翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
Amazon Bedrock ナレッジベースの仕組み
Amazon Bedrock のナレッジベースは、検索拡張生成 (RAG) の活用に役立ちます。RAG は、データストアから情報を取得して、大規模言語モデル (LLM) によって生成されるレスポンスを拡張する一般的な手法です。データソースを使用してナレッジベースを設定すると、アプリケーションはナレッジベースに対してクエリを実行し、ソースからの直接の引用、またはクエリ結果から生成される自然なレスポンスによってクエリに答える情報を返すことができます。
Amazon Bedrock ナレッジベースを使用すると、ナレッジベースでのクエリから得られるコンテキストによって強化されたアプリケーションを構築できます。パイプライン構築の面倒な作業から解放され、すぐに使える RAG ソリューションを提供することでアプリケーションの構築時間を短縮できるため、市場投入までの時間を短縮できます。ナレッジベースを追加すると、プライベートデータを使用できるようにモデルを継続的にトレーニングする必要がなくなるため、コスト効率が向上します。
以下の図は、RAG がどのように実行されるかを概略的に示しています。ナレッジベースは、このプロセスのいくつかのステップを自動化することで、RAG の設定と実装を簡素化します。
非構造化データの前処理
非構造化プライベートデータ (構造化データストアに存在しないデータ) を効果的に検索できるようにするには、データをテキストに変換してから、管理しやすいかたまりに分割するのが一般的です。このかたまり (チャンク) は埋め込みに変換され、元のドキュメントへのマッピングを維持したままベクトルインデックスに書き込まれます。これらの埋め込みは、クエリとデータソースからのテキストの意味上の類似性を判断するために使用されます。以下の図は、ベクトルデータベース用のデータの前処理を示しています。
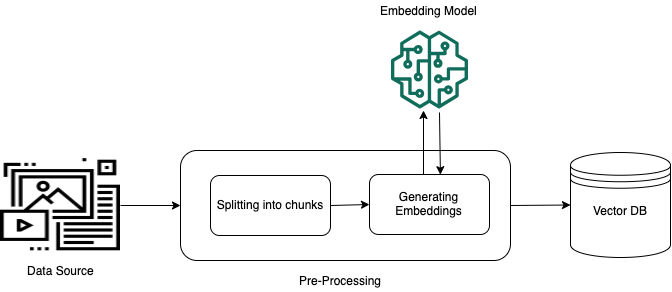
ベクトル埋め込みとは、テキストの各チャンクを表す一連の数値です。モデルは、各テキストチャンクをベクトルと呼ばれる一連の数値に変換し、テキストを数学的に比較できるようにします。これらのベクトルは、浮動小数点数 (float32) またはバイナリ数のいずれかです。Amazon Bedrock でサポートされているほとんどの埋め込みモデルは、デフォルトで浮動小数点ベクトルを使用します。ただし、一部のモデルはバイナリベクトルをサポートしています。バイナリ埋め込みモデルを選択する場合は、バイナリベクトルをサポートするモデルとベクトルストアも選択する必要があります。
1 ディメンションあたり 1 ビットしか使用しないバイナリベクトルは、1 ディメンションあたり 32 ビットを使用する浮動小数点 (float32) ベクトルほどストレージにコストがかかりません。ただし、バイナリベクトルは、テキストの表現が浮動小数点ベクトルほど正確ではありません。
次の例は、3 つの表現のテキストを示しています。
| 表記 | 値 |
|---|---|
| テキスト | "Amazon Bedrock は、主要な AI 企業や Amazon が提供する高パフォーマンスな基盤モデルを使用します。" |
| 浮動小数点ベクトル | [0.041..., 0.056..., -0.018..., -0.012..., -0.020...,
...] |
| バイナリベクトル | [1,1,0,0,0, ...] |
ランタイムの実行
実行時には、埋め込みモデルを使用してユーザーのクエリをベクトルに変換します。次に、ドキュメントベクトルとユーザークエリベクトルを比較して、ベクトルインデックスをクエリしてユーザークエリの検索対象に意味的に類似したチャンクを検索します。最後のステップでは、ベクトルインデックスから取得したチャンクの追加コンテキストがユーザープロンプトに追加されます。その後、追加のコンテキストと共にプロンプトがモデルに送信され、ユーザーへのレスポンスが生成されます。以下の画像は、RAG が実行時にどのように動作してユーザークエリへのレスポンスを補強するかを示しています。
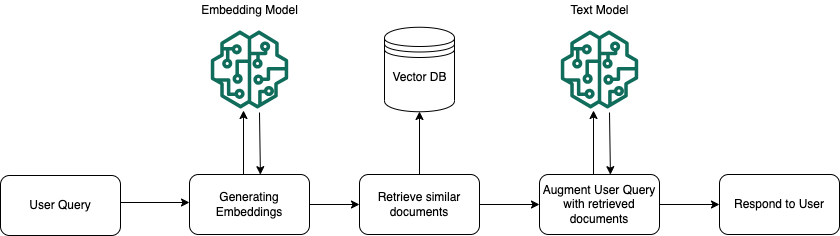
データをナレッジベースに変換する方法、ナレッジベースの設定後にナレッジベースへのクエリを実行する方法、取り込み中にデータソースに適用できるカスタマイズの詳細については、以下のトピックを参照してください。
