翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
GitHub リポジトリ
トレーニングジョブを起動するには、2 つの異なる GitHub リポジトリのファイルを使用します。
これらのリポジトリには、大規模言語モデル (LLM) トレーニングプロセスを開始、管理、カスタマイズするための重要なコンポーネントが含まれています。リポジトリのスクリプトを使用して、LLM のトレーニングジョブをセットアップして実行します。
HyperPod レシピリポジトリ
SageMaker HyperPod レシピ
-
main.py: このファイルは、クラスターまたは SageMaker トレーニングジョブにトレーニングジョブを送信するプロセスを開始するための主要なエントリポイントとして機能します。 -
launcher_scripts: このディレクトリには、さまざまな大規模言語モデル (LLM) のトレーニングプロセスを容易にするために設計された、一般的に使用されるスクリプトのコレクションが含まれています。 -
recipes_collection: このフォルダには、デベロッパーが提供する事前定義された LLM レシピのコンパイルが格納されます。ユーザーは、これらのレシピをカスタムデータと組み合わせて活用し、特定の要件に合わせた LLM モデルをトレーニングできます。
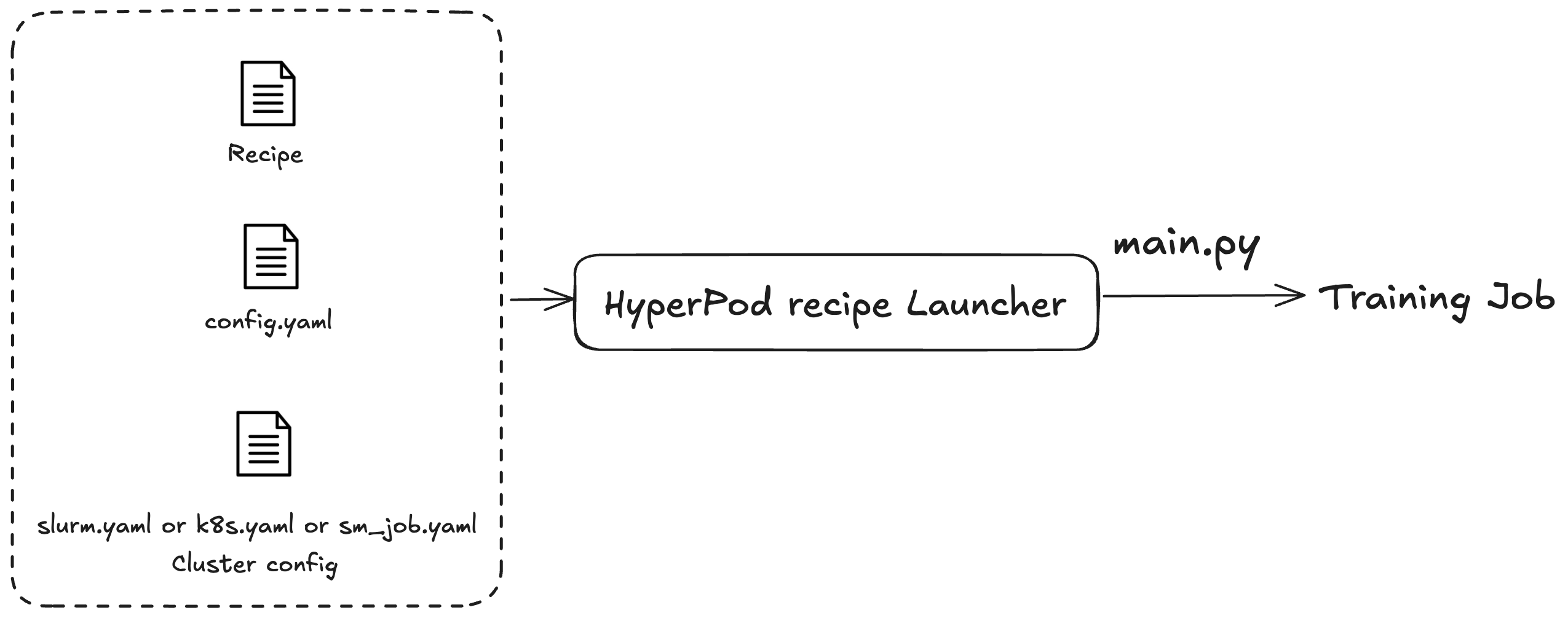
SageMaker HyperPod レシピを使用して、トレーニングジョブまたはファインチューニングジョブを起動します。使用しているクラスターを問わず、ジョブを送信するプロセスは同じです。例えば、同じスクリプトを使用して Slurm または Kubernetes クラスターにジョブを送信できます。ランチャーは、次の 3 つの設定ファイルに基づいてトレーニングジョブをディスパッチします。
-
一般設定 (
config.yaml): トレーニングジョブで使用されるデフォルトのパラメータや環境変数などの一般的な設定が含まれます。 -
クラスター設定 (クラスター): クラスターを使用するトレーニングジョブのみ。Kubernetes クラスターにトレーニングジョブを送信する場合は、ボリューム、ラベル、再起動ポリシーなどの情報を指定する必要がある場合があります。Slurm クラスターの場合、Slurm ジョブ名を指定する必要がある場合があります。すべてのパラメータは、使用している特定のクラスターに関連しています。
-
レシピ (レシピ): レシピには、モデルタイプ、シャーディング度、データセットパスなど、トレーニングジョブの設定が含まれています。例えば、Llama をトレーニングモデルとして指定し、8 台のマシンにまたがって Fully Sharded Distributed Parallel (FSDP) などのモデルまたはデータ並列処理手法を使用してトレーニングできます。トレーニングジョブに異なるチェックポイント頻度またはパスを指定することもできます。
レシピを指定したら、ランチャースクリプトを実行して、main.py エントリポイントの設定に基づいてクラスターのエンドツーエンドのトレーニングジョブを指定します。使用するレシピごとに、launch_scripts フォルダに付随するシェルスクリプトがあります。これらの例では、トレーニングジョブの送信と開始について説明します。次の図は、SageMaker HyperPod レシピランチャーが上記に基づいてトレーニングジョブをクラスターに送信する方法を示しています。現時点で SageMaker HyperPod レシピランチャーは、Nvidia NeMo Framework Launcher を基盤に構築されています。詳細については、「NeMo Launcher ガイド
HyperPod レシピアダプタリポジトリ
SageMaker HyperPod トレーニングアダプタは、トレーニングフレームワークです。これを使用して、トレーニングジョブのライフサイクル全体を管理できます。アダプタを使用して、モデルの事前トレーニングまたはファインチューニングを複数のマシンに分散できます。このアダプタは、さまざまな並列処理手法を使用してトレーニングを分散します。また、チェックポイント保存の実装と管理も処理します。詳細については、詳細設定を参照してください。
SageMaker HyperPod レシピアダプタリポジトリ
-
src: このディレクトリには、大規模言語モデル (LLM) トレーニングの実装が含まれており、モデル並列処理、混合精度トレーニング、チェックポイント管理などのさまざまな機能が含まれています。 -
examples: このフォルダは、LLM モデルをトレーニングするためのエントリポイントを作成する方法を示す例のコレクションを提供し、ユーザー向けの実用的なガイドとして機能します。
