翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
RunBooks の問題
次のセクションには、発生する可能性のある問題、検出方法、問題の解決方法に関する提案が含まれています。
インストールの問題
トピック
........................
RES をインストールした後にカスタムドメインをセットアップしたい
注記
前提条件: これらのステップを実行する前に、証明書と PrivateKey のコンテンツを Secrets Manager シークレットに保存する必要があります。
ウェブクライアントに証明書を追加する
-
external-alb ロードバランサーのリスナーにアタッチされた証明書を更新します。
-
ECEC2 Load Balancing > Load Balancer の下の AWS コンソールで RES 外部ロードバランサーに移動します。
-
命名規則 に従うロードバランサーを検索します
<env-name>-external-alb -
ロードバランサーにアタッチされているリスナーを確認します。
-
新しい証明書の詳細がアタッチされたデフォルトの SSL/TLS 証明書を持つリスナーを更新します。
-
変更内容を保存します。
-
-
クラスター設定テーブルで、次の操作を行います。
-
DynamoDB -> Tables -> でクラスター設定テーブルを見つけます
<env-name>.cluster-settings -
属性で項目を検索してフィルタリングする – 名前「key」、タイプ「string」、条件「contains」、値「external_alb」に移動します。
-
True
cluster.load_balancers.external_alb.certificates.providedに設定します。 -
の値を更新します
cluster.load_balancers.external_alb.certificates.custom_dns_name。これはウェブユーザーインターフェイスのカスタムドメイン名です。 -
の値を更新します
cluster.load_balancers.external_alb.certificates.acm_certificate_arn。これは、Amazon Certificate Manager (ACM) に保存されている対応する証明書の Amazon リソースネーム (ARN) です。
-
-
ウェブクライアント用に作成した対応する Route53 サブドメインレコードを更新して、外部 Alb ロードバランサー の DNS 名を指定します
<env-name>-external-alb。 -
SSO が環境にすでに設定されている場合は、RES ウェブポータルの全般設定 > ID プロバイダー > シングルサインオン > ステータス > 編集ボタンから、最初に使用したものと同じ入力で SSO を再設定します。
VDIs に証明書を追加する
-
シークレットに次のタグを追加して、シークレットに対して GetSecret オペレーションを実行するアクセス許可を RES アプリケーションに付与します。
-
res:EnvironmentName:<env-name> -
res:ModuleName:virtual-desktop-controller
-
-
クラスター設定テーブルで、次の操作を行います。
-
DynamoDB -> Tables -> でクラスター設定テーブルを見つけます
<env-name>.cluster-settings -
属性で項目を探索してフィルタリングする – 名前「key」、タイプ「string」、条件「contains」、値「dcv_connection_gateway」に移動します。
-
True
vdc.dcv_connection_gateway.certificate.providedに設定します。 -
の値を更新します
vdc.dcv_connection_gateway.certificate.custom_dns_name。これは VDI アクセスのカスタムドメイン名です。 -
の値を更新します
vdc.dcv_connection_gateway.certificate.certificate_secret_arn。これは、証明書の内容を保持するシークレットの ARN です。 -
の値を更新します
vdc.dcv_connection_gateway.certificate.private_key_secret_arn。これは、プライベートキーの内容を保持するシークレットの ARN です。
-
-
ゲートウェイインスタンスに使用される起動テンプレートを更新します。
-
EC2 > Auto Scaling > Auto Scaling Groups の下の AWS コンソールで Auto Scaling グループを開きます。
-
RES 環境に対応するゲートウェイの自動スケーリンググループを選択します。名前は命名規則 に従います
<env-name>-vdc-gateway-asg -
詳細セクションで起動テンプレートを見つけて開きます。
-
詳細 > アクション > テンプレートの変更 (新しいバージョンの作成) を選択します。
-
下にスクロールして詳細を表示します。
-
一番下のユーザーデータまでスクロールします。
-
CERTIFICATE_SECRET_ARNと の単語を探しますPRIVATE_KEY_SECRET_ARN。これらの値を、証明書 (ステップ 2.c を参照) およびプライベートキー (ステップ 2.d を参照) の内容を保持するシークレットに指定された ARNs で更新します。 -
Auto Scaling グループが、(Auto Scaling グループページから) 最近作成した起動テンプレートのバージョンを使用するように設定されていることを確認します。
-
-
仮想デスクトップ用に作成した対応する Route53 サブドメインレコードを更新して、外部 nlb ロードバランサーの DNS 名を指すようにします
<env-name>-external-nlb -
既存の dcv-gateway インスタンスを終了
<env-name>-vdc-gateway
........................
AWS CloudFormation スタックはWaitCondition received failed message」というメッセージで を作成できません。エラー:States.TaskFailed"
問題を特定するには、 という名前の Amazon CloudWatch ロググループを調べます<stack-name>-InstallerTasksCreateTaskDefCreateContainerLogGroup<nonce>-<nonce>。同じ名前のロググループが複数ある場合は、最初に使用可能なロググループを調べます。ログ内のエラーメッセージには、問題に関する詳細情報が表示されます。
注記
パラメータ値にスペースがないことを確認します。
........................
スタックが正常に作成された後に AWS CloudFormation E メール通知が受信されない
AWS CloudFormation スタックが正常に作成された後に E メールの招待を受信しなかった場合は、以下を確認します。
-
E メールアドレスパラメータが正しく入力されたことを確認します。
E メールアドレスが正しくないか、アクセスできない場合は、Research and Engineering Studio 環境を削除して再デプロイします。
-
インスタンスのサイクルの証拠については、Amazon EC2 コンソールを確認してください。
<envname>プレフィックスが の Amazon EC2 インスタンスが終了済みとして表示され、新しいインスタンスに置き換えられる場合、ネットワークまたは Active Directory の設定に問題がある可能性があります。 -
High AWS Performance Compute レシピをデプロイして外部リソースを作成した場合は、VPC、プライベートサブネットとパブリックサブネット、およびその他の選択したパラメータがスタックによって作成されたことを確認します。
パラメータのいずれかが正しくない場合は、RES 環境を削除して再デプロイする必要がある場合があります。詳細については、「製品のアンインストール」を参照してください。
-
独自の外部リソースを使用して製品をデプロイした場合は、ネットワークと Active Directory が予想される設定と一致していることを確認します。
インフラストラクチャインスタンスが Active Directory に正常に参加したことを確認することが重要です。のステップを試インスタンスサイクルまたは vdc-controller が失敗状態して問題を解決します。
........................
インスタンスサイクルまたは vdc-controller が失敗状態
この問題の最も可能性の高い原因は、リソース (複数可) が Active Directory に接続または参加できないことです。
問題を検証するには:
-
コマンドラインから、vdc-controller の実行中のインスタンスで SSM とのセッションを開始します。
-
sudo su -を実行します。 -
systemctl status sssdを実行します。
ステータスが非アクティブ、失敗、またはログにエラーが表示される場合、インスタンスは Active Directory に参加できませんでした。
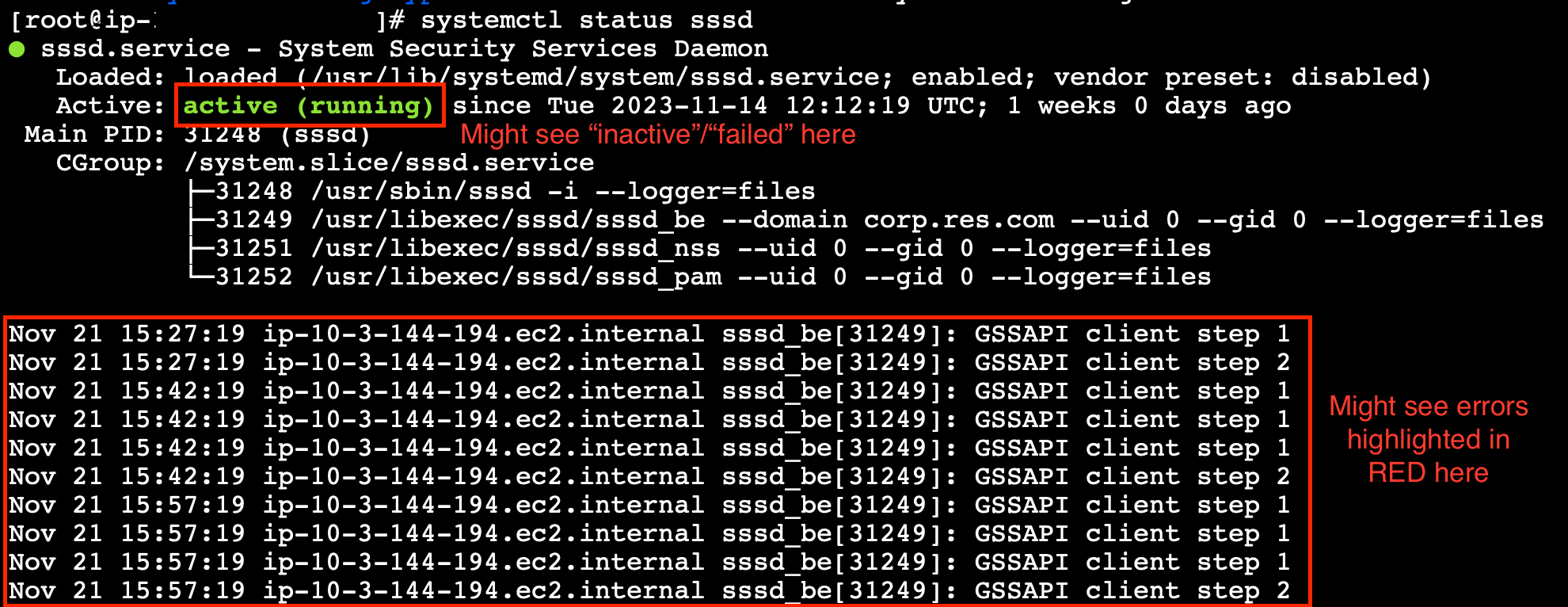
SSM エラーログ
問題を解決するには:
-
同じコマンドラインインスタンスから、
cat /root/bootstrap/logs/userdata.logを実行してログを調査します。
この問題には、3 つの根本原因のいずれかが考えられます。
ログを見直します。以下が複数回繰り返される場合、インスタンスは Active Directory に参加できませんでした。
+ local AD_AUTHORIZATION_ENTRY= + [[ -z '' ]] + [[ 0 -le 180 ]] + local SLEEP_TIME=34 + log_info '(0 of 180) waiting for AD authorization, retrying in 34 seconds ...' ++ date '+%Y-%m-%d %H:%M:%S,%3N' + echo '[2024-01-16 22:02:19,802] [INFO] (0 of 180) waiting for AD authorization, retrying in 34 seconds ...' [2024-01-16 22:02:19,802] [INFO] (0 of 180) waiting for AD authorization, retrying in 34 seconds ... + sleep 34 + (( ATTEMPT_COUNT++ ))
-
RES スタックの作成中に以下のパラメータ値が正しく入力されたことを確認します。
-
directoryservice.ldap_connection_uri
-
directoryservice.ldap_base
-
directoryservice.users.ou
-
directoryservice.groups.ou
-
directoryservice.sudoers.ou
-
directoryservice.computers.ou
-
directoryservice.name
-
-
DynamoDB テーブルの誤った値を更新します。テーブルは、テーブルの下の DynamoDB コンソールにあります。テーブル名は である必要があります
<stack name>.cluster-settings -
テーブルを更新したら、現在環境インスタンスを実行している cluster-manager と vdc-controller を削除します。Auto Scaling は、DynamoDB テーブルの最新の値を使用して新しいインスタンスを開始します。
ログが を返す場合Insufficient permissions to modify computer account、スタックの作成時に入力した ServiceAccount 名が正しくない可能性があります。
-
AWS コンソールから Secrets Manager を開きます。
-
directoryserviceServiceAccountUsernameを検索します。シークレットは である必要があります<stack name>-directoryservice-ServiceAccountUsername -
シークレットを開いて詳細ページを表示します。シークレット値 で、シークレット値の取得 を選択し、プレーンテキスト を選択します。
-
値が更新された場合は、環境の現在実行中の cluster-manager インスタンスと vdc-controller インスタンスを削除します。自動スケーリングは、Secrets Manager の最新の値を使用して新しいインスタンスを起動します。
ログに と表示される場合Invalid credentials、スタックの作成時に入力した ServiceAccount パスワードが正しくない可能性があります。
-
AWS コンソールから Secrets Manager を開きます。
-
directoryserviceServiceAccountPasswordを検索します。シークレットは である必要があります<stack name>-directoryservice-ServiceAccountPassword -
シークレットを開いて詳細ページを表示します。シークレット値 で、シークレット値の取得 を選択し、プレーンテキスト を選択します。
-
パスワードを忘れた場合、または入力したパスワードが正しいかどうかわからない場合は、Active Directory と Secrets Manager でパスワードをリセットできます。
-
でパスワードをリセットするには AWS Managed Microsoft AD:
-
AWS コンソールを開き、 に移動します AWS Directory Service。
-
RES ディレクトリのディレクトリ ID を選択し、アクションを選択します。
-
ユーザーパスワードのリセットを選択します。
-
ServiceAccount ユーザー名を入力します。
-
新しいパスワードを入力し、パスワードのリセットを選択します。
-
-
Secrets Manager でパスワードをリセットするには:
-
AWS コンソールを開き、Secrets Manager に移動します。
-
directoryserviceServiceAccountPasswordを検索します。シークレットは である必要があります<stack name>-directoryservice-ServiceAccountPassword -
シークレットを開いて詳細ページを表示します。シークレット値 で、シークレット値の取得 を選択し、プレーンテキスト を選択します。
-
[編集] を選択します。
-
ServiceAccount ユーザーの新しいパスワードを設定し、保存を選択します。
-
-
-
値を更新した場合は、環境の現在実行中の cluster-manager インスタンスと vdc-controller インスタンスを削除します。Auto Scaling は、最新の値を使用して新しいインスタンスを起動します。
........................
環境 CloudFormation スタックが依存オブジェクトエラーにより削除に失敗する
などの依存オブジェクトエラーが原因で <env-name>-vdcvdcdcvhostsecuritygroup、コンソールを使用して AWS RES が作成したサブネットまたはセキュリティグループに起動された Amazon EC2 インスタンスが原因である可能性があります。
この問題を解決するには、この方法で起動されたすべての Amazon EC2 インスタンスを検索して終了します。その後、環境の削除を再開できます。
........................
環境の作成中に CIDR ブロックパラメータでエラーが発生しました
環境を作成すると、レスポンスステータスが [FAILED] の CIDR ブロックパラメータにエラーが表示されます。
エラーの例:
Failed to update cluster prefix list: An error occurred (InvalidParameterValue) when calling the ModifyManagedPrefixList operation: The specified CIDR (52.94.133.132/24) is not valid. For example, specify a CIDR in the following form: 10.0.0.0/16.
この問題を解決するために想定される形式は x.x.x.0/24 または x.x.x.0/32 です。
........................
環境作成中の CloudFormation スタック作成の失敗
環境の作成には、一連のリソース作成オペレーションが含まれます。一部のリージョンでは、容量の問題が発生し、CloudFormation スタックの作成が失敗する可能性があります。
この場合、環境を削除し、作成を再試行します。または、別のリージョンで作成を再試行することもできます。
........................
AdDomainAdminNode CREATE_FAILED で外部リソース (デモ) スタックの作成が失敗する
デモ環境スタックの作成が次のエラーで失敗した場合、インスタンスの起動後のプロビジョニング中に Amazon EC2 パッチ適用が予期せず発生した可能性があります。
AdDomainAdminNode CREATE_FAILED Failed to receive 1 resource signal(s) within the specified duration
失敗の原因を特定するには:
-
SSM ステートマネージャーで、パッチ適用が設定されているかどうか、およびすべてのインスタンスに対して設定されているかどうかを確認します。
-
SSM RunCommand/Automation の実行履歴で、パッチ適用関連の SSM ドキュメントの実行がインスタンスの起動と一致するかどうかを確認します。
-
環境の Amazon EC2 インスタンスのログファイルで、ローカルインスタンスのログ記録を確認して、プロビジョニング中にインスタンスが再起動したかどうかを確認します。
パッチ適用が原因で問題が発生した場合は、起動から少なくとも 15 分後に RES インスタンスのパッチ適用を遅らせます。
........................
ID 管理の問題
シングルサインオン (SSO) と ID 管理のほとんどの問題は、設定ミスが原因で発生します。SSO 設定の設定については、以下を参照してください。
ID 管理に関連するその他の問題をトラブルシューティングするには、以下のトラブルシューティングトピックを参照してください。
トピック
........................
iam:PassRole を実行する権限がありません
iam:PassRole アクションを実行する権限がないというエラーが表示された場合は、ポリシーを更新して RES にロールを渡すことができるようにする必要があります。
一部の AWS サービスでは、新しいサービスロールまたはサービスにリンクされたロールを作成する代わりに、そのサービスに既存のロールを渡すことができます。そのためには、サービスにロールを渡す権限が必要です。
次の例のエラーは、marymajor という名前の IAM ユーザーがコンソールを使用して RES でアクションを実行しようとすると発生します。ただし、このアクションをサービスが実行するには、サービスロールから付与された権限が必要です。メアリーには、ロールをサービスに渡す許可がありません。
User: arn:aws:iam::123456789012:user/marymajor is not authorized to perform: iam:PassRole
この場合、Mary のポリシーを更新してメアリーに iam:PassRole アクションの実行を許可する必要があります。サポートが必要な場合は、 AWS 管理者にお問い合わせください。サインイン資格情報を提供した担当者が管理者です。
........................
自分の AWS アカウント以外のユーザーに リソースの AWS Research and Engineering Studio へのアクセスを許可したい
他のアカウントのユーザーや組織外の人が、リソースにアクセスするために使用できるロールを作成できます。ロールの引き受けを委託するユーザーを指定できます。リソースベースのポリシーまたはアクセスコントロールリスト (ACL) をサポートするサービスの場合、それらのポリシーを使用して、リソースへのアクセスを付与できます。
詳細については、以下を参照してください:
-
所有している AWS アカウント間でリソースへのアクセスを提供する方法については、IAM ユーザーガイドの「所有している別の AWS アカウントの IAM ユーザーへのアクセスを提供する」を参照してください。
-
サードパーティー AWS アカウントにリソースへのアクセスを提供する方法については、IAM ユーザーガイドの「サードパーティーが所有する AWS アカウントへのアクセスを提供する」を参照してください。
-
ID フェデレーションを通じてアクセスを提供する方法については、IAM ユーザーガイドの「外部で認証されたユーザー (ID フェデレーション) へのアクセスを提供する」を参照してください。
-
クロスアカウントアクセスにロールとリソースベースのポリシーを使用する方法の違いについては、IAM ユーザーガイドの「IAM ロールとリソースベースのポリシーの違い」を参照してください。
........................
環境にログインすると、すぐにログインページに戻ります。
この問題は、SSO 統合の設定が間違っている場合に発生します。問題を特定するには、コントローラーインスタンスログをチェックし、エラーがないか設定を確認します。
ログを確認するには:
-
CloudWatch コンソール
を開きます。 -
ロググループから、 という名前のグループを見つけます
/。<environment-name>/cluster-manager -
ロググループを開いて、ログストリームのエラーを検索します。
設定を確認するには:
-
テーブルから、 という名前のテーブルを見つけます
<environment-name>.cluster-settings -
テーブルを開き、Explore テーブル項目を選択します。
-
フィルターセクションを展開し、次の変数を入力します。
-
属性名 – キー
-
条件 – を含む
-
値 – sso
-
-
[Run] (実行) を選択します。
-
返された文字列で、SSO 設定値が正しいことを確認します。正しくない場合は、sso_enabled キーの値を False に変更します。
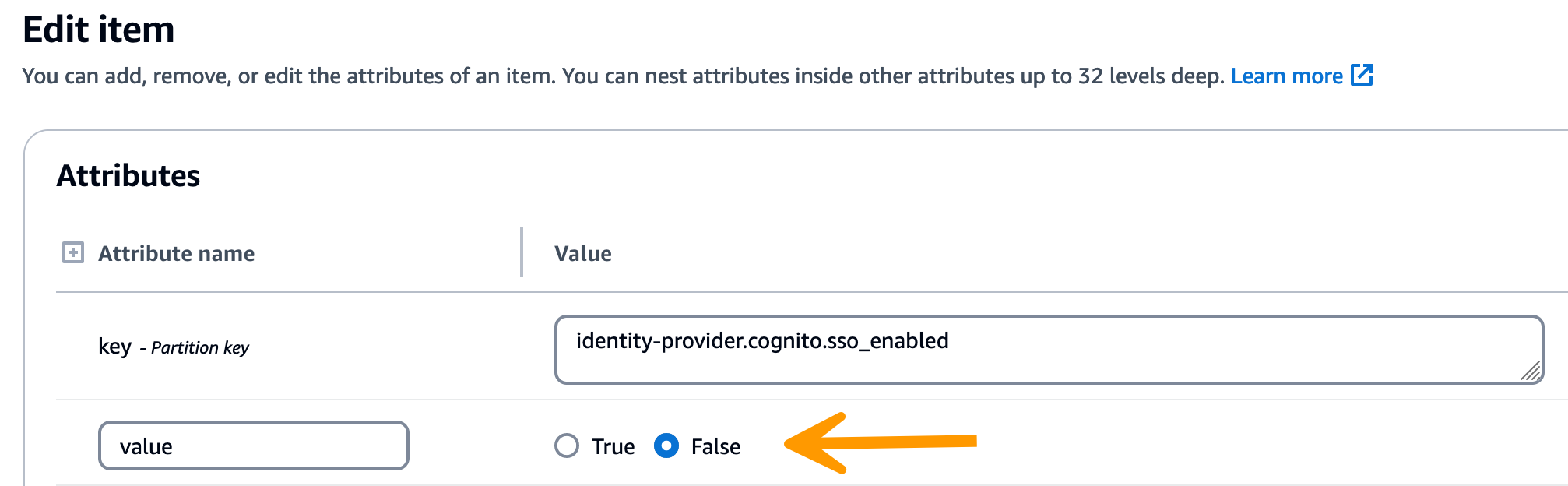
-
RES ユーザーインターフェイスに戻り、SSO を再設定します。
........................
ログイン試行時の「ユーザーが見つかりません」エラー
ユーザーが RES インターフェイスにログインしようとしたときに「ユーザーが見つかりません」というエラーが表示され、そのユーザーが Active Directory に存在する場合:
-
ユーザーが RES に存在せず、最近 AD にユーザーを追加した場合
-
ユーザーがまだ RES に同期されていない可能性があります。RES は 1 時間ごとに同期するため、次の同期後にユーザーが追加されたことを待機して確認する必要がある場合があります。すぐに同期するには、「」の手順に従いますActive Directory に追加されたが、RES に欠落しているユーザー。
-
-
ユーザーが RES に存在する場合:
-
属性マッピングが正しく設定されていることを確認します。詳細については、「シングルサインオン (SSO) 用の ID プロバイダーの設定」を参照してください。
-
SAML 件名と SAML E メールの両方がユーザーの E メールアドレスにマッピングされていることを確認します。
-
........................
Active Directory に追加されたが、RES に欠落しているユーザー
ユーザーを Active Directory に追加しても RES にない場合は、AD 同期をトリガーする必要があります。AD 同期は、AD エントリを RES 環境にインポートする Lambda 関数によって 1 時間ごとに実行されます。場合によっては、新しいユーザーまたはグループを追加した後、次の同期プロセスが実行されるまで遅延することがあります。Amazon Simple Queue Service から手動で同期を開始できます。
同期プロセスを手動で開始します。
-
Amazon SQS コンソール
を開きます。 -
キューから、 を選択します
<environment-name>-cluster-manager-tasks.fifo。 -
[メッセージの送信と受信] を選択します。
-
メッセージ本文には、次のように入力します。
{ "name": "adsync.sync-from-ad", "payload": {} } -
メッセージグループ ID には、次のように入力します。
adsync.sync-from-ad -
メッセージ重複排除 ID には、ランダムな英数字文字列を入力します。このエントリは、過去 5 分以内に行われたすべての呼び出しとは異なる必要があります。そうしないと、リクエストは無視されます。
........................
セッションの作成時にユーザーが使用できない
セッションを作成する管理者が、セッションの作成時に Active Directory に属しているユーザーが利用できない場合、ユーザーは初めてログインする必要がある場合があります。セッションはアクティブなユーザーに対してのみ作成できます。アクティブなユーザーは、少なくとも 1 回環境にログインする必要があります。
........................
CloudWatch クラスターマネージャーログのサイズ制限超過エラー
2023-10-31T18:03:12.942-07:00 ldap.SIZELIMIT_EXCEEDED: {'msgtype': 100, 'msgid': 11, 'result': 4, 'desc': 'Size limit exceeded', 'ctrls': []}
CloudWatch クラスターマネージャーログにこのエラーが表示された場合、ldap 検索が返したユーザーレコードが多すぎる可能性があります。この問題を修正するには、IDP の ldap 検索結果の制限を増やします。
........................
[Storage (ストレージ)]
トピック
........................
RES を使用してファイルシステムを作成しましたが、VDI ホストにマウントされません
ファイルシステムは、VDI ホストでマウントする前に「使用可能」状態である必要があります。以下の手順に従って、ファイルシステムが必須状態であることを確認します。
Amazon EFS
-
Amazon EFS コンソール
に移動します。 -
ファイルシステムの状態が使用可能であることを確認します。
-
ファイルシステムの状態が使用可能でない場合は、VDI ホストを起動する前に待ちます。
Amazon FSx ONTAP
-
Amazon FSx コンソール
に移動します。 -
ステータスが使用可能であることを確認します。
-
Status が使用可能でない場合は、VDI ホストを起動するまで待ちます。
........................
RES を介してファイルシステムをオンボードしたが、VDI ホストにマウントされない
RES にオンボードされるファイルシステムには、VDI ホストがファイルシステムをマウントできるように、必要なセキュリティグループルールが設定されている必要があります。これらのファイルシステムは RES の外部で作成されるため、RES は関連するセキュリティグループルールを管理しません。
オンボードされたファイルシステムに関連付けられたセキュリティグループは、次のインバウンドトラフィックを許可する必要があります。
Linux " ホストからの NFS トラフィック (ポート: 2049)
Windows " ホストからの SMB トラフィック (ポート: 445)
........................
VDI ホストから読み書きできない
ONTAP は、ボリュームの UNIX、NTFS、MIXED セキュリティスタイルをサポートしています。セキュリティスタイルは、ONTAP がデータアクセスを制御するために使用するアクセス許可のタイプと、これらのアクセス許可を変更できるクライアントタイプを決定します。
たとえば、ボリュームが UNIX セキュリティスタイルを使用している場合でも、ONTAP のマルチプロトコル特性により、SMB クライアントは引き続きデータにアクセスできます (ただし、適切に認証および認可される場合に限ります)。ただし、ONTAP は UNIX クライアントのみがネイティブツールを使用して変更できる UNIX アクセス許可を使用します。
アクセス許可処理のユースケースの例
Linux ワークロードでの UNIX スタイルのボリュームの使用
アクセス許可は、他のユーザーの sudoer で設定できます。たとえば、次の例では、 /<project-name> ディレクトリに対する<group-ID>完全な読み取り/書き込みアクセス許可のすべてのメンバーに付与します。
sudo chown root:<group-ID>/<project-name>sudo chmod 770 /<project-name>
Linux および Windows ワークロードでの NTFS スタイルのボリュームの使用
共有アクセス許可は、特定のフォルダの共有プロパティを使用して設定できます。たとえば、ユーザーuser_01とフォルダ がある場合myfolder、Full Control、、Changeまたは のアクセス許可Readを Allowまたは に設定できますDeny。
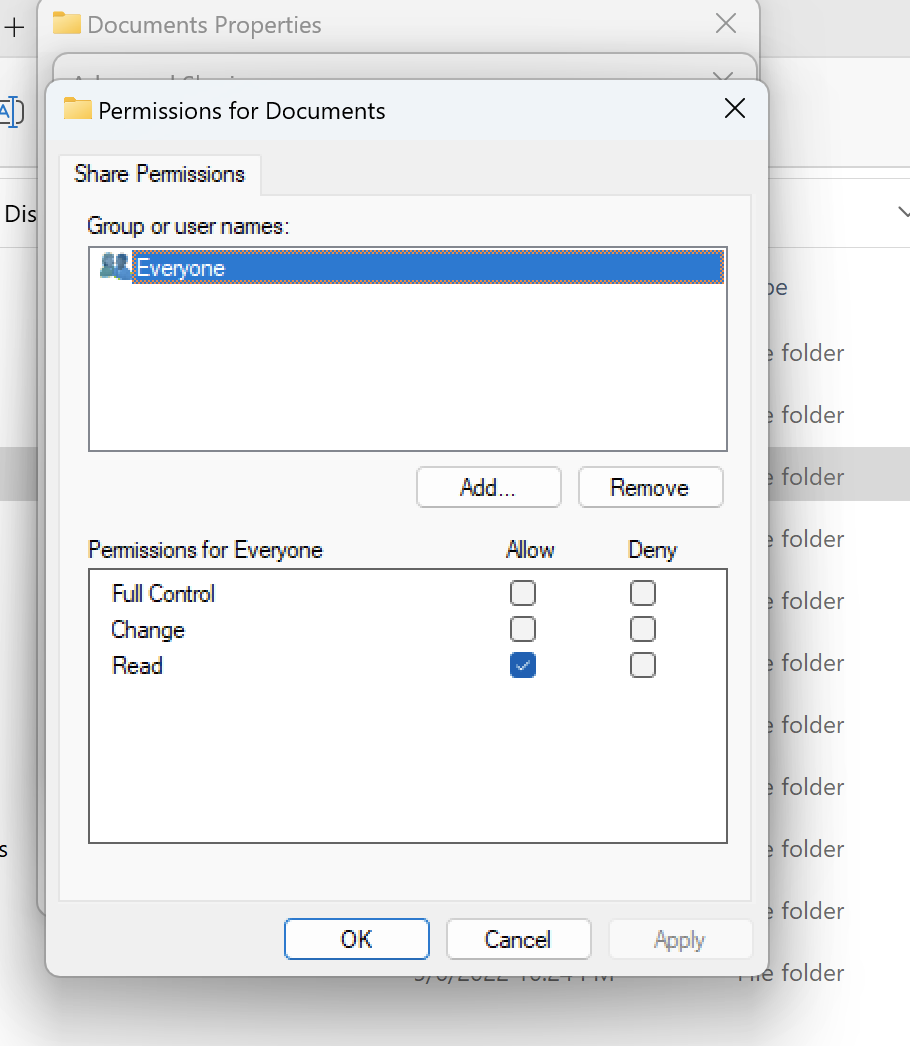
Linux クライアントと Windows クライアントの両方でボリュームを使用する場合は、Linux ユーザー名を同じユーザー名に domain\username の NetBIOS ドメイン名形式に関連付ける名前マッピングを SVM に設定する必要があります。これは、Linux ユーザーと Windows ユーザーの間で変換するために必要です。リファレンスについては、「Amazon FSx for NetApp ONTAP によるマルチプロトコルワークロードの有効化
........................
RES から Amazon FSx for NetApp ONTAP を作成しましたが、ドメインに参加していません
現在、RES コンソールから Amazon FSx for NetApp ONTAP を作成すると、ファイルシステムはプロビジョニングされますが、ドメインには参加しません。作成した ONTAP ファイルシステム SVM をドメインに結合するには、「Microsoft Active Directory SVMs の結合」を参照して、Amazon FSx コンソール
ドメインに結合したら、クラスター設定 DynamoDB テーブルで SMB DNS 設定キーを編集します。
-
Amazon DynamoDB コンソール
に移動します。 -
テーブルを選択し、 を選択します
<stack-name>-cluster-settings。 -
「Explore table items」で、フィルターを展開し、次のフィルターを入力します。
属性名 - キー
条件 - に等しい
-
値 -
shared-storage.<file-system-name>.fsx_netapp_ontap.svm.smb_dns
-
返された項目を選択し、次にアクション、編集項目を選択します。
-
以前にコピーした SMB DNS 名で値を更新します。
-
[保存して閉じる] を選択します。
さらに、ファイルシステムに関連付けられたセキュリティグループが、Amazon VPC によるファイルシステムアクセスコントロールで推奨されているトラフィックを許可していることを確認します。ファイルシステムを使用する新しい VDI ホストは、ドメインに参加している SVM とファイルシステムをマウントできるようになりました。
または、RES Onboard File System 機能を使用してドメインに既に参加している既存のファイルシステムをオンボードすることもできます。環境管理からファイルシステム、オンボードファイルシステムを選択します。
........................
スナップショット
........................
スナップショットのステータスが Failed である
RES スナップショットページで、スナップショットのステータスが Failed の場合、エラーが発生した時間、クラスターマネージャーの Amazon CloudWatch ロググループに移動することで原因を特定できます。
[2023-11-19 03:39:20,208] [INFO] [snapshots-service] creating snapshot in S3 Bucket: asdf at path s31 [2023-11-19 03:39:20,381] [ERROR] [snapshots-service] An error occurred while creating the snapshot: An error occurred (TableNotFoundException) when calling the UpdateContinuousBackups operation: Table not found: res-demo.accounts.sequence-config
........................
スナップショットは、テーブルをインポートできなかったことを示すログとともに適用されません。
以前の env から取得したスナップショットが新しい env に適用されない場合は、クラスターマネージャーの CloudWatch ログを調べて問題を特定します。必要なテーブルクラウドがインポートされないことが問題で言及されている場合は、スナップショットが有効な状態であることを確認します。
-
metadata.json ファイルをダウンロードし、さまざまなテーブルの ExportStatus のステータスが COMPLETED であることを確認します。さまざまなテーブルに
ExportManifestフィールドが設定されていることを確認します。上記のフィールドセットが見つからない場合、スナップショットは無効な状態であり、スナップショットの適用機能では使用できません。 -
スナップショットの作成を開始したら、RES でスナップショットのステータスが COMPLETED になっていることを確認します。スナップショットの作成プロセスには最大 5~10 分かかります。スナップショット管理ページを再ロードまたは再アクセスして、スナップショットが正常に作成されたことを確認します。これにより、作成されたスナップショットが有効な状態になります。
........................
インフラストラクチャ
........................
正常なインスタンスがないロードバランサーターゲットグループ
サーバーエラーメッセージなどの問題が UI に表示される場合、またはデスクトップセッションが接続できない場合、インフラストラクチャの Amazon EC2 インスタンスに問題がある可能性があります。
問題の原因を特定する方法は、まず Amazon EC2 コンソールで、繰り返し終了し、新しいインスタンスに置き換えられていると思われる Amazon EC2 インスタンスがないかを確認することです。その場合は、Amazon CloudWatch logsをチェックして原因を特定できます。
もう 1 つの方法は、システム内のロードバランサーを確認することです。システムに問題がある可能性があることを示すのは、Amazon EC2 コンソールで見つかったロードバランサーに、登録された正常なインスタンスが表示されない場合です。
通常の外観の例を以下に示します。
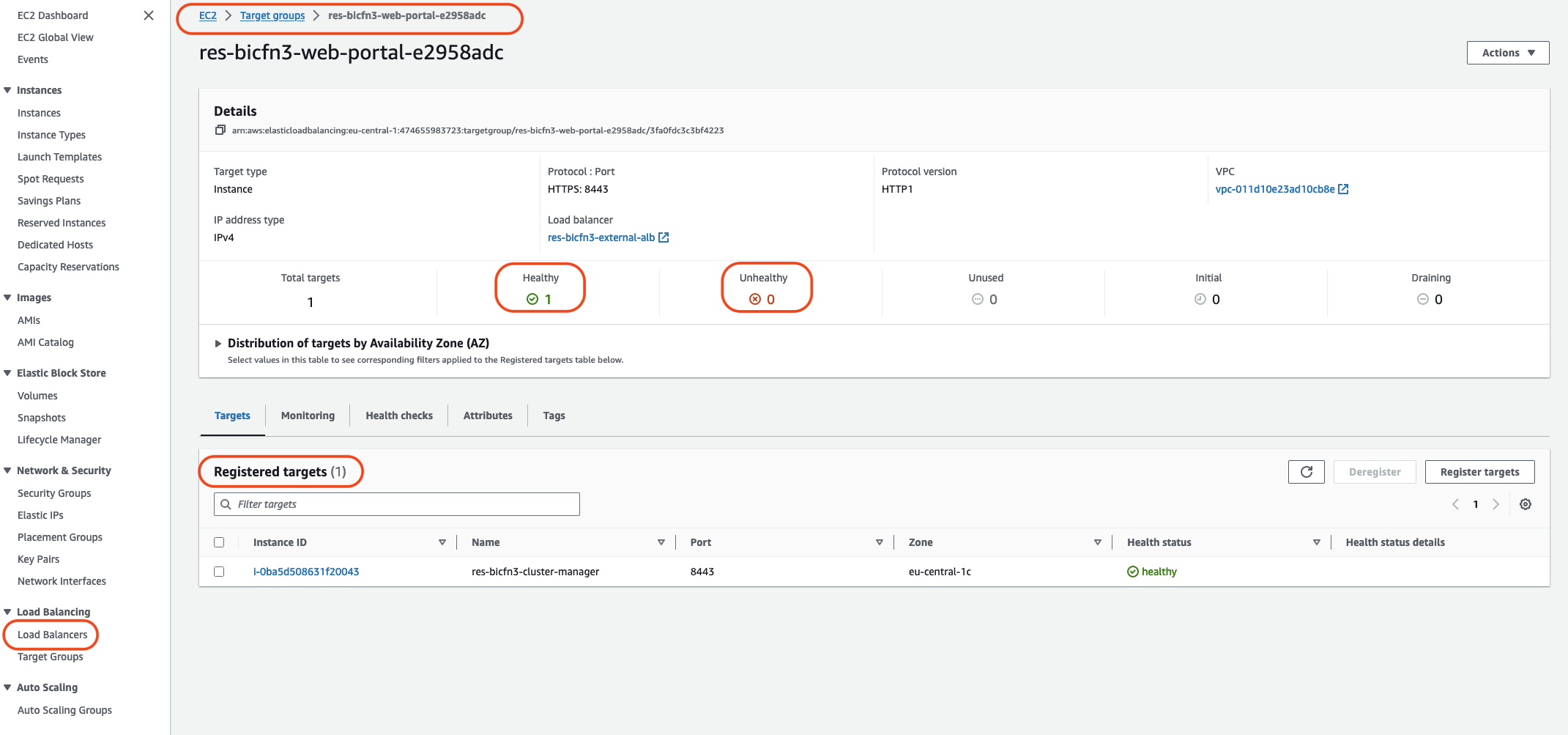
Healthy エントリが 0 の場合、リクエストを処理できる Amazon EC2 インスタンスがないことを示します。
Unhealthy エントリが 0 以外の場合は、Amazon EC2 インスタンスが循環している可能性があります。これは、インストールされているアプリケーションソフトウェアがヘルスチェックに合格していないことが原因である可能性があります。
Healthy エントリと Unhealthy エントリの両方が 0 の場合、ネットワークの設定ミスの可能性を示します。たとえば、パブリックサブネットとプライベートサブネットには、対応する AZs がない場合があります。この状態が発生すると、ネットワーク状態が存在することを示す追加のテキストがコンソールに表示される場合があります。
........................
仮想デスクトップの起動
トピック
........................
以前に動作していた仮想デスクトップが正常に接続できなくなりました
デスクトップ接続が閉じられたり、接続できなくなったりすると、基盤となる Amazon EC2 インスタンスが失敗するか、Amazon EC2 インスタンスが RES 環境の外部で終了または停止されたことが原因である可能性があります。管理者 UI のステータスは、準備完了状態を引き続き表示する場合がありますが、接続の試行は失敗します。
Amazon EC2 コンソールを使用して、インスタンスが終了または停止されたかどうかを判断する必要があります。停止した場合は、もう一度開始してみてください。状態が終了した場合は、別のデスクトップを作成する必要があります。ユーザーのホームディレクトリに保存されたデータは、新しいインスタンスの起動時に引き続き使用できます。
以前に失敗したインスタンスが管理者 UI にまだ表示されている場合は、管理者 UI を使用して終了する必要がある場合があります。
........................
5 つの仮想デスクトップしか起動できない
ユーザーが起動できる仮想デスクトップの数のデフォルトの制限は 5 です。これは、次のように管理者 UI を使用して管理者が変更できます。
デスクトップ設定に移動します。
Server タブを選択します。
DCV セッションパネルで、右側の編集アイコンをクリックします。
ユーザーあたりの許可されたセッションの値を、必要な新しい値に変更します。
[Submit] を選択してください。
ページを更新して、新しい設定が設定されていることを確認します。
........................
デスクトップ Windows の接続試行は「接続が閉じられました。トランスポートエラー"
Windows デスクトップ接続が UI エラー「接続が閉じられました。トランスポートエラー」。Windows インスタンスでの証明書の作成に関連する DCV サーバーソフトウェアの問題が原因である可能性があります。
Amazon CloudWatch ロググループは、次のようなメッセージで接続試行エラーをログに記録する<envname>/vdc/dcv-connection-gateway場合があります。
Nov 24 20:24:27.631 DEBUG HTTP:Splicer Connection{id=9}: Websocket{session_id="1291e75f-7816-48d9-bbb2-7371b3b911cd"}: Resolver lookup{client_ip=Some(52.94.36.19) session_id="1291e75f-7816-48d9-bbb2-7371b3b911cd" protocol_type=WebSocket extension_data=None}:NoStrictCertVerification: Additional stack certificate (0): [s/n: 0E9E9C4DE7194B37687DC4D2C0F5E94AF0DD57E] Nov 24 20:25:15.384 INFO HTTP:Splicer Connection{id=21}:Websocket{ session_id="d1d35954-f29d-4b3f-8c23-6a53303ebc3f"}: Connection initiated error: unreachable, server io error Custom { kind: InvalidData, error: General("Invalid certificate: certificate has expired (code: 10)") } Nov 24 20:25:15.384 WARN HTTP:Splicer Connection{id=21}: Websocket{session_id="d1d35954-f29d-4b3f-8c23-6a53303ebc3f"}: Error in websocket connection: Server unreachable: Server error: IO error: unexpected error: Invalid certificate: certificate has expired (code: 10)
この場合、SSM セッションマネージャーを使用して Windows インスタンスへの接続を開き、次の 2 つの証明書関連ファイルを削除することが解決される可能性があります。
PS C:\Windows\system32\config\systemprofile\AppData\Local\NICE\dcv> dir Directory: C:\Windows\system32\config\systemprofile\AppData\Local\NICE\dcv Mode LastWriteTime Length Name ---- ------------- ------ ---- -a---- 8/4/2022 12:59 PM 1704 dcv.key -a---- 8/4/2022 12:59 PM 1265 dcv.pem
ファイルは自動的に再作成され、それ以降の接続試行が成功する可能性があります。
この方法で問題を解決し、Windows デスクトップの新しい起動で同じエラーが発生した場合は、ソフトウェアスタックの作成 関数を使用して、再生成された証明書ファイルを含む固定インスタンスの新しい Windows ソフトウェアスタックを作成します。これにより、正常な起動と接続に使用できる Windows ソフトウェアスタックが生成されます。
........................
VDIsプロビジョニング状態でスタックする
デスクトップ起動が管理者 UI のプロビジョニング状態のままである場合は、いくつかの理由が考えられます。
原因を特定するには、デスクトップインスタンスのログファイルを調べ、問題の原因となっている可能性のあるエラーを探します。このドキュメントには、ログファイルと Amazon CloudWatch ロググループのリストが含まれており、有用なログおよびイベント情報ソースというラベルが付いたセクションに関連情報が含まれています。
この問題の潜在的な原因は次のとおりです。
-
使用されている AMI ID は software-stack として登録されていますが、RES ではサポートされていません。
Amazon マシンイメージ (AMI) に必要な設定またはツールがないため、ブートストラッププロビジョニングスクリプトを完了できませんでした。Linux インスタンスなど、インスタンス
/root/bootstrap/logs/のログファイルには、これに関する有用な情報が含まれている場合があります。 AWS Marketplace から取得した AMIs ID は、RES デスクトップインスタンスでは機能しない場合があります。サポートされているかどうかを確認するには、テストが必要です。 -
ユーザーデータスクリプトは、Windows 仮想デスクトップインスタンスがカスタム AMI から起動されたときに実行されません。
デフォルトでは、ユーザーデータスクリプトは Amazon EC2 インスタンスの起動時に 1 回実行されます。既存の仮想デスクトップインスタンスから AMI を作成し、その AMI にソフトウェアスタックを登録して、このソフトウェアスタックで別の仮想デスクトップを起動しようとすると、ユーザーデータスクリプトは新しい仮想デスクトップインスタンスでは実行されません。
この問題を解決するには、AMI の作成に使用した元の仮想デスクトップインスタンスで管理者として PowerShell コマンドウィンドウを開き、次のコマンドを実行します。
C:\ProgramData\Amazon\EC2-Windows\Launch\Scripts\InitializeInstance.ps1 –Schedule次に、インスタンスから新しい AMI を作成します。新しい AMI を使用してソフトウェアスタックを登録し、後で新しい仮想デスクトップを起動できます。プロビジョニング状態のままのインスタンスで同じコマンドを実行し、インスタンスを再起動して仮想デスクトップセッションを修正することもできますが、設定ミスのある AMI から別の仮想デスクトップを起動すると、同じ問題が再度発生することに注意してください。
........................
起動後に VDIsがエラー状態になる
- 考えられる問題 1: ホームファイルシステムに、異なる POSIX アクセス許可を持つユーザーのディレクトリがあります。
-
これは、次のシナリオが当てはまる場合に直面する問題である可能性があります。
-
デプロイされた RES バージョンは 2024.01 以降です。
-
RES スタックのデプロイ中に、 の 属性が に設定
EnableLdapIDMappingされましたTrue。 -
RES スタックのデプロイ時に指定されたホームファイルシステムは、RES 2024.01 より前のバージョンで使用されたか、 を
EnableLdapIDMappingに設定して以前の環境で使用されましたFalse。
解決手順: ファイルシステム内のユーザーディレクトリを削除します。
-
クラスターマネージャーホストへの SSM。
-
cd /home. -
ls- は、admin1、.. などのユーザー名に一致するディレクトリ名を持つディレクトリを一覧表示する必要がありますadmin2。 -
ディレクトリ を削除します
sudo rm -r 'dir_name'。ssm-user ディレクトリと ec2-user ディレクトリを削除しないでください。 -
ユーザーが新しい env に既に同期されている場合は、ユーザーの DDB テーブルからユーザーの を削除します (clusteradmin を除く)。
-
AD 同期の開始 - クラスターマネージャー Amazon EC2
sudo /opt/idea/python/3.9.16/bin/resctl ldap sync-from-adで実行します。 -
RES ウェブページから
Error状態の VDI インスタンスを再起動します。VDI が約 20 分でReady状態に移行することを確認します。
-
........................
仮想デスクトップコンポーネント
........................
Amazon EC2 インスタンスがコンソールで終了を繰り返し表示している
インフラストラクチャインスタンスが Amazon EC2 コンソールで終了済みとして繰り返し表示される場合、原因はその設定に関連しており、インフラストラクチャインスタンスタイプによって異なります。以下に、原因を特定する方法を示します。
Amazon EC2 コンソールで vdc-controller インスタンスが終了状態が繰り返し表示される場合は、シークレットタグが正しくない可能性があります。RES によって維持されるシークレットには、インフラストラクチャの Amazon EC2 インスタンスにアタッチされた IAM アクセスコントロールポリシーの一部として使用されるタグがあります。vdc-controller がサイクルしていて、CloudWatch ロググループに次のエラーが表示された場合、シークレットが正しくタグ付けされていない可能性があります。シークレットには、次のタグを付ける必要があることに注意してください。
{ "res:EnvironmentName": "<envname>" # e.g. "res-demo" "res:ModuleName": "virtual-desktop-controller" }
このエラーの Amazon CloudWatch ログメッセージは、次のように表示されます。
An error occurred (AccessDeniedException) when calling the GetSecretValue operation: User: arn:aws:sts::160215750999:assumed-role/<envname>-vdc-gateway-role-us-east-1/i-043f76a2677f373d0 is not authorized to perform: secretsmanager:GetSecretValue on resource: arn:aws:secretsmanager:us-east-1:160215750999:secret:Certificate-res-bi-Certs-5W9SPUXF08IB-F1sNRv because no identity-based policy allows the secretsmanager:GetSecretValue action
Amazon EC2 インスタンスのタグをチェックし、それらが上記のリストと一致することを確認します。
........................
AD への参加に失敗したために vdc-controller インスタンスがサイクルしています / eVDI モジュールが失敗した API ヘルスチェックを表示
eVDI モジュールがヘルスチェックに失敗した場合、環境ステータスセクションに以下が表示されます。
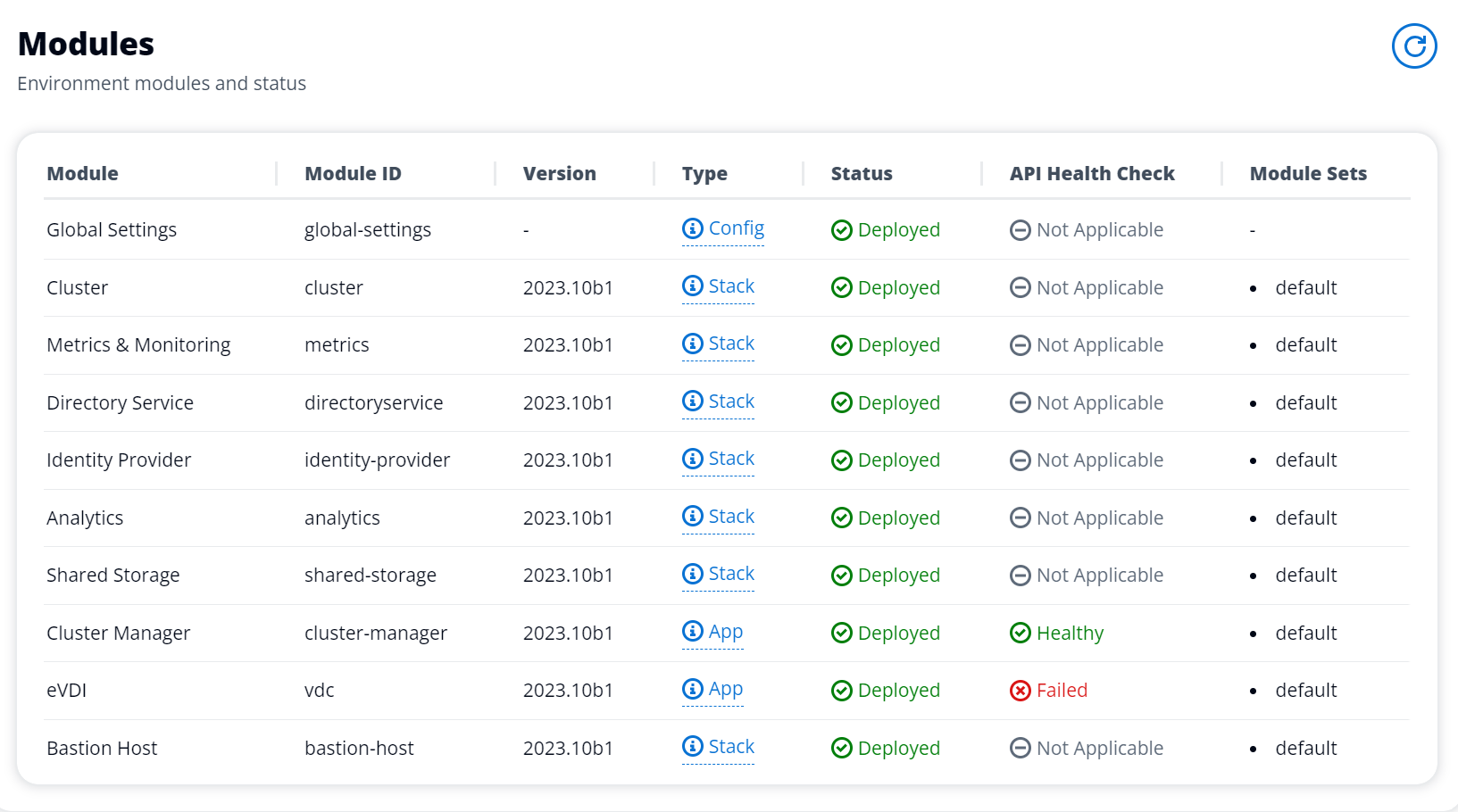
この場合、デバッグの一般的なパスは、クラスターマネージャーの CloudWatch<env-name>/cluster-manager。)
考えられる問題:
-
ログにテキスト が含まれている場合は
Insufficient permissions、res スタックの作成時に指定された ServiceAccount ユーザー名のスペルが正しいことを確認してください。ログ行の例:
Insufficient permissions to modify computer account: CN=IDEA-586BD25043,OU=Computers,OU=RES,OU=CORP,DC=corp,DC=res,DC=com: 000020E7: AtrErr: DSID-03153943, #1: 0: 000020E7: DSID-03153943, problem 1005 (CONSTRAINT_ATT_TYPE), data 0, Att 90008 (userAccountControl):len 4 >> 432 ms - request will be retried in 30 seconds-
SecretsManager コンソール
から、RES デプロイ中に提供される ServiceAccount ユーザー名にアクセスできます。Secrets Manager で対応するシークレットを検索し、プレーンテキストの取得を選択します。ユーザー名が正しくない場合は、編集を選択してシークレット値を更新します。現在の cluster-manager インスタンスと vdc-controller インスタンスを終了します。新しいインスタンスは安定した状態になります。 -
提供された外部リソーススタックによって作成されたリソースを使用している場合、ユーザー名は「ServiceAccount」である必要があります。RES のデプロイ中に
DisableADJoinパラメータが False に設定されている場合は、ServiceAccount」ユーザーに AD でコンピュータオブジェクトを作成するアクセス許可があることを確認します。
-
-
使用したユーザー名が正しいが、ログにテキスト が含まれている場合
Invalid credentials、入力したパスワードが間違っているか、有効期限が切れている可能性があります。ログ行の例:
{'msgtype': 97, 'msgid': 1, 'result': 49, 'desc': 'Invalid credentials', 'ctrls': [], 'info': '80090308: LdapErr: DSID-0C090569, comment: AcceptSecurityContext error, data 532, v4563'}-
環境の作成時に入力したパスワードは、Secrets Manager コンソールにパスワードを保存するシーク
レットにアクセスして読み取ることができます。シークレット ( など <env_name>directoryserviceServiceAccountPassword) を選択し、プレーンテキストの取得を選択します。 -
シークレットのパスワードが正しくない場合は、編集を選択してシークレットの値を更新します。現在の cluster-manager インスタンスと vdc-controller インスタンスを終了します。新しいインスタンスは更新されたパスワードを使用し、安定した状態になります。
-
パスワードが正しい場合、接続された Active Directory でパスワードの有効期限が切れている可能性があります。まず Active Directory でパスワードをリセットしてから、シークレットを更新する必要があります。Directory Service コンソール
から Active Directory でユーザーのパスワードをリセットできます。 -
適切なディレクトリ ID を選択する
-
アクション、ユーザーパスワードのリセットを選択し、ユーザー名 (ServiceAccount」など) と新しいパスワードをフォームに入力します。
-
新しく設定したパスワードが以前のパスワードと異なる場合は、対応する Secret Manager シークレットのパスワードを更新します (例:
<env_name>directoryserviceServiceAccountPassword。 -
現在の cluster-manager インスタンスと vdc-controller インスタンスを終了します。新しいインスタンスは安定した状態になります。
-
-
........................
プロジェクトは、ソフトウェアスタックを編集して追加するときにプルダウンに表示されません
この問題は、ユーザーアカウントと AD の同期に関連する次の問題に関連している可能性があります。この問題が発生した場合は、クラスターマネージャーの Amazon CloudWatch ロググループでエラー<user-home-init> account not available yet. waiting for user to be synced「」をチェックして、原因が同じか関連しているかを判断します。
........................
cluster-manager Amazon CloudWatch ログには、「<user-home-init> アカウントはまだ利用できません。ユーザーの同期を待っています」と表示されます (アカウントはユーザー名です)。
SQS サブスクライバーは、ユーザーアカウントにアクセスできないため、ビジー状態で無限ループに陥っています。このコードは、ユーザーの同期中にユーザーのホームファイルシステムを作成しようとしたときにトリガーされます。
ユーザーアカウントにアクセスできない理由は、使用中の AD に対して RES が正しく設定されていない可能性があります。たとえば、BI/RES 環境の作成時に使用された ServiceAccountCredentialsSecretArnパラメータの値が正しくない可能性があります。
........................
ログイン試行時の Windows デスクトップに「アカウントが無効になっています。管理者にお問い合わせください」
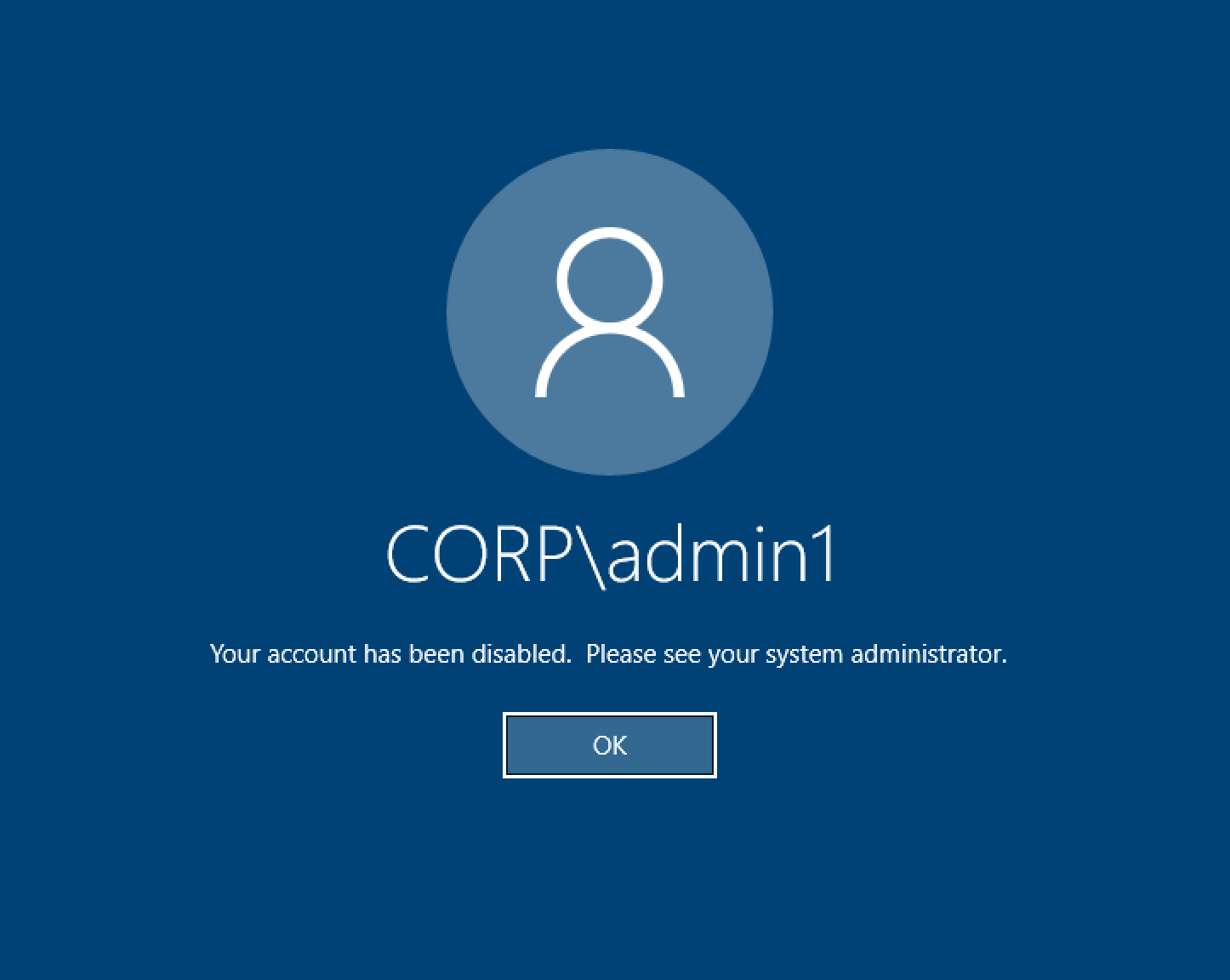
ユーザーがロックされた画面に再度ログインできない場合は、SSO 経由で正常にサインオンした後、RES 用に設定された AD でユーザーが無効になっている可能性があります。
AD でユーザーアカウントが無効になっている場合、SSO ログインは失敗します。
........................
外部/顧客の AD 設定に関する DHCP オプションの問題
独自の Active Directory "The connection has been closed. Transport error"で RES を使用するときに Windows 仮想デスクトップで というエラーが発生した場合は、dcv-connection-gateway Amazon CloudWatch ログで次のような点を確認してください。
Oct 28 00:12:30.626 INFO HTTP:Splicer Connection{id=263}: Websocket{session_id="96cffa6e-cf2e-410f-9eea-6ae8478dc08a"}: Connection initiated error: unreachable, server io error Custom { kind: Uncategorized, error: "failed to lookup address information: Name or service not known" } Oct 28 00:12:30.626 WARN HTTP:Splicer Connection{id=263}: Websocket{session_id="96cffa6e-cf2e-410f-9eea-6ae8478dc08a"}: Error in websocket connection: Server unreachable: Server error: IO error: failed to lookup address information: Name or service not known Oct 28 00:12:30.627 DEBUG HTTP:Splicer Connection{id=263}: ConnectionGuard dropped
独自の VPC の DHCP オプションに AD ドメインコントローラーを使用している場合は、以下を行う必要があります。
-
AmazonProvidedDNS を 2 つのドメインコントローラー IPs。
-
ドメイン名を ec2.internal に設定します。
以下に例を示します。この設定がない場合、RES/DCV は ip-10-0-x-xx.ec2.internal ホスト名を検索するため、Windows デスクトップはトランスポートエラー を返します。

........................
Firefox エラー MOZILLA_PKIX_ERROR_REQUIRED_TLS_FEATURE_MISSING
Firefox ウェブブラウザを使用すると、仮想デスクトップに接続しようとすると、MOZILLA_PKIX_ERROR_REQUIRED_TLS_FEATURE_MISSING というエラーメッセージが表示されることがあります。
原因は、RES ウェブサーバーが TLS + Stapling On でセットアップされているが、Stapling Validation で応答していないことです (https://support.mozilla.org/en-US/questions/1372483
これは、https://really-simple-ssl.com/mozilla_pkix_error_required_tls_feature_missing
........................
Env 削除
トピック
........................
res-xxx-cluster スタックが「DELETE_FAILED」状態で、「Role is invalid or cannot be assumed」エラーのため手動で削除できない
「res-xxx-cluster」スタックが「DELETE_FAILED」状態で、手動で削除できない場合は、次の手順を実行して削除できます。
スタックが「DELETE_FAILED」状態にある場合は、まずスタックを手動で削除してみてください。スタックの削除を確認するダイアログが表示される場合があります。[削除] を選択します。
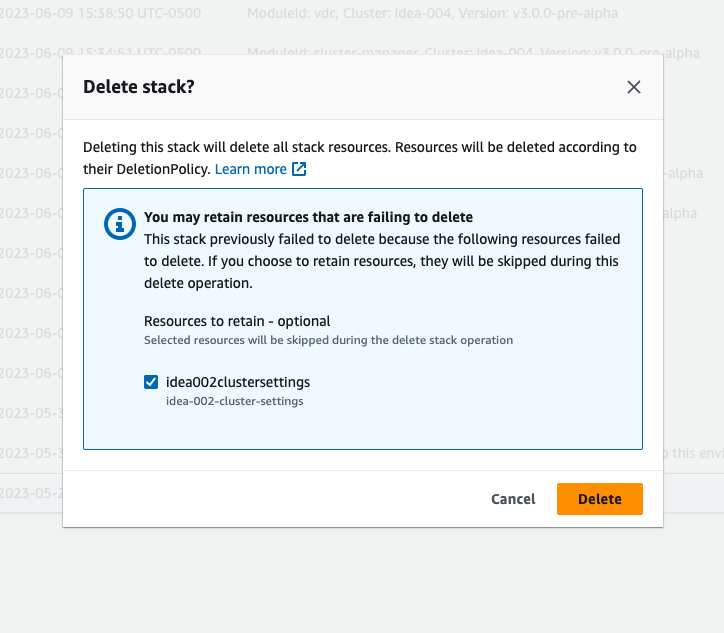
必要なスタックリソースをすべて削除しても、保持するリソースを選択するメッセージが表示されることがあります。その場合は、「保持するリソース」としてすべてのリソースを選択し、「削除」を選択します。
次のようなエラーが表示される場合があります。 Role: arn:aws:iam::... is Invalid or cannot be assumed
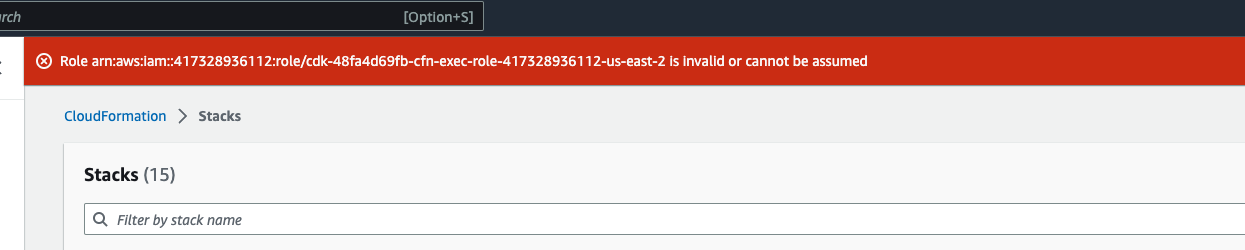
これは、スタックの削除に必要なロールが、スタックの前に最初に削除されたことを意味します。これを回避するには、ロールの名前をコピーします。IAM コンソールに移動し、次に示すようにパラメータを使用して、その名前のロールを作成します。
-
信頼されたエンティティタイプでAWS サービスを選択します。
-
ユースケース で、
Use cases for other AWS servicesを選択しますCloudFormation。
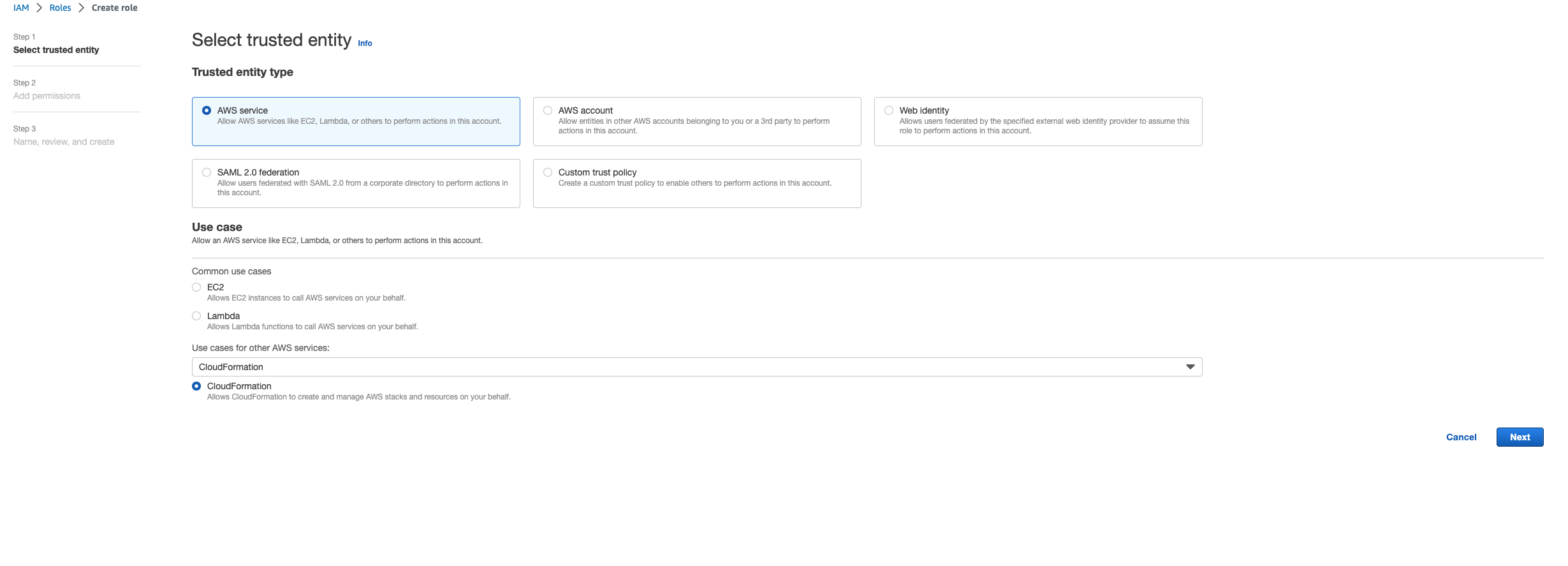
[次へ] を選択します。ロールに「」とAWSCloudFormationFullAccessAdministratorAccess「」のアクセス許可を付与してください。レビューページは次のようになります。
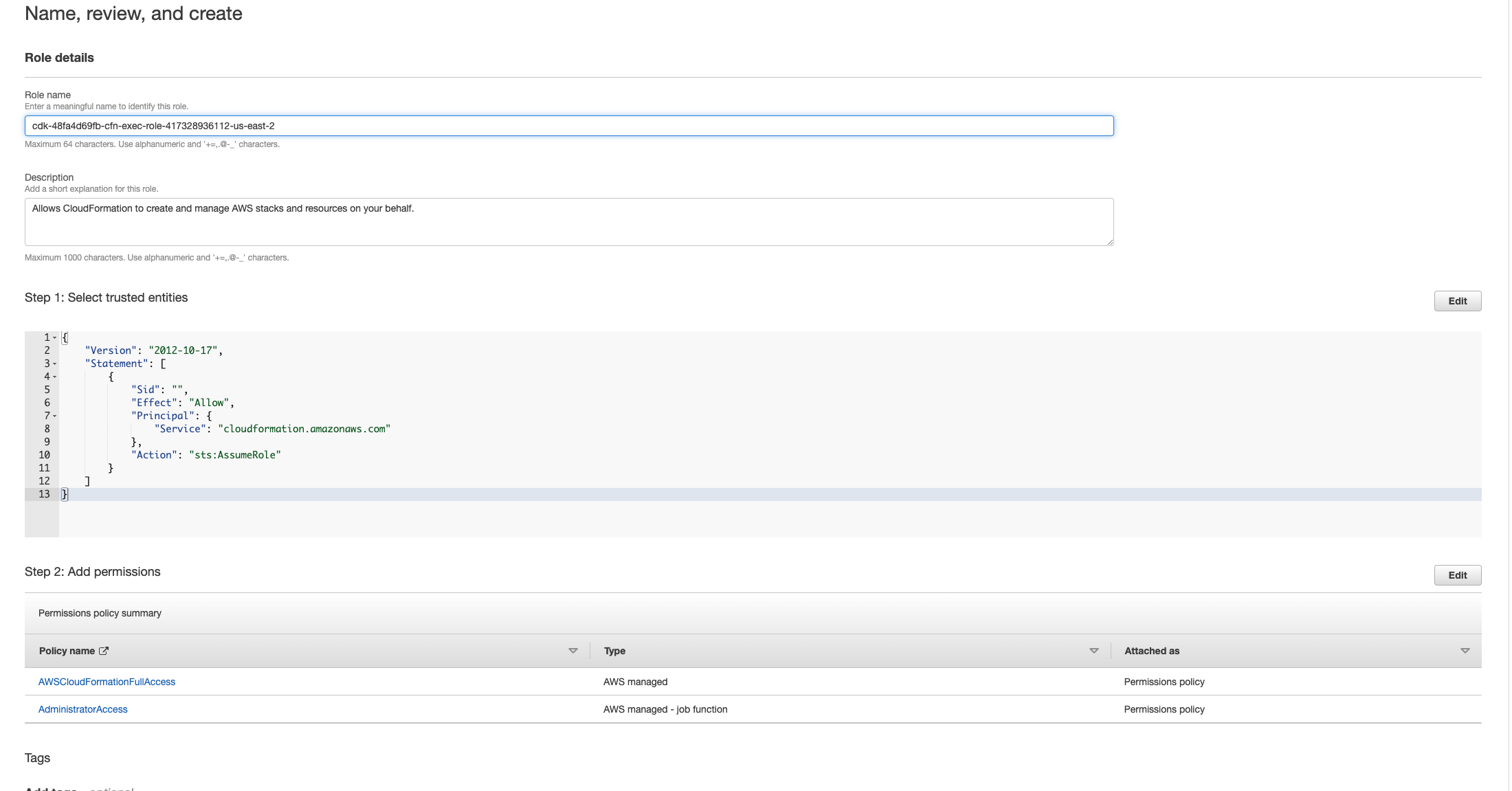
次に、CloudFormation コンソールに戻り、スタックを削除します。これで、ロールを作成した後で削除できるようになります。最後に、IAM コンソールに移動し、作成したロールを削除します。
........................
ログの収集
EC2 コンソールから EC2 インスタンスにログインする
インフラストラクチャホストログの収集
-
Cluster-manager: 次の場所からクラスターマネージャーのログを取得し、チケットにアタッチします。
-
CloudWatch ロググループ からのすべてのログ
<env-name>/cluster-manager。 -
<env-name>-cluster-managerEC2 インスタンスの/root/bootstrap/logsディレクトリにあるすべてのログ。このセクションの冒頭にあるEC2 コンソールから EC2 インスタンスにログインする」から にリンクされた手順に従って、インスタンスにログインします。
-
-
Vdc-controller: 次の場所から vdc-controller のログを取得し、チケットにアタッチします。
-
CloudWatch ロググループ からのすべてのログ
<env-name>/vdc-controller。 -
<env-name>-vdc-controllerEC2 インスタンスの/root/bootstrap/logsディレクトリにあるすべてのログ。このセクションの冒頭にあるEC2 コンソールから EC2 インスタンスにログインする」から にリンクされた手順に従って、インスタンスにログインします。
-
ログを簡単に取得する方法の 1 つは、 Linux EC2 インスタンスからのログのダウンロードセクションの指示に従うことです。モジュール名はインスタンス名になります。
VDI ログの収集
- 対応する Amazon EC2 インスタンスを特定する
-
ユーザーがセッション名 で VDI を起動した場合
VDI1、Amazon EC2 コンソールのインスタンスの対応する名前は になります<env-name>-VDI1-<user name>。 - Linux VDI ログの収集
-
このセクションの冒頭にあるAmazon EC2 コンソールから EC2 インスタンスにログインする」の「」にリンクされた手順に従って、Amazon EC2 コンソールから対応する Amazon EC2 インスタンスにログインします。VDI Amazon EC2 インスタンスの
/root/bootstrap/logsおよび/var/log/dcv/ディレクトリにあるすべてのログを取得します。ログを取得する方法の 1 つは、ログを s3 にアップロードし、そこからダウンロードすることです。そのためには、次のステップに従って 1 つのディレクトリからすべてのログを取得し、アップロードします。
-
/root/bootstrap/logsディレクトリの下に dcv ログをコピーするには、次の手順に従います。sudo su - cd /root/bootstrap mkdir -p logs/dcv_logs cp -r /var/log/dcv/* logs/dcv_logs/ -
次に、次のセクション「」に記載されている手順に従ってVDI ログのダウンロードログをダウンロードします。
-
- Windows VDI ログの収集
-
このセクションの冒頭にあるAmazon EC2 コンソールから EC2 インスタンスにログインする」の「」にリンクされた手順に従って、Amazon EC2 コンソールから対応する Amazon EC2 インスタンスにログインします。VDI EC2 インスタンスの
$env:SystemDrive\Users\Administrator\RES\Bootstrap\Log\ディレクトリですべてのログを取得します。ログを取得する方法の 1 つは、ログを S3 にアップロードし、そこからダウンロードすることです。これを行うには、次のセクション「」に記載されているステップに従いますVDI ログのダウンロード。
........................
VDI ログのダウンロード
VDI EC2 インスタンスの IAM ロールを更新して S3 アクセスを許可します。
EC2 コンソールに移動し、VDI インスタンスを選択します。
使用している IAM ロールを選択します。
-
アクセス許可の追加ドロップダウンメニューのアクセス許可ポリシーセクションで、ポリシーのアタッチを選択し、AmazonS3FullAccess ポリシーを選択します。
アクセス許可を追加 を選択して、そのポリシーをアタッチします。
-
その後、VDI タイプに基づいて以下の手順に従ってログをダウンロードします。モジュール名はインスタンス名になります。
-
Linux EC2 インスタンスからのログのダウンロード Linux 用。
-
Windows EC2 インスタンスからのログのダウンロード for Windows。
-
-
最後に、ロールを編集して
AmazonS3FullAccessポリシーを削除します。
注記
すべての VDIs、 と同じ IAM ロールを使用します。 <env-name>-vdc-host-role-<region>
........................
Linux EC2 インスタンスからのログのダウンロード
ログをダウンロードする EC2 インスタンスにログインし、次のコマンドを実行してすべてのログを s3 バケットにアップロードします。
sudo su - ENV_NAME=<environment_name>REGION=<region>ACCOUNT=<aws_account_number>MODULE=<module_name>cd /root/bootstrap tar -czvf ${MODULE}_logs.tar.gz logs/ --overwrite aws s3 cp ${MODULE}_logs.tar.gz s3://${ENV_NAME}-cluster-${REGION}-${ACCOUNT}/${MODULE}_logs.tar.gz
その後、S3 コンソールに移動<environment_name>-cluster-<region>-<aws_account_number>し、名前が のバケットを選択し、以前にアップロードした<module_name>_logs.tar.gzファイルをダウンロードします。
........................
Windows EC2 インスタンスからのログのダウンロード
ログをダウンロードする EC2 インスタンスにログインし、次のコマンドを実行してすべてのログを S3 バケットにアップロードします。
$ENV_NAME="<environment_name>" $REGION="<region>" $ACCOUNT="<aws_account_number>" $MODULE="<module_name>" $logDirPath = Join-Path -Path $env:SystemDrive -ChildPath "Users\Administrator\RES\Bootstrap\Log" $zipFilePath = Join-Path -Path $env:TEMP -ChildPath "logs.zip" Remove-Item $zipFilePath Compress-Archive -Path $logDirPath -DestinationPath $zipFilePath $bucketName = "${ENV_NAME}-cluster-${REGION}-${ACCOUNT}" $keyName = "${MODULE}_logs.zip" Write-S3Object -BucketName $bucketName -Key $keyName -File $zipFilePath
その後、S3 コンソールに移動<environment_name>-cluster-<region>-<aws_account_number>し、名前が のバケットを選択し、以前にアップロードした<module_name>_logs.zipファイルをダウンロードします。
........................
WaitCondition エラーの ECS ログの収集
-
デプロイされたスタックに移動し、リソースタブを選択します。
-
Deploy → ResearchAndEngineeringStudio → Installer → Tasks → CreateTaskDef → CreateContainer → LogGroup を展開し、ロググループを選択して CloudWatch ログを開きます。
-
このロググループから最新のログを取得します。
........................
デモ環境
........................
ID プロバイダーへの認証リクエストを処理するときのデモ環境ログインエラー
問題
ログインしようとして、ID プロバイダーへの認証リクエストを処理するときに「予期しないエラー」が発生した場合、パスワードの有効期限が切れている可能性があります。これは、ログインしようとしているユーザーのパスワードまたは Active Directory サービスアカウントのいずれかです。
緩和策
-
Directory サービスコンソール
でユーザーとサービスアカウントのパスワードをリセットします。 -
Secrets Manager
のサービスアカウントのパスワードを、上記で入力した新しいパスワードと一致するように更新します。 -
Keycloak スタックの : PasswordSecret-...-RESExternal-...-DirectoryService-... with Description: Password for Microsoft Active Directory
-
for RES: res-ServiceAccountPassword-... with 説明: Active Directory サービスアカウントのパスワード
-
-
EC2 コンソール
に移動し、クラスターマネージャーインスタンスを終了します。Auto Scaling ルールは、新しいインスタンスのデプロイを自動的にトリガーします。
........................
デモスタックのキークロークが機能しない
問題
キークロークサーバーがクラッシュし、サーバーを再起動したときにインスタンスの IP が変更された場合、キークロークが壊れた可能性があります。RES ポータルのログインページがロードに失敗するか、ロード状態でスタックし、解決されません。
緩和策
Keycloak を正常な状態に復元するには、既存のインフラストラクチャを削除し、Keycloak スタックを再デプロイする必要があります。以下の手順に従ってください。
-
Cloudformation に移動します。そこに 2 つのキークローク関連スタックが表示されます。
-
<env-name>-RESSsoKeycloak-<random characters><env-name>-RESSsoKeycloak-<random characters>-RESSsoKeycloak-*
-
-
Stack1 を削除します。ネストされたスタックを削除するように求められたら、はいを選択してネストされたスタックを削除します。
スタックが完全に削除されていることを確認します。
-
ここで RES SSO Keycloak スタックテンプレートをダウンロードします
。 -
削除されたスタックとまったく同じパラメータ値を使用して、このスタックを手動でデプロイします。CloudFormation コンソールからデプロイするには、スタックの作成 → 新しいリソース (標準) を使用 → 既存のテンプレートを選択する → テンプレートファイルをアップロードします。削除されたスタックと同じ入力を使用して、必要なパラメータを入力します。これらの入力は、CloudFormation コンソールでフィルターを変更し、Parameters タブに移動することで、削除されたスタックで確認できます。環境名、キーペア、およびその他のパラメータが元のスタックパラメータと一致していることを確認します。
-
スタックがデプロイされると、環境を再度使用する準備が整います。ApplicationUrl は、デプロイされたスタックの出力タブにあります。
........................
