Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Progettazione di architetture AI serverless
Tradurre i principi dell'intelligenza artificiale senza server in sistemi reali richiede un'architettura attenta. L'obiettivo è quello di integrarle liberamente in pipeline modulari e intelligenti che scalino elasticamente e rispondano Servizi AWS in tempo reale.
Questa sezione fornisce indicazioni prescrittive su come assemblare sistemi di intelligenza artificiale nativi del cloud utilizzando servizi AWS serverless, tra cui l'orchestrazione generativa dell'intelligenza artificiale, l'inferenza in tempo reale e l'edge computing. Ogni modello architettonico corrisponde a un caso d'uso aziendale comune, garantendo pertinenza e applicabilità.
In questa sezione
Modelli di architettura fondamentali
In un'architettura applicativa tradizionale basata sugli eventi, il sistema è strutturato in quattro livelli logici che separano le preoccupazioni e consentono scalabilità e reattività. Nella parte superiore, il livello applicativo gestisce le interazioni degli utenti e gli eventi dell'interfaccia utente APIs, spesso attivando nel sistema eventi specifici del dominio. Al di sotto di esso, il livello di orchestrazione gestisce i flussi di lavoro, le regole aziendali e il sequenziamento degli eventi utilizzando strumenti come macchine a stati o flussi di lavoro senza server. Il livello di servizio contiene funzioni o microservizi modulari e riutilizzabili che rispondono agli eventi ed eseguono la logica di base. Alla base, il livello dati è responsabile della persistenza, dello streaming e dell'approvvigionamento degli eventi. Il livello dati sfrutta servizi come database, archivi di oggetti o registri degli eventi per emettere e utilizzare eventi di modifica. Insieme, questi livelli supportano un'architettura liberamente accoppiata, scalabile e gestibile in cui gli eventi determinano il flusso dell'intero stack.
I sistemi di intelligenza artificiale serverless sono composti in modo analogo da servizi liberamente accoppiati e basati sugli eventi che possono scalare, evolversi e ripristinare in modo indipendente. Per progettare questi sistemi con coerenza e scalabilità, è essenziale considerare l'architettura come cinque livelli distinti. Ogni livello svolge una funzione specifica e si associa direttamente a una struttura appositamente Servizi AWS progettata. Il diagramma seguente mostra ogni livello.
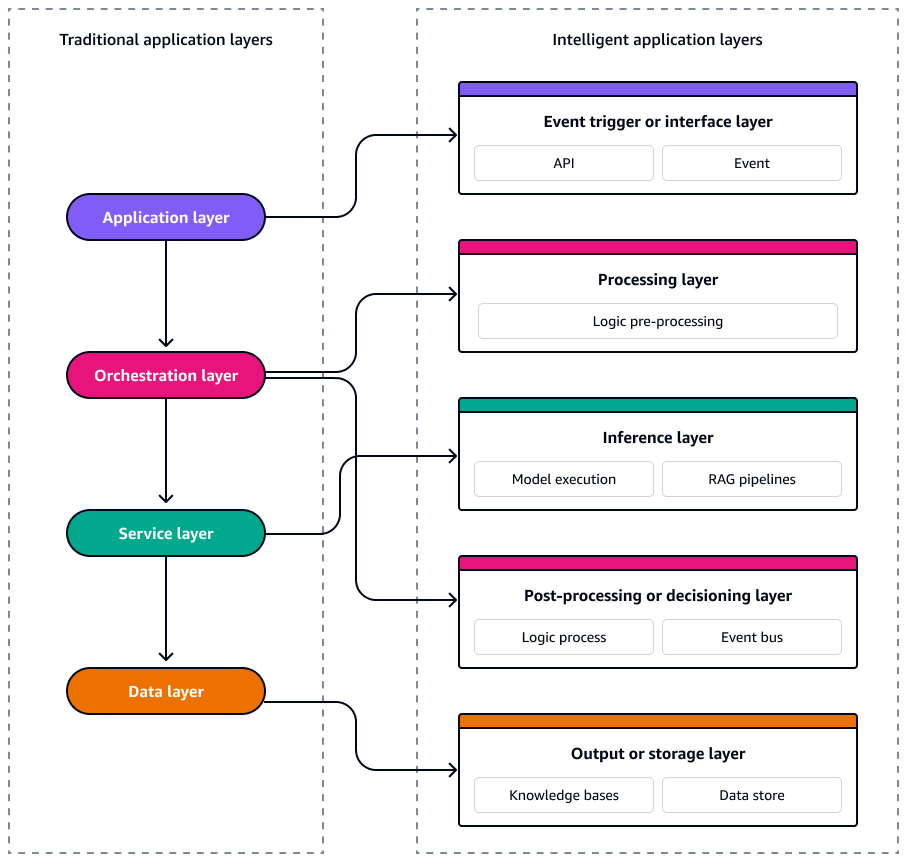
Questi cinque livelli costituiscono il modello per la creazione di applicazioni intelligenti e basate sugli eventi, resilienti, osservabili e ottimizzate sia in termini di costi che di prestazioni.
Event Trigger o livello di interfaccia
L'event trigger o livello di interfaccia è il punto di ingresso al tuo sistema di intelligenza artificiale senza server. Cattura le interazioni degli utenti, gli eventi di sistema o le modifiche ai dati e li emette come eventi strutturati nell'architettura. Consente l'orchestrazione asincrona e separa gli input a monte dalla logica di elaborazione a valle.
Le responsabilità del livello di attivazione degli eventi includono quanto segue:
-
Registra le azioni degli utenti come clic, messaggi e caricamenti
-
Emetti eventi di dominio o notifiche di modifica
-
Normalizza i dati in entrata per il consumo a valle
Servizi AWS che vengono comunemente utilizzati con questo livello includono quanto segue:
-
Amazon API Gateway accetta l'input dell'utente tramite REST o WebSocket APIs.
-
Amazon EventBridge indirizza gli eventi interni o esterni utilizzando un registro di schemi.
-
Amazon Simple Storage Service (Amazon S3) attiva la creazione di oggetti come il caricamento di documenti e file multimediali.
-
Amazon Kinesis e Amazon Managed Streaming for Apache Kafka (Amazon MSK) acquisiscono eventi di streaming su larga scala.
Esempio: una richiesta di assistenza clienti inviata tramite un modulo Web attiva una EventBridge regola, avviando un flusso di lavoro degli agenti Amazon Bedrock a valle.
Livello di elaborazione
Il livello di elaborazione trasforma o arricchisce i dati prima di passarli al modello di intelligenza artificiale. Gestisce attività di pre-elaborazione come la convalida degli input, la formattazione, l'etichettatura dei metadati, il rilevamento della lingua e l'arricchimento dei dati utilizzando tabelle di ricerca o esterne. APIs
Le responsabilità del livello di elaborazione includono quanto segue:
-
Convalida e normalizza l'input non elaborato.
-
Estrai o inserisci metadati come lingua e ID cliente.
-
Logica di routing o diramazione basata sugli attributi dei dati.
Servizi AWS che vengono comunemente utilizzati con questo livello includono quanto segue:
-
AWS Lambdaè un calcolo stateless e basato sugli eventi per la logica di trasformazione.
-
AWS Step Functionsorchestrano attività di preelaborazione in più fasi.
-
Amazon Comprehend fornisce il rilevamento del linguaggio, il riconoscimento di entità o l'analisi del sentimento come parte della preelaborazione.
Esempio: i reclami assicurativi caricati vengono scansionati alla ricerca di informazioni di identificazione personale (PII) e tipo di documento utilizzando Lambda e Amazon Comprehend prima del riepilogo basato sull'intelligenza artificiale.
Livello di inferenza
Essendo il fulcro del sistema di intelligenza artificiale, il livello di inferenza esegue l'inferenza dell'apprendimento automatico (ML) o del modello di base (FM). Può includere uno o più modelli, generativi, predittivi o di classificazione, a seconda del caso d'uso.
Le responsabilità del livello di inferenza includono quanto segue:
-
Esegui l'inferenza del modello ML o FM.
-
Genera previsioni, classificazioni o contenuti generati.
-
Integra il contesto Retrieval Augmented Generation (RAG) ove applicabile.
Servizi AWS che vengono comunemente utilizzati con questo livello includono quanto segue:
-
Amazon Bedrock fornisce inferenza del modello di base (testo, immagine, multimodale) di provider come Anthropic, Amazon (per Amazon Nova) e. Meta Mistral
-
Amazon SageMaker Serverless Inference esegue modelli ML personalizzati su larga scala.
-
Amazon Bedrock Agents fornisce un ragionamento basato su un modello di linguaggio di grandi dimensioni (LLM) e un'orchestrazione basata sugli obiettivi.
Esempio: un agente Amazon Bedrock utilizza Amazon Nova Pro per generare una risposta a una richiesta di supporto complessa, basata su conoscenze aziendali tramite RAG.
Livello di post-elaborazione o decisionale
Il livello di post-elaborazione o decisionale perfeziona o agisce sui risultati dell'inferenza. Può formattare la risposta, registrare l'output, richiamare azioni a valle o prendere decisioni basate sulla fiducia del modello, sulle classificazioni o su regole aziendali esterne.
Le responsabilità del livello di post-elaborazione o decisionale includono quanto segue:
-
Formatta l'output AI per sistemi o display a valle.
-
Attiva la logica o la chiamata condizionale. APIs
-
Indirizza i dati arricchiti per l'archiviazione o l'analisi.
Servizi AWS che vengono comunemente utilizzati con questo livello includono quanto segue:
-
Lambda può formattare risultati, applicare trasformazioni o effettuare chiamate. APIs
-
Amazon Simple Notification Service (Amazon SNS) ed EventBridge emettono ulteriori eventi in base all'output del modello.
-
Step Functions applica la logica a catena, ad esempio, aumenta la richiesta di supporto se il sentimento è uguale a «arrabbiato».
Esempio: una raccomandazione di prodotto proveniente da un LLM viene convalidata in modo incrociato rispetto all'inventario in tempo reale utilizzando una funzione Lambda prima che la raccomandazione venga inviata all'utente.
Livello di output o di archiviazione
Infine, il livello di output o di archiviazione gestisce la fornitura dei risultati agli utenti o ai sistemi e mantiene gli output strutturati per il controllo, l'analisi o i cicli di feedback.
Le responsabilità del livello di output o di archiviazione includono quanto segue:
-
Restituisci i risultati dell'IA agli utenti finali tramite APIs o UIs.
-
Mantieni gli output e i log strutturati.
-
Inserisci dati nei data lake o riqualifica le pipeline.
Servizi AWS che vengono comunemente utilizzati con questo livello includono quanto segue:
-
Amazon S3 archivia log di inferenza, riepiloghi o contenuti generati.
-
Amazon DynamoDB offre uno storage chiave-valore a bassa latenza per l'output AI specifico della sessione.
-
Amazon OpenSearch Service fornisce output strutturati a indice per la ricerca e l'analisi.
-
API Gateway e WebSocket APIs fornisce risposte di ritorno a client frontend o mobili.
Esempio: un riepilogo di un documento legale, generato da Amazon Bedrock, viene archiviato in Amazon S3 e indicizzato OpenSearch in Service per consentire la ricerca semantica aziendale.
Considerazioni sulla progettazione su più livelli
Le seguenti considerazioni e modelli chiave di progettazione si applicano a tutti i livelli architettonici:
-
Resilienza: ogni livello dovrebbe fallire e riprovare indipendentemente (ad esempio, dead-letter queues () su Lambda)DLQs.
-
Osservabilità: invia ad Amazon CloudWatch log, tracce e metriche strutturati da ogni fase per rilevare deviazioni comportamentali.
-
Sicurezza: utilizza la separazione dei ruoli AWS Identity and Access Management(IAM) e AWS Key Management Service(AWS KMS) per la crittografia dei dati su più livelli.
-
Ottimizzazione dei costi: utilizza l'esecuzione asincrona ove possibile e scegli modelli della giusta dimensione.
-
Estensibilità: il design modulare consente di sostituire o aggiornare i servizi in modo indipendente.
Questi cinque livelli formano un'architettura di riferimento modulare, scalabile e senza server per carichi di lavoro basati sull'intelligenza artificiale su. AWS Ogni livello può essere sviluppato, implementato e ottimizzato in modo indipendente, per consentire un'iterazione rapida, l'eccellenza operativa e una chiara separazione delle preoccupazioni tra i domini aziendali.
Utilizzando questo modello a più livelli come struttura di progettazione, le aziende possono standardizzare il loro approccio all'intelligenza artificiale senza server e accelerare il percorso dal prototipo alla produzione in tutta sicurezza.
Considerazioni sulla progettazione dell'architettura
L'architettura AI serverless AWS consente di creare applicazioni intelligenti modulari, scalabili e di livello di produzione. Che si tratti di implementare modelli sull'edge, orchestrare pipeline di inferenza in più fasi o creare assistenti AI generativi, è possibile potenziare la prossima generazione di applicazioni native per l'intelligenza artificiale. Servizi AWS
Quando progetti un'architettura AI serverless, tieni presente i seguenti obiettivi di progettazione chiave e le migliori pratiche:
-
Sicurezza: utilizza ruoli IAM dettagliati, crittografa richieste e output e limita l'accesso alle API.
-
Osservabilità: log integrati e personalizzati per ogni fase della CloudWatch AWS X-Ray pipeline.
-
Scalabilità: utilizza solo componenti serverless, come Lambda, Amazon Bedrock e Serverless Inference. SageMaker
-
Latenza: sfrutta Lambda @Edge, la concorrenza fornita o l'inferenza asincrona.
-
Modularità: progetta pipeline utilizzando trigger di eventi e funzioni isolate per ogni attività.
-
Riusabilità: parametrizza i prompt, usa livelli Lambda condivisi e disaccoppia la logica utilizzando Step Functions.
