翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
決定論的過信
Galおよび Ghahramani (2016) は、ソフトマックス確率を信頼度スコアとして解釈しないよう警告しました。彼らは、点推定値をソフトマックス活性化関数に通すと大きな確率が得られるのに対し、推定値の分布をソフトマックスに通すとより合理的で低い信頼スコアが得られることを経験的に示しました。この決定論的過信は、単一の予測
 ではなく、予測分布
ではなく、予測分布
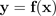 を学習する動機となっていることが一因です。
を学習する動機となっていることが一因です。
正式には、決定論的自信過剰の推測は、以下の不等式によって詳細に説明できます。

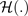 演算子はシャノンのエントロピーを表します。シャノンのエントロピーは、入力ベクトルの要素がより類似しているほど大きくなり、したがって均一なベクトルでは最大になります。したがって、前の式では、ベイジアンモデル
から期待されるソフトマックス確率ベクトル (分布の平均) のシャノンのエントロピー
演算子はシャノンのエントロピーを表します。シャノンのエントロピーは、入力ベクトルの要素がより類似しているほど大きくなり、したがって均一なベクトルでは最大になります。したがって、前の式では、ベイジアンモデル
から期待されるソフトマックス確率ベクトル (分布の平均) のシャノンのエントロピー
 に関する不確実性は、決定論的モデル
に関する不確実性は、決定論的モデル
 (単一点推定を生成するモデル) のソフトマックス確率ベクトルと同じかそれ以上になると述べています。前の方程式の不等式の証明と実証については、付録 Aを参照してください。
(単一点推定を生成するモデル) のソフトマックス確率ベクトルと同じかそれ以上になると述べています。前の方程式の不等式の証明と実証については、付録 Aを参照してください。
決定論的過信は、深層学習モデルの信頼性と安全性に影響します。組立ラインの品目に欠陥がないとモデルが自信を持って予測しているのに、実際には欠陥があるために、その品目が品質レビュープロセスをスキップするケースを考えてみましょう。この欠陥品はより大きな製品に埋め込まれ、その完全性が損なわれる可能性があります。せいぜい、欠陥が将来発見されれば非効率になり、さらに悪いことに、欠陥が見つからなかった場合は製品全体が故障することになります。したがって、プロジェクトの成功と深層学習の将来のためには、決定論的自信過剰の問題を理解し、克服することが不可欠です。
不確実性測定の質を向上させ、自信過剰を克服する3つの方法は次のとおりです。
-
温度スケーリングによるソフトマックス確率の事後校正 (Guo et al.2017)
-
MC ドロップアウトによるベイズ推定の近似 (つまり、推論中はドロップアウトをオンのままにする) (ガル&ガハラマニ 2016)
-
ディープアンサンブルによるベイズ推定の近似 (ラクシュミナラヤナン、プリッツェル、ブランデル 2017)
決定論的過剰信頼は、分布内データと分布外データの両方に当てはまる理論です。 1 次のセクションでは、定量化可能な不確実性の合計2を、認識論的 (モデル) 不確実性と偶然性 (データ) の不確実性という2つの構成要素に分割する方法について説明します (ケンダル&ガル 2017)。
メモ
1 特に、データが決定境界から遠く離れている場合、特にデータが分布から外れた場合、修正線形単位 (ReLU) の自信過剰が自信過剰の大きな原因であることが最近判明しました (Hein、Andriushchenko、およびBitterwolf 2019)。ReLU の自信過剰に対して強固になるために提案される方法の 1 つは、偶然性不確実性の情報理論的概念をモデル化することです (ガル&ガハラマニ 2016、Hein、Andriushchenko、Bitterwolf 2019、van Amersfoort et al. 2020)。これについては、このガイドの後半で説明します。
2 一部の分野では、すべての不確実性を定量化可能な不確実性と定量化できない不確実性に分解します。このガイドで説明する内容は、定量化可能な不確実性に限定されます。したがって、「不確実性の合計」と「定量化可能な不確実性の合計」は同じ意味で使用されます。
