Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Fasi di preparazione dei dati
L'esperienza di preparazione dei dati di Amazon Quick Sight offre undici potenti tipi di passaggi che consentono di trasformare i dati in modo sistematico. Ogni fase ha uno scopo specifico nel flusso di lavoro di preparazione dei dati.
I passaggi possono essere configurati tramite un'interfaccia intuitiva nel riquadro Configurazione, con un feedback immediato visibile nel riquadro Anteprima. I passaggi possono essere combinati in sequenza per creare sofisticate trasformazioni dei dati senza richiedere competenze SQL.
Ogni passaggio può ricevere input da una tabella fisica o l'output di un passaggio precedente. La maggior parte dei passaggi accetta un singolo input, con le eccezioni dei passaggi Append e Join, che richiedono esattamente due input.
Input
La fase di input avvia il flusso di lavoro di preparazione dei dati in Quick Sight consentendoti di selezionare e importare dati da più fonti per la trasformazione nei passaggi successivi.
Opzioni di input
-
Aggiungi set di dati
Sfrutta i set di dati Quick Sight esistenti come fonti di input, basandoti su dati già preparati e ottimizzati dal tuo team.
-
Aggiungi fonte di dati
Connettiti direttamente a database come Amazon Redshift, Athena, RDS o altre fonti supportate selezionando oggetti di database specifici e fornendo parametri di connessione.
-
Aggiungi file e carica
Importa i dati direttamente dai file locali in formati come CSV, TSV, Excel o JSON.
Configurazione
La fase di input non richiede alcuna configurazione. Il riquadro di anteprima mostra i dati importati insieme alle informazioni sulla fonte, inclusi i dettagli di connessione, il nome della tabella e i metadati delle colonne.
Note per l'utilizzo
-
All'interno di un unico flusso di lavoro possono esistere più passaggi di input.
-
Puoi aggiungere passaggi di input in qualsiasi momento del flusso di lavoro.
Aggiungi colonne calcolate
Il passo Aggiungi colonne calcolate consente di creare nuove colonne utilizzando espressioni a livello di riga che eseguono calcoli su colonne esistenti. È possibile creare nuove colonne utilizzando funzioni e operatori scalari (a livello di riga) e applicare calcoli a livello di riga che fanno riferimento a colonne esistenti.
Configurazione
Per configurare il passo Aggiungi colonne calcolate, nel riquadro Configurazione:
-
Assegna un nome alla nuova colonna calcolata.
-
Salva il calcolo.
-
Visualizza l'anteprima dei risultati dell'espressione.
-
Aggiungi altre colonne calcolate in base alle esigenze.
Note per l'utilizzo
-
In questo passaggio sono supportati solo i calcoli scalari (a livello di riga).
-
In SPICE, le colonne calcolate vengono materializzate e funzionano come colonne standard nei passaggi successivi.
Modifica il tipo di dati
Quick Sight semplifica la gestione dei tipi di dati supportando quattro tipi di dati astratti: datedecimal,integer, estring. Questi tipi astratti eliminano la complessità mappando automaticamente vari tipi di dati di origine ai rispettivi equivalenti Quick Sight. Ad esempio,, tinyint smallintinteger, e bigint sono tutti mappati suinteger, while datedatetime, e timestamp sono mappati su. date
Questa astrazione significa che devi solo comprendere i quattro tipi di dati di Quick Sight, poiché Quick Sight gestisce automaticamente tutte le conversioni e i calcoli dei tipi di dati sottostanti quando interagisce con diverse fonti di dati.
Configurazione
Per configurare il passaggio Modifica del tipo di dati, nel riquadro Configurazione:
-
Seleziona una colonna da convertire.
-
Scegli il tipo di dati di destinazione (
stringinteger,decimal, odate). -
Per le conversioni di data, specifica le impostazioni del formato e visualizza in anteprima i risultati in base ai formati di input. Scopri i formati di data supportati in Quick Sight.
-
Aggiungi colonne aggiuntive da convertire secondo necessità.
Note per l'utilizzo
-
Converti i tipi di dati di più colonne in un unico passaggio per una maggiore efficienza.
-
Quando si utilizza SPICE, tutte le modifiche ai tipi di dati vengono materializzate nei dati importati.
Rinomina colonne
Il passaggio Rinomina colonne consente di modificare i nomi delle colonne in modo che siano più descrittivi, intuitivi e coerenti con le convenzioni di denominazione dell'organizzazione.
Configurazione
Per configurare il passaggio Rinomina colonne, nel riquadro Configurazione:
-
Seleziona una colonna a cui assegnare un nome.
-
Immettete un nuovo nome per la colonna selezionata.
-
Aggiungi altre colonne da rinominare secondo necessità.
Note per l'utilizzo
-
Tutti i nomi delle colonne devono essere univoci all'interno del set di dati.
Seleziona colonne
Il passaggio Seleziona colonne consente di semplificare il set di dati includendo, escludendo e riordinando le colonne. Ciò consente di ottimizzare la struttura dei dati rimuovendo le colonne non necessarie e organizzando quelle rimanenti in una sequenza logica per l'analisi.
Configurazione
Per configurare il passo Seleziona colonne, nel riquadro Configurazione:
-
Scegli colonne specifiche da includere nell'output.
-
Seleziona le colonne nell'ordine che preferisci per stabilire la sequenza.
-
Usa Seleziona tutto per includere le colonne rimanenti nell'ordine originale.
-
Escludi le colonne indesiderate lasciandole deselezionate.
Caratteristiche principali
-
Le colonne di output vengono visualizzate nell'ordine di selezione.
-
Seleziona tutto mantiene la sequenza di colonne originale.
Note per l'utilizzo
-
Le colonne non selezionate vengono rimosse dai passaggi successivi.
-
Ottimizza le dimensioni del set di dati rimuovendo le colonne non necessarie.
Append
Il passaggio Append combina verticalmente due tabelle, in modo simile a un'operazione SQL UNION ALL. Quick Sight abbina automaticamente le colonne per nome anziché per sequenza, consentendo un consolidamento efficiente dei dati anche quando le tabelle hanno ordini di colonne diversi o un numero variabile di colonne.
Configurazione
Per configurare la fase Append, nel riquadro Configurazione:
-
Seleziona due tabelle di input da aggiungere.
-
Esamina la sequenza delle colonne di output.
-
Esamina quali colonne sono presenti in entrambe le tabelle rispetto alle tabelle singole.
Caratteristiche principali
-
Corrisponde alle colonne per nome anziché per sequenza.
-
Conserva tutte le righe di entrambe le tabelle, inclusi i duplicati.
-
Supporta tabelle con un numero diverso di colonne.
-
Segue la sequenza di colonne della Tabella 1 per le colonne corrispondenti, quindi aggiunge colonne uniche dalla Tabella 2.
-
Mostra indicatori di origine chiari per tutte le colonne
Note per l'utilizzo
-
Utilizzate innanzitutto un passaggio di ridenominazione quando aggiungete colonne con nomi diversi.
-
Ogni passaggio di aggiunta combina esattamente due tabelle; utilizza passaggi di aggiunta aggiuntivi per più tabelle.
Join
Il passaggio Join combina orizzontalmente i dati di due tabelle in base ai valori corrispondenti nelle colonne specificate. Quick Sight supporta i tipi Left Outer, Right Outer, Full Outer e Inner Join, offrendo opzioni flessibili per le vostre esigenze analitiche. Il passaggio include la risoluzione intelligente dei conflitti tra le colonne che gestisce automaticamente i nomi di colonna duplicati. Sebbene i self-join non siano disponibili come tipo di join specifico, è possibile ottenere risultati simili utilizzando la divergenza del flusso di lavoro.
Configurazione
Per configurare la fase di iscrizione, nel riquadro Configurazione:
-
Seleziona due tabelle di input da unire.
-
Scegli il tipo di join (Left Outer, Right Outer, Full Outer o Inner).
-
Specificate le chiavi di unione da ogni tabella.
-
Esamina i conflitti tra nomi di colonna risolti automaticamente.
Caratteristiche principali
-
Supporta più tipi di join per diverse esigenze analitiche.
-
Risolve automaticamente i nomi di colonna duplicati.
-
Accetta le colonne calcolate come chiavi di unione.
Note per l'utilizzo
-
Le chiavi di join devono avere tipi di dati compatibili; se necessario, utilizzare il passaggio Modifica tipo di dati.
-
Ogni passaggio di Join combina esattamente due tabelle; utilizza passaggi di Join aggiuntivi per più tabelle.
-
Crea un passaggio di ridenominazione dopo il Join per personalizzare le intestazioni delle colonne risolte automaticamente.
Aggregazione
La fase di aggregazione consente di riepilogare i dati raggruppando le colonne e applicando operazioni di aggregazione. Questa potente trasformazione condensa i dati dettagliati in riepiloghi significativi basati sulle dimensioni specificate. Quick Sight semplifica le operazioni SQL complesse attraverso un'interfaccia intuitiva, che offre funzioni di aggregazione complete, tra cui operazioni avanzate sulle stringhe come e. ListAgg ListAgg distinct
Configurazione
Per configurare la fase di aggregazione, nel riquadro Configurazione:
-
Seleziona le colonne in base alle quali raggruppare.
-
Scegli le funzioni di aggregazione per le colonne di misura.
-
Personalizza i nomi delle colonne di output.
-
Per
ListAggeListAgg distinct:-
Seleziona la colonna da aggregare.
-
Scegli un separatore (virgola, trattino, punto e virgola o linea verticale).
-
-
Visualizza l'anteprima dei dati riepilogati.
Funzioni supportate per tipo di dati
| Tipo di dati | Funzioni supportate |
|---|---|
|
Numerico |
|
|
Data |
|
|
Stringa |
|
Caratteristiche principali
-
Applica diverse funzioni di aggregazione alle colonne nello stesso passaggio.
-
Le funzioni di raggruppamento senza aggregazione fungono da SQL SELECT DISTINCT.
-
ListAggconcatena tutti i valori;ListAgg distinctinclude solo valori univoci. -
ListAggper impostazione predefinita, le funzioni mantengono l'ordinamento crescente.
Note per l'utilizzo
-
L'aggregazione riduce significativamente il numero di righe nel set di dati.
-
ListAggeListAgg distinctsupportanodatei valori ma non.datetime -
Usa i separatori per personalizzare l'output della concatenazione di stringhe.
Filtro
La fase Filtro consente di restringere il set di dati includendo solo le righe che soddisfano criteri specifici. Puoi applicare più condizioni di filtro in un unico passaggio, combinandole tutte tramite la AND logica per concentrare l'analisi sui dati pertinenti.
Configurazione
Per configurare la fase Filtro, nel riquadro Configurazione:
-
Seleziona una colonna da filtrare.
-
Scegli un operatore di confronto.
-
Specificate i valori del filtro in base al tipo di dati della colonna.
-
Se necessario, aggiungi condizioni di filtro aggiuntive su colonne diverse.
Nota
-
Filtri a stringa con «is in» o «is not in»: inserisci più valori (uno per riga).
-
Filtri numerici e di data: inserisci valori singoli (tranne «tra» che richiede due valori).
Operatori supportati per tipo di dati
| Tipo di dati | Operatori supportati |
|---|---|
|
Numero intero e decimale |
Uguale, non è uguale Maggiore di, Minore di È maggiore o uguale a, È minore o uguale a È compreso tra |
|
Data |
Dopo, prima È compreso tra È dopo o uguale a, È prima o uguale a |
|
Stringa |
Uguale, non è uguale Inizia con, finisce con Contiene, non contiene È dentro, non è dentro |
Note per l'utilizzo
-
Applica più condizioni di filtro in un unico passaggio.
-
Combina le condizioni tra diversi tipi di dati.
-
Visualizza in anteprima i risultati filtrati in tempo reale.
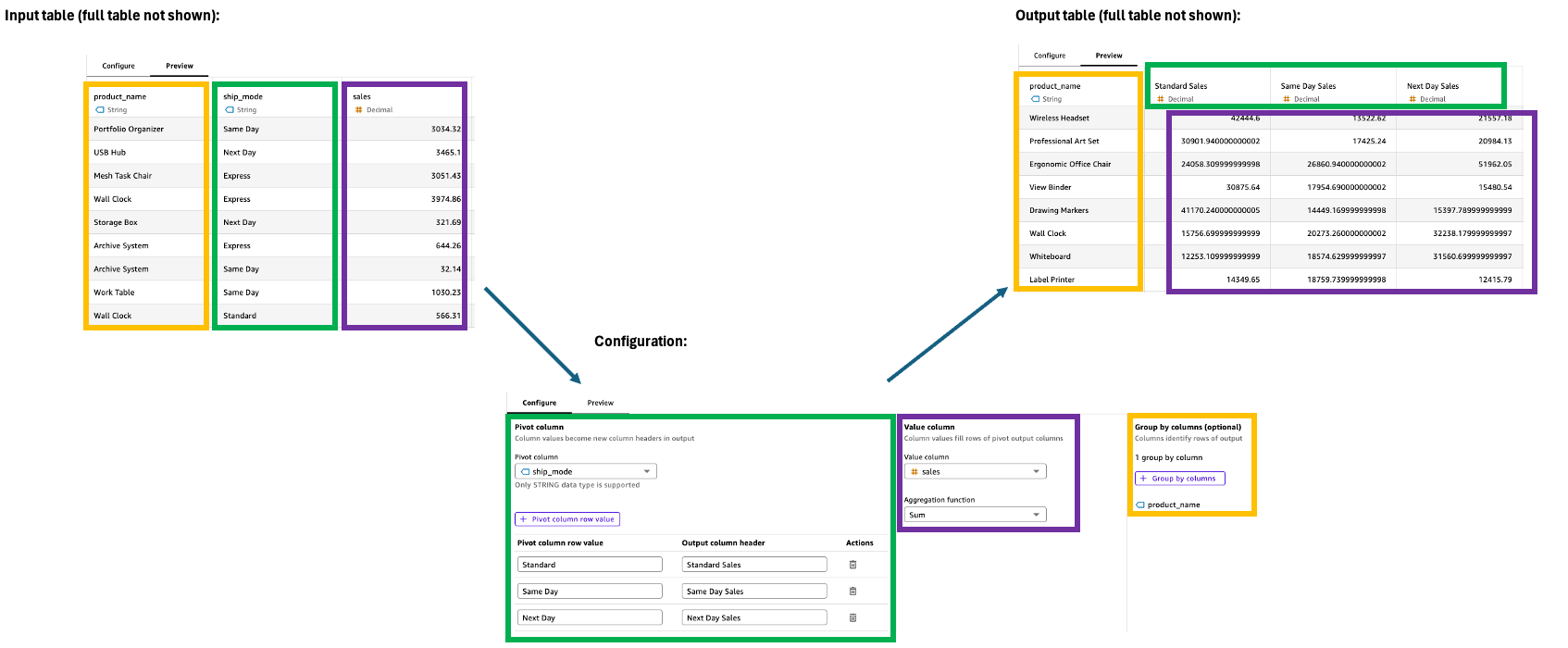
Pivot
La fase Pivot trasforma i valori delle righe in colonne uniche, convertendo i dati da un formato lungo a un formato ampio per facilitare il confronto e l'analisi. Questa trasformazione richiede specifiche per il filtraggio, l'aggregazione e il raggruppamento dei valori per gestire efficacemente le colonne di output.
Configurazione
Per configurare la fase Pivot, utilizza quanto segue nel riquadro Configurazione:
-
Colonna Pivot: seleziona la colonna i cui valori diventeranno intestazioni di colonna (ad esempio, Categoria).
-
Valore della riga della colonna pivot: filtra valori specifici da includere (ad esempio, tecnologia, forniture per ufficio).
-
Intestazione delle colonne di output: personalizza le nuove intestazioni di colonna (l'impostazione predefinita sono i valori delle colonne pivot).
-
Colonna dei valori: seleziona la colonna da aggregare (ad esempio, Vendite).
-
Funzione di aggregazione: scegli il metodo di aggregazione (ad esempio, Sum).
-
Raggruppa per: specifica le colonne organizzative (ad esempio, Segmento).
Operatori supportati per tipo di dati
| Tipo di dati | Operatori supportati |
|---|---|
|
Numero intero e decimale |
|
|
Data |
|
|
Stringa |
|
Note per l'utilizzo
-
Ogni colonna pivotata contiene i valori aggregati della colonna dei valori.
-
Personalizza le intestazioni delle colonne per maggiore chiarezza.
-
Visualizza in anteprima i risultati della trasformazione in tempo reale.
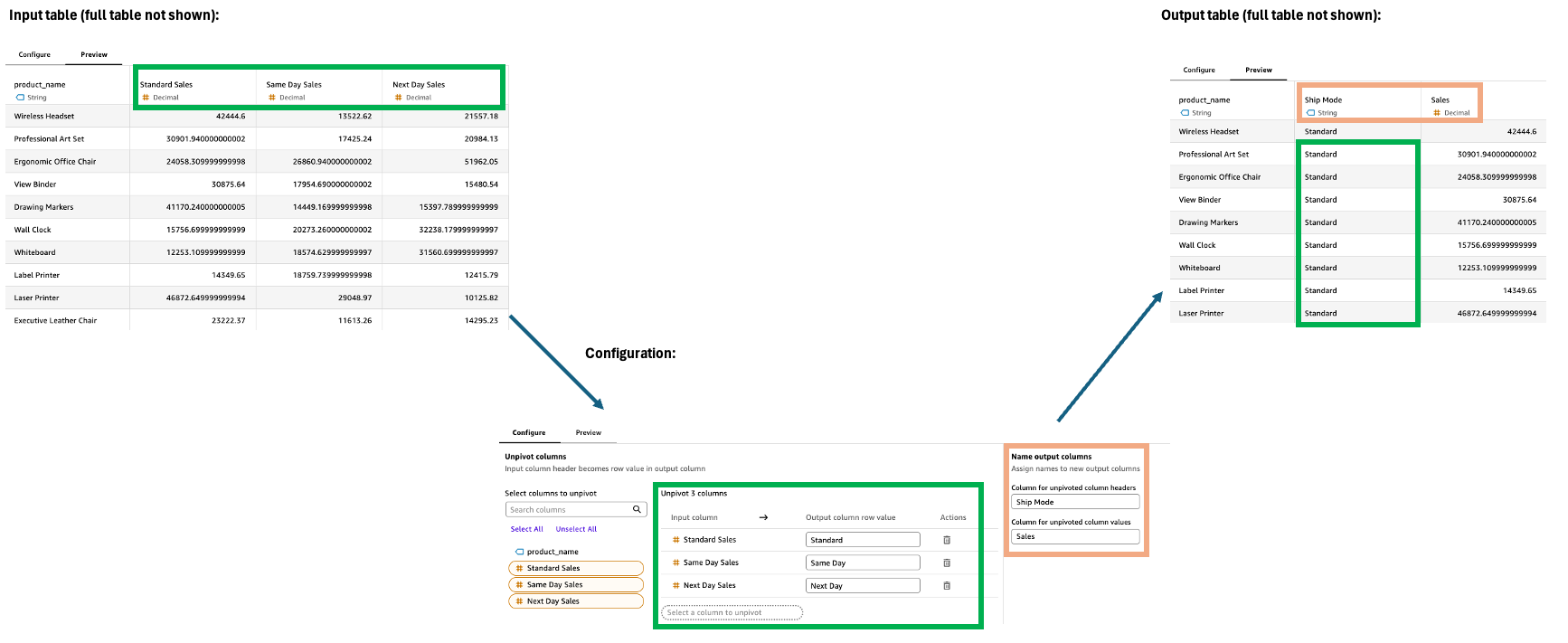
Unpivot
La fase Unpivot trasforma le colonne in righe, convertendo dati di grandi dimensioni in un formato più lungo e stretto. Questa trasformazione aiuta a organizzare i dati distribuiti su più colonne in un formato più strutturato per facilitare l'analisi e la visualizzazione.
Configurazione
Per configurare la fase Unpivot, nel riquadro Configurazione:
-
Seleziona le colonne da scomporre in righe.
-
Definisci i valori delle righe delle colonne di output. L'impostazione predefinita è il nome della colonna originale. Alcuni esempi includono tecnologia, forniture per ufficio e mobili.
-
Assegna un nome alle due nuove colonne di output.
-
Intestazione di colonna non pivotata: il nome dei nomi delle colonne precedenti (ad esempio, Categoria)
-
Valori di colonna non pivotati: il nome dei valori non pivotati (ad esempio, Sales)
-
Caratteristiche principali
-
Mantiene tutte le colonne non ruotate nell'output.
-
Crea automaticamente due nuove colonne: una per i nomi delle colonne precedenti e una per i valori corrispondenti.
-
Trasforma dati di grandi dimensioni in un formato lungo.
Note per l'utilizzo
-
Tutte le colonne non pivotate devono avere tipi di dati compatibili.
-
Il numero di righe in genere aumenta dopo l'annullamento della rotazione.
-
Visualizza l'anteprima delle modifiche in tempo reale prima di applicarle.
