翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
Amazon Athena SQL での Iceberg テーブルの開始方法
Amazon Athena は Iceberg の組み込みサポートを提供します。Athena ドキュメントの「開始方法」セクションで説明されているサービスの前提条件を設定する以外は、追加のステップや設定なしで Iceberg を使用できます。このセクションでは、Athena でテーブルを作成する方法を簡単に説明します。詳細については、このガイドの後半の「Athena SQL を使用した Iceberg テーブルの操作」を参照してください。
異なるエンジン AWS を使用して、 で Iceberg テーブルを作成できます。これらのテーブルはシームレスに動作します AWS のサービス。Athena SQL で最初の Iceberg テーブルを作成するには、次の定型コードを使用できます。
CREATE TABLE <table_name> ( col_1 string, col_2 string, col_3 bigint, col_ts timestamp) PARTITIONED BY (col_1, <<<partition_transform>>>(col_ts)) LOCATION 's3://<bucket>/<folder>/<table_name>/' TBLPROPERTIES ( 'table_type' ='ICEBERG' )
以下のセクションでは、Athena でパーティション分割された Iceberg テーブルとパーティション分割されていない Iceberg テーブルを作成する例を示します。詳細については、Athena ドキュメントで詳述されている Iceberg 構文を参照してください。
パーティション化されていないテーブルの作成
次のステートメント例では、定型 SQL コードをカスタマイズして、Athena でパーティション分割されていない Iceberg テーブルを作成します。このステートメントを Athena コンソール
CREATE TABLE athena_iceberg_table ( color string, date string, name string, price bigint, product string, ts timestamp) LOCATION 's3://DOC_EXAMPLE_BUCKET/ice_warehouse/iceberg_db/athena_iceberg_table/' TBLPROPERTIES ( 'table_type' ='ICEBERG' )
クエリエディタを使用するstep-by-stepについては、Athena ドキュメントの「開始方法」を参照してください。
パーティションテーブルの作成
次のステートメントは、Iceberg の非表示day() 変換を使用して、タイムスタンプ列から dd-mm-yyyy形式を使用して日次パーティションを取得します。Iceberg はこの値をデータセットの新しい列として保存しません。代わりに、データを書き込んだりクエリしたりすると、その場で値が算出されます。
CREATE TABLE athena_iceberg_table_partitioned ( color string, date string, name string, price bigint, product string, ts timestamp) PARTITIONED BY (day(ts)) LOCATION 's3://DOC_EXAMPLE_BUCKET/ice_warehouse/iceberg_db/athena_iceberg_table/' TBLPROPERTIES ( 'table_type' ='ICEBERG' )
単一の CTAS ステートメントを使用してテーブルを作成し、データをロードする
前のセクションのパーティション分割された例とパーティション分割されていない例では、Iceberg テーブルは 空のテーブルとして作成されます。INSERT または MERGEステートメントを使用して、テーブルにデータをロードできます。または、CREATE TABLE AS SELECT (CTAS)ステートメントを使用して、1 つのステップで Iceberg テーブルにデータを作成してロードすることもできます。
CTAS は、Athena でテーブルを作成し、1 つのステートメントにデータをロードする最適な方法です。次の例は、CTAS を使用して Athena の既存の Hive/Parquet テーブル (iceberg_ctas_table) から Iceberg テーブル (hive_table) を作成する方法を示しています。
CREATE TABLE iceberg_ctas_table WITH ( table_type = 'ICEBERG', is_external = false, location = 's3://DOC_EXAMPLE_BUCKET/ice_warehouse/iceberg_db/iceberg_ctas_table/' ) AS SELECT * FROM "iceberg_db"."hive_table" limit 20 --- SELECT * FROM "iceberg_db"."iceberg_ctas_table" limit 20
CTAS の詳細については、Athena CTAS ドキュメントを参照してください。
データの挿入、更新、削除
Athena は、、INSERT INTO、、MERGE INTOおよび DELETE FROM ステートメントを使用して Iceberg UPDATEテーブルにデータを書き込むさまざまな方法をサポートしています。
注記
Athena SQL は現在copy-on-writeアプローチをサポートしていません。UPDATE、MERGE INTO、および DELETE FROMオペレーションでは、指定されたテーブルプロパティに関係なく、位置削除で常にmerge-on-readアプローチを使用します。write.update.mode、、 などのテーブルプロパティをcopy-on-writeを使用するwrite.merge.modewrite.delete.modeように設定した場合、クエリは失敗しませんが、Athena はそれらを無視してmerge-on-readを使用し続けます。
次のステートメントではINSERT INTO、 を使用して Iceberg テーブルにデータを追加します。
INSERT INTO "iceberg_db"."ice_table" VALUES ( 'red', '222022-07-19T03:47:29', 'PersonNew', 178, 'Tuna', now() ) SELECT * FROM "iceberg_db"."ice_table" where color = 'red' limit 10;
サンプル出力:

詳細については、Athena のドキュメントを参照してください。
Iceberg テーブルのクエリ
前の例に示すように、Athena SQL を使用して Iceberg テーブルに対して通常の SQL クエリを実行できます。
通常のクエリに加えて、Athena は Iceberg テーブルのタイムトラベルクエリもサポートしています。前述のように、Iceberg テーブルの更新または削除を通じて既存のレコードを変更できるため、タイムトラベルクエリを使用して、タイムスタンプまたはスナップショット ID に基づいてテーブルの古いバージョンをさかのぼるのが便利です。
たとえば、次のステートメントは の色値を更新しPerson5、2023 年 1 月 4 日以前の値を表示します。
UPDATE ice_table SET color='new_color' WHERE name='Person5' SELECT * FROM "iceberg_db"."ice_table" FOR TIMESTAMP AS OF TIMESTAMP '2023-01-04 12:00:00 UTC'
サンプル出力:
構文とタイムトラベルクエリのその他の例については、Athena ドキュメントを参照してください。
Iceberg テーブルの構造
Iceberg テーブルを使用するための基本的なステップを説明したので、Iceberg テーブルの複雑な詳細と設計について詳しく見てみましょう。
このガイドで前述した機能を有効にするために、Iceberg はデータとメタデータファイルの階層レイヤーを使用して設計されています。これらのレイヤーはメタデータをインテリジェントに管理し、クエリの計画と実行を最適化します。
次の図は、Iceberg テーブルの編成を 2 つの視点で示しています。テーブルの保存 AWS のサービス に使用される と、Amazon S3 でのファイル配置です。
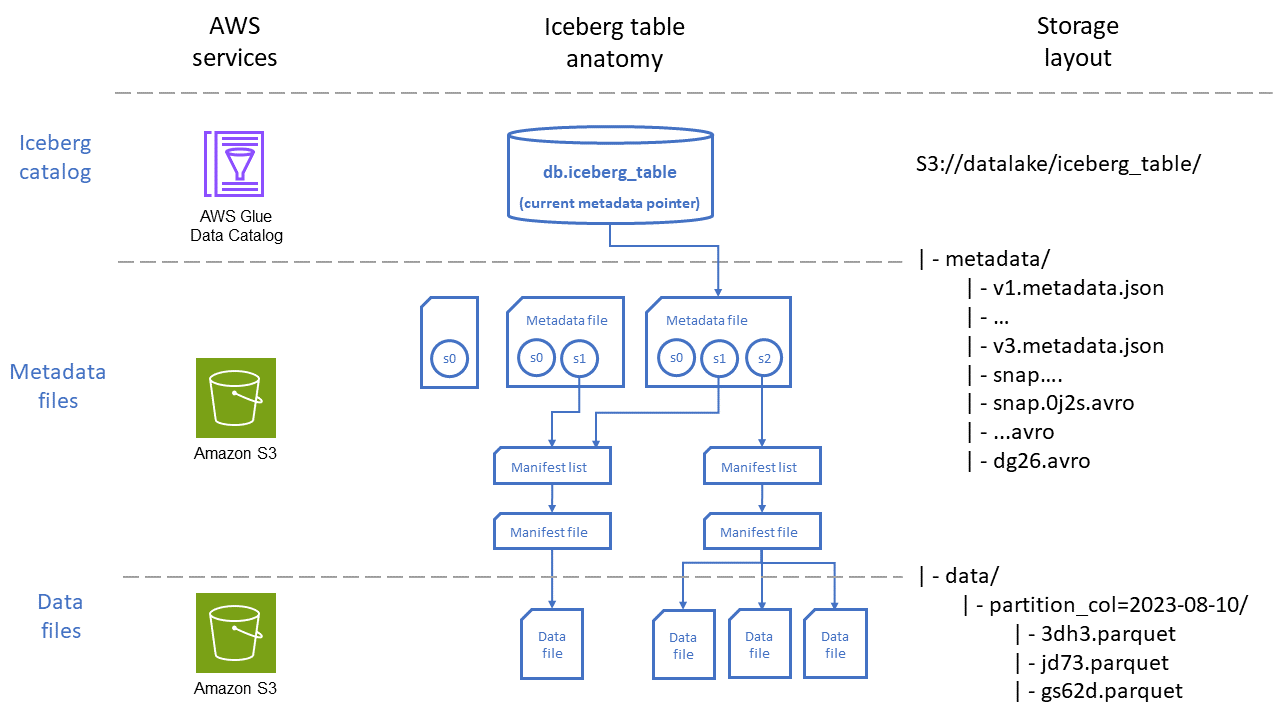
図に示すように、Iceberg テーブルは 3 つのメインレイヤーで構成されます。
-
Iceberg Catalog: は Iceberg とネイティブ AWS Glue Data Catalog に統合されており、ほとんどのユースケースでは、 で実行されるワークロードに最適なオプションです AWS。Iceberg テーブルとやり取りするサービス (Athena など) は、カタログを使用してテーブルの現在のスナップショットバージョンを検索し、データの読み取りまたは書き込みを行います。
-
メタデータレイヤー: メタデータファイル、つまりマニフェストファイルとマニフェストリストファイルは、テーブルのスキーマ、パーティション戦略、データファイルの場所などの情報と、各データファイルに保存されているレコードの最小範囲と最大範囲などの列レベルの統計情報を追跡します。これらのメタデータファイルは、テーブルパス内の Amazon S3 に保存されます。
-
マニフェストファイルには、場所、形式、サイズ、チェックサム、その他の関連情報など、各データファイルのレコードが含まれます。
-
マニフェストリストは、マニフェストファイルのインデックスを提供します。テーブル内のマニフェストファイルの数が増えるにつれて、その情報を小さなサブセクションに分割することで、クエリでスキャンする必要があるマニフェストファイルの数を減らすことができます。
-
メタデータファイルには、マニフェストリスト、スキーマ、パーティションメタデータ、スナップショットファイル、およびテーブルのメタデータの管理に使用されるその他のファイルなど、Iceberg テーブル全体に関する情報が含まれます。
-
-
データレイヤー: このレイヤーには、クエリが実行されるデータレコードを持つファイルが含まれています。これらのファイルは、Apache Parquet
、Apache Avro 、Apache ORC など、さまざまな形式で保存できます。 -
データファイルには、テーブルのデータレコードが含まれます。
-
Iceberg テーブルの行レベルの削除および更新オペレーションをエンコードするファイルを削除します。Iceberg には、Iceberg ドキュメント
で説明されているように、2 種類の削除ファイルがあります。これらのファイルは、merge-on-readモードを使用して オペレーションによって作成されます。
-
