翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
Access Connect カスタマーデータレイク
データレイクにアクセスするには、 AWS コンソール、 AWS コマンドラインインターフェイス
分析データレイクにアクセスし、共有するデータを設定するには、次の 2 つの方法があります。
オプション 1 を使用してスケジューリングテーブルにアクセスできない場合は、オプション 2 を試してください。
オプション 1: Connect Customer コンソールを使用する
https://console.aws.amazon.com/connect/
で Connect Customer コンソールを開きます。 -
インスタンスページで、インスタンスエイリアスを選択します。インスタンスエイリアスは、Connect Customer URL に表示されるインスタンス名でもあります。次の図は、Connect Customer Virtual Contact Center インスタンスページと、インスタンスエイリアスを囲むボックスを示しています。
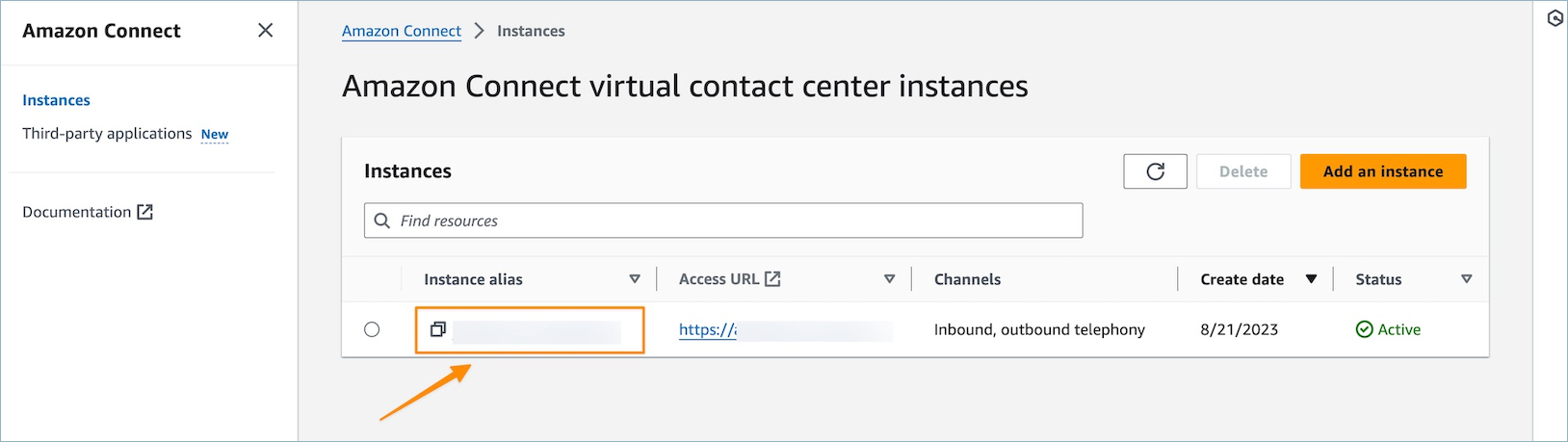
-
左側のナビゲーションメニューで、[分析ツール]、[データ共有の追加] の順に選択します。
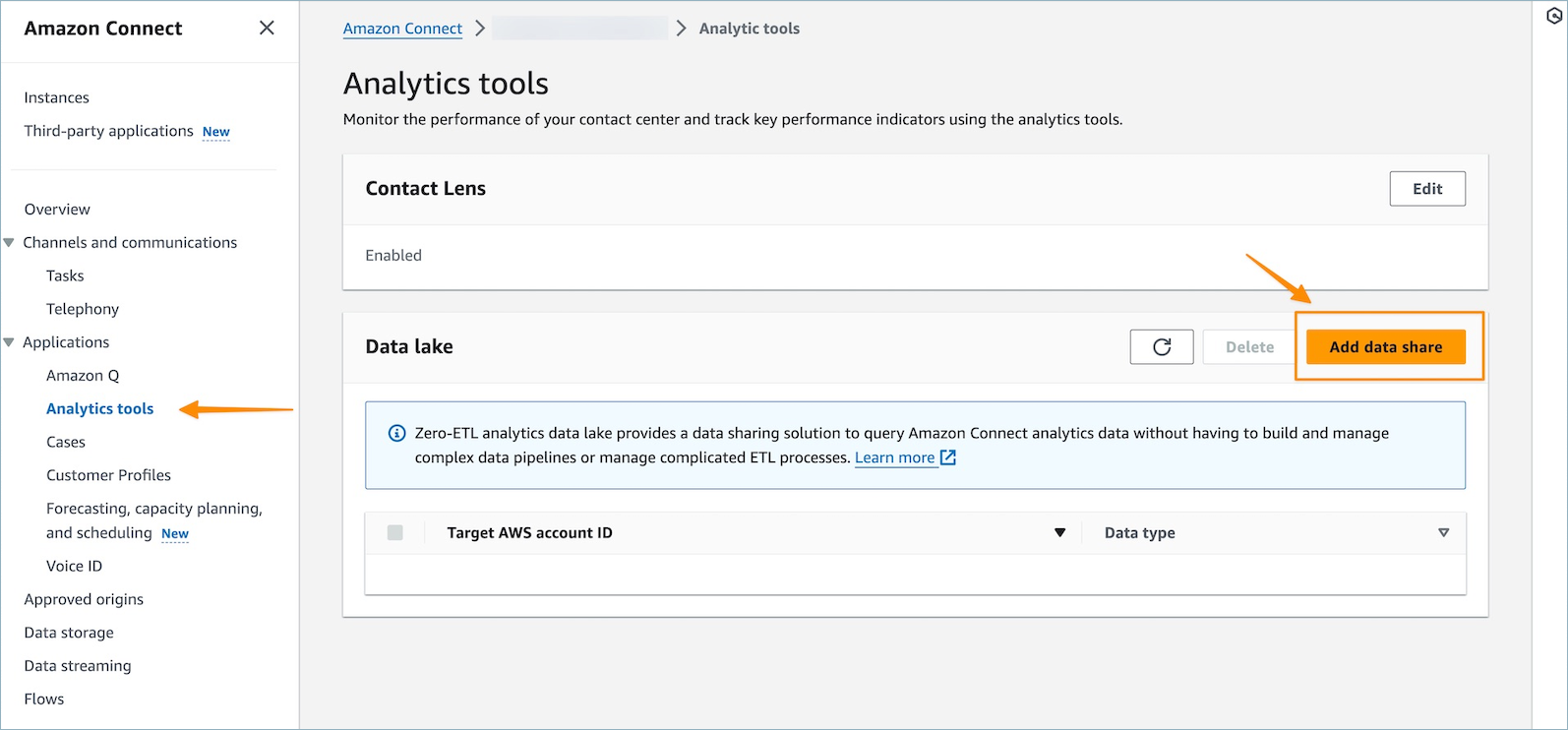
-
ターゲット AWS アカウント ID には、データ (コンシューマー) にアクセスするアカウントのアカウント AWS ID を指定します。これは、Connect Customer インスタンスのホストと同じ AWS アカウントでも、別の AWS アカウントでもかまいません。コンシューマーアカウントからアクセスする 1 つまたは複数のデータ型を選択し、[確認] を選択します。
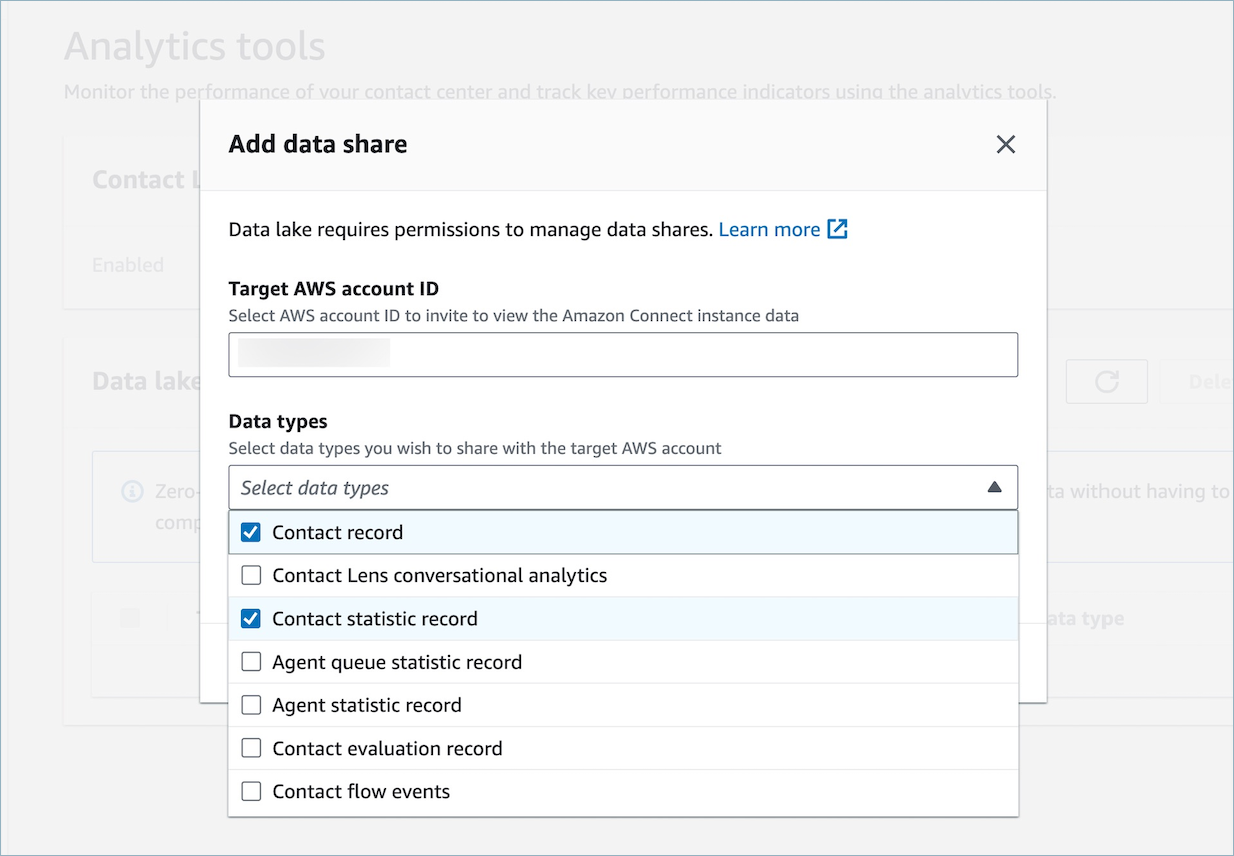
オプション 2: CLI または CloudShell を使用する
-
aws connect batch-associate-analytics-data-set --generate-cli-skeleton input > input_batch_association.jsonコマンドを実行して、generate Association apiリクエストファイルを生成します。 -
テキストエディタで、JSON ファイルを開いて次のテキストを入力します。
-
インスタンス ID – Connect Customer インスタンス ID。
-
DataSetID – 必須テーブルを入力します。必須テーブルの詳細については、「Connect Customer Analytics データレイクのテーブルを関連付ける」を参照してください。
-
TargetAccountId – データを共有するアカウント ID。
以下は、すべてのテーブルを含む JSON ファイルの例です。
{ "InstanceId":your_instance_id, "DataSetIds": [ "contact_record", "contact_flow_events", "contact_statistic_record", "contact_lens_conversational_analytics", "agent_queue_statistic_record", "agent_statistic_record", "contact_evaluation_record" ], "TargetAccountId":your_account_ID} -
-
aws connect batch-associate-analytics-data-set --cli-input-json file:コマンドを実行して、データレイクを単一のアカウントに関連付けます (このパスは JSON ファイルの場所に基づいています)。///path/to/request/file
