翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
トレーニングのスケーリング
以下のセクションでは、トレーニングをスケールアップするシナリオと、 AWS リソースを使用する方法について説明します。次のいずれかの状況でトレーニングをスケールできます。
-
単一の GPU から多数の GPU へのスケーリング
-
単一インスタンスから複数インスタンスへのスケーリング
-
カスタムのトレーニングスクリプトの使用
単一の GPU から多数の GPU へのスケーリング
機械学習で使用するデータの量やモデルのサイズによって、モデルのトレーニング時間が待てないほど長くなる状況が生じることがあります。また、モデルやトレーニングデータが大きすぎるため、トレーニングがまったく機能しないことがあります。解決策の 1 つは、トレーニングに使う GPU の数を増やすことです。複数の GPU を持つインスタンスでは、8 つの GPU を持つ p3.16xlarge のように、データと処理が 8 つの GPU に分割されます。分散トレーニングライブラリを使うと、モデルのトレーニングにかかる時間内がほぼ直線的に高速化されます。1 つの GPU で p3.2xlarge を使用した場合の 1/8 を少し上回る時間しかかかりません。
| インスタンスタイプ | GPUs |
|---|---|
| p3.2xlarge | 1 |
| p3.8xlarge | 4 |
| p3.16xlarge | 8 |
| p3dn.24xlarge | 8 |
注記
SageMaker トレーニングで使用される ml インスタンスタイプは、対応する p3 インスタンスタイプと同じ数の GPU があります。例えば、ml.p3.8xlarge には p3.8xlarge - 4 と同じ数の GPU があります。
単一インスタンスから複数インスタンスへのスケーリング
トレーニングをさらにスケールする場合は、より多くのインスタンスを使用できます。ただし、インスタンスを追加する前に、より大きなインスタンスタイプを選択してください。前の表を見て、各 p3 インスタンスタイプに含まれる GPU の数を確認してください。
p3.2xlarge の 1 つの GPU から p3.8xlarge の 4 つの GPU に増やした後、さらに処理能力が必要だと判断した場合、インスタンス数を増やす前に p3.16xlarge を選択すると、パフォーマンスが向上し、コストが低くなる可能性があります。使うライブラリによっては、トレーニングを 1 つのインスタンスで維持すると、複数のインスタンスを使うシナリオよりもパフォーマンスが向上し、コストが低くなります。
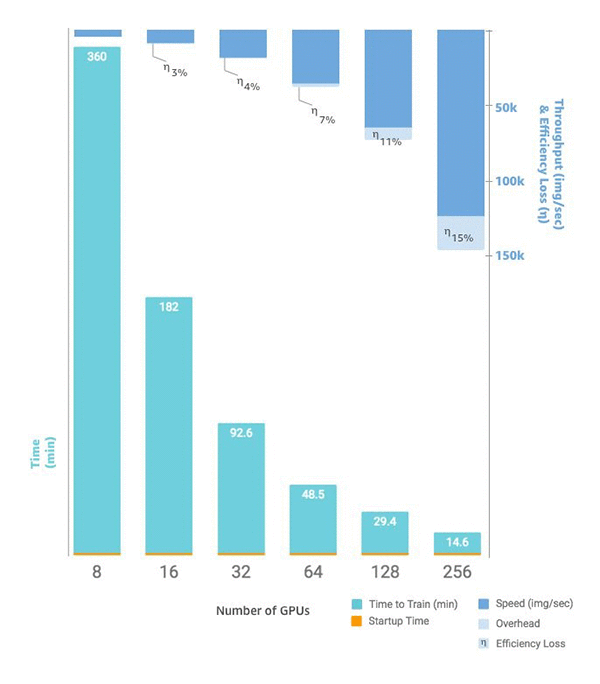
インスタンス数をスケールする準備ができたら、SageMaker AI Python SDK の estimator 関数を使って instance_count を設定することでこれを行うことができます。例えば、instance_type = p3.16xlarge と instance_count =
2 を設定すると、1 つの p3.16xlarge 上の 8 つの GPU の代わりに、2 つの同じインスタンスにまたがって 16 の GPU を持つことができます。次のグラフは、1 つのインスタンスに 8 つの GPU がある状態から
カスタムトレーニングスクリプト
SageMaker AI では、インスタンスと GPU の数を簡単にデプロイしてスケールできますが、選択したフレームワークによっては、データと結果の管理が非常に困難なことがあるため、外部のサポートライブラリがよく使用されます。この最も基本的な形の分散トレーニングでは、データ分散を管理するためにトレーニングスクリプトを変更する必要があります。
SageMaker AI は、Horovod や、各主要な深層学習フレームワークのネイティブな分散トレーニングの実装もサポートしています。これらのフレームワークのサンプルを使う場合は、SageMaker AI の Deep Learning Containers のコンテナガイドや、実装をデモするさまざまなサンプルノートブック
