Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Passaggio 3: implementa un caso d'uso utilizzando la procedura guidata del dashboard di distribuzione
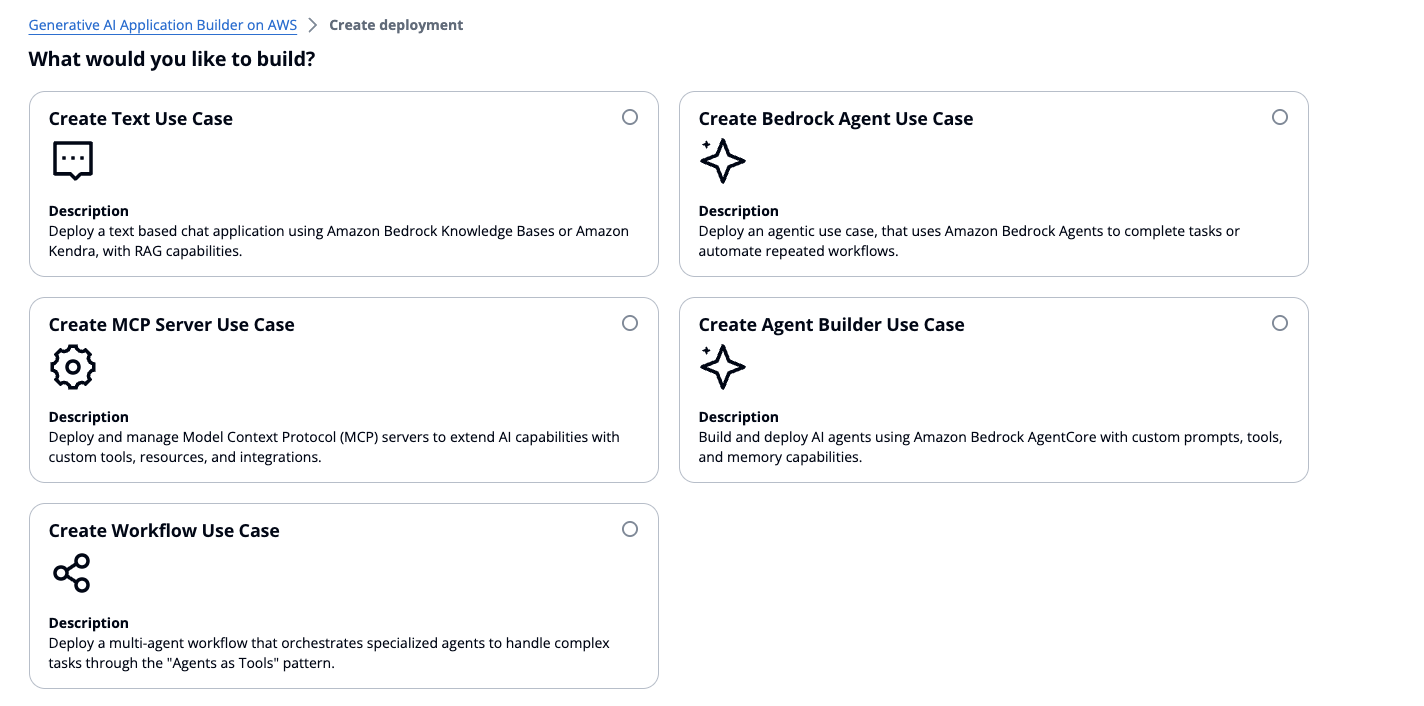
Nella procedura guidata del dashboard di distribuzione, devi scegliere tra le seguenti opzioni:
-
Caso d'uso testuale: distribuisce un'applicazione di chat, con funzionalità RAG opzionali
-
Caso d'uso di Bedrock Agent: utilizza Amazon Bedrock Agents per completare attività o automatizzare flussi di lavoro ripetuti
-
Server MCP: distribuisci e gestisci i server MCP con metodi gateway o di runtime
-
Agent Builder: crea e distribuisci agenti personalizzati AgentCore con l'integrazione MCP e la gestione della memoria
-
Workflow Builder - Orchestra più agenti Agent Builder utilizzando la delega gerarchica
Mostra cinque opzioni: Create Text use Case, Create Bedrock Agent Use Case, Create MCP Server Use Case, Create Agent Builder Use Case o Create Workflow Use Case.
Fase 3a: Implementazione di un caso d'uso testuale
Questa sezione fornisce istruzioni per la distribuzione di un caso d'uso di tipo Text.
Seleziona il caso d'uso
Quando scegli il caso d'uso Crea testo, l'interfaccia utente apre la schermata Seleziona caso d'uso. Inserisci le informazioni che seguono:
-
Usa il nome del caso.
-
Indirizzo e-mail opzionale per l'utente predefinito del caso d'uso da aggiungere al pool di utenti di Amazon Cognito per il caso d'uso e a cui assegnare le autorizzazioni per interagire con esso.
-
Se desideri implementare un'interfaccia utente con questo caso d'uso. Se non desideri implementare un'interfaccia utente con lo use case, puoi utilizzare gli endpoint API distribuiti per utilizzarli con la tua applicazione.
Dettagli dei casi d’uso
La fase relativa ai dettagli del caso d'uso consente di configurare impostazioni aggiuntive per la distribuzione.
Per impostazione predefinita, lo use case Text crea e configura un pool di utenti Amazon Cognito per te quando la soluzione implementa la dashboard di distribuzione. La soluzione autentica nuovi casi d'uso con un client appena creato nello stesso pool di utenti. Tuttavia, puoi fornire un ID del pool di utenti e un ID client esistenti in questa fase se desideri utilizzare il tuo pool di utenti e client Amazon Cognito con lo use case.
Importante
Gli utenti amministratori hanno accesso a tutti i casi d'uso distribuiti quando il pool di utenti di Amazon Cognito viene creato tramite la procedura guidata di distribuzione. Se fornisci il tuo pool di utenti durante la distribuzione, devi assicurarti che l'amministratore disponga delle autorizzazioni per accedere ai casi d'uso distribuiti.
Dovrai inoltre aggiornare la richiamata consentita URLs e la disconnessione consentita nei client dell'app URLs in Cognito. Per farlo:
-
Passa alla console Cognito
-
Scegli User Pools (Pool di utenti).
-
Scegli il tuo pool di utenti.
-
Scegli App Clients nel menu a sinistra.
-
Scegli il client dell'app che desideri modificare.
-
Scegli la scheda Pagine di accesso.
-
Scegli Modifica e aggiungi il tuo URLs.
-
Scegli Save changes (Salva modifiche).
Inoltre, se devi aggiungere altri utenti a un caso d'uso, consulta la sezione Gestione del pool di utenti di Cognito.
Seleziona la configurazione di rete
Questa procedura guidata consente di implementare lo use case con un Amazon Virtual Private Cloud (Amazon
Selezione del modello
Nella fase Seleziona il modello, puoi scegliere il fornitore del modello dal menu a discesa. Sono disponibili due opzioni: Bedrock e. SageMaker
Se si seleziona SageMaker, è possibile creare un endpoint del modello SageMaker AI nella console SageMaker AI e fornire lo schema di input previsto dal modello e l'output JSONPath per la risposta LLM. Puoi fare riferimento alla sezione Using Amazon SageMaker AI as an LLM Provider e agli esempi di payload SageMaker AI
Se selezioni Amazon Bedrock, ti verranno presentate quattro opzioni:
-
Modelli Quick Start: inizia rapidamente con una raccolta di modelli con price/performance caratteristiche diverse. Consigliato per creare le tue prime app. Questa opzione consente di selezionare il nome di un modello dall'elenco fornito.
-
Altri modelli Foundation: accedi alla gamma completa di modelli di fondazione con diverse capacità e specializzazioni. Questa opzione consente di inserire l'ID del modello per il modello di fondazione Bedrock on-demand desiderato.
-
Profili di inferenza: i profili di inferenza sfruttano l'inferenza interregionale di Bedrock per aumentare la velocità effettiva e migliorare la resilienza instradando le richieste su più regioni AWS durante i picchi di utilizzo. Questa opzione ti consente di inserire l'ID del profilo di inferenza che desideri utilizzare.
-
Modelli forniti: capacità di throughput dedicata per carichi di lavoro di produzione che richiedono prestazioni costanti. Questa opzione ti consente di inserire l'ARN del provisioned/custom modello da utilizzare da Amazon Bedrock.
La fase di selezione del modello consente inoltre di scegliere le impostazioni avanzate del modello. Consulta le impostazioni Advanced LLM per dettagli sulla configurazione di Amazon Bedrock Guardrails, sul throughput assegnato per Amazon Bedrock e sui parametri aggiuntivi del modello.
Inferenza tra regioni
L'inferenza tra regioni aiuta gli utenti di Amazon Bedrock a gestire senza problemi i picchi di traffico non pianificati utilizzando l'elaborazione in diverse regioni AWS. Per utilizzare l'inferenza tra regioni, è necessario il profilo di inferenza. Un profilo di inferenza è un'astrazione su un pool di risorse su richiesta da un set configurato di regioni AWS. Può indirizzare la richiesta di inferenza, proveniente dalla regione di origine, verso un'altra regione configurata in quel pool. Ciò consente la distribuzione del traffico su più regioni AWS. Questo aiuta a consentire un throughput più elevato e una maggiore resilienza durante i periodi di picco della domanda.
I profili di inferenza prendono il nome dal modello e dalle regioni che supportano. È necessario richiamare un profilo di inferenza da una delle regioni che include. Ad esempio, come illustrato nella tabella seguente, l'ID del profilo di inferenza us.anthropic.claude-3-haiku-20240307-v1:0 consente la distribuzione del traffico tra us-east-1 le us-west-2 regioni del modello scelto. Alcuni modelli sono disponibili solo con un profilo di inferenza in una particolare regione.
| Profilo di inferenza | ID del profilo di inferenza | Regioni incluse |
|---|---|---|
|
US Anthropic Claude 3 Haiku |
|
Stati Uniti orientali (Virginia settentrionale) ( Stati Uniti occidentali (Oregon) ( |
Se desideri utilizzare un ID del profilo di inferenza anziché un ID del modello, devi identificare l'ID del profilo di inferenza appropriato. Per ulteriori informazioni, consulta Regioni e modelli supportati per i profili di inferenza nella Amazon Bedrock User Guide. Nella console Amazon Bedrock
Dopo aver identificato l'ID del profilo di inferenza da utilizzare, puoi utilizzarlo durante la fase di selezione del modello eseguendo le seguenti operazioni:
-
Seleziona Amazon Bedrock come fornitore del modello.
-
Seleziona l'opzione del pulsante radio Inference Profiles.
-
Inserisci l'ID del tuo profilo di inferenza nella casella di testo visualizzata.
Per ulteriori dettagli sui profili di inferenza, consulta Improve resilience with cross-region inference nella Amazon Bedrock User Guide.
Seleziona la knowledge base
Se stai cercando di implementare un caso d'uso diverso da Retrieval Augmented Generation (RAG), puoi saltare questo passaggio.
Tuttavia, se desideri abilitare RAG come parte della tua distribuzione, ora puoi fornire un Amazon Kendra Index Id preconfigurato o un Amazon Bedrock Knowledge Base ID. Puoi anche creare un nuovo Amazon Kendra Index da utilizzare con la soluzione. La soluzione attualmente supporta Amazon Kendra e Amazon Bedrock Knowledge Base come knowledge base per la distribuzione di use case basati su RAG.
Consulta la sezione Configurazione di una Knowledge Base per le linee guida sull'inserimento di dati nella knowledge base da utilizzare con la distribuzione basata su RAG.
Configurazioni RAG avanzate
La procedura guidata consente di selezionare opzioni avanzate da utilizzare con l'implementazione RAG, ad esempio il numero di documenti da recuperare ogni volta che viene inviata una query alla knowledge base, una risposta testuale statica dal LLM quando non viene trovato alcun documento nella knowledge base, se si desidera visualizzare le fonti dei documenti con la risposta LLM per i controlli di integrità, ecc. Puoi inoltre configurare configurazioni specifiche della knowledge base per Amazon Kendra, ad esempio Role-based Access Control (RBAC) o Override Search Type quando usi Amazon Serverless con Amazon Bedrock Knowledge Bases. OpenSearch Consulta la sezione Impostazioni avanzate della Knowledge Base per maggiori dettagli su queste impostazioni avanzate.
Nota
La Knowledge Base deve trovarsi nello stesso account e nella stessa regione degli stack di dashboard di Deployment e case case distribuiti.
Seleziona i prompt e i limiti dei token
In questo passaggio, puoi configurare il prompt per l'utilizzo con l'LLM. I prompt possono richiedere segnaposti come, e. {input} {history} {context} Questi segnaposto indicano all'LLM da dove attingere l'input dell'utente, la cronologia delle conversazioni e le informazioni recuperate dalla knowledge base.
-
Per il fornitore di modelli Bedrock, è necessario fornire il prompt di sistema, che non presenta restrizioni per un caso d'uso diverso da RAG. La richiesta di chiarimento delle ambiguità per il fornitore di modelli Bedrock richiede tuttavia un minimo di due segnaposto e
{input}{history} -
Per quanto riguarda il fornitore SageMaker del modello, il sistema e le istruzioni di disambiguazione, entrambi richiedono un minimo di due segnaposto: e.
{input}{history} -
Per i casi d'uso RAG, per ogni fornitore di modelli, è richiesto in aggiunta il segnaposto.
{context}
Per ulteriori informazioni, consulta Configurazione delle istruzioni. Puoi anche fare riferimento alla sezione Suggerimenti per la gestione dei limiti dei token del modello mentre selezioni le dimensioni dei limiti dei token per i tuoi prompt.
Abilita l'input multimodale
Questo passaggio consente di abilitare le funzionalità di input multimodali per il proprio caso d'uso. Se abilitata, gli utenti possono caricare e inviare immagini e documenti insieme alle loro query di testo.
Tipi di file e vincoli supportati:
-
Immagini: fino a 20 immagini per messaggio. Ogni immagine non deve avere più di 3,75 MB di dimensione e 8.000 px di altezza e larghezza. Formati supportati: png, jpeg, gif, webp
-
Documenti: fino a 5 documenti per messaggio. Ogni documento non deve avere una dimensione superiore a 4,5 MB. Formati supportati: pdf, csv, doc, docx, xls, xlsx, html, txt, md
Come usare l'input multimodale:
-
Abilita il MultimodalEnabledparametro durante la distribuzione dei casi d'uso
-
Nell'interfaccia di chat, gli utenti possono caricare file in due modi:
-
Facendo clic sul pulsante di caricamento nella casella di immissione della chat, oppure
-
Trascinare e rilasciare i file direttamente nell'interfaccia della chat
-
-
I file vengono caricati su Amazon S3 ed elaborati dal modello selezionato
-
I file caricati vengono eliminati automaticamente dopo 48 ore
Monitoraggio dello stato dei file:
DevOps gli utenti possono monitorare i metadati dei file in DynamoDB, che includono il tempo di caricamento e lo stato di elaborazione. I file possono avere i seguenti stati:
-
in sospeso: il caricamento del file è stato avviato ma non ancora completato. Questo è lo stato iniziale quando viene generato un URL predefinito.
-
caricato - Il file è stato caricato con successo su S3 ed è pronto per essere elaborato dal modello.
-
cancellato: il file è stato eliminato dall'utente e non dovrebbe più essere accessibile per l'elaborazione.
-
non valido: controlli di convalida del file non riusciti (ad esempio, mancata corrispondenza del tipo di file o errore di convalida di sicurezza).
I file in sospeso che non vengono mai caricati verranno ripuliti automaticamente alla scadenza del TTL. Solo i file con lo stato di caricamento possono essere elaborati dal modello.
Il bucket multimodale S3 e la tabella di metadati DynamoDB sono disponibili negli output del Deployment Dashboard con le chiavi e, rispettivamente. MultimodalDataBucketName MultimodalDataMetadataTable
Nota
Non tutti i modelli supportano l'input multimodale. Assicurati che il modello selezionato supporti l'elaborazione di immagini e documenti prima di attivare questa funzione. Consulta i modelli di base supportati nella documentazione di Amazon Bedrock per verificare quale modello supporta Image come modalità di input.
Importante
I file caricati dagli utenti vengono archiviati in Amazon S3 con una politica del ciclo di vita di 48 ore. I metadati sui file caricati vengono archiviati in Amazon DynamoDB con un TTL di 24 ore per la cronologia delle conversazioni.
Revisione e implementazione
Dopo questo passaggio, rivedi le impostazioni selezionate e scegli Deploy Use Case. Il nuovo use case viene quindi implementato e diventa visibile nella visualizzazione del dashboard di Deployment per gestirlo ulteriormente.
Fase 3b: Implementazione di un caso d'uso di Bedrock Agent
Lo use case Bedrock Agent fornisce un meccanismo potente e sicuro per richiamare Amazon Bedrock Agents nei tuoi casi d'uso. Questa funzionalità consente agli sviluppatori di integrare senza problemi le funzionalità degli agenti autonomi basati sull'intelligenza artificiale in grado di orchestrare ed eseguire attività in più fasi su vari modelli di base, fonti di dati, applicazioni software e conversazioni con gli utenti, mantenendo al contempo solide misure di sicurezza.
Prerequisiti
Prima di creare un agente Amazon Bedrock, assicurati di disporre di quanto segue:
-
L'account AWS in cui è distribuito Generative AI Application Builder su AWS, con accesso alla console Amazon Bedrock.
-
Autorizzazioni IAM appropriate per creare e gestire Amazon Bedrock Agents.
Creazione di un agente Amazon Bedrock
Per istruzioni dettagliate sulla creazione di un agente, consulta la sezione Crea e configura l'agente manualmente nella Amazon Bedrock User Guide. Puoi configurare opzioni come:
-
Istruzioni (prompt) per il tuo agente
-
Knowledge base, utilizzata per cercare informazioni aggiuntive in base all'input dell'utente
-
Memoria dell'agente per consentire agli agenti di ricordare le informazioni in più sessioni (per un massimo di 30 giorni)
Dopo aver creato con successo un agente Amazon Bedrock, puoi procedere al flusso guidato dei casi d'uso di Generative AI Application Builder su AWS Bedrock Agent. Per farlo, scegli Deploy a new use case nella dashboard di Deployment e seleziona Create Bedrock Agent Use Case. Segui la procedura guidata e utilizza i seguenti passaggi per configurare lo use case.
Seleziona il caso d'uso
Questo passaggio è lo stesso del caso d'uso Text descritto in precedenza.
Seleziona la configurazione di rete
Questo passaggio è lo stesso del caso d'uso Text descritto in precedenza
Seleziona agente
In questa fase, devi fornire l'ID agente e l'ID alias dell'agente Amazon Bedrock che hai creato.
Fase 3c: Implementazione di un caso d'uso del server MCP
Lo use case del server MCP (Model Context Protocol) consente di distribuire e gestire server MCP che possono essere integrati con modelli e agenti AI. I server MCP forniscono un modo standardizzato per esporre strumenti, risorse e funzionalità alle applicazioni AI. È possibile creare server MCP a partire da funzioni APIs Lambda esistenti oppure ospitare server MCP personalizzati utilizzando immagini di container.
Prerequisiti
Prima di implementare un caso d'uso del server MCP, assicuratevi di disporre di quanto segue:
-
L'account AWS in cui viene distribuito Generative AI Application Builder su AWS.
-
Autorizzazioni IAM appropriate per creare e gestire risorse Amazon Bedrock AgentCore .
-
A seconda del metodo di creazione scelto:
-
Per il metodo Gateway (Lambda/API/MCPServer): funzioni Lambda, endpoint API con i file di schema corrispondenti (formato JSON per Lambda, OpenAPI/Smithy for APIs) o endpoint URL del server MCP
-
Per il metodo Runtime (ECR): un'immagine del contenitore Docker inviata ad Amazon ECR contenente l'implementazione del server MCP
-
Metodi di creazione del server MCP
La soluzione supporta due metodi per la creazione di server MCP:
Crea da Lambda, API o MCP Server (metodo Gateway)
Questo metodo crea un gateway MCP che include funzioni Lambda, REST o server MCP esterni esistenti APIs, rendendoli accessibili come strumenti MCP. Il gateway gestisce la traduzione del protocollo tra MCP e i servizi esistenti.
-
Obiettivi Lambda: integra le funzioni Lambda esistenti fornendo la funzione ARN e un file di schema JSON che descrive il formato della funzione input/output
-
Obiettivi OpenAPI: integra REST utilizzando le specifiche APIs OpenAPI (formato JSON o YAML) con supporto per l'autenticazione 2.0 o API Key OAuth
-
Obiettivi Smithy: integrazione APIs definita utilizzando i file del modello Smithy (formato.smithy o.json)
-
Obiettivi del server MCP: Connettiti direttamente a server MCP esterni tramite endpoint URL, consentendo l'integrazione dei server MCP esistenti senza implementare una nuova infrastruttura
È possibile configurare più destinazioni (fino a 10) all'interno di un singolo gateway MCP, ognuna delle quali rappresenta uno strumento o una funzionalità diversi.
Hosting da ECR Image (metodo Runtime)
Questo metodo implementa un server MCP containerizzato da un'immagine Amazon ECR. Utilizza questo approccio quando disponi di un'implementazione server MCP personalizzata che deve essere eseguita come servizio autonomo.
-
Fornite l'URI dell'immagine ECR (deve includere un tag, ad esempio, o)
:latest:v1.0.0 -
Facoltativamente, configura le variabili di ambiente per passare la configurazione al tuo contenitore
-
Il contenitore deve implementare il protocollo MCP ed esporre gli endpoint richiesti
Implementazione di un server MCP
Per distribuire un caso d'uso del server MCP, scegli Implementa un nuovo caso d'uso nella dashboard di distribuzione e seleziona Crea caso d'uso del server MCP. Segui la procedura guidata e utilizza i seguenti passaggi per configurare lo use case.
Seleziona il caso d'uso
Questo passaggio è lo stesso del caso d'uso Text descritto in precedenza.
Seleziona la configurazione di rete
Attualmente è abilitato solo l'accesso pubblico e il VPC non è supportato per la configurazione di rete.
Crea un server MCP
In questo passaggio, configuri la distribuzione del server MCP:
Metodo di creazione del server MCP
Scegliete tra i due metodi di creazione:
-
Crea da Lambda, API o MCP Server: crea un gateway MCP da funzioni Lambda, specifiche API o endpoint server MCP esterni esistenti
-
Hosting da un'immagine ECR: implementa un server MCP personalizzato da un'immagine del contenitore
Nota
Il metodo di creazione non può essere modificato dopo la distribuzione. Se è necessario cambiare metodo, è necessario implementare un nuovo use case del server MCP.
Configurazione del gateway (per il metodo Lambda/API/MCP Server)
Se hai selezionato il metodo Gateway, configura una o più destinazioni:
-
Nome della destinazione (obbligatorio): un nome descrittivo per identificare questa configurazione di destinazione
-
Descrizione dell'obiettivo (opzionale): una breve descrizione di ciò che fa questo obiettivo
-
Tipo di destinazione: seleziona il tipo di oggetto da configurare:
-
Lambda: per le funzioni AWS Lambda
-
OpenAPI: per REST con specifiche APIs OpenAPI
-
Smithy: Per APIs le definizioni dei modelli Smithy
-
Server MCP: per la connessione diretta a server MCP esterni tramite endpoint URL
-
-
File di schema (obbligatorio): carica il file di schema che descrive il tuo obiettivo:
-
Per Lambda: file di schema JSON che descrive il formato. input/output Per i dettagli sulla creazione di schemi di strumenti Lambda, consulta lo schema degli strumenti Lambda nella Amazon Bedrock Developer Guide. AgentCore
-
Per OpenAPI: file delle specifiche OpenAPI (JSON o YAML). Per informazioni dettagliate sui requisiti dello schema OpenAPI, consulta lo schema OpenAPI nella Amazon Bedrock Developer Guide. AgentCore
-
Per Smithy: file modello Smithy (.smithy or .json). Per informazioni dettagliate sulla creazione degli obiettivi Smithy, consulta Building Smithy nella Amazon Bedrock Developer Guide. AgentCore
-
-
ARN della funzione Lambda (richiesto per i target Lambda): l'ARN della funzione Lambda da integrare
-
URL del server MCP (obbligatorio per le destinazioni del server MCP): l'endpoint URL del server MCP esterno a cui connettersi. L'URL deve essere codificato correttamente e il server MCP deve supportare le funzionalità degli strumenti con le versioni del protocollo MCP 2025-06-18. Per ulteriori informazioni, consulta gli obiettivi dei server MCP nella Amazon Bedrock AgentCore Developer Guide.
-
Autenticazione in uscita (richiesta per i target OpenAPI): configura l'autenticazione per le chiamate API REST:
-
Tipo di autenticazione: scegli OAuth 2.0 o chiave API
-
ARN del provider di autenticazione in uscita: l'ARN del provider di credenziali nel vault di token Amazon Bedrock AgentCore
-
Configurazioni aggiuntive: a seconda del tipo di autenticazione:
-
Per OAuth 2.0: configura ambiti e parametri personalizzati
-
Per la chiave API: specifica la posizione (parametro di intestazione o query), il nome del parametro e il prefisso opzionale
-
-
Puoi aggiungere più destinazioni (fino a 10) scegliendo Aggiungi un'altra destinazione. Ogni destinazione rappresenta uno strumento o una funzionalità separata esposta dal server MCP.
Configurazione ECR (per il metodo ECR Image)
Se hai selezionato il metodo Runtime, fornisci:
-
URI dell'immagine ECR (richiesto): l'URI completo dell'immagine Docker in Amazon ECR
-
Formato:
account-id.dkr.ecr.region.amazonaws.com/repository-name:tag -
L'immagine deve trovarsi nella stessa regione AWS della distribuzione
-
È richiesto un tag (ad esempio
:latest,:v1.0.0)
-
-
Variabili di ambiente (opzionali): configura le coppie chiave-valore da passare al contenitore in fase di esecuzione
-
Utilizzale per fornire configurazione, credenziali o flag personalizzati
-
Puoi aggiungere fino a 10 variabili di ambiente
-
Revisione e implementazione
Dopo aver configurato il server MCP, rivedi le impostazioni selezionate e scegli Deploy Use Case. Il nuovo use case MCP Server viene quindi distribuito e diventa visibile nella visualizzazione del dashboard di Deployment per un'ulteriore gestione.
Nota
Le implementazioni di MCP Server creano risorse in Amazon Bedrock AgentCore, inclusi gateway, runtime e identità dei carichi di lavoro. Queste risorse vengono gestite automaticamente dalla soluzione e verranno ripulite quando elimini lo use case.
Fase 3d: Implementazione di un caso d'uso di Agent Builder
Agent Builder ti consente di creare, configurare e distribuire agenti AI pronti per la produzione su Amazon Bedrock. AgentCore Questa funzionalità offre il pieno controllo sul comportamento degli agenti tramite istruzioni di sistema, selezione del modello, integrazione del server MCP e gestione della memoria.
Il processo di distribuzione è principalmente lo stesso di un caso d'uso Text, con alcune differenze notevoli.
Seleziona il caso d'uso
Questo passaggio è lo stesso del caso d'uso Text descritto in precedenza.
Dettagli dei casi d’uso
Questo passaggio è lo stesso del caso d'uso Text descritto in precedenza.
Configurare l'agente
In questo passaggio, configuri le impostazioni principali dell'agente, tra cui il prompt di sistema, servers/Strands gli strumenti MCP disponibili e la memoria.
Prompt di sistema
Il prompt di sistema definisce il comportamento, la personalità e le capacità dell'agente. Puoi:
-
Modifica il modello di prompt di sistema predefinito
-
Utilizzate il pulsante Ripristina i valori predefiniti per ripristinare il modello originale
-
Includi istruzioni per l'utilizzo dello strumento e la formattazione delle risposte
Integrazione con server MCP (opzionale)
Configura i server Model Context Protocol per fornire al tuo agente l'accesso a strumenti e dati aziendali:
-
Seleziona uno dei server MCP disponibili nel menu a discesa
-
Consulta gli strumenti pronti all'uso disponibili che saranno accessibili all'agente
Nota
I server MCP devono essere configurati e accessibili prima della distribuzione. Fate riferimento alla documentazione MCP per le istruzioni di configurazione del server.
Configurazione della memoria
Configura il modo in cui l'agente mantiene il contesto e le conoscenze:
-
Memoria a breve termine: abilitata per impostazione predefinita per tutti gli agenti. Mantiene il contesto della conversazione all'interno delle sessioni.
-
Memoria a lungo termine: attiva questa opzione per abilitare l'estrazione e l'archiviazione delle informazioni tra le sessioni. Utilizza la AgentCore memoria con una strategia di memoria semantica.
Revisione e implementazione
Dopo questo passaggio, rivedi le impostazioni selezionate e scegli Deploy Use Case. L'implementazione di Agent Builder viene in genere completata in 10-15 minuti. Il nuovo caso d'uso diventa quindi visibile nella visualizzazione del dashboard di Deployment per essere ulteriormente gestito.
Fase 3e: Implementazione di un caso d'uso di Workflow
Workflow Builder consente di creare agenti supervisori che orchestrano più agenti Agent Builder utilizzando il modello di delega Agents as Tools. Questa funzionalità consente di creare flussi di lavoro multiagente complessi riutilizzando le distribuzioni esistenti di Agent Builder.
Il processo di distribuzione segue uno schema simile a quello di Agent Builder, con passaggi aggiuntivi per l'individuazione e la selezione degli agenti.
Seleziona il caso d'uso
Questo passaggio è lo stesso del caso d'uso Text descritto in precedenza.
Dettagli dei casi d’uso
Questo passaggio è lo stesso del caso d'uso Text descritto in precedenza.
Configura l'agente supervisore
In questo passaggio, si configura l'agente supervisore che coordinerà gli agenti specializzati di Agent Builder.
Prompt di sistema
Il prompt di sistema definisce il modo in cui i delegati dell'agente supervisore lavorano agli agenti specializzati. Puoi:
-
Modifica il modello di prompt di sistema predefinito
-
Include istruzioni per la selezione e la delega degli agenti
-
Definisci come aggregare i risultati di più agenti
-
Utilizzate il pulsante Ripristina i valori predefiniti per ripristinare il modello originale
Nota
Il prompt di sistema dovrebbe descrivere chiaramente quando e come utilizzare ciascun agente specializzato. Le descrizioni degli agenti sono fondamentali per una corretta delega.
Selezione del modello
Seleziona il modello di base per l'agente supervisore. L'agente supervisore utilizza questo modello per:
-
Comprendere le richieste degli utenti
-
Seleziona gli agenti specializzati appropriati
-
Coordinare l'esecuzione degli agenti
-
Aggrega e formatta le risposte
Seleziona agenti specializzati
In questo passaggio, si selezionano gli agenti di Agent Builder a cui il supervisore può delegare il lavoro.
Aggiungere agenti
-
Fate clic su Aggiungi agente per aprire la finestra di dialogo di selezione dell'agente
-
Seleziona uno o più agenti Agent Builder dall'elenco
-
Consulta le descrizioni degli agenti che verranno fornite al supervisore
-
Conferma la selezione
Nota
-
I flussi di lavoro richiedono almeno 1 caso d'uso di Agent Builder come agente specializzato
-
Tutti gli agenti specializzati devono essere implementati correttamente prima di creare il flusso di lavoro
Revisione e implementazione
Rivedi la configurazione del flusso di lavoro, tra cui:
-
Prompt e modello del sistema dell'agente supervisore
-
Elenco degli agenti specializzati
-
Impostazioni della memoria
Scegli Deploy Use Case. L'implementazione di Workflow viene in genere completata in 15-20 minuti. Il nuovo flusso di lavoro diventa visibile nella visualizzazione del dashboard di Deployment per gestirlo ulteriormente.
