Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Equità, spiegabilità dei modelli e rilevamento dei pregiudizi con Clarify SageMaker
Puoi usare Amazon SageMaker Clarify per comprendere l'equità e la spiegabilità dei modelli e per spiegare e rilevare errori nei tuoi modelli. Puoi configurare un processo di elaborazione SageMaker Clarify per calcolare metriche di distorsioni e attribuzioni di funzionalità e generare report per la spiegabilità del modello. SageMaker I processi di elaborazione di Clarify vengono implementati utilizzando un'immagine del contenitore Clarify specializzata. SageMaker La pagina seguente descrive come funziona SageMaker Clarify e come iniziare con un'analisi.
Cosa sono l’equità e la spiegabilità dei modelli per le previsioni di machine learning?
I modelli di machine learning (ML) contribuiscono a prendere decisioni in diversi settori, come quello dei servizi finanziari, dell’assistenza sanitaria, dell’istruzione e delle risorse umane. Policy maker, organismi di regolamentazione e avvocati hanno cercato di sensibilizzare l’opinione pubblica sulle sfide etiche e in materia di policy poste dal machine learning e dai sistemi basati sui dati. Amazon SageMaker Clarify può aiutarti a capire perché il tuo modello di machine learning ha creato una previsione specifica e se questa distorsione influisce su questa previsione durante l'addestramento o l'inferenza. SageMaker Clarify fornisce anche strumenti che possono aiutarti a creare modelli di machine learning meno distorti e più comprensibili. SageMaker Clarify può anche generare report sulla governance dei modelli da fornire ai team di gestione dei rischi e della conformità e alle autorità di regolamentazione esterne. Con SageMaker Clarify, puoi fare quanto segue:
-
Rilevare i bias e spiegare le previsioni tramite modello.
-
Identificare i tipi di bias nei dati di preaddestramento.
-
Identificare nei dati di post-addestramento i tipi di bias che possono emergere durante l’addestramento o quando il modello è in produzione.
SageMaker Clarify aiuta a spiegare in che modo i modelli effettuano previsioni utilizzando le attribuzioni di funzionalità. Monitora anche i modelli di inferenza in produzione per rilevare derive dei bias o dell’attribuzione delle funzionalità. Queste informazioni possono aiutarti nelle aree seguenti:
-
Normativa: policy maker e altri organismi di regolamentazione possono avere preoccupazioni riguardo agli impatti discriminatori delle decisioni basate sugli output provenienti da modelli di ML. Ad esempio, un modello di ML può codificare i bias e influenzare una decisione automatizzata.
-
Aziende: i domini regolamentati possono richiedere spiegazioni attendibili sulle modalità di generazione delle previsioni dei modelli di ML. La spiegabilità dei modelli può essere particolarmente importante per i settori che dipendono dall’affidabilità, dalla sicurezza e dalla conformità. Tra questi figurano servizi finanziari, risorse umane, assistenza sanitaria e trasporti automatizzati. Ad esempio, le applicazioni per i prestiti potrebbero dover spiegare a responsabili dei prestiti, analisti e clienti in che modo i modelli di ML hanno prodotto determinate previsioni.
-
Data science: i Data Scientist e gli ingegneri di ML possono eseguire il debug e migliorare i modelli di ML quando riescono a determinare se un modello sta effettuando inferenze basate su caratteristiche rumorose o irrilevanti. Possono anche comprendere i limiti dei propri modelli e i tipi di errore in cui potrebbero incorrere i modelli.
Per un post sul blog che mostra come progettare e creare un modello di machine learning completo per reclami automobilistici fraudolenti che integri SageMaker Clarify in una pipeline di SageMaker intelligenza artificiale, consulta Architect e crea l'intero ciclo di vita dell'apprendimento automatico con: AWS Una
Best practice per valutare l’equità e la spiegabilità nel ciclo di vita di ML
L’equità come processo: i concetti di bias ed equità dipendono fortemente dall’applicazione. La misurazione del bias e la scelta delle metriche sui bias possono essere guidate da considerazioni sociali, legali e di altro tipo non tecnico. Un’adozione efficace degli approcci di ML consapevoli dell’equità prevede la creazione del consenso e una solida collaborazione tra le principali parti interessate. Questi possono includere prodotti, policy, aspetti legali, tecnici, team, utenti finali e community. AI/ML
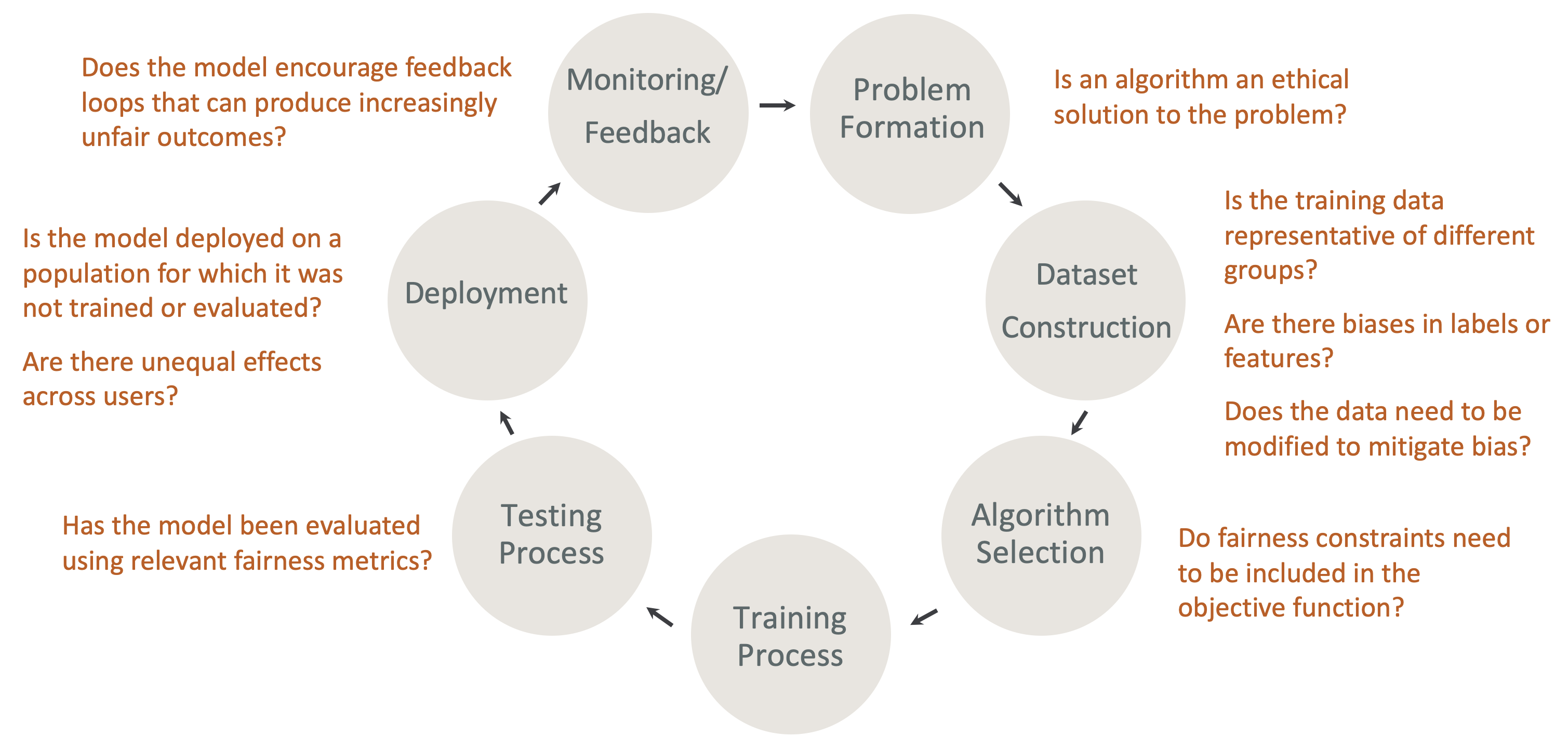
Equità e spiegabilità fin dalla progettazione nel ciclo di vita di ML: tieni in considerazione l’equità e la spiegabilità in ogni fase del ciclo di vita di ML. Queste fasi includono la formazione dei problemi, la costruzione del set di dati, la selezione degli algoritmi, il processo di addestramento dei modelli, il processo di test, l’implementazione, il monitoraggio e il feedback. È importante disporre degli strumenti giusti per eseguire questa analisi. Ti consigliamo di porre le seguenti domande durante il ciclo di vita di ML:
-
Il modello incoraggia cicli di feedback che possono produrre risultati sempre più di parte?
-
Un algoritmo è una soluzione etica al problema?
-
I dati di addestramento sono rappresentativi di diversi gruppi?
-
Ci sono bias nelle etichette o nelle funzionalità?
-
I dati devono essere modificati per mitigare i bias?
-
I vincoli di equità devono essere inclusi nella funzione obiettivo?
-
Il modello è stato valutato utilizzando metriche di equità pertinenti?
-
Gli effetti sono diversi tra i vari utenti?
-
Il modello è utilizzato su una popolazione per la quale non è stato addestrato o valutato?
Guida alle spiegazioni sull' SageMaker intelligenza artificiale e alla documentazione sui pregiudizi
I bias possono verificarsi ed essere misurati nei dati sia prima che dopo l’addestramento di un modello. SageMaker Clarify può fornire spiegazioni per le previsioni dei modelli dopo la formazione e per i modelli implementati in produzione. SageMaker Clarify può anche monitorare i modelli in produzione per rilevare eventuali variazioni nelle loro attribuzioni esplicative di base e calcolare le linee di base quando necessario. La documentazione per spiegare e rilevare i pregiudizi utilizzando Clarify è strutturata come segue: SageMaker
-
Per informazioni sulla configurazione di un processo di elaborazione per bias e spiegabilità, consulta Configurazione di un processo di elaborazione SageMaker Clarify.
-
Per informazioni sul rilevamento dei bias durante la pre-elaborazione dei dati, eseguita prima che questi vengano utilizzati per addestrare un modello, consulta Pre-training Distorsione dei dati.
-
Per informazioni sul rilevamento dei bias nei dati di post-addestramento e nel modello, consulta Post-training Bias dei dati e dei modelli.
-
Per informazioni sull’approccio di attribuzione delle funzionalità indipendente dal modello per spiegare le previsioni tramite modello dopo l’addestramento, consulta Spiegabilità del modello.
-
Per informazioni sul monitoraggio della deriva dell’attribuzione delle funzionalità rispetto alla baseline specificata durante l’addestramento dei modelli, consulta Deriva dell’attribuzione delle funzionalità per i modelli in produzione.
-
Per informazioni sul monitoraggio dei modelli in produzione per rilevare la deriva della baseline, consulta Deriva dei bias per i modelli in produzione.
-
Per informazioni su come ottenere spiegazioni in tempo reale da un SageMaker endpoint di intelligenza artificiale, consulta. Spiegabilità online con Clarify SageMaker
Come funzionano i lavori di elaborazione di SageMaker Clarify
Puoi usare SageMaker Clarify per analizzare i tuoi set di dati e modelli per verificarne la spiegabilità e gli errori. Un processo di elaborazione SageMaker Clarify utilizza il contenitore di elaborazione SageMaker Clarify per interagire con un bucket Amazon S3 contenente i set di dati di input. Puoi anche utilizzare SageMaker Clarify per analizzare un modello di cliente distribuito su un endpoint di inferenza AI. SageMaker
Il grafico seguente mostra come un processo di elaborazione SageMaker Clarify interagisce con i dati di input e, facoltativamente, con un modello del cliente. Questa interazione dipende dal tipo specifico di analisi eseguita. Il contenitore di elaborazione SageMaker Clarify ottiene il set di dati di input e la configurazione per l'analisi da un bucket S3. Per determinati tipi di analisi, inclusa l'analisi delle feature, il contenitore di elaborazione SageMaker Clarify deve inviare le richieste al contenitore del modello. Quindi recupera le previsioni del modello dalla risposta inviata dal container del modello. Successivamente, il contenitore di elaborazione SageMaker Clarify calcola e salva i risultati dell'analisi nel bucket S3.

È possibile eseguire un processo di elaborazione SageMaker Clarify in più fasi del ciclo di vita del flusso di lavoro di apprendimento automatico. SageMaker Clarify può aiutarvi a calcolare i seguenti tipi di analisi:
-
Pre-training metriche di distorsione. Le metriche sui bias preaddestramento possono aiutarti a comprendere i bias presenti nei dati in modo da correggerli e addestrare il modello su un set di dati più equo. Per informazioni sulle metriche sui bias di preaddestramento, consulta Pre-training Metriche di distorsione. Per eseguire un processo di analisi dei parametri di bias prima dell'addestramento, devi fornire il set di dati e un file di configurazione dell'analisi JSON a File di configurazione dell’analisi.
-
Post-training metriche di pregiudizio. Le metriche sui bias post-addestramento possono aiutarti a comprendere eventuali bias introdotti da un algoritmo, le scelte degli iperparametri o qualsiasi bias che non era precedentemente visibile nel flusso. Per ulteriori informazioni sulle metriche relative ai pregiudizi post-allenamento, consulta. Post-training Metriche di distorsione dei dati e dei modelli SageMaker Clarify utilizza le previsioni del modello oltre ai dati e alle etichette per identificare i pregiudizi. Per eseguire un processo di analisi dei parametri di bias post-addestramento, è necessario fornire il set di dati e un file di configurazione dell'analisi JSON. La configurazione deve includere il nome del modello o dell'endpoint.
-
I valori Shapely per la spiegabilità possono aiutarti a capire l’impatto della funzionalità sulle previsioni del tuo modello. Per ulteriori informazioni sui valori Shapley, consulta Caratterizzazione delle attribuzioni che utilizzano i valori Shapley. Questa funzionalità richiede un modello addestrato.
-
I grafici di dipendenza parziale (PDP) possono aiutarti a capire quanto cambierebbe la variabile di destinazione prevista se variassi il valore di una funzionalità. Per ulteriori informazioni sui grafici PDP, consulta Analisi dei grafici di dipendenza parziale (PDP). Questa funzionalità richiede un modello addestrato.
SageMaker Clarify necessita di modelli predittivi per calcolare le metriche di distorsione e l'attribuzione delle funzionalità dopo l'allenamento. È possibile fornire un endpoint oppure SageMaker Clarify creerà un endpoint temporaneo utilizzando il nome del modello, noto anche come endpoint ombra. Il contenitore SageMaker Clarify elimina l'endpoint shadow dopo il completamento dei calcoli. A un livello elevato, il contenitore SageMaker Clarify completa i seguenti passaggi:
-
Convalida input e parametri.
-
Crea l'endpoint shadow (se viene fornito un nome di modello).
-
Carica il set di dati di input in un frame di dati.
-
Ottiene le previsioni del modello dall'endpoint, se necessario.
-
Calcola i parametri di bias e le attribuzioni delle funzionalità.
-
Elimina l'endpoint shadow.
-
Genera i risultati dell'analisi.
Una volta completato il processo di elaborazione di SageMaker Clarify, i risultati dell'analisi verranno salvati nella posizione di output specificata nel parametro di output di elaborazione del lavoro. Questi risultati includono un file JSON con parametri di bias e attribuzioni di funzionalità globali, un report visivo e file aggiuntivi per le attribuzioni di funzionalità locali. È possibile scaricare i risultati dalla posizione di output e visualizzarli.
Per ulteriori informazioni sulle metriche dei pregiudizi, sulla spiegabilità e su come interpretarle, consulta Scopri come Amazon SageMaker Clarify aiuta a rilevare bias
Notebook di esempio
Le seguenti sezioni contengono taccuini che consentono di iniziare a utilizzare SageMaker Clarify, di utilizzarlo per attività speciali, incluse quelle all'interno di un lavoro distribuito, e per la visione artificiale.
Nozioni di base
I seguenti taccuini di esempio mostrano come utilizzare SageMaker Clarify per iniziare con le attività di spiegabilità e distorsione dei modelli. Queste attività includono la creazione di un processo di elaborazione, l’addestramento di un modello di machine learning (ML) e il monitoraggio delle previsioni tramite modello:
-
Spiegabilità e rilevamento delle distorsioni con Amazon SageMaker Clarify: usa SageMaker Clarify
per creare un processo di elaborazione per rilevare distorsioni e spiegare le previsioni dei modelli. -
Monitoraggio della deriva dei pregiudizi e delle variazioni nell'attribuzione delle funzionalità Amazon SageMaker Clarify: utilizza SageMaker Amazon
Model Monitor per monitorare la deriva dei pregiudizi e la variazione dell'attribuzione delle funzionalità nel tempo. -
Come leggere un set di dati in formato JSON Lines in un processo di elaborazione Clarify.
SageMaker -
Attenua i pregiudizi, addestra un altro modello imparziale e inseriscilo nel registro dei modelli: usa Synthetic Minority Over-sampling Technique (SMOTE)
e SageMaker Clarify per mitigare i pregiudizi, addestrare un altro modello e quindi inserire il nuovo modello nel registro dei modelli. Questo notebook di esempio mostra anche come inserire i nuovi artefatti del modello, inclusi dati, codice e metadati del modello, nel registro dei modelli. Questo notebook fa parte di una serie che mostra come integrare SageMaker Clarify in una pipeline di SageMaker intelligenza artificiale descritta in Architect e creare l'intero ciclo di vita dell'apprendimento automatico con un post sul blog. AWS
Casi speciali
I seguenti taccuini mostrano come utilizzare SageMaker Clarify per casi speciali, ad esempio all'interno del proprio contenitore e per attività di elaborazione del linguaggio naturale:
-
Equità e spiegabilità con SageMaker Clarify (Bring Your Own Container): create il vostro modello e contenitore
in grado di integrarsi con SageMaker Clarify per misurare le distorsioni e generare un rapporto di analisi della spiegabilità. Questo taccuino di esempio introduce anche i termini chiave e mostra come accedere al rapporto tramite Studio Classic. SageMaker -
Equità e spiegabilità con SageMaker Clarify Spark Distributed Processing: utilizzate l'elaborazione distribuita
per eseguire un job SageMaker Clarify che misuri la distorsione pre-addestramento di un set di dati e la distorsione post-formazione di un modello. Questo taccuino di esempio mostra anche come ottenere una spiegazione dell'importanza delle funzionalità di input sull'output del modello e accedere al rapporto di analisi della spiegabilità tramite Studio Classic. SageMaker -
Spiegabilità con SageMaker Clarify - Partial Dependence Plots (PDP): utilizzate SageMaker Clarify per generare PDP
e accedere a un rapporto sulla spiegabilità del modello. -
Spiegazione dell'analisi del sentimento testuale utilizzando la spiegabilità dell'elaborazione del linguaggio naturale (NLP) di Clarify: utilizzate SageMaker Clarify per l'analisi
del sentimento testuale. SageMaker -
Utilizza la spiegabilità della visione artificiale (CV) per la classificazione delle immagini
e il rilevamento degli oggetti .
È stato verificato che questi notebook funzionino in Amazon SageMaker Studio Classic. Se hai bisogno di istruzioni su come aprire un notebook in Studio Classic, consulta Crea o apri un notebook Amazon SageMaker Studio Classic. Se ti viene richiesto di scegliere un kernel, scegli Python 3 (Data Science).
