Amazon Braket Hybrid Jobs の使用方法
Amazon Braket Hybrid Jobs は、古典的 AWS リソースおよび量子処理ユニット (QPU) の両方を必要とするハイブリッド量子古典アルゴリズムを実行することができます。Hybrid Jobs は、リクエストされた古典的リソースを起動し、アルゴリズムを実行し、完了後にインスタンスを解放するように設計されているため、使用量に対してのみ料金が発生します。
Hybrid Jobs は、古典コンピューティングリソースと量子コンピューティングリソースの両方を使用する、長時間実行される反復アルゴリズムに最適です。Hybrid Jobs を使用する場合、実行するアルゴリズムを送信すると、アルゴリズムは、Braket により、スケーラブルでコンテナ化された環境で実行されます。アルゴリズムが完了したら、結果を取得できます。
さらに、ハイブリッドジョブから作成された量子タスクは、ターゲットとなる QPU デバイスへのキューイングにおいて優先順位が高くなるという利点があります。この優先順位付けにより、送信した量子コンピューティングが処理され、キューで待機している他のタスクよりも前に実行されます。これは、1 つの量子タスクの結果が以前の量子タスクの結果に依存する反復ハイブリッドアルゴリズムの場合に特に利点があります。このようなアルゴリズムの例としては、量子近似最適化アルゴリズム (QAOA)
Braket のハイブリッドジョブには、以下を使用してアクセスできます。
-
Amazon Braket API。
このセクションの内容:
Amazon Braket Hybrid Jobs を使用すべき場合
Amazon Braket Hybrid Jobs を使用すると、古典的なコンピューティングリソースと量子コンピューティングデバイスを組み合わせて、今日の量子系のパフォーマンスを最適化する、変分量子固有ソルバー (VQE) や量子近似最適化アルゴリズム (QAOA) などのハイブリッド量子古典アルゴリズムを実行できます。Amazon Braket Hybrid Jobs には、主に次の 3 つの利点があります。
-
パフォーマンス: Amazon Braket Hybrid Jobs は、お客様の環境からハイブリッドアルゴリズムを実行するよりも優れたパフォーマンスを提供します。ハイブリッドジョブは、実行中に、選択したターゲット QPU に優先的にアクセスできます。ハイブリッドジョブ内のタスクは、デバイスでキューに入っている他のタスクよりも先に実行されます。これにより、ハイブリッドアルゴリズムの実行時間が短くなり、予測しやすくなります。また、Amazon Braket Hybrid Jobs は、パラメトリックコンパイルもサポートしています。自由パラメータを使用して回路を送信できるため、Braket は回路を 1 回コンパイルするだけです。同じ回路に対する後続のパラメータ更新を再コンパイルする必要がないため、実行時間がはるかに短縮されます。
-
利便性: Amazon Braket Hybrid Jobs は、コンピューティング環境のセットアップと管理を簡素化し、ハイブリッドアルゴリズムの実行中も実行し続けることができます。アルゴリズムスクリプトを提供し、実行する量子デバイス (量子処理装置またはシミュレーター) を選択するだけでよいのです。Amazon Braket は、ターゲットデバイスが利用可能になるまで待機し、古典リソースを起動し、構築済みのコンテナ環境でワークロードを実行し、Amazon Simple Storage Service (Amazon S3) に結果を返し、コンピューティングリソースを解放します。
-
メトリクス: Amazon Braket Hybrid Jobs は、実行中のアルゴリズムに関するオンザフライのインサイトを提供し、カスタマイズ可能なアルゴリズムメトリクスをほぼリアルタイムで Amazon CloudWatch と Amazon Braket コンソールに配信することで、アルゴリズムの進行状況を追跡できます。
Amazon Braket Hybrid Jobs でハイブリッドジョブを実行する
Amazon Braket Hybrid Jobs でハイブリッドジョブを実行するには、まずアルゴリズムを定義する必要があります。Amazon Braket Python SDK
いずれの場合も、次に Amazon Braket API を使用してジョブを作成します。ここで、アルゴリズムスクリプトまたはコンテナを指定し、ハイブリッドジョブが使用するターゲット量子デバイスを選択し、さまざまなオプション設定から選択します。これらのオプション設定で提供されているデフォルト値は、ほとんどのユースケースで機能します。ターゲットデバイスにハイブリッドジョブを実行させる場合、QPU、オンデマンドシミュレーター (SV1、DM1、TN1 など)、または古典的なハイブリッドジョブインスタンス自体のいずれかを選択できます。オンデマンドシミュレーターまたは QPU を選択する場合は、ハイブリッドジョブコンテナはリモートデバイスに API コールを行います。埋め込みシミュレーターを選択する場合は、シミュレーターがアルゴリズムスクリプトと同じコンテナに埋め込まれます。PennyLane の稲妻シミュレーター
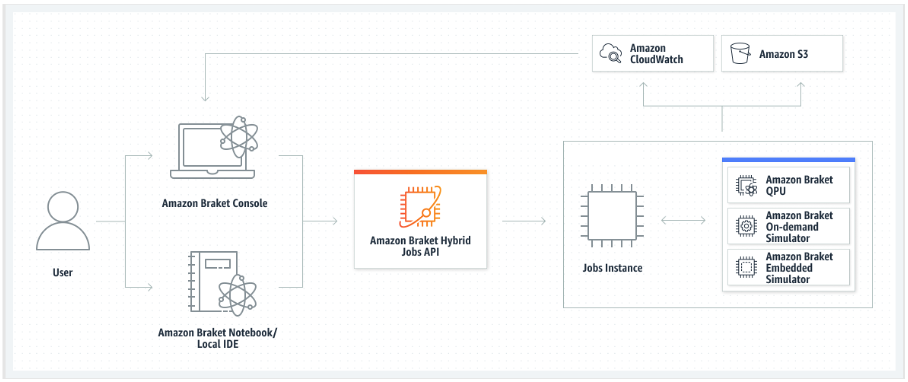
ターゲットデバイスがオンデマンドシミュレーターまたは埋め込みシミュレーターの場合、Amazon Braket はハイブリッドジョブの実行をすぐに開始します。ハイブリッドジョブインスタンスがスピンアップされて (API コールでインスタンスタイプをカスタマイズできます) アルゴリズムが実行され、結果が Amazon S3 に書き込まれてリソースが解放されます。このリソースの解放により、使用した分に対してのみお支払いいただくだけで済むようになります。
量子処理ユニット (QPU) あたりの同時ハイブリッドジョブの合計数は制限されています。現在、一度に QPU で実行できるハイブリッドジョブは 1 つのみです。許可される制限を超えないよう、実行できるハイブリッドジョブの数を制御するために、キューが使用されます。ターゲットデバイスが QPU の場合、ハイブリッドジョブは選択した QPU のジョブキューに最初に入ります。Amazon Braket は、必要なハイブリッドジョブインスタンスを起動し、ハイブリッドジョブをデバイスで実行します。アルゴリズムの期間中、ハイブリッドジョブには優先アクセスがあります。つまり、ハイブリッドジョブの量子タスクが数分に 1 回 QPU に送信されている場合、ジョブの量子タスクはデバイスでキューに入れられた他の Braket 量子タスクよりも先に実行されます。ハイブリッドジョブが完了すると、リソースが解放されるため、使用した分に対してのみ料金が発生します。
注記
デバイスはリージョナルであり、ハイブリッドジョブはプライマリデバイスと同じAWS リージョンで実行されます。
シミュレーターおよび QPU の両方のターゲットシナリオで、アルゴリズムの一部としてハミルトニアンのエネルギーなどのカスタムアルゴリズムメトリクスを定義するオプションがあります。これらのメトリクスは Amazon CloudWatch に自動的にレポートされ、そこからほぼリアルタイムに Amazon Braket コンソールに表示されます。
注記
GPU ベースのインスタンスを使用する場合は、Braket の埋め込みシミュレーターとともに使用できるいずれかの GPU ベースシミュレーター (例えば lightning.gpu など) を使用してください。いずれかの CPU ベース埋め込みシミュレーター (例えば lightning.qubit や braket:default-simulator など) を選択した場合、GPU が使用されないため、不要なコストが発生する可能性があります。
