定にパラメータを 1 つ追加して 16 ビット浮動小数点形式 (FP16) または Brain 浮動小数点形式
注記
シャーディングデータ並列処理による混合精度トレーニングは、SageMaker モデル並列処理ライブラリ v1.11.0 以降で使用できます。
シャーディングデータ並列処理による FP16 トレーニング
シャーディングデータ並列処理で FP16 トレーニングを実行するには、smp_options 設定ディクショナリに "fp16": True" を追加します。トレーニングスクリプトでは、smp.DistributedOptimizer モジュールを使用して静的損失スケーリングオプションと動的損失スケーリングオプションのいずれかを選択できます。詳細については、「モデル並列処理による FP16 トレーニング」を参照してください。
smp_options = { "enabled":True, "parameters": { "ddp":True, "sharded_data_parallel_degree":2, "fp16":True} }
シャーディングデータ並列処理による BF16 トレーニング
SageMaker AI のシャーディングデータ並列処理機能は BF16 データ型のトレーニングをサポートします。BF16 データ型は 8 ビットを使用して浮動小数点数の指数を表現し、FP16 データ型は 5 ビットを使用します。指数を 8 ビットにしておくと、32 ビットの単精度浮動小数点 (FP32) 数の指数と同じ表現を維持できます。これにより、FP32 と BF16 間の変換がより簡単になり、FP16 のトレーニング、特に大規模なモデルのトレーニングで頻繁に発生するオーバーフローやアンダーフローの問題が発生しにくくなります。どちらのデータ型も合計で 16 ビットを使用しますが、BF16 形式での指数の表現範囲が広がると、精度が低下します。大規模なモデルをトレーニングする場合、この精度の低下は、多くの場合、範囲とトレーニングの安定性にとって許容できるトレードオフと見なされます。
注記
現在、BF16 トレーニングはシャーディングデータ並列処理が有効になっている場合にのみ機能します。
シャーディングデータ並列処理で BF16 トレーニングを実行するには、smp_options 設定ディクショナリに "bf16": True を追加します。
smp_options = { "enabled":True, "parameters": { "ddp":True, "sharded_data_parallel_degree":2, "bf16":True} }
テンソル並列処理と NCCL Collectives によるシャーディングデータ並列処理
シャーディングデータ並列処理を使用し、グローバルバッチサイズも小さくする必要がある場合は、テンソル並列処理とシャーディングデータ並列処理の使用を検討してください。非常に大規模な計算クラスター (通常は 128 ノード以上) でシャーディングデータ並列処理を使用する大規模なモデルをトレーニングする場合、GPU あたりのバッチサイズが小さくても、グローバルバッチサイズが非常に大きくなります。これにより、収束の問題や計算パフォーマンスの低下の問題が発生する可能性があります。1 つのバッチがすでに大きく、それ以上削減できない場合、シャーディングデータ並列処理だけでは GPU あたりのバッチサイズを小さくできないことがあります。このような場合、シャーディングデータ並列処理とテンソル並列処理を組み合わせて使用すると、グローバルバッチサイズを小さくすることができます。
最適なシャーディングデータ並列度とテンソル並列度の選択は、モデルの規模、インスタンスタイプ、およびモデルが収束するのに適したグローバルバッチサイズによって異なります。CUDA のメモリ不足エラーを解決して最高のパフォーマンスを実現するには、低いテンソル並列度から始めてグローバルバッチサイズを計算クラスターに合わせることをお勧めします。次の 2 つのケース例を参照し、テンソル並列処理とシャーディングデータ並列処理の組み合わせにより、GPU をモデル並列処理用にグループ化することでグローバルバッチサイズを調整し、モデルレプリカの数を減らしてグローバルバッチサイズを小さくする方法を確認してください。
注記
この機能は SageMaker モデル並列処理ライブラリ v1.15 から提供されており、PyTorch v1.13.1 をサポートしています。
注記
この機能は、ライブラリのテンソル並列処理機能によりサポート対象のモデルで使用できます。サポートされているモデルのリストについては、「Hugging Face Transformer モデルのサポート」を参照してください。また、トレーニングスクリプトを変更する際は、smp.model_creation 引数に tensor_parallelism=True を渡す必要があることにも注意してください。詳細については、「SageMaker AI Examples GitHub リポジトリ」のトレーニングスクリプト train_gpt_simple.py
例 1
1536 GPU (192 ノード、それぞれ 8 GPU) のクラスターでモデルをトレーニングするとします。シャーディングデータの並列処理度を 32 (sharded_data_parallel_degree=32) に、GPU あたりのバッチサイズを 1 に設定し、各バッチのシーケンス長は 4096 トークンです。この場合、モデルレプリカは 1536 個、グローバルバッチサイズは 1536 個になり、各グローバルバッチには約 600 万個のトークンが含まれます。
(1536 GPUs) * (1 batch per GPU) = (1536 global batches) (1536 batches) * (4096 tokens per batch) = (6,291,456 tokens)
テンソル並列処理を追加すると、グローバルバッチサイズを小さくすることができます。設定例の 1 つは、テンソル並列度を 8 に、GPU あたりのバッチサイズを 4 に設定することです。これにより、192 のテンソル並列グループまたは 192 のモデルレプリカが形成され、各モデルレプリカは 8 つの GPU に分散されます。バッチサイズ 4 は、反復ごと、およびテンソル並列グループごとのトレーニングデータの量です。つまり、各モデルレプリカは反復ごとに 4 つのバッチを消費します。この場合、グローバルバッチサイズは 768 になり、各グローバルバッチには約 300 万個のトークンが含まれます。したがって、シャーディングデータ並列処理のみを行った前のケースと比較して、グローバルバッチサイズは半分に削減されます。
(1536 GPUs) / (8 tensor parallel degree) = (192 tensor parallelism groups) (192 tensor parallelism groups) * (4 batches per tensor parallelism group) = (768 global batches) (768 batches) * (4096 tokens per batch) = (3,145,728 tokens)
例 2
シャーディングデータ並列処理とテンソル並列処理の両方が有効になると、ライブラリは最初にテンソル並列処理を適用し、このディメンション全体でモデルをシャードします。テンソル並列ランクごとに、データ並列処理は sharded_data_parallel_degree という形式で適用されます。
例えば、32 個の GPU をテンソル並列度 4 (4 個の GPU のグループ形成)、シャーディングデータ並列度 4 に設定し、最終的にレプリケーション度を 2 に設定するとします。この割り当てにより、テンソル並列度に基づいて、(0,1,2,3)、(4,5,6,7)、(8,9,10,11)、(12,13,14,15)、(16,17,18,19)、(20,21,22,23)、(24,25,26,27)、(28,29,30,31) という形式で 8 個の GPU が作成されます。つまり、4 つの GPU が 1 つのテンソル並列グループを形成します。この場合、テンソル並列グループの 0 ランク GPU の縮小データ並列グループは (0,4,8,12,16,20,24,28) となります。縮小データ並列グループは、シャーディングデータ並列度 4 に基づいてシャーディングされ、データ並列処理用の 2 つのレプリケーショングループとなります。GPU (0,4,8,12) は 1 つのシャーディンググループを形成し、0 番目のテンソル並列ランクの全パラメータの完全なコピーをそれにまとめて保持します。一方、GPU (16,20,24,28) は別のそうしたグループを形成します。他のテンソル並列ランクにも同様のシャーディンググループとレプリケーショングループがあります。
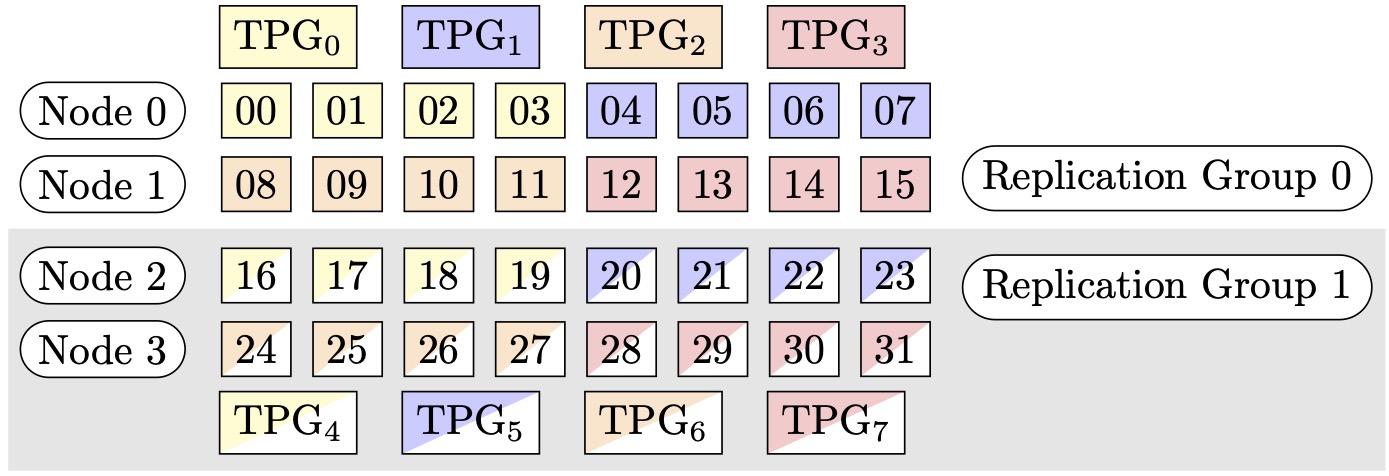
図 1: (ノード、シャーディングデータ並列度、テンソル並列度) = (4、4、4) のテンソル並列処理グループ。各四角形は、0 ~ 31 のインデックスを持つ GPU を表しています。これらの GPU が、TPG7 ~ TPG0 のテンソル並列処理グループを形成しています。レプリケーショングループは ({TPG0、TPG4}、{TPG1、TPG5}、{TPG2、TPG6}、{TPG3、TPG7}) です。各レプリケーショングループペアは同じ色ですが、塗りつぶし方が異なります。
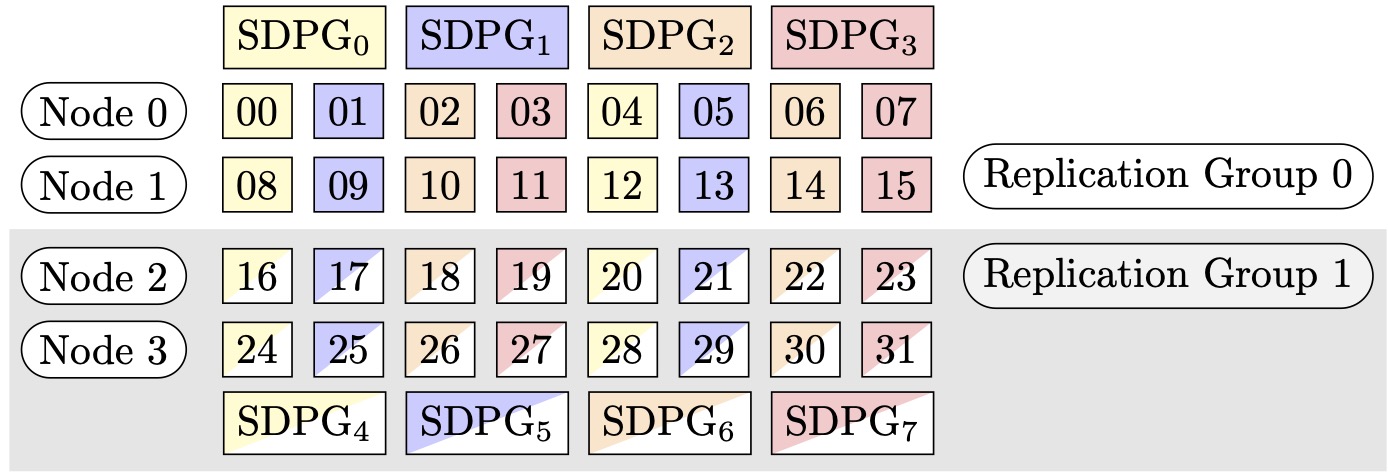
図 2: (ノード、シャーディングデータ並列度、テンソル並列度) = (4、4、4) のシャーディングデータ並列処理グループ。各四角形は、0 ~ 31 のインデックスを持つ GPU を表しています。これらの GPU が、SDPG0 ~ SDPG7 のシャーディングデータ並列処理グループを形成しています。レプリケーショングループは ({SDPG0、SDPG4}、{SDPG1、SDPG5}、{SDPG2、SDPG6}、{SDPG3、SDPG7}) です。各レプリケーショングループペアは同じ色ですが、塗りつぶし方が異なります。
テンソル並列処理でシャーディングデータ並列処理を有効にする方法
テンソル並列処理でシャーディングデータ並列処理を使用するには、SageMaker PyTorch 推定器 クラスのオブジェクトを作成する際のdistribution の設定で sharded_data_parallel_degree と tensor_parallel_degree の両方を設定する必要があります。
また、prescaled_batch を有効化する必要があります。つまり、各 GPU が独自のデータバッチを読み取る代わりに、各テンソル並列グループは、選択したバッチサイズの結合バッチをまとめて読み取ります。実際には、データセットを GPU の数 (またはデータの並列サイズ、smp.dp_size()) に等しい部分に分割する代わりに、GPU の数を tensor_parallel_degree で割った値 (縮小データ並列サイズ、smp.rdp_size() とも呼ばれます) に等しい部分に分割します。プリスケーリングされたバッチの詳細については、SageMaker Python SDK ドキュメンテーションの「プリスケーリングされたバッチtrain_gpt_simple.py
次のコードスニペットは、前述の 例 2 のシナリオに基づいて PyTorch 推定器オブジェクトを作成する例を示しています。
mpi_options = "-verbose --mca orte_base_help_aggregate 0 " smp_parameters = { "ddp": True, "fp16": True, "prescaled_batch": True, "sharded_data_parallel_degree":4, "tensor_parallel_degree":4} pytorch_estimator = PyTorch( entry_point="your_training_script.py", role=role, instance_type="ml.p4d.24xlarge", volume_size=200, instance_count=4, sagemaker_session=sagemaker_session, py_version="py3", framework_version="1.13.1", distribution={ "smdistributed": { "modelparallel": { "enabled": True, "parameters": smp_parameters, } }, "mpi": { "enabled": True, "processes_per_host": 8, "custom_mpi_options": mpi_options, }, }, source_dir="source_directory_of_your_code", output_path=s3_output_location)
シャーディングデータ並列処理を使用する際のヒントと考慮事項
SageMaker モデル並列処理ライブラリのシャーディングデータ並列処理を使用するときは、次の点を考慮してください。
-
シャーディングデータ並列処理は FP16 トレーニングと互換性があります。FP16 トレーニングを実行するには、「モデル並列処理による FP16 トレーニング」のセクションを参照してください。
-
シャーディングデータ並列処理はテンソル並列処理と互換性があります。テンソル並列処理でシャーディングデータ並列処理を使用する場合に考慮する必要がある項目は次のとおりです。
-
テンソル並列処理とシャーディングデータ並列処理を一緒に使用すると、埋め込み層もテンソル並列グループ全体に自動分散されます。つまり、
distribute_embeddingパラメータは自動的にTrueに設定されます。テンセル並列処理の詳細については、「テンソル並列処理」を参照してください。 -
シャーディングデータ並列処理とテンソル並列処理を併用するとき、現在、分散トレーニング戦略のバックエンドとして NCCL Collectives が使用されていることに注意してください。
詳細については、「テンソル並列処理と NCCL Collectives によるシャーディングデータ並列処理」のセクションを参照してください。
-
-
現在のところ、シャーディングデータ並列処理はパイプライン並列処理やオプティマイザ状態シャーディングとは互換性がありません。シャーディングデータ並列処理を有効にするには、オプティマイザ状態のシャーディングをオフにし、パイプラインの並列度を 1 に設定します。
-
アクティベーションチェックポイント機能とアクティベーションオフロード機能はシャーディングデータ並列処理と互換性があります。
-
勾配累積でシャーディングデータ並列処理を使用するには、モデルを
smdistributed.modelparallel.torch.DistributedModelモジュールでラップするときの累積ステップ数に backward_passes_per_step引数を設定します。これにより、モデルレプリケーショングループ (シャーディンググループ) にまたがる勾配AllReduceオペレーションが勾配累積の境界で確実に行われます。 -
ライブラリのチェックポイント API、
smp.save_checkpointおよびsmp.resume_from_checkpointを使用して、シャーディングデータ並列処理でトレーニングしたモデルをチェックポイントできます。詳細については、「分散 PyTorch モデルのチェックポイント機能 (v1.10.0 以降の SageMaker モデル並列処理ライブラリ用)」を参照してください。 -
シャーディングデータ並列処理では、
delayed_parameter_initialization設定パラメータの挙動が変わります。これら 2 つの機能を同時にオンにすると、パラメータの初期化を遅らせるのではなく、モデル作成時にパラメータがすぐにシャーディング方式で初期化されるため、ランクごとに独自のパラメータのシャードが初期化されて保存されます。 -
シャーディングデータ並列処理を有効にすると、
optimizer.step()の呼び出しの実行時にライブラリが内部で勾配クリッピングを実行します。勾配クリッピングには、torch.nn.utils.clip_grad_norm_()などのユーティリティ API を使用する必要はありません。勾配クリッピングのしきい値を調整するには、「シャーディングデータ並列処理をトレーニングジョブに適用する方法」セクションに示すように、SageMaker PyTorch 推定器を作成するときに、分散パラメータ設定の sdp_gradient_clippingパラメータを使用してしきい値を設定できます。
