Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Guida all'integrazione
L'intera soluzione è progettata per essere facilmente estensibile. Il livello di orchestrazione di questa soluzione è costruito utilizzando. LangChain
Espansione supportata LLMs
Per aggiungere un altro fornitore di modelli, ad esempio un provider LLM personalizzato, è necessario aggiornare i seguenti tre componenti della soluzione:
-
Crea un nuovo stack
TextUseCaseCDK, che distribuisce l'applicazione di chat configurata con il tuo provider LLM personalizzato:-
Clona il GitHub repository
di questa soluzione e configura il tuo ambiente di compilazione seguendo le istruzioni fornite nel file README.md. -
Copia (o creane uno nuovo), incollalo nella stessa directory e rinominalo in.
source/infrastructure/lib/bedrock-chat-stack.tscustom-chat-stack.ts -
Rinomina la classe nel file con una classe adatta, ad esempio.
CustomLLMChat -
Puoi scegliere di aggiungere un segreto di Secrets Manager a questo stack, che memorizza le tue credenziali per il tuo LLM personalizzato. È possibile recuperare queste credenziali durante l'invocazione del modello nel livello di chat Lambda discusso nel paragrafo successivo.
-
-
Crea e collega un layer Lambda contenente la libreria Python del provider di modelli da aggiungere. Per un'applicazione di chat per casi d'uso di Amazon Bedrock, la libreria
langchain-awsPython contiene i connettori personalizzati nella parte superiore LangChain del pacchetto per connettersi ai provider di modelli AWS (Amazon Bedrock SageMaker e AI), alle knowledge base (Amazon Kendra e Amazon Bedrock Knowledge Bases) e ai tipi di memoria (come DynamoDB). Analogamente, altri fornitori di modelli dispongono di connettori propri. Questo livello consente di collegare la libreria Python di questo fornitore di modelli in modo da poter utilizzare questi connettori nel livello di chat Lambda, che richiama l'LLM (passaggio 3). In questa soluzione, viene utilizzato un bundler di asset personalizzato per creare livelli Lambda, collegati utilizzando aspetti CDK. Per creare un nuovo livello per la libreria Custom Model Provider:-
Passate alla
LambdaAspectsclasse nelsource/infrastructure/lib/utils/lambda-aspects.tsfile. -
Segui le istruzioni su come estendere la funzionalità della classe di aspetti Lambda fornita nel file (ad esempio aggiungere il
getOrCreateLangchainLayermetodo). Per utilizzare questo nuovo metodo (ad esempio,getOrCreateCustomLLMLayer), aggiorna anche l'LLM_LIBRARY_LAYER_TYPESenum nelsource/infrastructure/lib/utils/constants.tsfile.
-
-
Estendi la funzione
chatLambda per implementare un builder, un client e un gestore per il nuovo provider.source/lambda/chatContiene le LangChain connessioni per diverse classi LLMs insieme alle classi di supporto per crearle. LLMs Queste classi di supporto seguono i modelli di progettazione Builder e Object Oriented per creare l'LLM.Ogni gestore (ad esempio
bedrock_handler.py) crea prima un client, controlla l'ambiente per le variabili di ambiente richieste e quindi chiama unget_modelmetodo per ottenere la LangChain classe LLM. Il metodo generate viene quindi chiamato per richiamare l'LLM e ottenere la sua risposta. LangChain attualmente supporta la funzionalità di streaming per Amazon Bedrock, ma non l' SageMaker intelligenza artificiale. In base alla funzionalità di streaming o non streaming, viene chiamato il WebSocket gestore (WebsocketStreamingCallbackHandleroWebsocketHandler) appropriato per inviare la risposta alla WebSocket connessione utilizzando il metodo.post_to_connectionLa
clients/buildercartella contiene le classi che aiutano a creare un LLM Builder utilizzando il pattern Builder. Innanzitutto, ause_case_configviene recuperato da un archivio di configurazioni DynamoDB, che memorizza i dettagli sul tipo di knowledge base, memoria di conversazione e modello da costruire. Contiene anche dettagli rilevanti del modello, come i parametri e i prompt del modello. Il Builder aiuta quindi a seguire i passaggi per la creazione di una knowledge base, la creazione di una memoria di conversazione per mantenere il contesto di conversazione per LLM, l'impostazione dei LangChain callback appropriati per i casi di streaming e non streaming e la creazione di un modello LLM basato sulle configurazioni del modello fornite. La configurazione di DynamoDB viene archiviata al momento della creazione del caso d'uso quando si distribuisce un caso d'uso dalla dashboard di distribuzione (o quando viene fornito dagli utenti nelle distribuzioni standalone dello stack di use case senza il dashboard di distribuzione).La
clients/factoriessottocartella consente di impostare la memoria di conversazione e la classe di knowledge base appropriate, in base alla configurazione LLM. Ciò consente una facile estensione a qualsiasi altra knowledge base o tipo di memoria che si desidera supportare dall'implementazione.La
sharedsottocartella contiene implementazioni specifiche della knowledge base e della memoria di conversazione, che vengono istanziate all'interno delle factory dal builder. Contiene anche i retriever Amazon Kendra e Amazon Bedrock Knowledge Base LangChain chiamati all'interno per recuperare i documenti per i casi d'uso RAG, insieme ai callback, utilizzati dal modello LLM. LangChainLe LangChain implementazioni utilizzano LangChain Expression Language (LCEL) per comporre insieme catene di conversazioni.
RunnableWithMessageHistoryla classe viene utilizzata per mantenere la cronologia delle conversazioni con catene LCEL personalizzate, abilitando funzionalità come la restituzione di documenti sorgente e l'utilizzo della domanda riformulata (o disambigua) inviata alla knowledge base per essere inviata anche al LLM.Per creare la propria implementazione di un provider personalizzato, è possibile:
-
Copia il
bedrock_handler.pyfile e crea il tuo gestore personalizzato (ad esempio,custom_handler.py), che crea il tuo client personalizzato (ad esempio,CustomProviderClient) (specificato nel passaggio seguente). -
Copia
bedrock_client.pynella cartella client. Rinominalo incustom_provider_client.py(o il nome del fornitore del modello specifico, ad esempioCustomProvider). Assegna un nome appropriato alla classe al suo interno, ad esempio la classeCustomProviderClientche eredita.LLMChatClientÈ possibile utilizzare i metodi forniti da
LLMChatCliento scrivere implementazioni personalizzate per sovrascriverli.Il
get_modelmetodo crea unCustomProviderBuilder(vedi il passaggio seguente) e chiama ilconstruct_chat_modelmetodo che costruisce il modello di chat utilizzando i passaggi del generatore. Questo metodo funge da Director nel pattern del builder. -
Copialo
clients/builders/bedrock_builder.pye rinominalo incustom_provider_builder.pye la classe al suo interno inCustomProviderBuilderthat inherits LLMBuilder ().llm_builder.pyÈ possibile utilizzare i metodi forniti da LLMBuilder o scrivere implementazioni personalizzate per sovrascriverli. I passaggi del builder vengono richiamati in sequenza all'interno delconstruct_chat_modelmetodo del client, ad esempioset_model_defaults,set_knowledge_basee.set_conversation_memoryIl
set_llm_modelmetodo creerebbe il modello LLM effettivo utilizzando tutti i valori impostati utilizzando i metodi chiamati in precedenza. In particolare, è possibile creare un LLM RAG (CustomProviderRetrievalLLM) o non RAG (CustomProviderLLM), in base a quanto recuperato dalla configurazione LLM in DynamoDB.rag_enabled variableQuesta configurazione viene recuperata nel metodo della classe.
retrieve_use_case_configLLMChatClient -
Implementate
CustomProviderRetrievalLLMl'implementazioneCustomProviderLLMor nellallm_modelssottocartella a seconda che abbiate bisogno di un caso d'uso RAG o non RAG. La maggior parte delle funzionalità per implementare questi modelli sono fornite rispettivamente nelle rispettiveRetrievalLLMclassi, per casi d'uso diversi da RAGBaseLangChainModele RAG.È possibile copiare il
llm_models/bedrock.pyfile e apportare le modifiche necessarie per chiamare il LangChain modello che fa riferimento al provider personalizzato. Ad esempio, Amazon Bedrock utilizza unaChatBedrockclasse per creare un modello di chat utilizzando LangChain.Il metodo generate genera la risposta LLM utilizzando le catene LangChain LCEL.
È inoltre possibile utilizzare il
get_clean_model_paramsmetodo per disinfettare i parametri del modello in base ai requisiti LangChain del modello.
-
Espansione degli strumenti Strands supportati
La soluzione consente di creare e distribuire server MCP, agenti AI e flussi di lavoro multiagente. Nell'ambito dell'esperienza Agent Builder, puoi collegare server MCP per offrire ai tuoi agenti funzionalità aggiuntive. Oltre ai server MCP, è possibile sfruttare gli strumenti integrati forniti da Strands
Pronta all'uso, la soluzione viene preconfigurata con i seguenti strumenti Strands:
-
Ora corrente (abilitata per impostazione predefinita)
-
Calcolatrice (abilitata per impostazione predefinita)
-
Ambiente
Selezione del server e degli strumenti MCP nella procedura guidata di Agent Builder che mostra gli strumenti Strands integrati

Per ampliare i tuoi agenti con strumenti Strands aggiuntivi, segui la procedura in quattro fasi descritta in questa sezione.
Fase 1: Trova lo strumento Strands
Sfoglia gli strumenti Strands disponibili
Fase 2: Aggiornare il parametro SSM
Per rendere disponibile uno strumento nell'interfaccia utente di distribuzione di Agent Builder, aggiorna il parametro AWS Systems Manager Parameter Store che definisce quali strumenti Strands sono supportati.
-
Accedi all'AWS Systems Manager Parameter Store nel tuo account AWS.
-
Individua il parametro:
/gaab/<stack-name>/strands-tools -
Aggiungete la configurazione dello strumento alla fine dell'elenco esistente utilizzando la seguente struttura JSON:
{ "name": "Bedrock KB Retrieve", "description": "Retrieve information from Bedrock Knowledge Base", "value": "retrieve", "category": "AI", "isDefault": false }Campo Description name
Nome visualizzato nell'interfaccia utente di Agent Builder
description
Breve descrizione della funzionalità dello strumento
value
Il nome esatto dello strumento come definito nel pacchetto Strands tools
category
Categoria organizzativa per il raggruppamento degli strumenti nell'interfaccia utente
è l'impostazione predefinita
Se lo strumento deve essere abilitato per impostazione predefinita per i nuovi agenti
Fase 3: Configurare le variabili di ambiente
Molti strumenti Strands richiedono variabili di ambiente per la configurazione. È possibile impostare queste variabili in due modi:
Opzione 1: configurazione diretta su AgentCore Runtime
Aggiorna l'agente distribuito direttamente su Amazon Bedrock AgentCore Runtime con le variabili di ambiente richieste.
Opzione 2: parametri del modello nella procedura guidata di distribuzione
Aggiungere variabili di ambiente durante la fase di selezione del modello nella procedura guidata di Agent Builder utilizzando la sezione Parametri del modello. Le variabili di ambiente che seguono la convenzione di denominazione ENV_<ALL_CAPS_TOOL_NAME>_<env_variable_name> verranno caricate automaticamente in fase di esecuzione nell'ambiente di esecuzione dell'agente come. <env_variable_name>
Esempio:
-
ENV_RETRIEVE_KNOWLEDGE_BASE_IDdiventaKNOWLEDGE_BASE_ID -
ENV_RETRIEVE_MIN_SCOREdiventaMIN_SCORE
Sezione dei parametri avanzati del modello che mostra la configurazione ENV_RETRIEVE_KNOWLEDGE_BASE_ID

Fate riferimento alla documentazione o al codice sorgente dello strumento specifico per identificare le variabili di ambiente richieste. Per lo strumento di recupero, puoi trovare le opzioni di configurazione nel codice sorgente.
Fase 4: Aggiungere le autorizzazioni IAM
Aggiungi manualmente le autorizzazioni IAM necessarie al tuo ruolo AgentCore di esecuzione Runtime per consentire all'agente di utilizzare lo strumento.
Ad esempio, per utilizzare lo strumento di recupero con Amazon Bedrock Knowledge Bases:
-
Accedi alla console IAM nel tuo account AWS.
-
Individua il ruolo AgentCore di esecuzione in Runtime per il tuo agente.
-
Aggiungi la seguente autorizzazione:
{ "Effect": "Allow", "Action": "bedrock:Retrieve", "Resource": "arn:aws:bedrock:region:account-id:knowledge-base/knowledge-base-id" }
Console IAM che mostra la StrandsRetrieveTool KBAccess policy associata al ruolo AgentCore di esecuzione Runtime

Le autorizzazioni specifiche richieste varieranno in base allo strumento. Consulta la documentazione dello strumento e la documentazione del servizio AWS per determinare le autorizzazioni IAM appropriate.
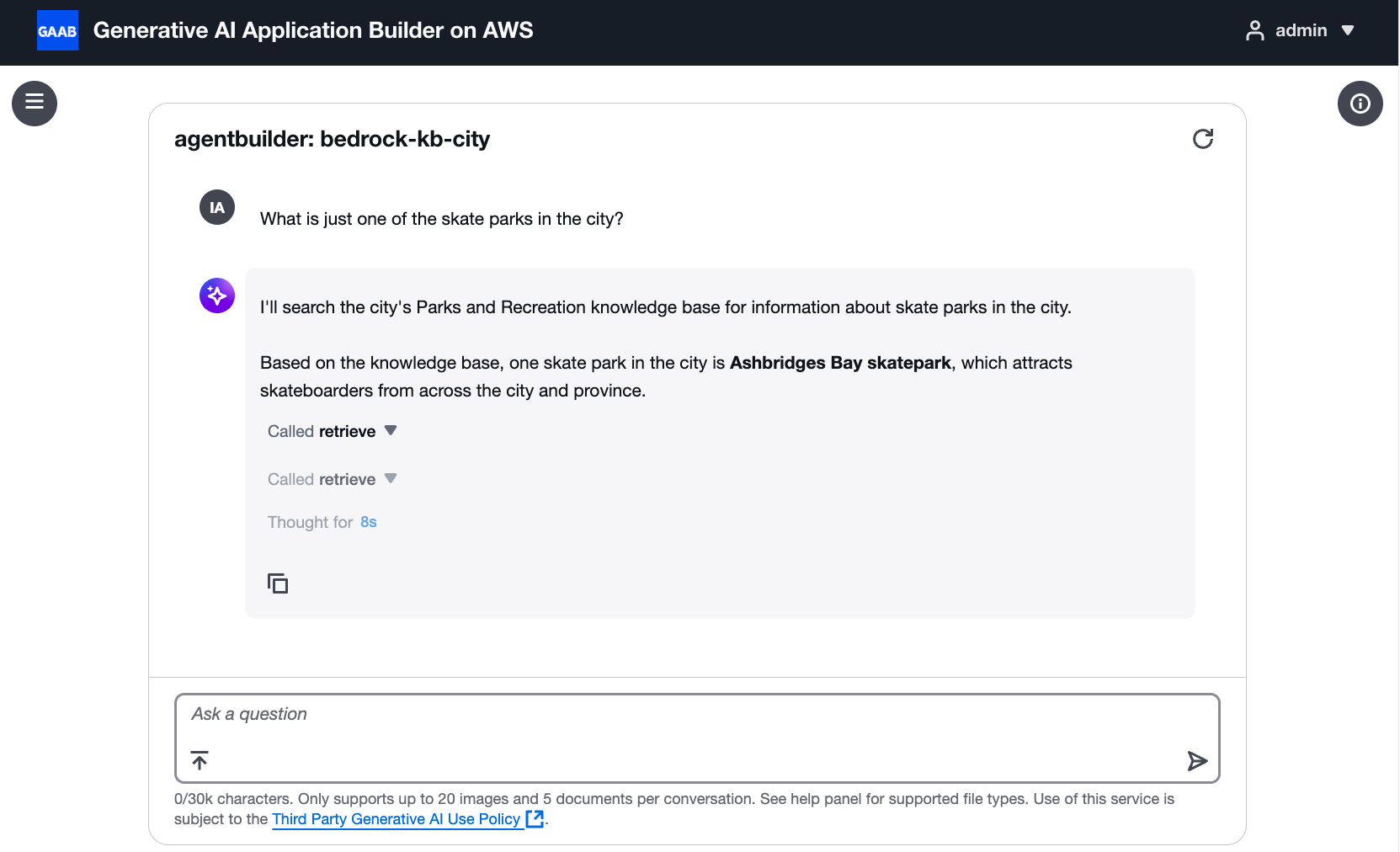
Fase 5: testare l'agente
Dopo aver completato i passaggi di configurazione, testate l'agente per verificare che lo strumento funzioni correttamente. Dovresti vedere le chiamate agli strumenti nei registri di esecuzione e nelle risposte dell'agente.
Agente che utilizza con successo lo strumento di recupero per rispondere a una domanda sugli skate park
Nota
Per un elenco completo degli strumenti Strands disponibili e delle relative funzionalità, consultate la documentazione degli Strands
Ampliamento delle basi di conoscenza e dei tipi di memoria di conversazione supportati
Per aggiungere le tue implementazioni della memoria di conversazione o della knowledge base, aggiungi le implementazioni richieste shared nella cartella, quindi modifica le impostazioni di fabbrica e le enumerazioni appropriate per creare un'istanza di queste classi.
Quando fornite la configurazione LLM, che è memorizzata all'interno dell'archivio dei parametri, verranno create la memoria di conversazione e la knowledge base appropriate per il vostro LLM. Ad esempio, quando ConversationMemoryType viene specificato come DynamoDB, viene creata un'istanza DynamoDBChatMessageHistory di (disponibile shared_components/memory/ddb_enhanced_message_history.py all'interno). Quando KnowledgeBaseType viene specificato come Amazon Kendra, viene creata un'istanza KendraKnowledgeBase di (disponibile shared_components/knowledge/kendra_knowledge_base.py all'interno).
Creazione e implementazione delle modifiche al codice
Costruisci il programma con il npm run build comando. Una volta risolti gli errori, esegui cdk synth per generare i file modello e tutte le risorse Lambda.
-
Puoi utilizzare lo
–0—/stage-assets.shscript per inserire manualmente le risorse generate nello staging bucket del tuo account. -
Utilizzate il seguente comando per distribuire o aggiornare la piattaforma:
cdk deploy DeploymentPlatformStack --parameters AdminUserEmail='admin-email@amazon.com'Insieme al AdminUserEmailparametro devono essere forniti anche eventuali CloudFormation parametri AWS aggiuntivi.
