Amazon Redshift non supporterà più la creazione di nuove UDF Python a partire dalla Patch 198. Le UDF Python esistenti continueranno a funzionare fino al 30 giugno 2026. Per ulteriori informazioni, consulta il post del blog
Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Eseguire un proof of concept (POC) per Amazon Redshift
Amazon Redshift, un data warehouse su cloud ampiamente utilizzato, offre un servizio basato sul cloud completamente gestito che si integra con il data lake, i flussi in tempo reale, i flussi di lavoro di machine learning (ML), i flussi di lavoro transazionali di Amazon Simple Storage Service di un’organizzazione e molto altro. Nelle sezioni seguenti viene illustrato il processo di esecuzione di un proof of concept (POC) in Amazon Redshift. Le informazioni riportate qui consentono di fissare gli obiettivi per il POC e sfruttano gli strumenti in grado di automatizzare il provisioning e la configurazione dei servizi per il POC.
Nota
Per una copia di queste informazioni in formato PDF, scegli il link Esegui il tuo POC su Redshift nella pagina Risorse di Amazon Redshift
L’esecuzione di un POC di Amazon Redshift prevede un processo di test, verifica e adozione di funzionalità come funzioni di sicurezza eccellenti, dimensionamento elastico, integrazione e importazione semplificate, oltre a opzioni flessibili di architettura dei dati decentralizzata.

Per eseguire un POC, segui la procedura descritta.
Fase 1: definire l’ambito del POC

Quando esegui un POC, puoi scegliere di utilizzare i dati dell’organizzazione oppure i set di dati di benchmarking. Nel primo caso, esegui query personalizzate sui dati dell’organizzazione. Nel secondo caso, insieme al benchmark vengono fornite query di esempio. Se non sei ancora pronto a eseguire un POC con i dati dell’organizzazione, consulta Utilizzare i set di dati di esempio per ulteriori dettagli.
In generale consigliamo di utilizzare due settimane di dati per un POC Amazon Redshift.
Inizia eseguendo le operazioni seguenti:
Identifica i requisiti aziendali e funzionali, quindi procedi a ritroso. Alcuni esempi comuni sono: prestazioni più rapide, costi inferiori, test di nuovi carichi di lavoro o nuove funzionalità, confronto tra Amazon Redshift e un altro data warehouse.
Fissa degli obiettivi specifici che diventino i criteri di successo per il POC. Ad esempio, a partire dalle prestazioni più veloci, crea un elenco dei primi cinque processi che desideri accelerare e includi i tempi di esecuzione correnti insieme al tempo di esecuzione richiesto. Tra questi possono figurare i report, le query, i processi ETL, l’importazione dei dati o qualsiasi altro problema corrente.
Identifica l’ambito e gli artefatti specifici necessari per eseguire i test. Di quali set di dati devi eseguire la migrazione o l’importazione continua in Amazon Redshift? Quali query e processi servono per eseguire i test ed effettuare le valutazioni in base ai criteri di successo? Ci sono due modi per effettuare questa operazione:
Utilizzare i dati dell’organizzazione
Per testare i dati dell’organizzazione, crea l’elenco minimo valido degli artefatti di dati che è necessario per eseguire i test a fronte dei criteri di successo stabiliti. Ad esempio, se il data warehouse corrente ha 200 tabelle, ma i report che desideri testare ne richiedono solo 20, il POC può essere eseguito più velocemente utilizzando solo il sottoinsieme di tabelle più piccolo.
Utilizzo del set di dati di esempio
Se non disponi di set di dati personalizzati, puoi comunque iniziare a creare un POC su Amazon Redshift utilizzando i set di dati di benchmark standard del settore TPC-DS
come TPC-H or ed eseguire query di benchmarking di esempio per sfruttare la potenza di Amazon Redshift. Puoi accedere a questi set di dati dall’interno del data warehouse Amazon Redshift dopo che l’hai creato. Per istruzioni dettagliate su come accedere a questi set di dati e queste query di esempio, consulta Fase 2: avviare Amazon Redshift.
Fase 2: avviare Amazon Redshift

Amazon Redshift accelera il tempo di acquisizione delle informazioni con un data warehouse cloud rapido, semplice e sicuro su larga scala. Puoi iniziare rapidamente avviando il warehouse sulla console Redshift serverless
Configurare Amazon Redshift serverless
La prima volta che utilizzi Redshift serverless, la console ti guida nel processo da seguire per avviare il warehouse. Potresti anche avere diritto a un credito per l’uso di Redshift serverless nell’account. Per ulteriori informazioni sulla scelta di una prova gratuita, consultare Prova gratuita di Amazon Redshift
Se hai già avviato Redshift serverless nell’account, segui le fasi descritte in Creazione di un gruppo di lavoro con un namespace nella Guida alla gestione di Amazon Redshift. Una volta reso disponibile il warehouse, puoi scegliere di caricare i dati di esempio contenuti in Amazon Redshift. Per informazioni sull’utilizzo di Amazon Redshift Query Editor V2 per caricare i dati, consulta Caricamento dei dati di esempio nella Guida alla gestione di Amazon Redshift.
Se utilizzi i dati dell’organizzazione invece di caricare il set di dati di esempio, consulta Fase 3: caricare i dati.
Fase 3: caricare i dati

Dopo avere avviato Redshift serverless, la fase successiva consiste nel caricare i dati per il POC. Che tu stia caricando un semplice file CSV, importando dati semistrutturati da S3 o trasmettendo i dati direttamente in streaming, Amazon Redshift offre la flessibilità necessaria per spostare rapidamente e facilmente i dati nelle tabelle Amazon Redshift dall’origine.
Scegli uno dei metodi seguenti per caricare i dati.
Caricare un file locale
Per un’importazione e un’analisi rapide, puoi utilizzare Amazon Redshift Query Editor V2 per caricare facilmente i file di dati dal desktop locale. Ha la capacità di elaborare i file in vari formati come CSV, JSON, AVRO, PARQUET, ORC e altri. Per consentire agli utenti, in qualità di amministratore, di caricare i dati da un desktop locale utilizzando Query Editor V2, devi specificare un bucket Amazon S3 comune e l’account utente deve essere configurato con le autorizzazioni appropriate. Per indicazioni dettagliate puoi seguire la procedura di caricamento semplice e sicuro dei dati in Amazon Redshift con Query Editor V2
Caricare un file Amazon S3
Per caricare i dati da un bucket Amazon S3 in Amazon Redshift, inizia utilizzando il comando COPY, specificando la posizione Amazon S3 di origine e la tabella Amazon Redshift di destinazione. Assicurati che i ruoli IAM e le autorizzazioni siano configurati correttamente per consentire ad Amazon Redshift di accedere al bucket Amazon S3 designato. Per indicazioni dettagliate, segui Tutorial: caricamento dei dati da Amazon S3. Puoi anche scegliere l’opzione Carica dati in Query Editor V2 per caricare direttamente i dati dal bucket S3.
Importazione continua dei dati
La copia automatica (in anteprima) è un’estensione del comando COPY e automatizza il caricamento continuo dei dati dai bucket Amazon S3. Quando crei un processo di copia, Amazon Redshift rileva quando vengono creati nuovi file Amazon S3 in un percorso specificato e li carica automaticamente senza alcun intervento. Amazon Redshift tiene traccia dei file caricati per verificare che vengano caricati una sola volta. Per istruzioni su come creare i processi di copia, consulta COPY JOB
Nota
La copia automatica è attualmente disponibile in anteprima e supportata solo in determinati cluster predisposti. Regioni AWS Per creare un cluster di anteprima per la copia automatica, consulta Creare un’integrazione di eventi S3 per copiare automaticamente i file dai bucket Amazon S3.
Caricare i dati in streaming
L’importazione in streaming comporta l’importazione a bassa latenza e ad alta velocità dei dati in streaming dal flusso di dati Amazon Kinesis
Fase 4: analizzare i dati

Dopo avere creato il namespace e il gruppo di lavoro Redshift serverless e avere caricato i dati, puoi eseguire immediatamente le query aprendo Query Editor V2 dal pannello di navigazione della console Redshift serverless
Eseguire query con Amazon Redshift Query Editor V2
Puoi accedere a Query Editor V2 dalla console Amazon Redshift. Consulta Semplificare l’analisi dei dati con Amazon Redshift Query Editor V2
In alternativa, se desideri eseguire un test di carico come parte del POC, puoi farlo seguendo la procedura descritta per installare ed eseguire Apache JMeter.
Eseguire un test di carico con Apache JMeter
Per eseguire un test di carico per simulare “N” utenti che inviano query simultaneamente ad Amazon Redshift, puoi utilizzare Apache JMeter
Per installare e configurare Apache JMeter per l'esecuzione sul tuo gruppo di lavoro Redshift Serverless, segui le istruzioni in Automatizza i test di carico di Amazon Redshift con Analytics Automation Toolkit
Dopo avere completato la personalizzazione delle istruzioni SQL e la finalizzazione del piano di test, salva ed esegui il piano di test per il gruppo di lavoro Redshift serverless. Per monitorare l’avanzamento del test, apri la console Redshift serverless
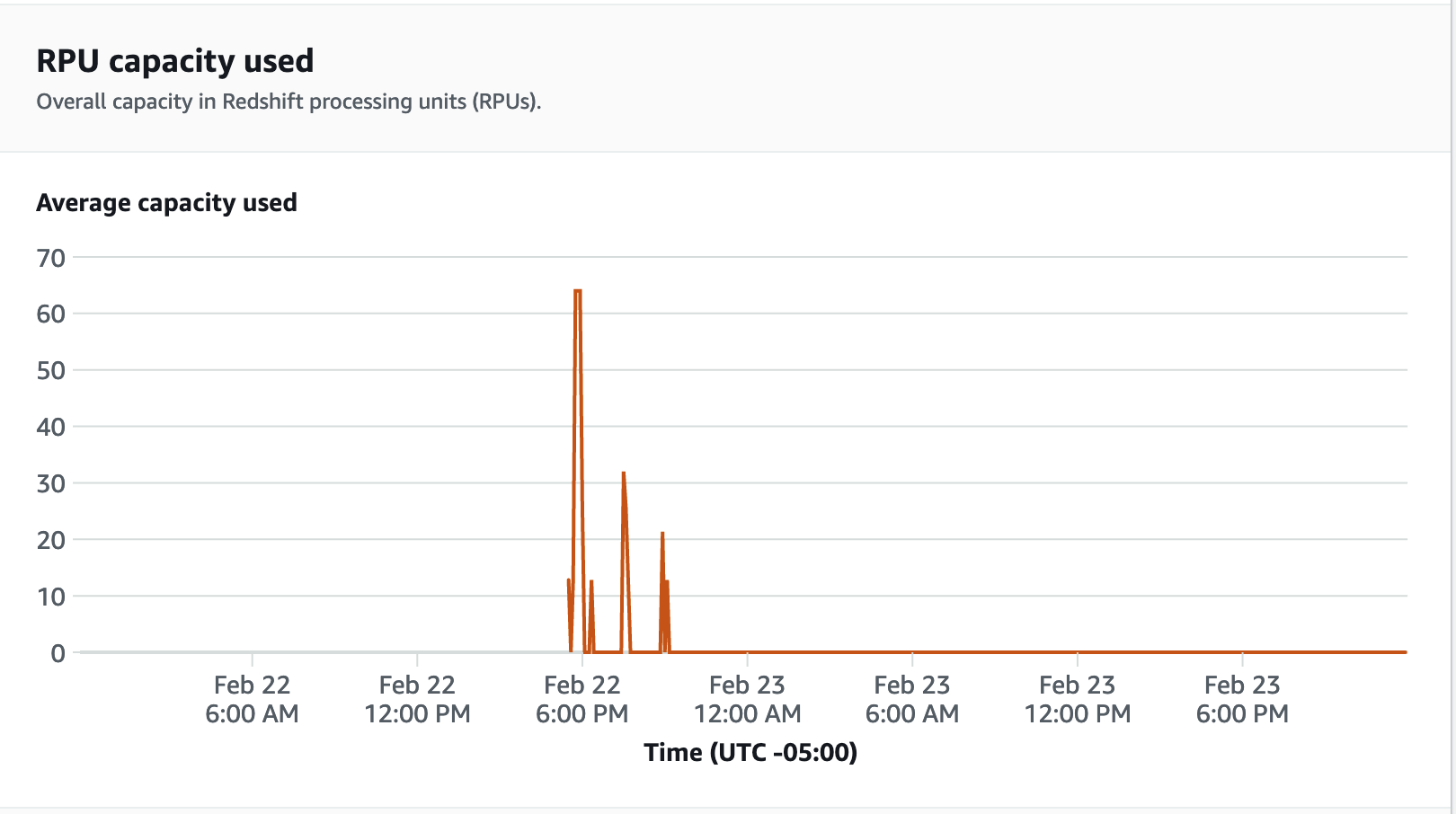
Per le metriche delle prestazioni scegli la scheda Prestazioni del database sulla console Redshift serverless per monitorare le metriche come Connessioni di database e Utilizzo della CPU. Qui puoi visualizzare un grafico per monitorare la capacità di RPU utilizzata e osservare come Redshift serverless scala automaticamente per soddisfare le richieste simultanee del carico di lavoro mentre il test di carico è in esecuzione sul gruppo di lavoro.
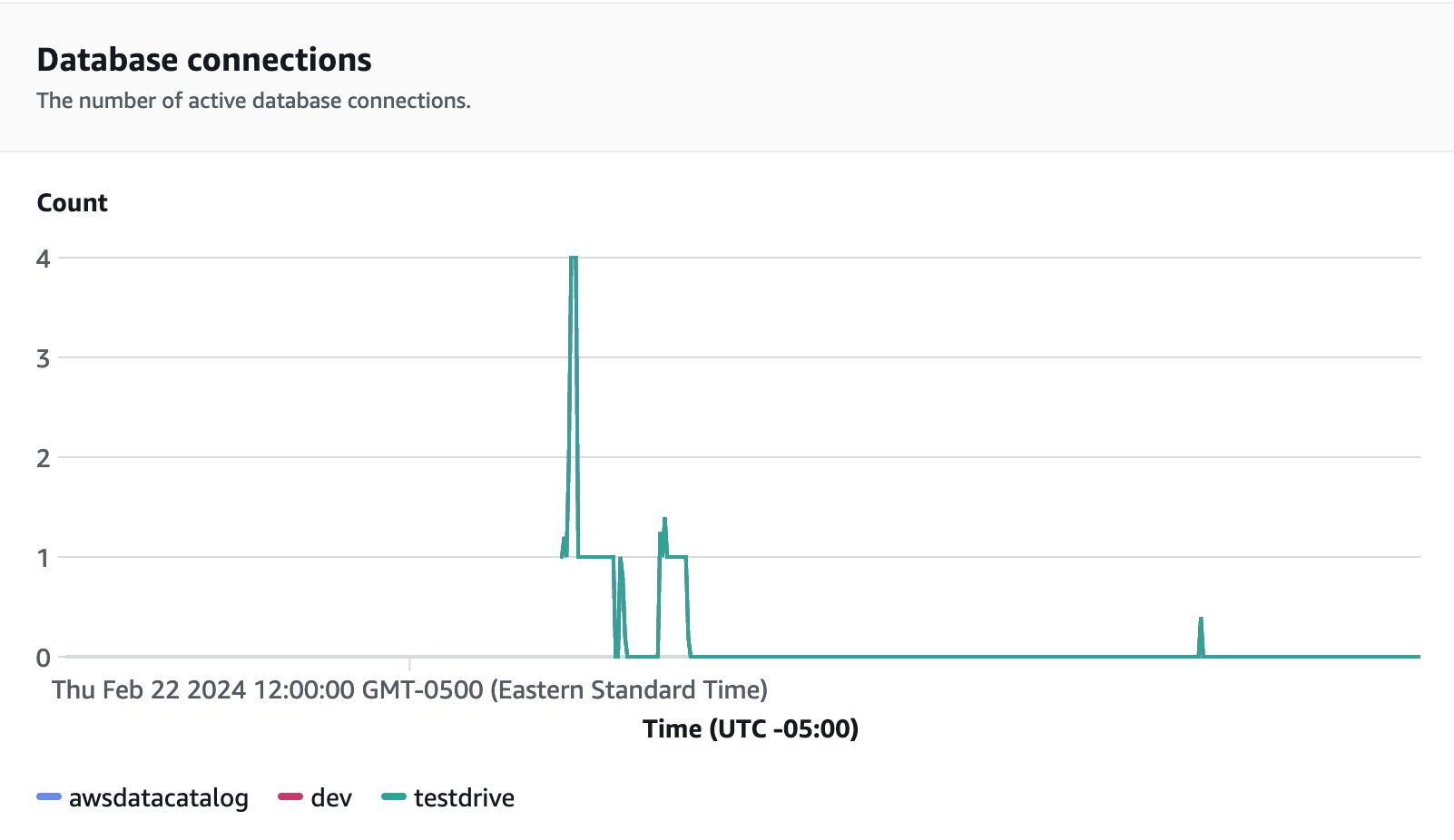
Le connessioni dei database sono un’altra metrica utile da monitorare durante l’esecuzione del test di carico per determinare come il gruppo di lavoro gestisce numerose connessioni simultanee in un dato momento per soddisfare le crescenti richieste del carico di lavoro.
Fase 5: ottimizzare

Amazon Redshift consente a decine di migliaia di utenti di elaborare exabyte di dati ogni giorno e potenziare i propri carichi di lavoro di analisi offrendo una varietà di configurazioni e funzionalità per supportare casi d’uso individuali. Quando scelgono tra queste opzioni, i clienti cercano strumenti che li aiutino a determinare la configurazione del data warehouse ottimale per supportare il carico di lavoro di Amazon Redshift.
Test Drive
Puoi utilizzare Test Drive
