翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
Amazon Redshift データを に取り込む AWS Glue Data Catalog
AWS Glue Data Catalog (データカタログ) の Amazon Redshift データウェアハウスで分析データを管理し、Amazon S3 データレイクと Amazon Redshift データウェアハウスを統合できます。Amazon Redshift は、 AWS クラウドにおけるフルマネージド型のペタバイト規模のデータウェアハウスサービスです。Amazon Redshift データウェアハウスは、ノードと呼ばれるコンピューティングリソースの集合で、クラスターと呼ばれるグループに編成されています。各クラスターは Amazon Redshift エンジンを実行し、1 つ以上のデータベースを含みます。
Amazon Redshift では、Amazon Redshift でプロビジョニングされたクラスターとサーバーレス名前空間を作成し、データカタログに登録できます。これにより、Amazon Redshift マネージドストレージ (RMS) と Amazon S3 バケットのデータを統合し、Apache Iceberg 互換の分析エンジンからデータにアクセスできるようになります。
名前空間とクラスターを登録することで、データをコピーまたは移動することなく、データへのアクセスを提供できます。Amazon Redshift でのクラスターと名前空間の登録の詳細については、「Amazon Redshift のクラスターや名前空間の AWS Glue Data Catalogへの登録」を参照してください。
Amazon Redshift では、データ共有を通じて、または名前空間とクラスターをデータカタログに登録することで、データ共有を実行できます。個々のデータベースオブジェクトレベルで動作するデータ共有では、テーブルまたはビューごとに共有を有効にする必要があります。これとは対照的に、名前空間はクラスターまたは名前空間レベルで関数を発行します。クラスターまたは名前空間をデータカタログに登録すると、その中のすべてのデータベースとテーブルが自動的に共有されます。個々のオブジェクトの共有を設定する必要はありません。
データカタログでは、名前空間またはクラスターごとにフェデレーティッドカタログを作成できます。データカタログ外のエンティティを指す場合、カタログはフェデレーティッドカタログと呼ばれます。Amazon Redshift 名前空間のテーブルとビューは、データカタログに個別のテーブルとして表示されます。フェデレーティッドデータベースは、同じアカウント内または Lake Formation の別のアカウント内の、選択した IAM プリンシパルおよび SAML ユーザーと共有できます。行と列のフィルター式を含めて、特定データへのアクセスを制限することもできます。詳細については、「Lake Formation でのデータフィルタリングとセルレベルのセキュリティ」を参照してください。
データカタログは、カタログ、データベース、テーブル (およびビュー) で構成される 3 レベルのメタデータ階層をサポートします。名前空間をデータカタログに登録すると、Amazon Redshift データ階層は次のようにデータカタログの 3 レベルの階層にマッピングされます。
-
Amazon Redshift 名前空間は、データカタログのマルチレベルカタログになります。
関連付けられた Amazon Redshift データベースは、データカタログにカタログとして登録されます。
-
Amazon Redshift スキーマは、データカタログ内のデータベースになります。
-
Amazon Redshift テーブルは、データカタログ内のテーブルになります。
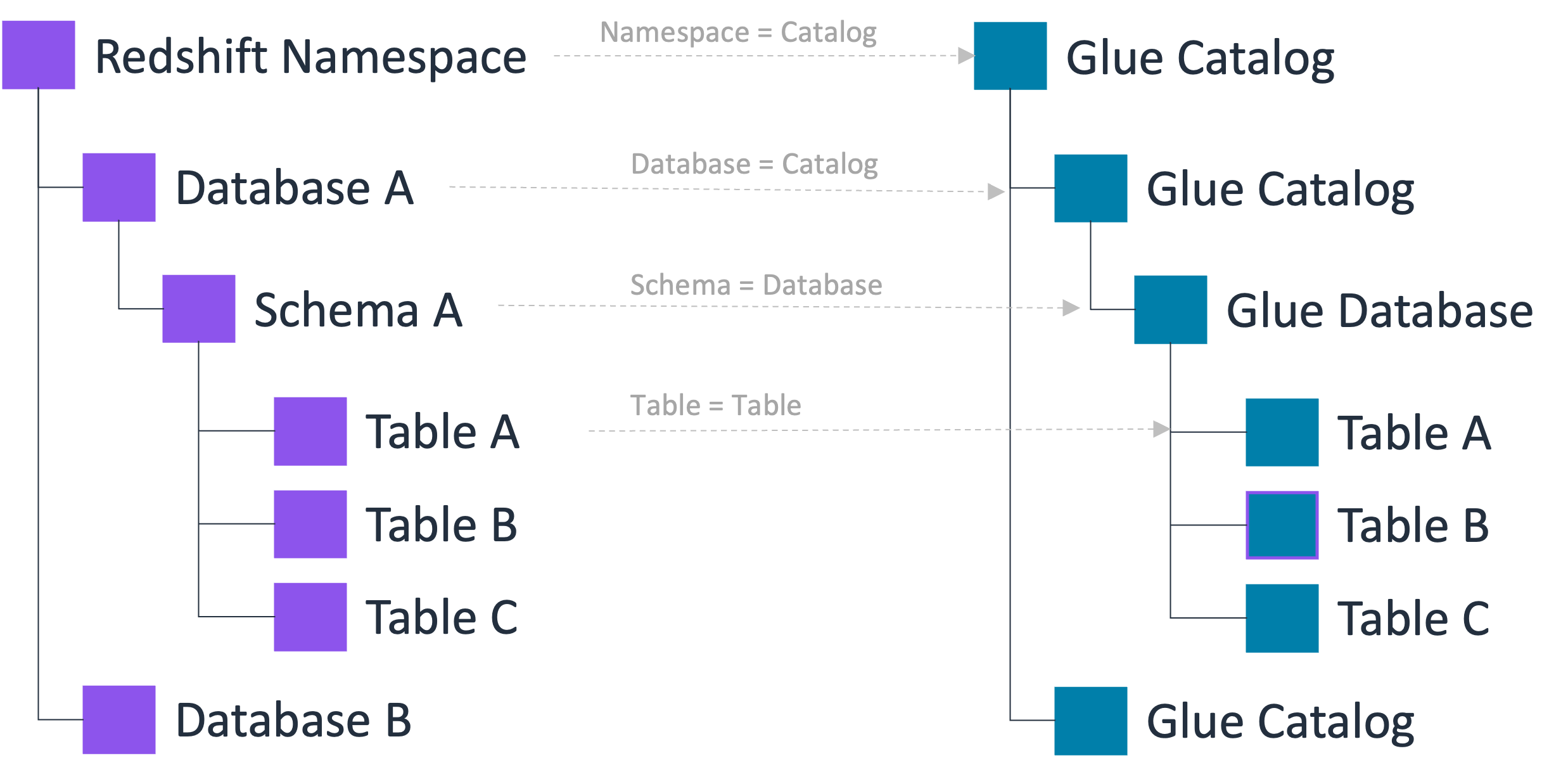
この 3 レベルのメタデータ階層では、データカタログの「catalog1/catalog2.database.table」という 3 つの部分からなる表記を使用して Amazon Redshift テーブルにアクセスできます。また、データチームは、Amazon Redshift が データカタログアカウント内のテーブルを整理するために使用するのと同じ組織を維持できます。
Lake Formation では、データカタログリソースのきめ細かなアクセスコントロールを使用して、Amazon Redshift からのデータを安全に管理できます。この統合により、共通のアクセスコントロールメカニズムを使用して、単一のカタログから分析データを管理、保護、クエリできます。
制限事項については、「Amazon Redshift データウェアハウスデータを に取り込む際の制限 AWS Glue Data Catalog」を参照してください。
トピック
主な利点
Amazon Redshift クラスターと名前空間を に登録 AWS Glue Data Catalog し、Amazon S3 データレイクと Amazon Redshift データウェアハウス間でデータを統合することで、次の利点が得られます。
統一されたクエリエクスペリエンス – データを移動したりコピーしたりせずに、Amazon EMR Serverless や Amazon Athena など、Apache Iceberg と互換性のある任意のクエリエンジンを使用して、Amazon Redshift マネージドデータとAmazon S3 バケット内のデータをクエリします。
-
サービス間の一貫したデータアクセス – データソースが Data Catalog に登録されているため、異なる AWS 分析サービスから同じフェデレーティッドデータソースにアクセスするときに、データパイプラインのデータベース名とテーブル名を更新する必要はありません。
きめ細かなアクセスコントロール – Lake Formation のアクセス許可を適用して、きめ細かなアクセスコントロールのアクセス許可を使用してフェデレーティッドデータソースへのアクセスを管理できます。
役割と責任
| ロール | 責任 |
| Amazon Redshift プロデューサークラスター管理者 |
クラスターまたは名前空間をデータカタログに登録します。 |
| Lake Formation データレイク管理者 |
クラスターまたは名前空間の招待を受け入れ、フェデレーティッドカタログを作成し、フェデレーティッドカタログへのアクセスを他のプリンシパルに付与します。 |
| Lake Formation 読み取り専用管理者 | フェデレーティッドカタログを検出し、フェデレーティッドカタログ内の Amazon Redshift テーブルをクエリします。 |
| データ転送ロール |
Amazon Redshift は、ユーザーに代わって Amazon S3 バケットとの間でデータを転送します。 |
以下は、Amazon Redshift 名前空間へのアクセスをユーザーに許可するための大まかな手順です。
-
Amazon Redshift では、プロデューサークラスター管理者はクラスターまたは名前空間をデータカタログに登録します。
-
データレイク管理者は、Amazon Redshift プロデューサークラスター管理者からの名前空間の招待を受け入れ、データカタログにフェデレーティッドカタログを作成します。
この手順を完了すると、データカタログ内で Amazon Redshift 名前空間カタログを管理できます。
-
カタログ、データベース、テーブルに対するアクセス許可をユーザーに付与します。名前空間カタログ全体またはテーブルのサブセットを、同じアカウント内または別のアカウント内のユーザーと共有できます。
