翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
ハイブリッドジョブの作成
このセクションでは、Python スクリプトを使用してハイブリッドジョブを作成する方法を示します。または、ハイブリッドジョブを作成する別の方法として任意の統合開発環境 (IDE) や Braket ノートブックなどのローカル Python コードを使用する手順については、「ローカルコードをハイブリッドジョブとして実行する」を参照してください。
このセクションの内容:
作成して実行
ハイブリッドジョブを実行する権限を持つロールを取得したら、次に進む準備が整ったことになります。最初の Braket ハイブリッドジョブの重要部分は、アルゴリズムスクリプトです。実行するアルゴリズムを定義し、アルゴリズムの一部である古典的な論理と量子タスクが含まれています。アルゴリズムスクリプトに加えて、他の依存関係ファイルを指定することもできます。アルゴリズムスクリプトとその依存関係は、ソースモジュールと呼ばれます。エントリポイントは、ハイブリッドジョブの開始時にソースモジュールで実行される最初のファイルまたは関数を定義します。
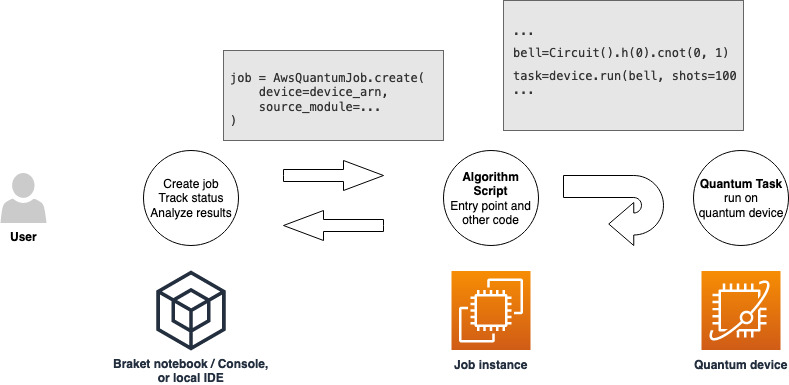
まず、5 つのベル状態を作成し、対応する測定結果を出力するアルゴリズムスクリプトの基本的な例を考えてみましょう。
import os from braket.aws import AwsDevice from braket.circuits import Circuit def start_here(): print("Test job started!") # Use the device declared in the job script device = AwsDevice(os.environ["AMZN_BRAKET_DEVICE_ARN"]) bell = Circuit().h(0).cnot(0, 1) for count in range(5): task = device.run(bell, shots=100) print(task.result().measurement_counts) print("Test job completed!")
このファイルをalgorithm_script.py という名前で、Braket ノートブックまたはローカル環境の現在の作業ディレクトリに保存します。algorithm_script.py ファイルには計画されたエントリーポイントとして start_here() が含まれます。
次に、algorithm_script.py ファイルと同じディレクトリに Python ファイルまたは Python ノートブックを作成します。このスクリプトは、ハイブリッドジョブを開始し、必要なステータスや主要な結果の出力などの非同期処理を扱っています。このスクリプトでは、少なくともハイブリッドジョブスクリプトとプライマリデバイスを指定する必要があります。
注記
Braket ノートブックを作成する方法、または algorithm_script.py ファイルなどのファイルをノートブックと同じディレクトリにアップロードする方法の詳細については、「Run your first circuit using the Amazon Braket Python SDK」を参照してください。
この基本的な最初のケースでは、シミュレーターをターゲットにします。ターゲットとする量子デバイス、シミュレーター、または実際の量子処理装置 (QPU) のいずれのタイプであっても、次のスクリプトでは、device でハイブリッドジョブをスケジュールするために使用され、アルゴリズムスクリプトで環境変数 AMZN_BRAKET_DEVICE_ARN として使用できます。
注記
ハイブリッドジョブ AWS リージョン の で使用できるデバイスのみを使用できます。Amazon Braket SDK はこの AWS リージョンを自動的に選択します。例えば、us-east-1 のハイブリッドジョブでは、IonQ、SV1、DM1、および TN1 デバイスを使用できますが、Rigetti デバイスは使用できません。
シミュレーターの代わりに量子コンピュータを選択した場合、Braket は優先アクセスですべての量子タスクを実行するようにハイブリッドジョブをスケジュールします。
from braket.aws import AwsQuantumJob from braket.devices import Devices job = AwsQuantumJob.create( Devices.Amazon.SV1, source_module="algorithm_script.py", entry_point="algorithm_script:start_here", wait_until_complete=True )
パラメータ wait_until_complete=True は、冗長モードを設定して、ジョブが実行中に実際のジョブからの出力を出力するようにします。以下の例のような出力が表示されます。
Initializing Braket Job: arn:aws:braket:us-west-2:111122223333:job/braket-job-default-123456789012 Job queue position: 1 Job queue position: 1 Job queue position: 1 .............. . . . Beginning Setup Checking for Additional Requirements Additional Requirements Check Finished Running Code As Process Test job started! Counter({'00': 58, '11': 42}) Counter({'00': 55, '11': 45}) Counter({'11': 51, '00': 49}) Counter({'00': 56, '11': 44}) Counter({'11': 56, '00': 44}) Test job completed! Code Run Finished 2025-09-24 23:13:40,962 sagemaker-training-toolkit INFO Reporting training SUCCESS
注記
AwsQuantumJob.create
結果をモニタリングする
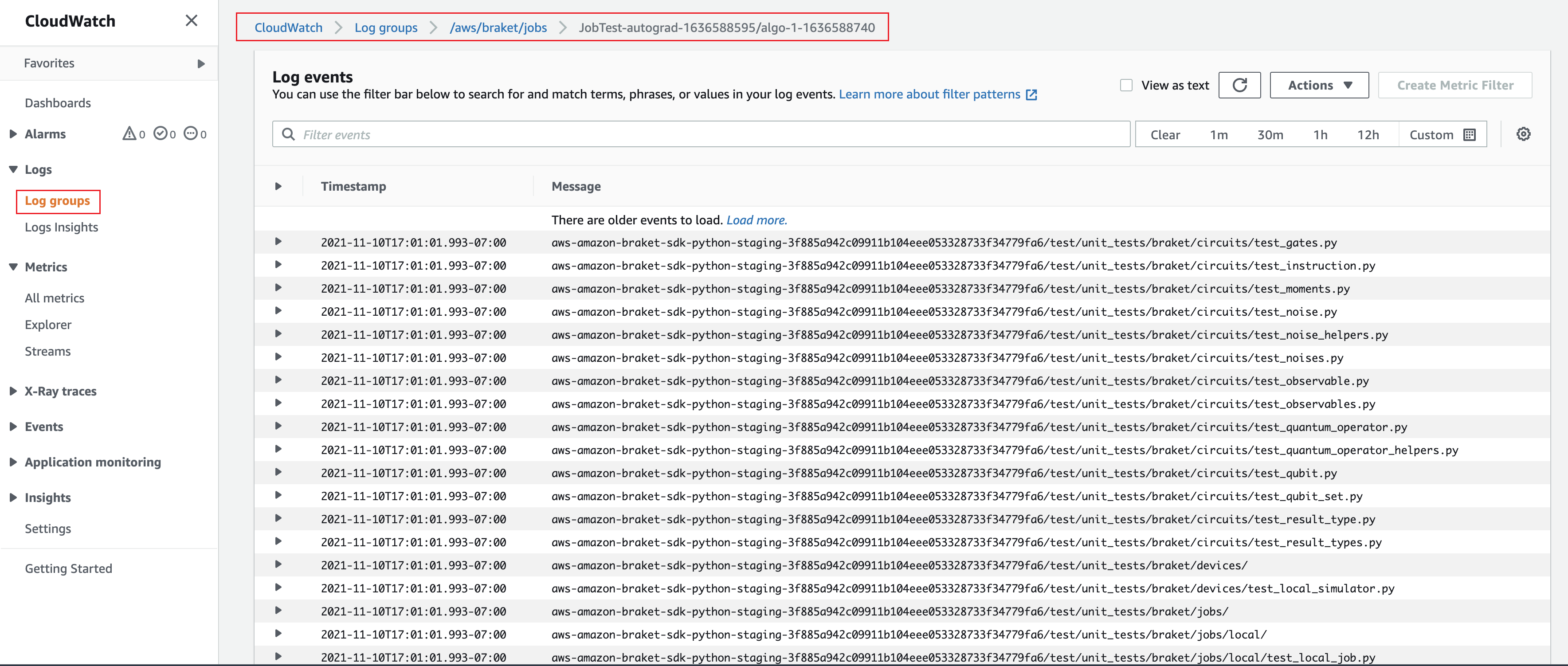
または、Amazon CloudWatch からのログ出力にアクセスすることもできます。これを行うには、ジョブ詳細ページの左側のメニューにある [ロググループ] タブに移動し、ロググループ aws/braket/jobs をクリックして、ジョブ名を含むログストリームを選択します。これは、上記の例では braket-job-default-1631915042705/algo-1-1631915190 です。
また、コンソールでハイブリッドジョブのステータスを表示するには、[ハイブリッドジョブ] ページを選択して [設定] を選択します。
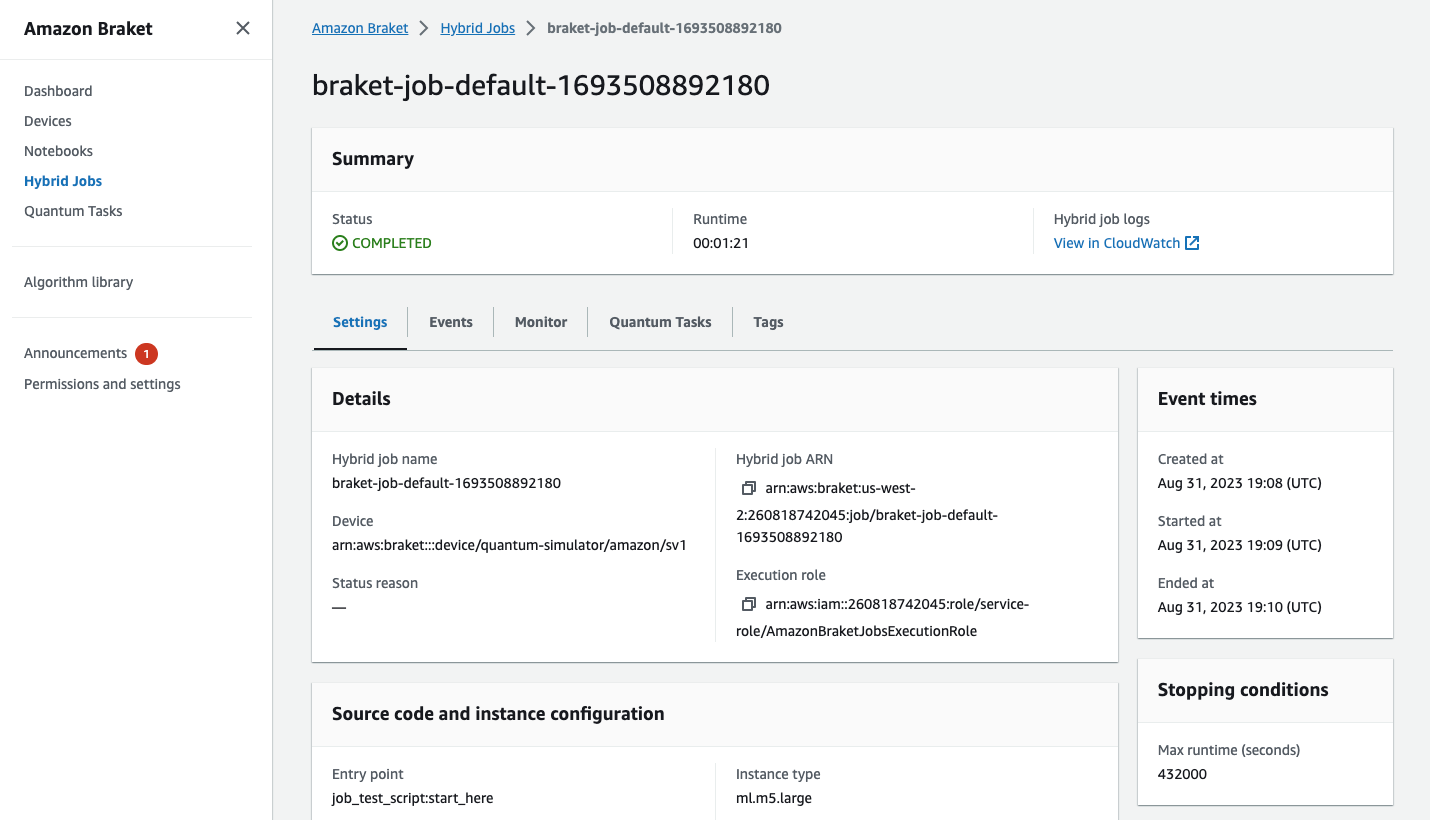
ハイブリッドジョブが実行されている間、Amazon S3 にアーティファクトがいくつか生成されます。デフォルトの S3 バケット名は amazon-braket-<region>-<accountid> で、コンテンツは jobs/<jobname>/<timestamp> ディレクトリにあります。Braket Python SDK でハイブリッドジョブを作成する際、別の code_location を指定することで、これらのアーティファクトが保存される S3 の場所を設定できます。
注記
この S3 バケットは、ジョブスクリプト AWS リージョン と同じ に配置する必要があります。
jobs/<jobname>/<timestamp> ディレクトリには、model.tar.gz ファイル内のエントリポイントスクリプトからの出力を含むサブフォルダが含まれています。script というディレクトリもあり、この中にある source.tar.gz ファイルにはアルゴリズムスクリプトのアーティファクトが含まれています。実際の量子タスクの結果は、jobs/<jobname>/tasks という名前のディレクトリにあります。
結果を保存する
アルゴリズムスクリプトによって生成された結果を保存することで、ハイブリッドジョブスクリプトのハイブリッドジョブオブジェクトと Amazon S3 の出力フォルダ (model.tar.gz という名前の tar zip ファイル内) からそれらを使用できるようにすることができます。
出力は JavaScript Object Notation (JSON) 形式を使用してファイルに保存する必要があります。numpy 配列の場合のように、データをテキストに簡単にシリアル化できない場合は、ピクル化データ形式を使用してシリアル化するオプションを入力として渡すことができます。詳細については、「braket.jobs.data_persistence module
ハイブリッドジョブの結果を保存するには、#ADD でコメントされた次の行を algorithm_script.py ファイルに追加します。
import os from braket.aws import AwsDevice from braket.circuits import Circuit from braket.jobs import save_job_result # ADD def start_here(): print("Test job started!") device = AwsDevice(os.environ['AMZN_BRAKET_DEVICE_ARN']) results = [] # ADD bell = Circuit().h(0).cnot(0, 1) for count in range(5): task = device.run(bell, shots=100) print(task.result().measurement_counts) results.append(task.result().measurement_counts) # ADD save_job_result({"measurement_counts": results}) # ADD print("Test job completed!")
次に、#ADD でコメントされた行 print(job.result()) を追加することで、ジョブスクリプトのジョブの結果を表示できます。
import time from braket.aws import AwsQuantumJob job = AwsQuantumJob.create( source_module="algorithm_script.py", entry_point="algorithm_script:start_here", device="arn:aws:braket:::device/quantum-simulator/amazon/sv1", ) print(job.arn) while job.state() not in AwsQuantumJob.TERMINAL_STATES: print(job.state()) time.sleep(10) print(job.state()) print(job.result()) # ADD
この例では、wait_until_complete=True を削除して冗長出力を抑制します。デバッグ用に再度追加できます。このハイブリッドジョブを実行すると、識別子と job-arn が出力され、その後、10 秒ごとにハイブリッドジョブの状態が出力されて、ハイブリッドジョブが COMPLETED になったら、ベル回路の結果が示されます。次の例を参照してください。
arn:aws:braket:us-west-2:111122223333:job/braket-job-default-123456789012 INITIALIZED RUNNING RUNNING RUNNING RUNNING RUNNING RUNNING RUNNING RUNNING RUNNING RUNNING ... RUNNING RUNNING COMPLETED {'measurement_counts': [{'11': 53, '00': 47},..., {'00': 51, '11': 49}]}
チェックポイントの使用
チェックポイントを使用して、ハイブリッドジョブの中間イテレーションを保存できます。前のセクションのアルゴリズムスクリプトの例では、#ADD でコメントされた次の行を追加して、チェックポイントファイルを作成します。
from braket.aws import AwsDevice from braket.circuits import Circuit from braket.jobs import save_job_checkpoint # ADD import os def start_here(): print("Test job starts!") device = AwsDevice(os.environ["AMZN_BRAKET_DEVICE_ARN"]) # ADD the following code job_name = os.environ["AMZN_BRAKET_JOB_NAME"] save_job_checkpoint(checkpoint_data={"data": f"data for checkpoint from {job_name}"}, checkpoint_file_suffix="checkpoint-1") # End of ADD bell = Circuit().h(0).cnot(0, 1) for count in range(5): task = device.run(bell, shots=100) print(task.result().measurement_counts) print("Test hybrid job completed!")
ハイブリッドジョブを実行すると、デフォルトの /opt/jobs/checkpoints パスを使用して、チェックポイントディレクトリのハイブリッドジョブアーティファクトにファイル <jobname>-checkpoint-1.json が作成されます。このデフォルトパスを変更しない限り、ハイブリッドジョブスクリプトは変更されません。
前のハイブリッドジョブによって生成されたチェックポイントからハイブリッドジョブをロードする場合、アルゴリズムスクリプトは from braket.jobs import load_job_checkpoint を使用します。アルゴリズムスクリプトにロードするロジックは次のとおりです。
from braket.jobs import load_job_checkpoint checkpoint_1 = load_job_checkpoint( "previous_job_name", checkpoint_file_suffix="checkpoint-1", )
このチェックポイントをロードした後、checkpoint-1 にロードされたコンテンツに基づいてロジックを続行できます。
注記
checkpoint_file_suffix は、チェックポイントの作成時に以前に指定した接尾辞と一致する必要があります。
オーケストレーションスクリプトでは、前のハイブリッドジョブ job-arn を、#ADD でコメントされた行で指定する必要があります。
from braket.aws import AwsQuantumJob job = AwsQuantumJob.create( source_module="source_dir", entry_point="source_dir.algorithm_script:start_here", device="arn:aws:braket:::device/quantum-simulator/amazon/sv1", copy_checkpoints_from_job="<previous-job-ARN>", #ADD )
