Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Rapido concatenamento degli schemi della saga
Reimmaginando il prompt chaining LLM come una saga basata sugli eventi, sblocchiamo un nuovo modello operativo: i flussi di lavoro diventano distribuiti, recuperabili e coordinati semanticamente tra agenti autonomi. Ogni fase di pronta risposta viene riformulata come un'attività atomica, emessa come evento, consumata da un agente dedicato e arricchita con metadati contestuali.
Il diagramma seguente è un esempio di concatenamento di prompt LLM:
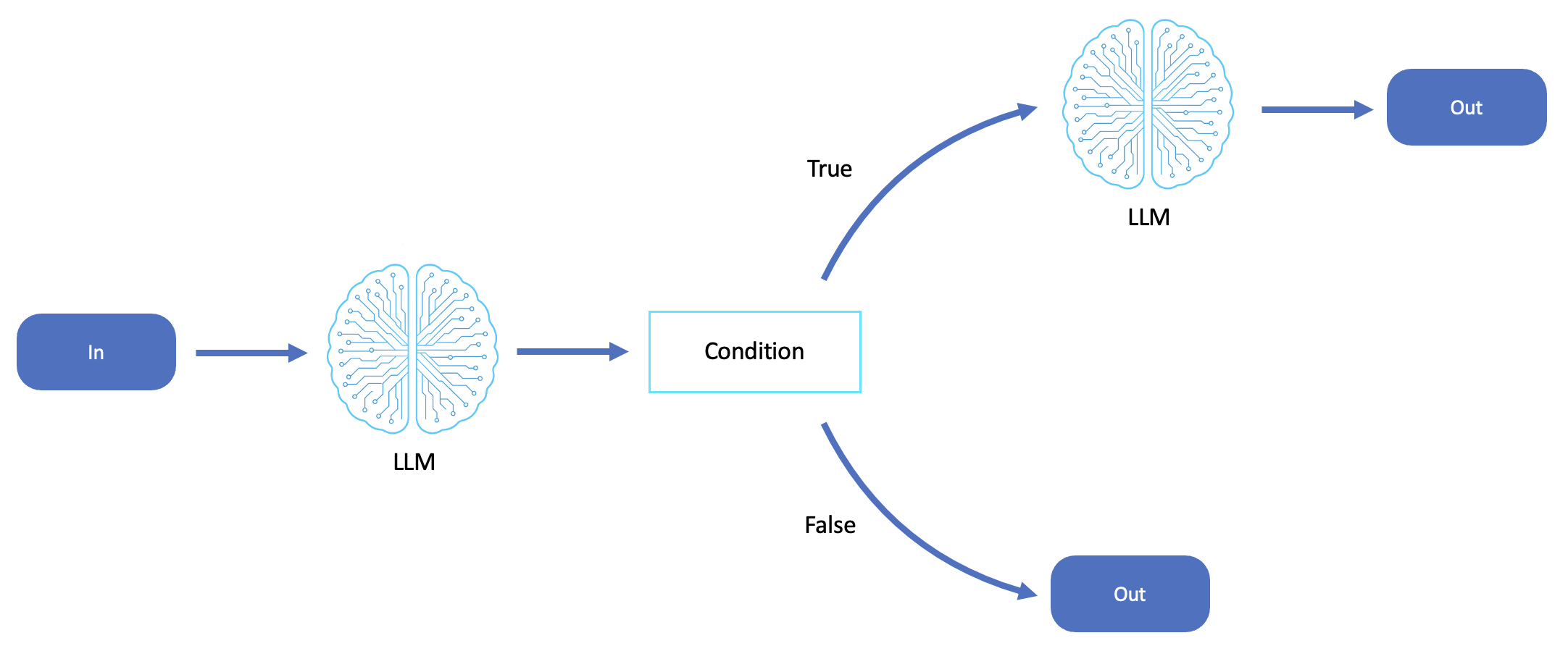
Coreografia saga
Il modello coreografico della saga è un approccio di implementazione in sistemi distribuiti che non ha un coordinatore centrale. Invece, ogni servizio o componente pubblica eventi che attivano l'azione successiva del flusso di lavoro. Questo modello è ampiamente utilizzato nei sistemi distribuiti per la gestione delle transazioni tra più servizi. In una saga, il sistema esegue una serie di transazioni locali coordinate. Se una fallisce, il sistema attiva azioni di compensazione per mantenere la coerenza.
Il diagramma seguente è un esempio di coreografia da saga:
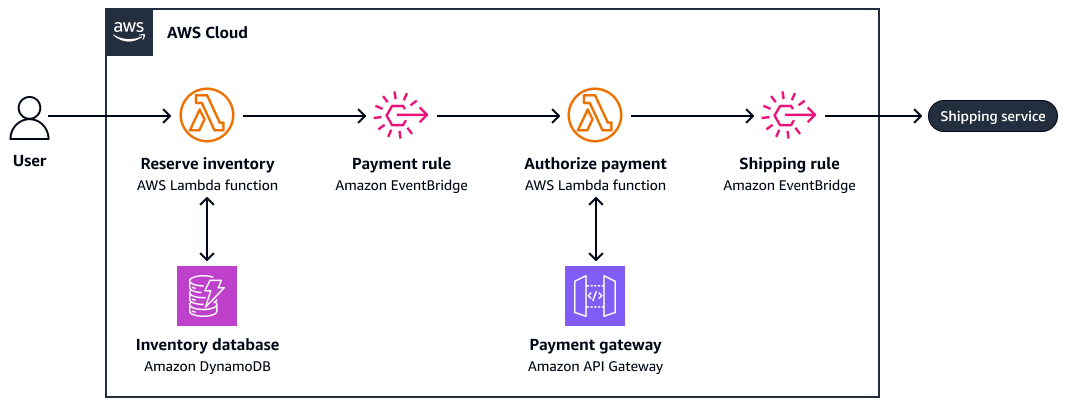
-
Inventario di riserva
-
Autorizza il pagamento
-
Crea un ordine di spedizione
Se la fase 3 fallisce, il sistema richiama azioni di compensazione (ad esempio, annullare un pagamento o rilasciare l'inventario).
Questo modello è particolarmente utile nelle architetture basate sugli eventi, in cui i servizi sono collegati in modo flessibile e gli stati devono essere risolti in modo coerente nel tempo, anche in presenza di guasti parziali.
Schema di concatenamento rapido
Il concatenamento rapido ricorda lo schema della saga sia nella struttura che nello scopo. Esegue una serie di passaggi di ragionamento che vengono creati in sequenza preservando il contesto e consentendo rollback e revisioni.
Coreografia dell'agente
-
LLM interpreta una query utente complessa e genera un'ipotesi
-
LLM elabora un piano per risolvere il problema
-
LLM esegue una sottoattività (ad esempio, utilizzando una chiamata a uno strumento o recuperando conoscenze)
-
LLM perfeziona l'output o rivisita un passaggio precedente se ritiene un risultato insoddisfacente
Se un risultato intermedio è difettoso, il sistema può eseguire una delle seguenti operazioni:
-
Riprova i passaggi utilizzando un approccio diverso
-
Torna a un prompt precedente e ripianifica
-
Utilizzate un ciclo di valutazione (ad esempio, dal pattern valutatore-ottimizzatore) per rilevare e correggere gli errori
Analogamente al modello saga, il prompt chaining consente meccanismi di avanzamento e rollback parziali. Ciò avviene attraverso il perfezionamento iterativo e la correzione diretta da LLM anziché attraverso la compensazione delle transazioni del database.
Il diagramma seguente è un esempio di coreografia tra agenti:
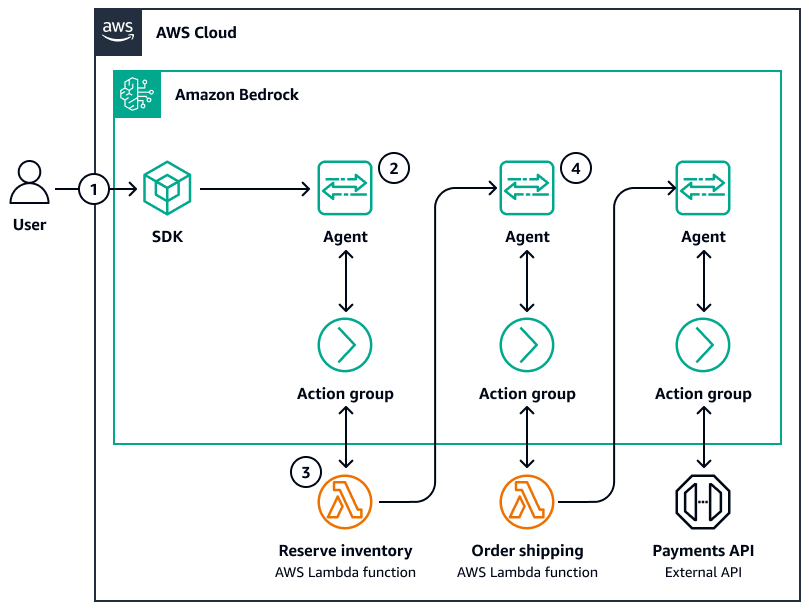
-
Un utente invia una richiesta tramite un SDK.
-
Un agente Amazon Bedrock orchestra il ragionamento attraverso quanto segue:
-
Interpretazione (LLM)
-
Pianificazione (LLM)
-
Esecuzione tramite uno strumento o una base di conoscenze
-
Costruzione della risposta
-
-
Se uno strumento si guasta o restituisce dati insufficienti, l'agente può ripianificare o riformulare dinamicamente l'attività.
-
La memoria (ad esempio, un archivio vettoriale a breve termine) può preservare il proprio stato attraverso i passaggi
Da asporto
Laddove Saga Pattern gestisce le chiamate di servizio distribuite con una logica di compensazione, il prompt chaining gestisce le attività di ragionamento con sequenziamento riflessivo e ripianificazione adattiva. Entrambi i sistemi consentono progressi incrementali, punti decisionali decentralizzati e ripristino degli errori, e tutto ciò avviene attraverso un ragionamento informato anziché un rigido rollback.
Il concatenamento rapido introduce il ragionamento transazionale, che è l'equivalente cognitivo delle saghe. Cioè, ogni «pensiero» viene rivalutato, rivisto o abbandonato come parte di un dialogo più ampio mirato.
