翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
最新のデータレイク
最新のデータレイクにおける高度なユースケース
データストレージの進化は、データベースからデータウェアハウス、データレイクへと進み、各テクノロジーが固有のビジネス要件とデータ要件に対処しています。従来のデータベースは構造化データとトランザクションワークロードの処理に優れていましたが、データ量が増えるにつれてパフォーマンスの課題に直面していました。データウェアハウスは、パフォーマンスとスケーラビリティの問題に取り組むために出現しましたが、データベースと同様に、垂直統合システム内の独自の形式に依存していました。
データレイクは、コスト、スケーラビリティ、柔軟性の観点からデータを保存するための最適なオプションの 1 つです。データレイクを使用すると、大量の構造化データと非構造化データを低コストで保持し、ビジネスインテリジェンスレポートからビッグデータ処理、リアルタイム分析、機械学習、生成人工知能 (AI) まで、さまざまなタイプの分析ワークロードにこのデータを使用して、より良い意思決定に役立てることができます。
これらの利点にもかかわらず、データレイクは当初、データベースのような機能で設計されていませんでした。データレイクは、アトミック性、整合性、分離性、耐久性 (ACID) 処理セマンティクスをサポートしていません。これは、さまざまなテクノロジーを使用して、数百人または数千人のユーザー間でデータを大規模に効果的に最適化および管理するために必要になる場合があります。データレイクは、以下の機能をネイティブにサポートしていません。
-
ビジネスでのデータ変更に伴うレコードレベルの効率的な更新と削除の実行
-
数百万のファイルと数十万のパーティションへのテーブルの増加に伴うクエリパフォーマンスの管理
-
複数の同時ライターとリーダー間でのデータ整合性の確保
-
オペレーションの途中で書き込みオペレーションが失敗した場合のデータ破損の防止
-
データセットを (部分的に) 書き換えることなく、時間の経過とともにテーブルスキーマを進化させる
これらの課題は、変更データキャプチャ (CDC) の処理や、プライバシー、データの削除、ストリーミングデータ取り込みに関するユースケースなど、ユースケースで特に一般的になっており、最適ではないテーブルが発生する可能性があります。
従来の Hive 形式のテーブルを使用するデータレイクは、ファイル全体の書き込みオペレーションのみをサポートします。これにより、更新と削除の実装が難しく、時間がかかり、コストがかかります。さらに、データの整合性と一貫性を確保するために、ACID 準拠システムで提供される同時実行制御と保証が必要です。
これらの課題により、ユーザーはジレンマに陥ります。つまり、完全に統合された独自のプラットフォームを選択するか、ベンダーに依存しないがリソースを大量に消費する自己構築型のデータレイクを選択して、潜在的な価値を実現するには、継続的なメンテナンスと移行が必要です。
これらの課題を克服するために、Iceberg には、Amazon S3
Apache Iceberg の概要
Apache Iceberg は、これまでデータベースまたはデータウェアハウスでのみ使用されていたデータレイクテーブルの機能を提供するオープンソースのテーブル形式です。スケーリングとパフォーマンスのために設計されており、数百ギガバイトを超えるテーブルの管理に適しています。Iceberg テーブルの主な機能は次のとおりです。
-
削除、更新、マージします。 Iceberg は、データレイクテーブルで使用するデータウェアハウス用の標準 SQL コマンドをサポートしています。
-
高速スキャン計画と高度なフィルタリング。Iceberg は、クエリの計画と実行を高速化するためにエンジンで使用できるパーティションや列レベルの統計などのメタデータを保存します。
-
完全なスキーマの進化。Iceberg は、副作用のない列の追加、削除、更新、名前変更をサポートしています。
-
パーティションの進化。データボリュームまたはクエリパターンの変化に応じて、テーブルのパーティションレイアウトを更新できます。Iceberg は、テーブルがパーティション分割されている列の変更、複合パーティションへの列の追加、複合パーティションからの列の削除をサポートしています。
-
非表示のパーティショニング。 この機能は、不要なパーティションを自動的に読み取るのを防ぎます。これにより、ユーザーがテーブルのパーティショニングの詳細を理解したり、クエリにフィルターを追加したりする必要がなくなります。
-
バージョンロールバック。ユーザーは、トランザクション前の状態に戻すことで問題をすばやく修正できます。
-
タイムトラベル。ユーザーは、特定の以前のバージョンのテーブルをクエリできます。
-
シリアル化可能な分離。テーブルの変更はアトミックであるため、読者は部分的またはコミットされていない変更を見ることはありません。
-
同時ライター。Iceberg はオプティミスティック同時実行を使用して、複数のトランザクションを成功させます。競合が発生した場合、ライターの 1 人がトランザクションを再試行する必要があります。
-
ファイル形式を開きます。Iceberg は、Apache Parquet
、Apache Avro 、Apache ORC など、複数のオープンソースファイル形式をサポートしています。
要約すると、Iceberg 形式を使用するデータレイクは、トランザクションの一貫性、速度、スケール、スキーマの進化の恩恵を受けます。これらの機能やその他の Iceberg 機能の詳細については、Apache Iceberg のドキュメント
AWS Apache Iceberg のサポート
Apache Iceberg は、Amazon EMR
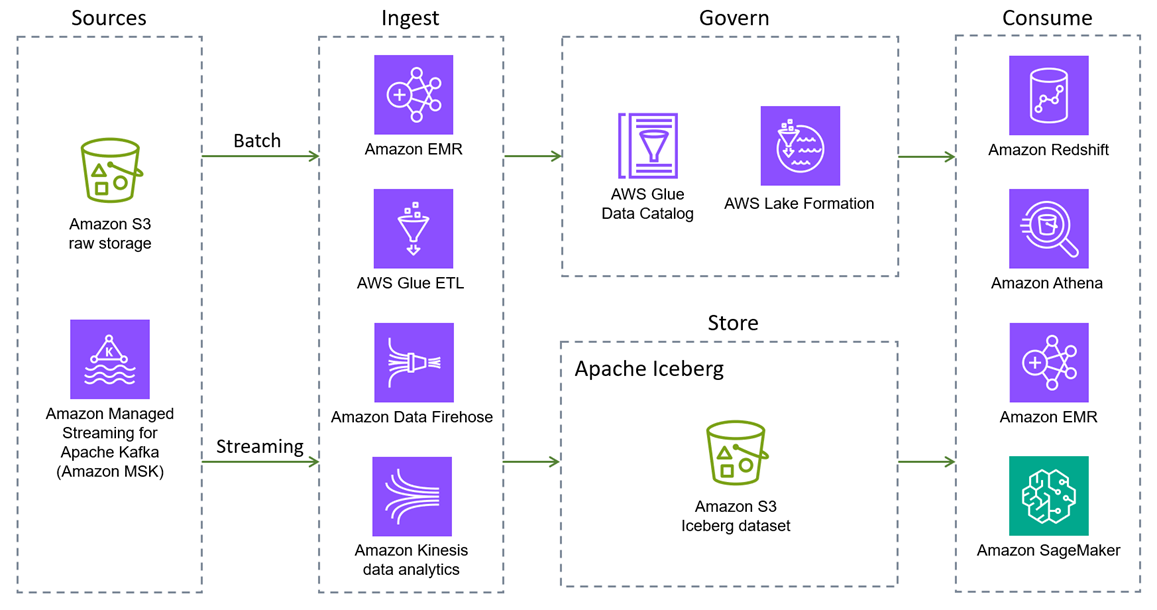
以下は AWS のサービス 、Iceberg のネイティブ統合を提供します。間接的に、または Iceberg ライブラリをパッケージ化することによって、Iceberg とやり取り AWS のサービス できる追加 があります。
-
Amazon S3 は、耐久性、可用性、スケーラビリティ、セキュリティ、コンプライアンス、監査機能を備えているため、データレイクを構築するのに最適な場所です。Iceberg は Amazon S3 とシームレスにやり取りするように設計および構築されており、Iceberg ドキュメント
に記載されている多くの Amazon S3 機能をサポートしています。さらに、Amazon S3 Tables は、Iceberg のサポートが組み込まれた最初のクラウドオブジェクトストアを提供し、大規模な表形式データの保存を合理化します。Iceberg の S3 Tables のサポートにより、一般的なクエリエンジン AWS とサードパーティーのクエリエンジンを使用して、表形式のデータを簡単にクエリできます。 -
次世代の SageMaker
は、Amazon S3 データレイク、Amazon Redshift データウェアハウス、サードパーティーおよびフェデレーティッドデータソース間のデータアクセスを統合するオープンレイクハウスアーキテクチャ上に構築されています。これらの機能は、データの 1 つのコピーで強力な分析と AI/ML アプリケーションを構築するのに役立ちます。レイクハウスは Iceberg と完全に互換性があるため、Iceberg REST API を使用してデータにアクセスしてクエリを実行する柔軟性があります。 -
Amazon EMR は、Apache Spark、Flink、Trino、Hive などのオープンソースフレームワークを使用してペタバイト規模のデータ処理、インタラクティブ分析、機械学習を行うためのビッグデータソリューションです。Amazon EMR は、カスタマイズされた Amazon Elastic Compute Cloud (Amazon EC2) クラスター、Amazon Elastic Kubernetes Service (Amazon EKS)、 AWS Outposts、または Amazon EMR Serverless で実行できます。
-
Amazon Athena は、オープンソースフレームワーク上に構築されたサーバーレスのインタラクティブな分析サービスです。オープンテーブル形式とファイル形式をサポートし、ペタバイト単位のデータを分析するためのシンプルで柔軟な方法を提供します。Athena は Iceberg の読み取り、タイムトラベル、書き込み、DDL クエリをネイティブにサポートし、Iceberg メタストア AWS Glue Data Catalog に を使用します。
-
Amazon Redshift は、クラスターベースとサーバーレスの両方のデプロイオプションをサポートするペタバイト規模のクラウドデータウェアハウスです。Amazon Redshift Spectrum は、 に登録 AWS Glue Data Catalog されAmazon S3に保存されている外部テーブルをクエリできます。Redshift Spectrum は Iceberg ストレージ形式もサポートしています。
-
AWS Glue は、分析、機械学習 (ML)、アプリケーション開発のために複数のソースからのデータを簡単に検出、準備、移動、統合できるサーバーレスデータ統合サービスです。Iceberg と完全に統合されています。具体的には、 AWS Glue ジョブを使用して Iceberg テーブルの読み取りおよび書き込みオペレーションを実行し、 AWS Glue Data Catalog (Hive メタストア互換) を使用してテーブルを管理し、 AWS Glue クローラを使用してテーブルを自動的に検出して登録し、 AWS Glue Data Quality 機能を使用して Iceberg テーブルのデータ品質を評価できます。は、列統計の収集、Iceberg テーブルの各列の個別値 (NDVs) の数の計算と更新、およびテーブルの自動最適化 (圧縮、スナップショット保持、孤立ファイル削除) AWS Glue Data Catalog もサポートしています。 は、 AWS のサービス およびサードパーティーアプリケーションのリストから Iceberg テーブルへのゼロ ETL 統合 AWS Glue もサポートしています。
-
Amazon Data Firehose は、Amazon S3、Amazon Redshift、Amazon OpenSearch Service、Amazon OpenSearch Serverless、Splunk、Apache Iceberg テーブルなどの送信先、および Datadog、Dynatrace、LogicMonitor、MongoDB、New Relic、Coralogix、Elastic など、サポートされているサードパーティーサービスプロバイダーが所有するカスタム HTTP または HTTP エンドポイントにリアルタイムのストリーミングデータを配信するためのフルマネージドサービスです。Firehose では、アプリケーションを記述したり、リソースを管理したりする必要はありません。Firehose にデータを送信するデータプロデューサーを作成すると、それにより、指定した送信先にデータが自動配信されます。データを配信前に変換するように、Firehose を設定することもできます。
-
Amazon Managed Service for Apache Flink は、Apache Flink アプリケーションを使用してストリーミングデータを処理できるフルマネージド型の Amazon サービスです。Iceberg テーブルとの読み取りと書き込みの両方をサポートし、リアルタイムのデータ処理と分析を可能にします。
-
Amazon SageMaker AI は、Iceberg 形式を使用して Amazon SageMaker AI Feature Store の機能セットのストレージをサポートします。
-
AWS Lake Formation は、Athena または Amazon Redshift によって消費される Iceberg テーブルなど、データにアクセスするための粗くきめ細かなアクセスコントロール許可を提供します。Iceberg テーブルのアクセス許可のサポートの詳細については、Lake Formation ドキュメントを参照してください。
AWS には Iceberg をサポートする幅広いサービスがありますが、これらのサービスをすべてカバーすることは、このガイドの範囲外です。以下のセクションでは、Amazon EMR および の Spark (バッチおよび構造化ストリーミング) AWS Glueと Athena SQL について説明します。次のセクションでは、Athena SQL での Iceberg サポートについて簡単に説明します。
