翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
サーバーレス AI アーキテクチャの設計
サーバーレス AI の原則を実際のシステムに変換するには、慎重なアーキテクチャが必要です。目標は、伸縮自在にスケールし、リアルタイムで応答するモジュール式のインテリジェントなパイプライン AWS のサービス に疎結合で統合することです。
このセクションでは、生成 AI オーケストレーション、リアルタイム推論、エッジコンピューティングなど、 AWS サーバーレスサービスを使用してクラウドネイティブ AI システムをアセンブルする方法に関する規範的なガイダンスを提供します。各アーキテクチャパターンは、一般的なエンタープライズユースケースに対応し、関連性と適用性を確保します。
このセクションの内容
基本的なアーキテクチャパターン
従来のイベント駆動型アプリケーションアーキテクチャでは、システムは、スケーラビリティと応答性を実現しながら、懸念を切り離す 4 つの論理レイヤーで構成されています。上部では、アプリケーションレイヤーがユーザーインタラクション、APIs、UI イベントを処理し、多くの場合、ドメイン固有のイベントをシステム内でトリガーします。オーケストレーションレイヤーはその下に、ステートマシンやサーバーレスワークフローなどのツールを使用してワークフロー、ビジネスルール、イベントシーケンスを管理します。サービスレイヤーには、イベントに応答してコアロジックを実行するモジュール式の再利用可能な関数またはマイクロサービスが含まれています。ベースでは、データレイヤーが永続性、ストリーミング、イベントソーシングを担当します。データレイヤーは、データベース、オブジェクトストア、イベントログなどのサービスを活用して、変更イベントを出力および消費します。これらのレイヤーは、イベントがスタック全体でフローを駆動する疎結合、スケーラブル、保守可能なアーキテクチャをサポートします。
同様に、サーバーレス AI システムは、独立してスケーリング、進化、復旧できる疎結合のイベント駆動型サービスで構成されています。これらのシステムを一貫性とスケーラビリティで設計するには、アーキテクチャを 5 つの異なるレイヤーとして表示することが重要です。各レイヤーは特定の関数を提供し、専用 に直接マッピングされます AWS のサービス。次の図は、各レイヤーを示しています。
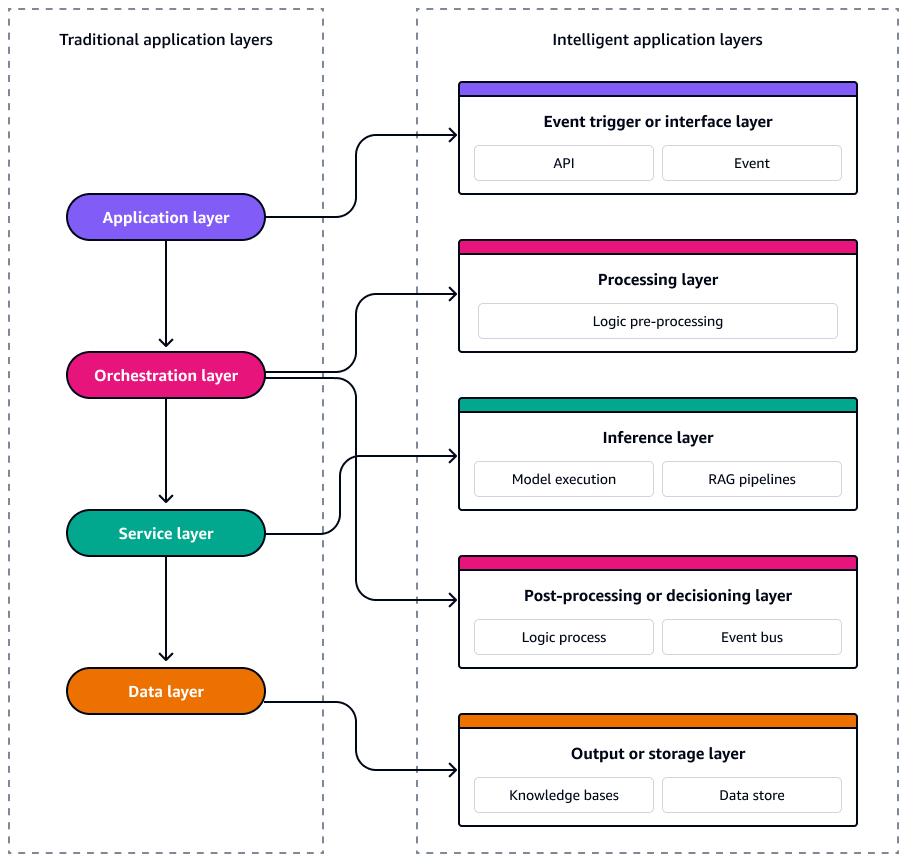
これらの 5 つのレイヤーは、回復力があり、観測可能で、コストとパフォーマンスの両方に最適化された、インテリジェントなイベント駆動型アプリケーションを構築するための設計図を形成します。
イベントトリガーまたはインターフェイスレイヤー
イベントトリガーまたはインターフェイスレイヤーは、サーバーレス AI システムへのエントリポイントです。ユーザーインタラクション、システムイベント、データ変更をキャプチャし、構造化イベントとしてアーキテクチャに出力します。これにより、非同期オーケストレーションが可能になり、アップストリーム入力とダウンストリーム処理ロジックを切り離します。
イベントトリガーレイヤーの責任は次のとおりです。
-
クリック、メッセージ、アップロードなどのユーザーアクションをキャプチャする
-
ドメインイベントの送信または通知の変更
-
ダウンストリーム消費のために受信データを正規化する
AWS のサービス このレイヤーで一般的に使用される には、次のようなものがあります。
-
Amazon API Gateway は、REST または WebSocket APIs。
-
Amazon EventBridge は、スキーマレジストリを使用して内部イベントまたは外部イベントをルーティングします。
-
Amazon Simple Storage Service (Amazon S3) は、ドキュメントのアップロードやメディアファイルなどのオブジェクトの作成時にトリガーされます。
-
Amazon Kinesis と Amazon Managed Streaming for Apache Kafka (Amazon MSK) は、ストリーミングイベントを大規模に取り込みます。
例: ウェブフォームを介して送信されたカスタマーサポートリクエストは EventBridge ルールをトリガーし、Amazon Bedrock エージェントワークフローをダウンストリームで開始します。
処理レイヤー
処理レイヤーは、AI モデルに渡す前にデータを変換または強化します。ルックアップテーブルまたは外部 APIs。
処理レイヤーの責任には以下が含まれます。
-
raw 入力を検証して正規化します。
-
言語や顧客 ID などのメタデータを抽出または挿入します。
-
データ属性に基づいてロジックをルーティングまたはブランチします。
AWS のサービス このレイヤーで一般的に使用される には、次のようなものがあります。
-
AWS Lambda は、変換ロジックのステートレスでイベント駆動型のコンピューティングです。
-
AWS Step Functions は、複数ステップの前処理タスクを調整します。
-
Amazon Comprehend は、前処理の一部として言語検出、エンティティ認識、または感情分析を提供します。
例: アップロードされた保険金請求は、AI の要約の前に Lambda と Amazon Comprehend を使用して、個人を特定できる情報 (PII) とドキュメントタイプについてスキャンされます。
推論レイヤー
AI システムの中核として、推論レイヤーは機械学習 (ML) または基盤モデル (FM) 推論を実行します。ユースケースに応じて、生成、予測、分類の 1 つ以上のモデルを含めることができます。
推論レイヤーの責任は次のとおりです。
-
ML または FM モデルの推論を実行します。
-
予測、分類、または生成されたコンテンツを生成します。
-
必要に応じて取得拡張生成 (RAG) コンテキストを統合します。
AWS のサービス このレイヤーで一般的に使用される には、次のようなものがあります。
-
Amazon Bedrock は、Anthropic、Amazon (Amazon Nova 向け)、、 などのプロバイダーから基盤モデル推論 (テキスト、イメージMeta、マルチモーダル) を提供しますMistral。
-
Amazon SageMaker Serverless Inference は、カスタム ML モデルを大規模に実行します。
-
Amazon Bedrock エージェントは、大規模言語モデル (LLM) 主導の推論と目標ベースのオーケストレーションを提供します。
例: Amazon Bedrock エージェントは Amazon Nova Pro を使用して、RAG を使用したエンタープライズナレッジに基づく複雑なサポートクエリへのレスポンスを生成します。
後処理または決定レイヤー
後処理レイヤーまたは決定レイヤーは、推論結果を絞り込むか、推論結果に基づいて動作します。レスポンスのフォーマット、ログ出力、ダウンストリームアクションの呼び出し、モデルの信頼度、分類、または外部のビジネスルールに基づく意思決定を行うことができます。
後処理レイヤーまたは決定レイヤーの責任は次のとおりです。
-
ダウンストリームシステムまたはディスプレイの AI 出力をフォーマットします。
-
条件付きロジックをトリガーするかAPIs。
-
ストレージまたは分析用に強化されたデータをルーティングします。
AWS のサービス このレイヤーで一般的に使用される には、次のようなものがあります。
-
Lambda は、結果をフォーマットしたり、変換を適用したり、APIs呼び出すことができます。
-
Amazon Simple Notification Service (Amazon SNS) と EventBridge は、モデル出力に基づいてさらにイベントを出力します。
-
Step Functions はチェーンロジックを適用します。たとえば、感情が「怒り」と等しい場合はサポートケースをエスカレーションします。
例: LLM からの製品レコメンデーションは、レコメンデーションがユーザーに送信される前に Lambda 関数を使用してリアルタイムインベントリに対して交差検証されます。
出力レイヤーまたはストレージレイヤー
最後に、出力レイヤーまたはストレージレイヤーは、ユーザーまたはシステムへの結果の配信を処理し、監査、分析、またはフィードバックループのための構造化された出力を保持します。
出力レイヤーまたはストレージレイヤーの責任は次のとおりです。
-
APIs または UIs。
-
構造化された出力とログを保持します。
-
データレイクまたは再トレーニングパイプラインにフィードします。
AWS のサービス このレイヤーで一般的に使用される には、次のようなものがあります。
-
Amazon S3 は、推論ログ、概要、または生成されたコンテンツを保存します。
-
Amazon DynamoDB は、セッション固有の AI 出力用に低レイテンシーのキーバリューストレージを提供します。
-
Amazon OpenSearch Service は、検索と分析のためのインデックス構造化出力を提供します。
-
API Gateway および WebSocket APIsは、フロントエンドクライアントまたはモバイルクライアントにリターンレスポンスを提供します。
例: Amazon Bedrock によって生成された法的ドキュメントの概要は、Amazon S3 に保存され、OpenSearch Service でインデックス化されてセマンティックエンタープライズ検索を有効にします。
レイヤー間の設計上の考慮事項
以下の主要な設計上の考慮事項とパターンは、すべてのアーキテクチャレイヤーに適用されます。
-
耐障害性 – 各レイヤーは個別に失敗して再試行する必要があります (Lambda のデッドレターキュー (DLQs) など)。
-
オブザーバビリティ – 各ステージから Amazon CloudWatch に構造化ログ、トレース、メトリクスを出力して、動作ドリフトを検出します。
-
セキュリティ – レイヤー間のデータ暗号化には AWS Identity and Access Management (IAM) ロール分離と AWS Key Management Service (AWS KMS) を使用します。
-
コスト最適化 – 可能な限り非同期実行を使用し、適切なサイズのモデルを選択します。
-
拡張性 – モジュラー設計により、サービスを個別に交換またはアップグレードできます。
これらの 5 つのレイヤーは、AI を活用したワークロード向けのモジュール式のスケーラブルなサーバーレスリファレンスアーキテクチャを形成します AWS。各レイヤーは個別に開発、デプロイ、最適化できるため、迅速な反復、運用上の優秀性、ビジネスドメイン間の懸念の明確な分離が可能になります。
このレイヤードパターンを設計足場として使用することで、企業はサーバーレス AI へのアプローチを標準化し、プロトタイプから本番環境への道を自信を持って加速できます。
アーキテクチャ設計に関する考慮事項
のサーバーレス AI アーキテクチャ AWS により、モジュール式、スケーラブル、本番稼働用のインテリジェントなアプリケーションを構築できます。エッジにモデルをデプロイする場合でも、複数ステップの推論パイプラインを調整する場合でも、生成 AI アシスタントを構築する場合でも、 AWS のサービス は次世代の AI ネイティブアプリケーションを強化できます。
サーバーレス AI アーキテクチャを設計するときは、以下の主要な設計の焦点とベストプラクティスに注意してください。
-
セキュリティ – きめ細かな IAM ロールを使用し、プロンプトと出力を暗号化して、API アクセスを制限します。
-
オブザーバビリティ – パイプラインステージごとに CloudWatch、 AWS X-Ray、およびカスタムログを統合します。
-
スケーラビリティ – Lambda、Amazon Bedrock、SageMaker Serverless Inference などのサーバーレスコンポーネントのみを使用します。
-
レイテンシー – Lambda@Edge、プロビジョニングされた同時実行、または非同期推論を活用します。
-
モジュール性 – 各タスクのイベントトリガーと分離された関数を使用してパイプラインを設計します。
-
再利用性 – Step Functions を使用して、プロンプトのパラメータ化、共有 Lambda レイヤーの使用、ロジックの分離を行います。
