Amazon Redshift non supporterà più la creazione di nuove UDF Python a partire dalla Patch 198. Le UDF Python esistenti continueranno a funzionare fino al 30 giugno 2026. Per ulteriori informazioni, consulta il post del blog
Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Utilizzo della vista SVL_QUERY_REPORT
Per analizzare le informazioni di riepilogo della query in base alla sezione con SVL_QUERY_REPORT, segui la procedura descritta:
-
Esegui la seguente operazione per determinare l'ID della tua query:
select query, elapsed, substring from svl_qlog order by query desc limit 5;Esamina il testo troncato della query nel campo
substringper determinare quale valorequeryrappresenta la tua query. Se hai eseguito la query più di una volta, utilizza il valorequerya partire dalla riga con il valoreelapsedpiù basso. Questa è la riga per la versione compilata. Se stai eseguendo molte query, puoi alzare il valore utilizzato dalla clausola LIMIT, che viene usata per accertarsi che la query sia inclusa. -
Seleziona le righe da SVL_QUERY_REPORT per la tua query. Ordina i risultati per segmento, fase, tempo trascorso e righe:
select * from svl_query_report where query = MyQueryID order by segment, step, elapsed_time, rows; -
Per ogni fase, verifica che tutte le sezioni abbiano processato approssimativamente lo stesso numero di righe:
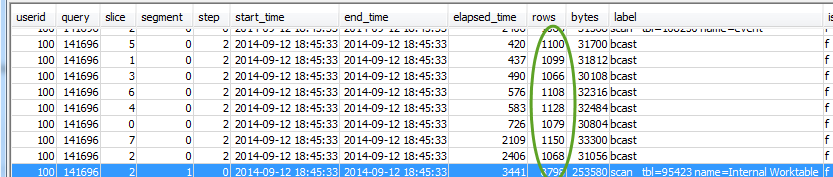
Verifica anche che tutte le sezioni abbiano impiegato approssimativamente lo stesso tempo:
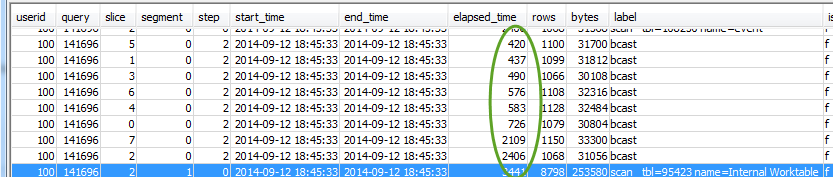
Grosse discrepanze in questi valori possono indicare che, la differenza della distribuzione dei dati, è dovuta allo stile di distribuzione non ottimale per questa query particolare. Per le soluzioni consigliate, consultare Distribuzione dei dati non ottimale.
