Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Pianificazione del disaster recovery
Il disaster recovery (DR) è un servizio fondamentale per la continuità e la conformità aziendale. AMS collabora con te per aiutarti a pianificare, implementare e mantenere la tua strategia di DR su AMS.
AMS landing zone (LZ), multi-account e single-account, fornisce componenti nativi, Multi-AZ e ad alta disponibilità per i componenti dell'infrastruttura AMS che soddisfano la maggior parte degli scenari di protezione dai disastri. Tuttavia, a seconda della copertura geografica della tua azienda, potresti aver bisogno di una protezione regionale. Per la disponibilità interregionale e il DR, è necessario un altro account AMS in una regione diversa (questo vale sia per la landing zone con più account che per la landing zone con account singolo).
AMS si allinea alle linee guida di AWS DR descritte in questo blog, Rapidly recovery mission-critical systems in a disaster
Multisito (o ad alta disponibilità)
Standby a caldo
Luce pilota
Backup e ripristino
Queste opzioni e il relativo supporto AMS sono descritti nelle seguenti sezioni.
Multi-site o altamente disponibile (HA)
La soluzione HA è in genere fornita dalle funzionalità integrate dell'applicazione, come il clustering o la replica sincrona. Gli utenti vengono indirizzati sia a Prod che ai nodi. HA/DR Il DNS punta ai nodi direttamente o tramite un sistema di bilanciamento del carico elastico (ELB).
Il vostro architetto cloud AMS (CA) collaborerà con voi nell'ambito della vostra pianificazione Well-Architected-Review e del DR.
HA DR utilizza servizi e funzionalità applicativi e AWS nativi, come illustrato nel seguente grafico:
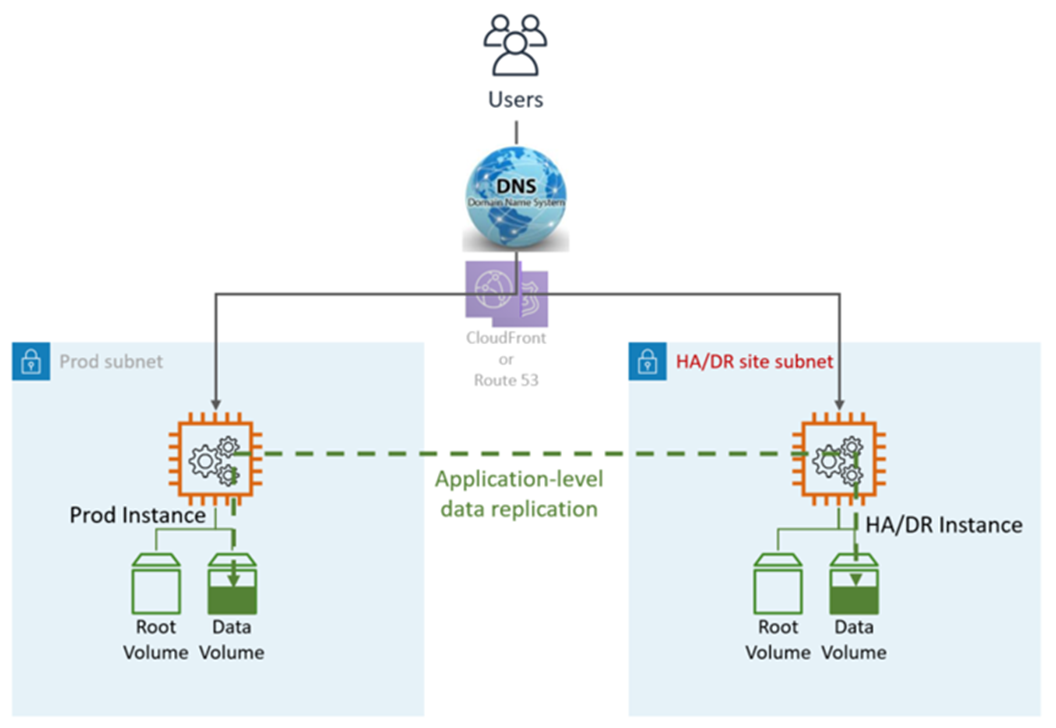
Il sito DR può trovarsi nello stesso sito o in un altro. Regione AWS
Nota
Una regione diversa (Cross-Region) avrà un ambiente Active Directory diverso.
Fasi DR (failover): failover automatico, non sono necessarie operazioni manuali. In caso di guasto nella LZ principale, gli utenti verranno automaticamente reindirizzati al nodo. DR/HA Ciò si ottiene sia tramite il DNS che con la configurazione dell'applicazione.
Metriche HA DR:
Obiettivo del punto di ripristino (RPO): <5 min
Obiettivo del tempo di ripristino e (RTO): <5 min
Manutenzione: elevata (sono necessarie modifiche sincrone in entrambi gli ambienti, ad esempio configurazione dell'applicazione, applicazione di patch, SG o ALB, certificati e così via).
Costo: alto
Warm standby
Il termine «warm standby» viene utilizzato per descrivere uno scenario di disaster recovery (DR) in cui una versione ridotta dell'ambiente è in esecuzione nel cloud.
La replica dei dati viene gestita dal livello dell'applicazione, in genere in modo asincrono, su un'istanza online, mentre le altre istanze (ad esempio, il livello Applicazione e Web) potrebbero essere disattivate per ridurre i costi. Gli utenti vengono indirizzati solo al sito di produzione. È possibile che anche altre AWS risorse, come Elastic Load Balancer (ELB), siano preinstallate nel sito DR.
Il vostro AMS Cloud Architect (CA) collaborerà con voi nell'ambito della vostra Well-Architected-Review pianificazione e del DR.
Warm Standby DR utilizza servizi e funzionalità applicativi e AWS nativi, come illustrato nel seguente grafico:
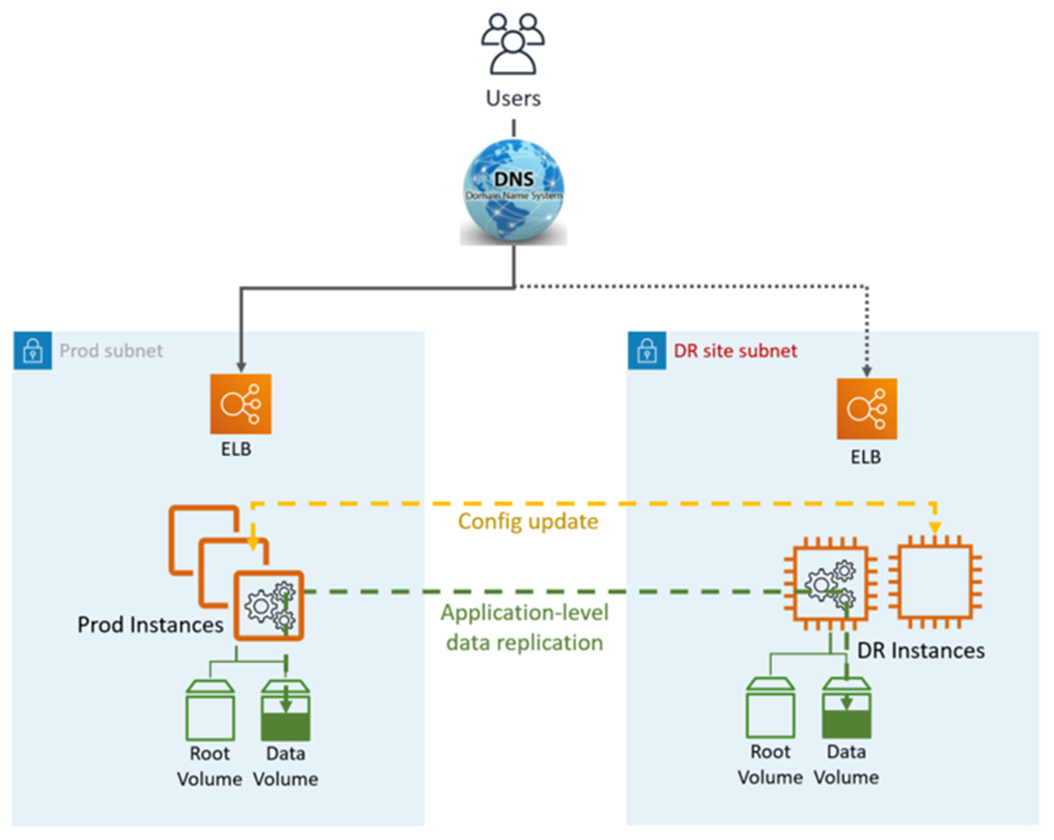
Il sito DR può essere uguale o diverso. Regione AWS
Nota
Una regione diversa (Cross-Region) avrà un ambiente Active Directory diverso.
Fasi di DR (failover):
Blocca la replica dei dati e rendi principale l'istanza di dati nel sito DR
Aggiorna la configurazione dell'applicazione come richiesto (nuovo IP, nome del server e così via)
Reindirizza il DNS al sito DR (ELB)
Dipendenze AD, se necessario (account di servizio, SPN, GPO e così via)
Metriche HA DR:
Recovery Point Objective (RPO): < 1 ora
Obiettivo e RTO (Recovery Time Objective): <1 ora (dipende dal numero di istanze e dall'orchestrazione)
Manutenzione: elevata (sono necessarie modifiche sincrone in entrambi gli ambienti, ad esempio configurazione delle applicazioni, applicazione di patch, gruppi di sicurezza (SG) o Application Load Balancer (ALB), certificati e così via).
Costo: medio
Pilot light
In questo approccio di disaster recovery (DR), replicate parte del vostro ambiente Prod per un set limitato di servizi di base. Una piccola parte dell'infrastruttura è sempre in funzione e sincronizza contemporaneamente dati mutabili (come database o documenti), mentre altre parti dell'infrastruttura vengono disattivate e utilizzate solo durante i test. A differenza di un approccio di backup e ripristino, è necessario assicurarsi che gli elementi principali più importanti siano già configurati e funzionanti nella landing zone del DR (la luce pilota).
Il vostro AMS Cloud Architect collaborerà con voi nell'ambito della vostra pianificazione Well-Architected-Review e del DR.
Pilot Light DR utilizza servizi e funzionalità applicativi e AWS nativi, come illustrato nel seguente grafico:
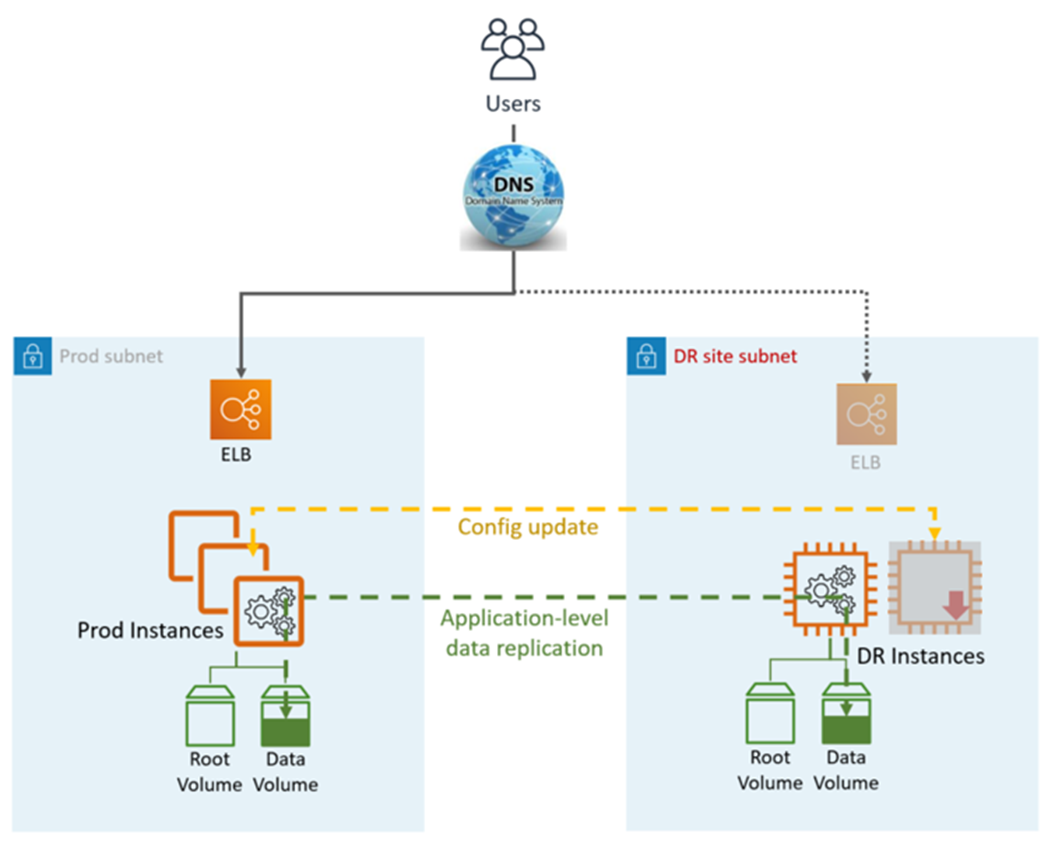
Il sito DR può essere uguale o diverso. Regione AWS
Nota
Una regione diversa (Cross-Region) avrà un ambiente Active Directory diverso.
Fasi di DR (failover):
Blocca la replica dei dati e rendi principale l'istanza di dati nel sito DR
Avvia le istanze e l'infrastruttura disattivate
Aggiorna la configurazione dell'applicazione come richiesto (nuovo IP, nome del server e così via)
Aggiungete le istanze all'ELB come richiesto
Reindirizza il DNS al sito DR (ELB)
Dipendenze AD, se necessario (account di servizio, SPN, GPO e così via)
Metriche Pilot Light DR:
Recovery Point Objective (RPO): < 1 ora
Obiettivo del tempo di ripristino e (RTO): ~1 ora (dipende dal numero di istanze e dall'orchestrazione)
Manutenzione: media
Costo: medio
Backup e ripristino
Questo approccio di disaster recovery (DR) semplice e a basso costo esegue il backup dei dati e delle applicazioni ovunque si trovino nella landing zone del DR per utilizzarli durante il ripristino da un disastro.
Il tuo AMS Cloud Architect collabora con te nell'ambito della pianificazione di Backup e DR.
Backup and Restore DR utilizza strumenti e processi automatizzati AMS, come illustrato nel seguente grafico:
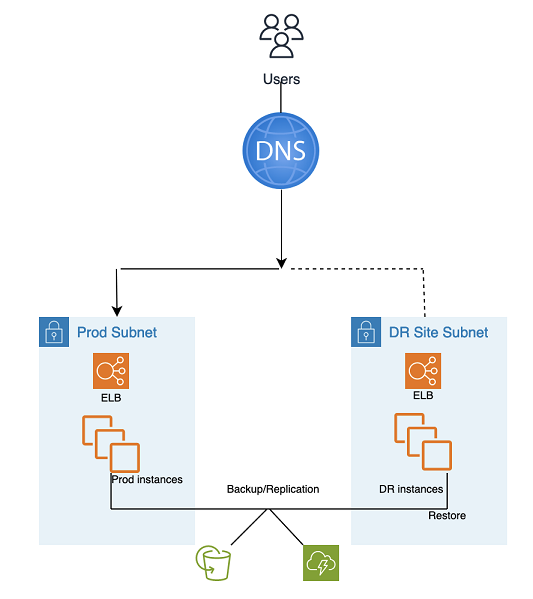
È possibile utilizzare due metodi di backup e replica:
Snapshot EBS (Recovery Point Objective (RPO) > 1 ora), nota come «EBS»
Ripristino di emergenza di elastico di AWS (Recovery Point Objective (RPO) ~ 0,25 ore), noto come «DRS»
Il sito DR può trovarsi nello stesso sito o in un altro. Regione AWS
Nota
Una regione diversa (Cross-Region) ha un ambiente Active Directory diverso.
Fasi di DR (failover):
Ripristina le istanze dalle istantanee (processo in due fasi con prima istanza placeholder)
Aggiorna la configurazione dell'applicazione (nuovo IP, nome del server e così via)
Configura altre infrastrutture come richiesto (SG, ELB e così via)
Reindirizza il DNS al sito DR (ELB)
Aggiorna o ripristina le dipendenze AD, se necessario (account di servizio, nomi principali di servizio (SPN), oggetti di policy di gruppo (GPO) e così via)
Metriche di backup e ripristino del disaster recovery:
Recovery Point Objective (RPO): >1 ora o ~0,25 ore (dipende dalla soluzione selezionata: EBS o DRE)
Recovery Time Objective e (RTO): ~1 ora (dipende dal numero di istanze e dall'orchestrazione)
Manutenzione: elevata (sono necessarie modifiche sincrone in entrambi gli ambienti, come la configurazione delle applicazioni, l'applicazione di patch, i gruppi di sicurezza o i sistemi di bilanciamento del carico delle applicazioni, i certificati e così via.
Costo: medio
Protezione dai disastri per EC2 con istantanee EBS su AMS
Prerequisiti:
AMS Prod Landing Zone (fonte)
Zona di atterraggio AMS DR (destinazione DR)
Le istantanee EBS sono abilitate per le istanze EC2 ()AWS Backup
Soluzione di replica delle istantanee:
Cross AZ: non applicabile: le istantanee EBS sono progettate per offrire un'elevata disponibilità all'interno della regione
Cross-Region: AWS Backup
Il diagramma seguente rappresenta il processo di ripristino EC2 dalle istantanee EBS su AMS:
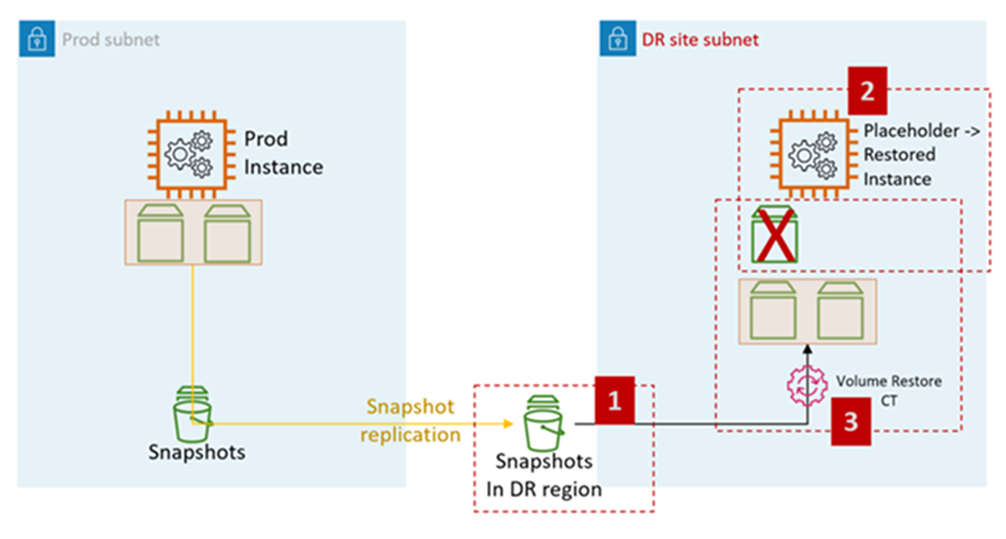
Fasi del DR EC2 su AMS:
Crea una RFC per condividere le istantanee EBS con l'account di destinazione (necessario per il DR). Cross-Region
: Gestione, Advanced Stack Components, EBS Snapshot, Share
Crea uno stack AMS EC2 segnaposto nella sottorete di destinazione (sottorete del sito DR). Si consiglia di utilizzare CFN ingestion per creare lo stack, in modo che il cliente possa combinare i passaggi di assegnazione dei gruppi di sicurezza e altri (ad esempio aggiungere l'istanza a un ELB) nello stesso stack.
Tipo di modifica: Deployment, Ingestion, Stack from Template, Create CloudFormation
Crea una RFC per eseguire il ripristino del volume dello stack EC2.
Tipo di modifica: gestione, componenti dello stack avanzato, stack di istanze EC2, volumi di ripristino.
Il CT ripristina i volumi dalle istantanee condivise nella fase 1 e si collega all'istanza placeholder creata nella fase 2.
Funzionalità Volume Restore CT:
Chiudi l'istanza placeholder
Ripristina i volumi dalle istantanee
Sostituisci i volumi
Avvia l'istanza
Abbandona il vecchio dominio
Modifica del nome host
Riavviare. Gli script di bootstrap AMS aggiungono l'istanza al dominio di destinazione (DR) all'avvio
Ingresso CT per il ripristino del volume:
InstanceId (ID dell'istanza segnaposto)
RootDeviceSnapshotId, lo snapshot EBS per il volume root ripristinato
KMSKeyId, l'identificatore di chiave KMS, o ARN, per crittografare tutti i volumi ripristinati sull'istanza EC2
DeviceNames, fino a 25 (opzionale)
SnapshotIds, fino a 25 (opzionale). Elenco di istantanee dei volumi da ripristinare
Protezione in caso di emergenza per EC2 con Elastic Disaster Recovery su AMS
Prerequisiti:
AMS Prod Landing Zone (fonte)
Zona di atterraggio AMS DR (destinazione DR)
Devi prima inizializzare il servizio Elastic Disaster Recovery per tutto Regioni AWS ciò in cui intendi utilizzarlo.
Crea un ruolo IAM nella tua landing zone (LZ) DR per l'accesso alla console Elastic Disaster Recovery.
Importante: un documento SSM viene creato come azione post-lancio all'interno di DRS. Questa azione deve essere abilitata su tutti i server nelle PostLaunch impostazioni.
l'istanza di destinazione (placeholder) deve avere una chiave tag: «AWSDRS», value: "». AllowLaunchingIntoThisInstance L'istanza placeholder deve essere nello stato interrotto. Altrimenti, AMS non può selezionare l'istanza placeholder nelle impostazioni di avvio e Elastic Disaster Recovery non può eseguire il ripristino sull'istanza placeholder.
Fasi del DR di EC2 con Elastic Disaster Recovery on AMS:
Crea uno stack EC2 AMS segnaposto nella sottorete di destinazione (sottorete del sito DR) con i tag appropriati. Per maggiori informazioni, consulta la sezione precedente. Ti consigliamo di utilizzare CFN ingestion per creare lo stack in quanto puoi combinare i passaggi di assegnazione dei gruppi di sicurezza e etichettare l'istanza, il volume EBS e altro (ad esempio aggiungere l'istanza a un ELB) nello stesso stack.
Tipo di modifica: Deployment, Ingestion, Stack from Template, Create CloudFormation
Arresta l'istanza placeholder.
Tipo di modifica: gestione, componenti dello stack avanzati, istanza EC2, Stop
Se non l'hai fatto nel passaggio 1, contrassegna l'istanza placeholder e il relativo volume EBS con la chiave: «AWSDRS», valore: "». AllowLaunchingIntoThisInstance
Tipo di modifica: gestione, componenti dello stack avanzati, tag, aggiornamento.
Utilizza l'istanza placeholder del passaggio 1 come destinazione in Launch into instance ID, DRS Launch Settings per il server di origine. Avvia l'esercitazione di ripristino dell'istanza dalla console Elastic Disaster Recovery per il server di origine.
Nota
I volumi delle istanze segnaposto vengono conservati nell'account. Per eliminare questi volumi, invia un Management | Advanced stack components | EBS Volume | Delete change type (ct-3e3h8u0sp5z80) al termine dell'operazione di disaster recovery.
Flusso di lavoro di ripristino Elastic Disaster Recovery:
L'istanza di destinazione (segnaposto) deve trovarsi nello stato interrotto
Scambia i volumi ed elimina il volume radice di origine (segnaposto)
Avviate l'istanza
Esegui le azioni successive al lancio per completare i seguenti elementi:
Attiva l'agente SSM.
Scambia i volumi ed elimina il volume radice di origine (segnaposto).
Avviate l'istanza
Esegui il documento PostLaunchScript SSM. Questo documento fa quanto segue:
Lascia il vecchio dominio.
Cambia il nome host.
Riavviare. Gli script di bootstrap AMS uniscono l'istanza al dominio di destinazione (DR) durante l'avvio.
