翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
従来のエージェントアーキテクチャ: 認識、理由、行動
次の図は、前のセクションで説明した構成要素が、認識、理由、行動のサイクルでどのように動作するかを示しています。
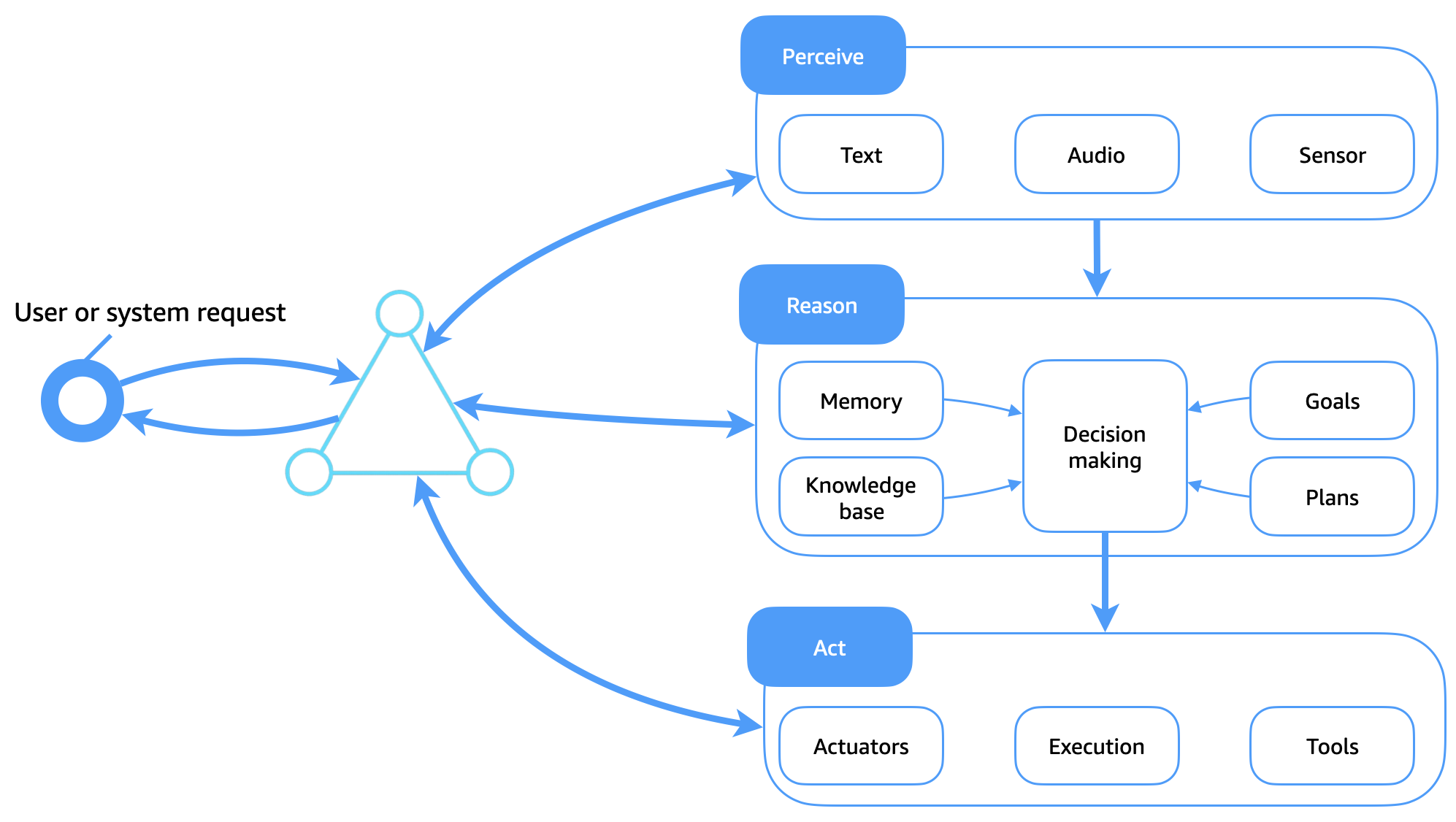
Perceive モジュール
認識モジュールは、外部ワールドとのエージェントの知覚インターフェイスとして機能します。生の環境入力を、推論を通知する構造化表現に変換します。これには、テキスト、オーディオ、センサー信号などのマルチモーダルデータの処理が含まれます。
-
テキスト入力は、ユーザーコマンド、ドキュメント、またはダイアログから取得できます。
-
音声入力には、話し方や環境音が含まれます。
-
センサー入力は、モーション、ビジュアルフィード、GPS などの実際の信号をキャプチャします。
raw 入力が取り込まれると、認識プロセスは特徴抽出を実行し、その後にオブジェクトまたはイベントの認識とセマンティック解釈を実行して、現在の状況の意味のあるモデルを作成します。これらの出力は、ダウンストリームの意思決定のための構造化されたコンテキストを提供し、実際の観測でエージェントの推論を固定します。
理由モジュール
理由モジュールは、エージェントのコグニティブコアです。コンテキストを評価し、インテントを策定し、適切なアクションを決定します。このモジュールは、学習した知識と推論の両方を使用して、目標主導型の動作を調整します。
理由モジュールは、緊密に統合されたサブモジュールで構成されます。
-
メモリ: ダイアログの状態、タスクコンテキスト、エピソード履歴を短期形式と長期形式の両方で維持します。
-
ナレッジベース: シンボリックルール、オントロジー、学習モデル (埋め込み、ファクト、ポリシーなど) へのアクセスを提供します。
-
目標と計画: 望ましい成果を定義し、それを達成するためのアクション戦略を構築します。目標は動的に更新でき、計画はフィードバックに基づいて適応的に変更できます。
-
意思決定: オプションを比較検討し、トレードオフを評価し、次のアクションを選択することで、中央の調停エンジンとして機能します。このサブモジュールでは、信頼度しきい値、目標の調整、コンテキスト制約の要因が示されます。
これらのコンポーネントを組み合わせることで、エージェントは環境について推論し、信条を更新し、パスを選択し、一貫性のある適応的な方法で動作できます。理由モジュールは、認識と動作のギャップを埋めます。
Act モジュール
act モジュールは、エージェントが選択した決定を実行するために、デジタル環境または物理環境のいずれかとやり取りしてタスクを実行します。ここで意図がアクションになります。
このモジュールには、次の 3 つの機能チャネルが含まれています。
-
アクチュエータ: 物理的に存在するエージェント (ロボットや IoT デバイスなど) の場合、 は移動、操作、シグナリングなどのハードウェアレベルのインタラクションを制御します。
-
実行: APIs、システムの更新など、ソフトウェアベースのアクションを処理します。
-
ツール: 検索、要約、コード実行、計算、ドキュメント処理などの機能を有効にします。これらのツールは、多くの場合動的でコンテキスト対応であり、エージェントのユーティリティを拡張します。
act モジュールの出力は環境にフィードバックし、ループを閉じます。これらの結果は、エージェントによって再び認識されます。エージェントの内部状態を更新し、将来の決定を通知するため、認識、理由、行動のサイクルを完了します。
