翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
AWS 最新のデータアーキテクチャ
このガイドでは、データ戦略フレームワークの実装方法について説明します AWS。これは、 AWS ドキュメント、ブログ記事、その他のガイドで説明されている広範なトピックです (リソースセクションを参照)。ただし、次の図は大まかな概要を示しています。この図は、AWS上のモダンデータアーキテクチャの主要コンポーネントを示しており、ロードマップに含まれる可能性のあるほとんどのサービスをカバーしています。
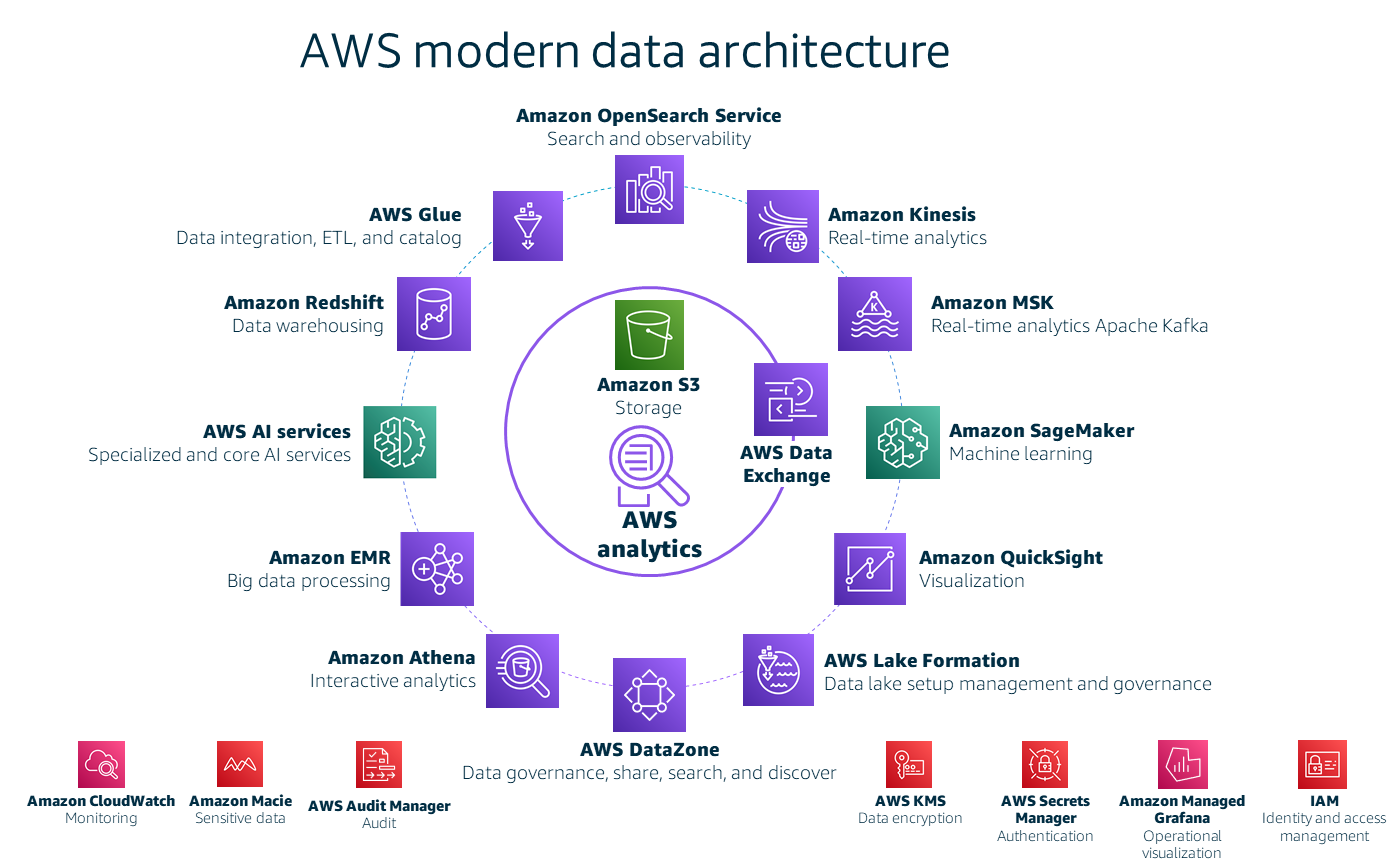
このアーキテクチャの主要コンポーネントは、前述のモダンデータ戦略の技術的原則をサポートしています。
-
統合された、費用対効果の高い、スケーラブルなストレージレイヤーを使用することで、すべてのデータプロデューサーとデータコンシューマーが、データを操作するための技術的能力を持つことができます。
Amazon Simple Storage Service (Amazon S3)
は、統合性、スケーラビリティ、データ可用性、セキュリティ、およびパフォーマンスを低コストで提供するオブジェクトストレージサービスです。 -
セキュリティは必須です。データプライバシールールを適用し、暗号化によるデータ保護を提供し、監査を有効にし、自動化されたコンプライアンスを提供します。
データプライバシー、保護、およびコンプライアンスを自動化された方法で適用し、監査を有効にするには、AWS Key Management Service (AWS KMS)
、AWS Identity and Access Management (IAM) 、AWS Secrets Manager 、AWS Audit Manager 、および Amazon Macie を使用できます。 -
会社全体で共有するためにデータを管理します。ユーザーが必要なデータを見つけて使用できるように、一意のデータカタログとビジネス用語集を提供します。
AWS Lake Formation
は、データを管理して会社全体で共有するのに役立ちます。さらに、AWS Glue 上で一意のデータカタログを作成し、Amazon DataZone (プレビュー) を使用してビジネス用語集を作成することで、従業員が必要なデータを見つけられるようになります。 -
適切なジョブに対して適切なサービスを選択します。コンポーネントを選択する際は、機能性、スケーラビリティ、データレイテンシー、サービスの実行に必要な労力、耐障害性、統合性、および自動化を考慮します。
Amazon Athena
、Amazon EMR 、、AWS Glue Amazon OpenSearch Service 、Amazon Kinesis 、Amazon Redshift 、Amazon Managed Streaming for Apache Kafka (Amazon MSK) 、Amazon Quick を検討してタスクを管理できます。たとえば、Kinesis または Amazon MSK を使用したリアルタイムストリーミング、Amazon EMR または を使用したデータ処理 AWS Glue、OpenSearch Service を使用した検索、Athena を使用したアドホッククエリ、Amazon Redshift を使用したデータウェアハウスを実行できます。 -
人工知能 (AI) と機械学習 (ML) を使用します。
AWS AI サービス
による人工知能の使用、および Amazon SageMaker AI による機械学習の使用を有効にできます。 -
データリテラシーと、ビジネスユーザー向けに抽象化されたツールを提供します。
データリテラシー、ツール、抽象化を提供するプロセスはアーキテクチャの一部ではありませんが、Amazon DataZone
(プレビュー)、AWS Lake Formation 、Amazon Quick をデータ抽象化ツールとして使用できます。 -
データイニシアチブの仮説をテストし、その結果を測定します。
Amazon OpenSearch Service
ダッシュボードまたは Amazon Quick を使用して、ビジネス成果メトリクスとテスト結果を操作し、仮説を検証できます。
さまざまなユースケースのサンプルアーキテクチャの例については、AWS アーキテクチャセンター
