Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Agenti di ragionamento di base
Un agente di ragionamento di base è la forma più semplice di intelligenza artificiale agentica che esegue l'inferenza logica o il processo decisionale in risposta a una domanda. Accetta input da un utente o da un sistema ed elabora le domande e genera risposte utilizzando prompt strutturati.
Questo modello è utile per le attività che richiedono un ragionamento, una classificazione o un riepilogo in un unico passaggio in base a un determinato contesto. Non utilizza memoria, strumenti o gestione dello stato, il che lo rende privo di stato, leggero e altamente componibile in flussi di lavoro di grandi dimensioni.
Architecture
Il flusso di un agente di ragionamento di base è mostrato nel diagramma seguente:
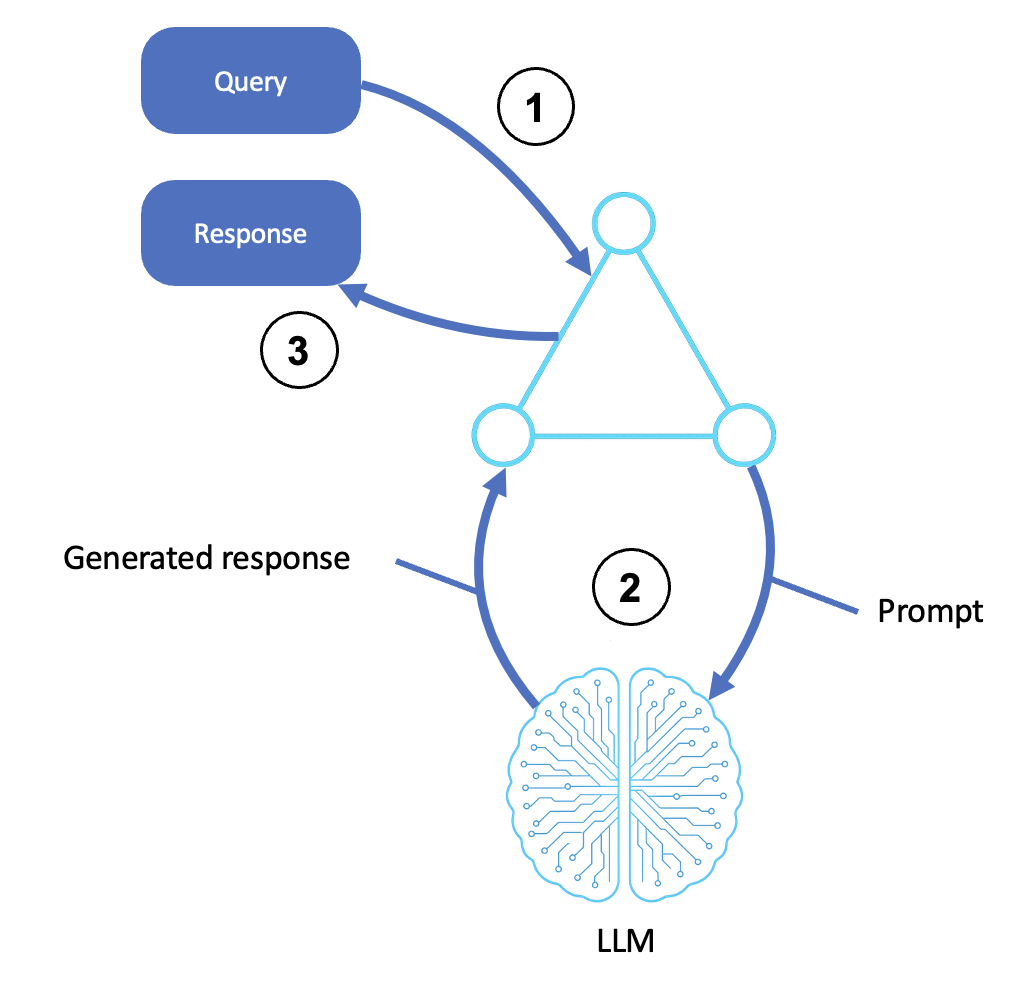
Description
-
Riceve un input
-
Un utente, un sistema o un agente upstream invia una richiesta o un'istruzione.
-
L'input viene trasferito alla shell dell'agente o al livello di orchestrazione.
-
Questo passaggio include qualsiasi preelaborazione, creazione di modelli rapidi e identificazione degli obiettivi.
-
-
Richiama l'LLM
-
L'agente trasforma la query in un prompt strutturato e la invia a un LLM (ad esempio, tramite Amazon Bedrock).
-
L'LLM genera una risposta basata sul prompt utilizzando conoscenze e contesto preformati.
-
L'output generato può includere fasi di ragionamento (catena di pensiero), risposte finali o opzioni classificate.
-
-
Restituisce una risposta
-
L'output generato viene inoltrato all'interfaccia dell'agente.
-
Ciò può includere la formattazione, la postelaborazione o una risposta API.
-
Funzionalità
-
Supporta il linguaggio naturale o l'input strutturato
-
Utilizza la progettazione tempestiva per guidare il comportamento
-
Senza stato e scalabile
-
Può essere integrato in UI, CLI, API e pipeline
Limitazioni
-
Nessuna memoria o consapevolezza storica
-
Nessuna interazione con strumenti o fonti di dati esterne
-
Limitato a ciò che il LLM conosce al momento dell'inferenza
Casi di utilizzo comune
-
Domande e risposte conversazionali
-
Spiegazioni e riassunti delle politiche
-
Linee guida per prendere decisioni
-
Flussi di chatbot leggeri e automatizzati
-
Classificazione, etichettatura e punteggio
Guida all’implementazione
È possibile utilizzare i seguenti strumenti e servizi per creare un agente di ragionamento di base:
-
Amazon Bedrock per invocazioni LLM (Anthropic, AI21, Meta)
-
Amazon API Gateway o AWS Lambda esporlo come microservizio stateless
-
Modelli di prompt archiviati in Parameter Store o come Gestione dei segreti AWS codice
Riepilogo
L'agente di ragionamento di base è fondamentale grazie alla sua struttura semplice. Ha funzionalità fondamentali che trasformano gli obiettivi in percorsi di ragionamento che portano a risultati intelligenti. Questo modello è spesso un punto di partenza per modelli avanzati, come agenti basati su strumenti e agenti che utilizzano la generazione aumentata di recupero (RAG). È anche un componente affidabile e modulare di flussi di lavoro di grandi dimensioni.
Agente RAG
Retrieval-augmented generazione (RAG) è una tecnica che combina il recupero delle informazioni con la generazione di testo per creare risposte accurate e contestuali. RAG consente agli agenti di recuperare informazioni esterne pertinenti prima di avviare il LLM. Estende la memoria effettiva e l'accuratezza del ragionamento di un agente basando le sue decisioni su informazioni aggiornate, fattuali o specifiche del dominio. A differenza dei LLM stateless che si basano esclusivamente su pesi predefiniti, RAG dispone di un livello di ricerca delle conoscenze esterno che migliora dinamicamente i prompt in base al contesto.
Architecture
La logica del pattern RAG è illustrata nel diagramma seguente:
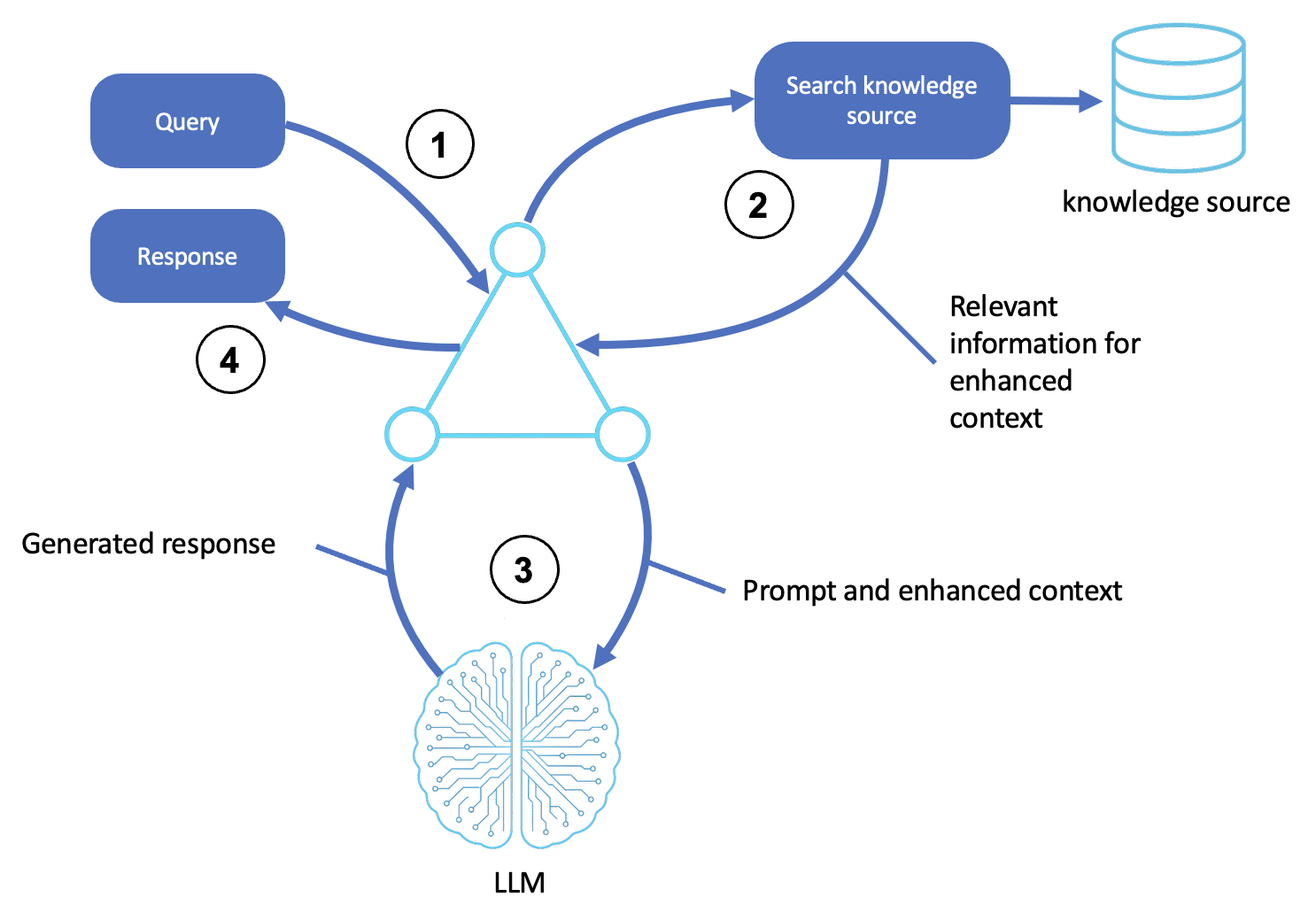
Description
-
Riceve una richiesta
-
Un utente o un sistema upstream invia una richiesta o un obiettivo all'agente.
-
La shell dell'agente accetta la richiesta e la formatta come richiesta di ragionamento.
-
-
Cerca una fonte esterna
-
L'agente identifica concetti e intenti a partire dall'interrogazione.
-
Interroga una fonte di conoscenza, ad esempio un archivio vettoriale, un database o un indice di documenti utilizzando la ricerca semantica o la corrispondenza di parole chiave.
-
I passaggi, i documenti o le entità più rilevanti vengono recuperati per essere utilizzati nella fase successiva.
-
-
Genera una risposta contestuale
-
L'agente aumenta il prompt con le informazioni recuperate, formando un input contestuale per l'LLM.
-
L'LLM elabora qualsiasi input utilizzando il ragionamento generativo (ad esempio, catena di pensiero o riflessione) per produrre una risposta accurata.
-
-
Restituisce l'output finale
-
L'agente prepara l'output inserendolo in qualsiasi intestazione di comunicazione o nella formattazione richiesta, quindi lo restituisce all'utente o al sistema chiamante.
-
(Facoltativo) I documenti recuperati e l'output LLM possono essere registrati, valutati e archiviati in memoria per future interrogazioni.
-
Funzionalità
-
Fact-grounded output anche in domini a coda lunga o specifici dell'azienda
-
Estensione della memoria senza ottimizzazione del modello
-
Contesto dinamico basato su ogni query e stato dell'utente
-
Pienamente compatibile con database vettoriali, indici semantici e filtraggio dei metadati
Casi di utilizzo comune
-
Assistenti alla conoscenza aziendale
-
Bot per la conformità normativa
-
Copiloti dell'assistenza clienti
-
Search-enhanced chatbot
-
Agenti di documentazione per sviluppatori
Guida all’implementazione
Utilizzate i seguenti strumenti e servizi per creare un agente che utilizzi RAG:
-
Amazon Bedrock per invocazioni LLM
-
Amazon Kendra OpenSearch o Amazon Aurora per la documentazione o una ricerca di dati strutturati
-
Amazon Simple Storage Service (Amazon S3) Simple Storage Service (Amazon S3) per l'archiviazione di documenti
-
AWS Lambda per orchestrare la ricerca, i prompt e l'inferenza LLM
-
Knowledge-based integrazioni con agenti (utilizzando plug-in di memoria, retriever semantici o Amazon Bedrock)
Riepilogo
Agent RAG collega il ragionamento basato su modelli statici all'intelligenza dinamica del mondo reale. Fornisce agli agenti la capacità di cercare ciò che non sanno, sintetizzare le risposte a partire dalle conoscenze acquisite e produrre risposte verificabili e altamente affidabili.
I pattern RAG sono la base per la creazione di agenti intelligenti che scalano l'accesso alla conoscenza senza riqualificazione. Spesso è un precursore di schemi di orchestrazione più complessi che coinvolgono l'uso di strumenti, la pianificazione e la memoria a lungo termine.
