Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Parallelizzazione e schemi di dispersione
Molte attività avanzate di ragionamento e generazione, come il riepilogo di documenti di grandi dimensioni, la valutazione di più percorsi di soluzione o il confronto di diverse prospettive, traggono vantaggio dall'esecuzione parallela dei prompt. I flussi di lavoro sequenziali tradizionali non sono all'altezza quando sono richieste scalabilità, reattività e tolleranza agli errori. Per ovviare a questo problema, la parallelizzazione basata su LLM può essere reinventata utilizzando un modello di scatter-gather basato sugli eventi, in cui le attività vengono assegnate dinamicamente ad agenti autonomi e i risultati sintetizzati in modo intelligente.
Il diagramma seguente è un esempio di flusso di lavoro di parallelizzazione LLM:
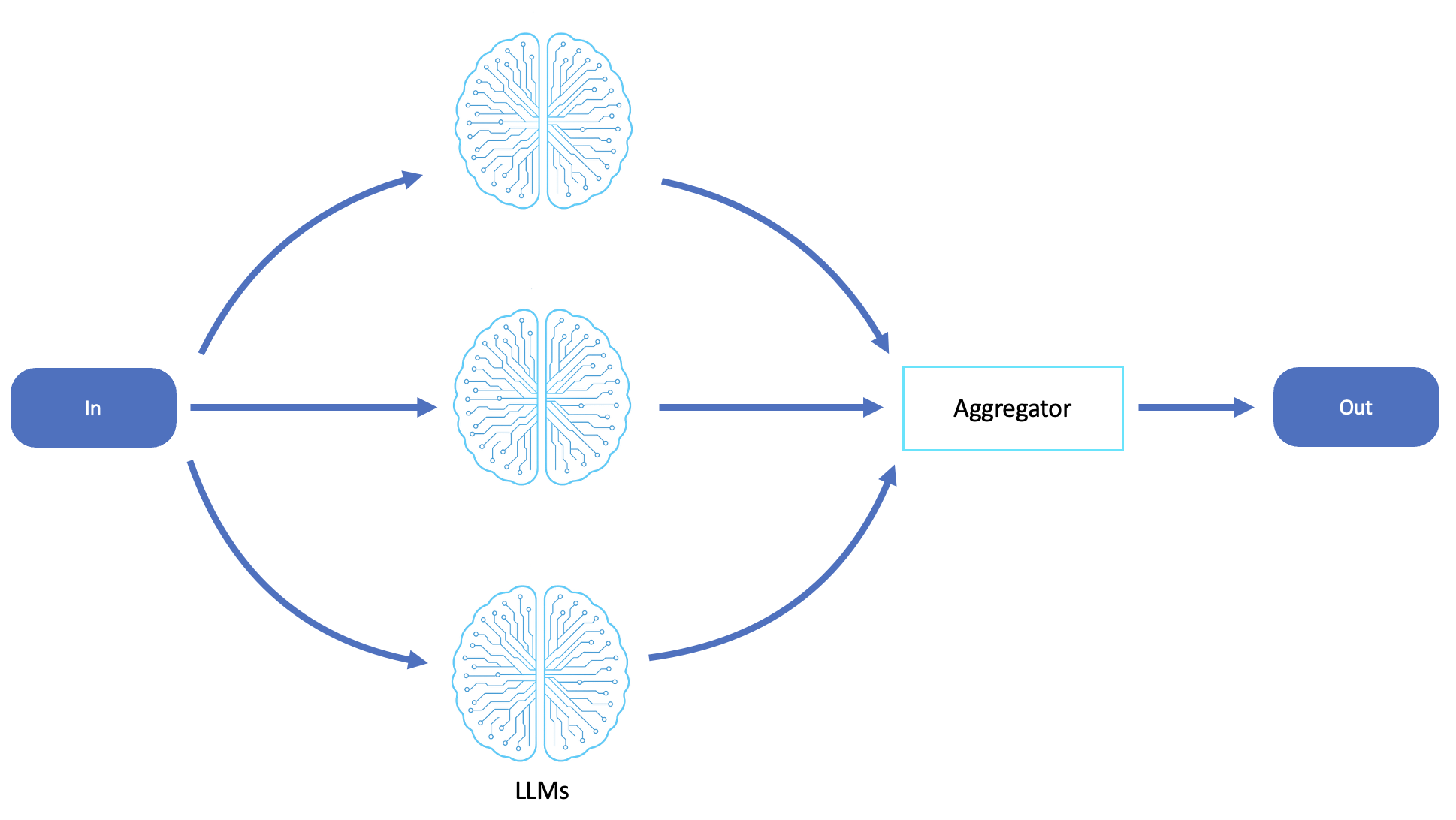
Scatter-gather
Nei sistemi distribuiti, un pattern scatter-gather invia le attività a più servizi o unità di elaborazione in parallelo, attende le loro risposte e quindi aggrega i risultati in un output consolidato. A differenza del fan-out, lo scatter-gather è coordinato perché prevede risposte e di solito applica la logica per combinare, confrontare e selezionare i risultati.
Le implementazioni comuni per la parallelizzazione e lo scatter-gather includono quanto segue:
-
AWS Step Functions mappare uno stato per l'esecuzione parallela di attività
-
AWS Lambda con concorrenza, coordinando i risultati di più funzioni richiamate
-
Amazon EventBridge con flussi di lavoro di correlazione IDs e aggregazione
-
Pattern di controller personalizzato per gestire il fan-out e raccogliere risultati utilizzando Amazon Simple Storage Service (Amazon S3), Amazon DynamoDB o code
Il diagramma seguente è un esempio di scatter-gather:
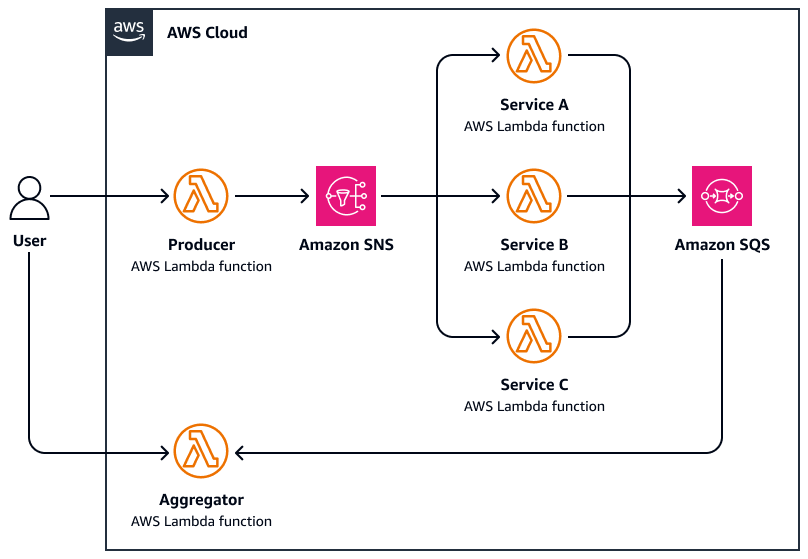
-
Un utente invia una richiesta a una funzione di coordinamento centrale che suddivide l'attività pubblicando messaggi paralleli su un argomento di Amazon Simple Notification Service (Amazon SNS).
-
Ogni messaggio include i metadati delle attività e viene indirizzato a un operatore specializzato. AWS Lambda
-
Ogni lavoratore elabora AWS Lambda in modo indipendente la sottoattività assegnata (ad esempio, interrogazione di un'API esterna, elaborazione di un documento e analisi dei dati).
-
I risultati vengono scritti su un livello di storage comune, come Amazon Simple Queue Service (Amazon SQS).
-
La funzione di aggregazione attende il completamento di tutte le risposte, quindi esegue le seguenti operazioni:
-
Raccoglie e aggrega i risultati (ad esempio, unisce i riepiloghi, seleziona le migliori corrispondenze)
-
Invia una risposta finale o attiva un flusso di lavoro a valle
-
I casi d'uso più comuni dei pattern scatter-gather includono i seguenti:
-
Ricerca federata
-
Motori di confronto dei prezzi
-
Analisi aggregata dei dati
-
Inferenza multimodello
Parallelizzazione basata su LLM (cognizione dispersa e raccolta)
Nei sistemi agentici, la parallelizzazione rispecchia da vicino lo scatter-gather distribuendo le sottoattività su più chiamate o agenti LLM, ciascuno dei quali affronta in modo indipendente una parte del problema. I risultati restituiti vengono raccolti e sintetizzati da un processo di aggregazione, che spesso è un altro LLM o un altro agente di controllo.
Parallelizzazione degli agenti
-
Un agente invia una richiesta «Riepiloga le informazioni raccolte in questi 10 report».
-
Suddivide i report in 10 attività di riepilogo LLM parallele.
-
Quando restituisce tutti i riepiloghi, l'agente esegue le seguenti operazioni:
-
Aggrega i riepiloghi in un briefing unificato
-
Identifica temi o contraddizioni
-
Invia l'output sintetizzato all'utente
-
Questo flusso di lavoro agentico consente un ragionamento parallelo scalabile, modulare e adattivo. È ideale per i casi d'uso che richiedono un throughput cognitivo elevato.
Il diagramma seguente è un esempio di parallelizzazione degli agenti:
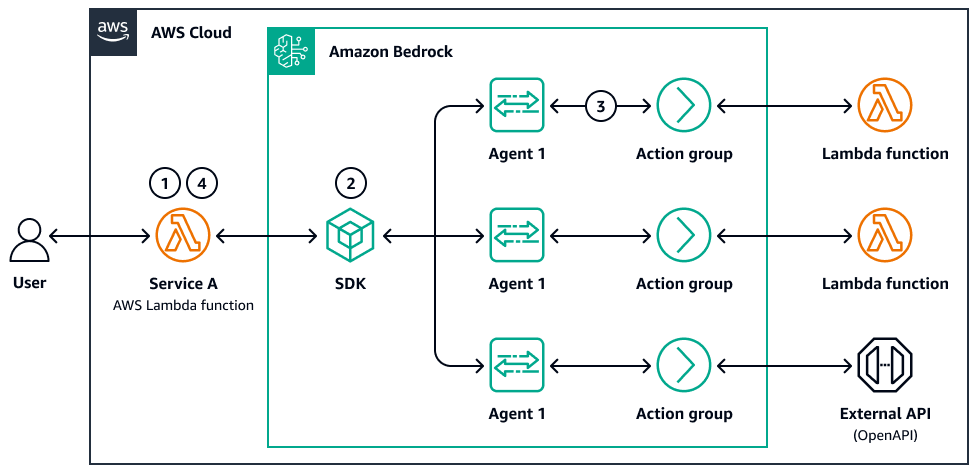
-
Un utente invia una query o un set di documenti composto da più parti.
-
Un controller AWS Lambda o una funzione Step distribuisce le sottoattività. Ogni attività richiama una chiamata o un subagente Amazon Bedrock LLM con il proprio prompt.
-
Quando le chiamate e le sottoattività sono complete, i risultati vengono archiviati (ad esempio, in Amazon S3 o nell'archivio di memoria) e una fase di aggregazione unisce, confronta o filtra gli output.
-
Il sistema restituisce la risposta finale all'utente o all'agente downstream.
Questo sistema dispone di un ciclo di ragionamento distribuito con tracciabilità, tolleranza ai guasti e logica opzionale di ponderazione o selezione dei risultati.
Take-away
La parallelizzazione agentica utilizza modelli scatter-gather per distribuire le attività LLM, abilitando l'elaborazione parallela e la sintesi intelligente dei risultati.
