Amazon Redshift non supporterà più la creazione di nuove UDF Python a partire dalla Patch 198. Le UDF Python esistenti continueranno a funzionare fino al 30 giugno 2026. Per ulteriori informazioni, consulta il post del blog
Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Caricamento di dati da Amazon EMR
Puoi utilizzare il comando COPY per caricare dati in parallelo da un cluster Amazon EMR configurato per scrivere file di testo sull'Hadoop Distributed File System (HDFS) del cluster come file a larghezza fissa, file delimitati da caratteri, file CSV o file. JSON-formatted
Processo per il caricamento dei dati da Amazon EMR
In questa sezione viene illustrato il processo di caricamento dei dati da un cluster Amazon EMR. Le sezioni seguenti forniscono le informazioni dettagliate necessarie per completare ogni fase.
-
Fase 1: configurazione delle autorizzazioni IAM
Gli utenti che creano il cluster Amazon EMR ed eseguono il comando COPY di Amazon Redshift devono disporre delle autorizzazioni necessarie.
-
Fase 2: Creazione di un cluster Amazon EMR
Configurare il cluster per i file di testo di output su Hadoop Distributed File System (HDFS). Saranno necessari l'ID del cluster Amazon EMR e il DNS pubblico principale del cluster (l'endpoint per l'istanza Amazon EC2 che ospita il cluster).
-
La chiave pubblica consente ai nodi del cluster Amazon Redshift per stabilire connessioni SSH agli host. Sarà utilizzato l'indirizzo IP per ciascun nodo del cluster per configurare i gruppi di sicurezza dell'host in modo da consentire l'accesso dal cluster Amazon Redshift utilizzando questi indirizzi IP.
-
Aggiungere la chiave pubblica del cluster Amazon Redshift al file di chiavi autorizzate dell'host in modo che l'host riconosca il cluster Amazon Redshift e accetti la connessione SSH.
-
Modifica i gruppi di sicurezza dell'istanza Amazon EMR per aggiungere regole di input per accettare gli indirizzi IP di Amazon Redshift.
-
Fase 6. esecuzione del comando COPY per il caricamento di dati
Da un database Amazon Redshift, eseguire il comando COPY per caricare i dati in una tabella Amazon Redshift.
Fase 1: configurazione delle autorizzazioni IAM
Gli utenti che creano il cluster Amazon EMR ed eseguono il comando COPY di Amazon Redshift devono disporre delle autorizzazioni necessarie.
Per configurare le autorizzazioni IAM
-
Aggiungi le seguenti autorizzazioni per l'utente che creerà il cluster Amazon EMR.
ec2:DescribeSecurityGroups ec2:RevokeSecurityGroupIngress ec2:AuthorizeSecurityGroupIngress redshift:DescribeClusters -
Aggiungi le seguenti autorizzazioni per l'utente o il ruolo IAM che eseguirà il comando COPY.
elasticmapreduce:ListInstances -
Aggiungere le seguenti autorizzazioni al ruolo IAM del cluster Amazon EMR.
redshift:DescribeClusters
Fase 2: Creazione di un cluster Amazon EMR
Il comando COPY carica i dati dai file nell'file di sistema distribuito Hadoop (HDFS) di Amazon EMR. Quando si crei il cluster Amazon EMR, configurare il cluster per i file di dati di output nell'HDFS del cluster.
Come creare un cluster Amazon EMR
-
Crea un cluster Amazon EMR nella stessa AWS regione del cluster Amazon Redshift.
Se il cluster Amazon Redshift si trova in un VPC, il cluster Amazon EMR dovrà trovarsi nello stesso gruppo VPC. Se il cluster Amazon Redshift utilizza la EC2-Classic modalità (ovvero non si trova in un VPC), anche il cluster Amazon EMR deve utilizzare la modalità. EC2-Classic Per ulteriori informazioni, consulta Gestione dei cluster nel cloud privato virtuale (VPC) nella Guida alla gestione di Amazon Redshift.
-
Configurare il cluster per i file di dati di output nell'HDFS del cluster. I nomi dei file HDFS non devono contenere asterischi (*) o punti interrogativi (?).
Importante
I nomi dei file non devono contenere asterischi (*) o punti interrogativi (?).
-
Specificare No per l'Auto-terminateopzione nella configurazione del cluster Amazon EMR in modo che il cluster rimanga disponibile durante l'esecuzione del comando COPY.
Importante
Se uno qualsiasi dei file di dati viene modificato o cancellato prima del completamento dell'operazione di COPY, si potrebbero ottenere risultati imprevisti o l'operazione di COPY potrebbe fallire.
-
Prendi nota dell'ID e del DNS pubblico principale del cluster (l'endpoint per l'istanza Amazon EC2 che ospita il cluster). Queste informazioni saranno utili per le fasi successive.
Fase 3: Recupero degli indirizzi IP dei nodi del cluster e della chiave pubblica del cluster Amazon Redshift
Sarà utilizzato l'indirizzo IP per ciascun nodo del cluster per configurare i gruppi di sicurezza dell'host in modo da consentire l'accesso dal cluster Amazon Redshift utilizzando questi indirizzi IP.
Come recuperare la chiave pubblica del cluster Amazon Redshift e gli indirizzi IP dei nodi del cluster tramite la console
-
Accedere alla console di gestione di Amazon Redshift.
-
Nel riquadro di navigazione scegli Clusters (Cluster).
-
Selezionare il cluster dall'elenco.
-
Individuare il gruppo SSH Ingestion Settings (Impostazioni di inserimento SSH).
Prendere nota dei valori di Cluster Public Key (Chiave pubblica del cluster) e Node IP addresses (Indirizzi IP del nodo). Queste informazioni saranno utili per le fasi successive.
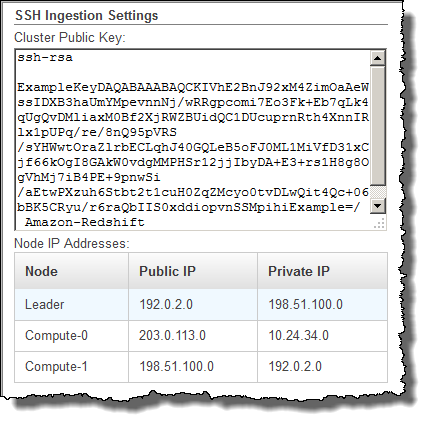
Saranno utilizzati gli indirizzi IP privati nella fase 3 per configurare l'host Amazon EC2 affinché accetti la connessione da Amazon Redshift.
Per recuperare la chiave pubblica del cluster e gli indirizzi IP dei nodi del cluster tramite la CLI di Amazon Redshift, emettere il comando describe-clusters. Esempio:
aws redshift describe-clusters --cluster-identifier <cluster-identifier>
La risposta includerà un ClusterPublicKey valore e l'elenco di indirizzi IP privati e pubblici, simili ai seguenti:
{ "Clusters": [ { "VpcSecurityGroups": [], "ClusterStatus": "available", "ClusterNodes": [ { "PrivateIPAddress": "10.nnn.nnn.nnn", "NodeRole": "LEADER", "PublicIPAddress": "10.nnn.nnn.nnn" }, { "PrivateIPAddress": "10.nnn.nnn.nnn", "NodeRole": "COMPUTE-0", "PublicIPAddress": "10.nnn.nnn.nnn" }, { "PrivateIPAddress": "10.nnn.nnn.nnn", "NodeRole": "COMPUTE-1", "PublicIPAddress": "10.nnn.nnn.nnn" } ], "AutomatedSnapshotRetentionPeriod": 1, "PreferredMaintenanceWindow": "wed:05:30-wed:06:00", "AvailabilityZone": "us-east-1a", "NodeType": "dc2.large", "ClusterPublicKey": "ssh-rsa AAAABexamplepublickey...Y3TAl Amazon-Redshift", ... ... }
Per recuperare la chiave pubblica del cluster e gli indirizzi IP dei nodi del cluster per il cluster con l'API di Amazon Redshift, utilizzare l'operazione DescribeClusters. Per ulteriori informazioni, consulta describe-clusters nella Amazon Redshift CLI Guide o DescribeClustersnella Amazon Redshift API Guide.
Fase 4: Aggiunta della chiave pubblica del cluster Amazon Redshift a ciascun file di chiavi autorizzate dell'host Amazon EC2
Aggiungere la chiave pubblica del cluster a ciascun file delle chiavi autorizzate dell'host per tutti i nodi del cluster Amazon EMR in modo che gli host riconoscano Amazon Redshift e accettino la connessione SSH.
Come aggiungere la chiave pubblica del cluster Amazon Redshift al file di chiavi autorizzate di ciascun host
-
Accedere all'host tramite una connessione SSH.
Per ulteriori informazioni sulla connessione a un'istanza che utilizza SSH, consultare Connessione all'istanza nella Guida per l'utente di Amazon EC2.
-
Copiare la chiave pubblica di Amazon Redshift dalla console o dal testo di risposta della CLI.
-
Copiare e incollare i contenuti della chiave pubblica nel file
/home/<ssh_username>/.ssh/authorized_keysnell'host. Includere la stringa completa, compreso il prefisso "ssh-rsa" e il suffisso "Amazon-Redshift". Ad esempio:ssh-rsa AAAACTP3isxgGzVWoIWpbVvRCOzYdVifMrh… uA70BnMHCaMiRdmvsDOedZDOedZ Amazon-Redshift
Fase 5: Configurazione degli host affinché accettino tutti gli indirizzi IP del cluster Amazon Redshift
Per consentire il traffico in entrata verso le istanze dell'host, modificare il gruppo di sicurezza e aggiungere una regola in entrata per ciascun nodo del cluster Amazon Redshift. In Type (Tipo), seleziona SSH con il protocollo TCP sulla porta 22. In Source (Origine), inserisci gli indirizzi IP privati dei nodi cluster di Amazon Redshift recuperati in Fase 3: Recupero degli indirizzi IP dei nodi del cluster e della chiave pubblica del cluster Amazon Redshift. Per informazioni sull'aggiunta di regole a un gruppo di sicurezza Amazon EC2, consultare Autorizzazione del traffico in entrata per le istanze nella Guida per l'utente di Amazon EC2.
Fase 6. esecuzione del comando COPY per il caricamento di dati
Eseguire un comando COPY per effettuare la connessione al cluster Amazon EMR e caricare i dati in una tabella Amazon Redshift. Il cluster Amazon EMR deve continuare a funzionare fino al completamento del comando COPY. Ad esempio, non configurare la terminazione automatica del cluster.
Importante
Se uno qualsiasi dei file di dati viene modificato o cancellato prima del completamento dell'operazione di COPY, si potrebbero ottenere risultati imprevisti o l'operazione di COPY potrebbe fallire.
Nel comando COPY, specificare l'ID cluster Amazon EMR e il percorso del file HDFS e il nome del file.
COPY sales FROM 'emr://myemrclusterid/myoutput/part*' CREDENTIALS IAM_ROLE 'arn:aws:iam::0123456789012:role/MyRedshiftRole';
È possibile utilizzare i caratteri jolly asterisco (*) e punto interrogativo (?) come parte dell'argomento del nome file. Ad esempio, part* carica i file part-0000, part-0001 e così via. Se specifichi solo il nome di una cartella, COPY tenta di caricare tutti i file nella cartella.
Importante
Se utilizzi caratteri jolly o solo il nome della cartella, verifica che non vengano caricati file indesiderati o che il comando COPY fallisca. Ad esempio, alcuni processi potrebbero scrivere un file di log nella cartella di output.
