Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Riferimento a Data Quality Definition Language (DQDL)
Il Data Quality Definition Language (DQDL) è un linguaggio specifico del dominio utilizzato per definire le regole per AWS Glue Data Quality.
Questa guida introduce i concetti chiave di DQDL per aiutarti a comprendere il linguaggio. Fornisce inoltre un riferimento per i tipi di regole DQDL con sintassi ed esempi. Prima di utilizzare questa guida, ti consigliamo di avere dimestichezza con AWS Glue Data Quality. Per ulteriori informazioni, consulta AWS Glue Qualità dei dati.
Nota
DynamicRules sono supportati solo in AWS Glue ETL.
Sintassi di DQDL
Un documento DQDL fa distinzione tra maiuscole e minuscole e contiene un set di regole che raggruppa le singole regole di qualità dei dati. Per costruire un set di regole, è necessario creare un elenco denominato Rules (in maiuscolo), delimitato da una coppia di parentesi quadre. L'elenco deve contenere una o più regole DQDL separate da virgole come nell'esempio seguente.
Rules = [ IsComplete "order-id", IsUnique "order-id" ]
Struttura delle regole
La struttura di una regola DQDL dipende dal tipo di regola. Tuttavia, le regole DQDL generalmente si adattano al seguente formato.
<RuleType> <Parameter> <Parameter> <Expression>
RuleType è il nome (sensibile al maiuscolo/minuscolo) del tipo di regola che si desidera configurare. Ad esempio, IsComplete, IsUnique o CustomSql. I parametri delle regole sono diversi per ogni tipo di regola. Per un riferimento completo ai tipi di regole DQDL e ai relativi parametri, consulta Documentazione di riferimento del tipo di regola DQDL.
Regole composite
DQDL supporta i seguenti operatori logici che possono essere utilizzati per combinare le regole. Queste regole vengono chiamate Regole composite.
- and
-
L'operatore logico
andrestituiscetruese e solo se le regole che connette sonotrue. Altrimenti, la regola combinata darà come risultatofalse. Ogni regola connessa all'operatoreanddeve essere racchiusa tra parentesi.L'esempio seguente utilizza l'operatore
andper combinare due regole DQDL.(IsComplete "id") and (IsUnique "id") - or
-
L'operatore logico
orrestituiscetruese e solo se una o più regole che connette sonotrue. Ogni regola connessa all'operatoreordeve essere racchiusa tra parentesi.L'esempio seguente utilizza l'operatore
orper combinare due regole DQDL.(RowCount "id" > 100) or (IsPrimaryKey "id")
È possibile utilizzare lo stesso operatore per connettere più regole, quindi la seguente combinazione di regole è consentita.
(Mean "Star_Rating" > 3) and (Mean "Order_Total" > 500) and (IsComplete "Order_Id")
È possibile combinare gli operatori logici in un'unica espressione. Esempio:
(Mean "Star_Rating" > 3) and ((Mean "Order_Total" > 500) or (IsComplete "Order_Id"))
È anche possibile creare regole più complesse e annidate.
(RowCount > 0) or ((IsComplete "colA") and (IsUnique "colA"))
Come funzionano le regole composite
Per impostazione predefinita, le regole composite vengono valutate come regole individuali sull'intero set di dati o tabella e i risultati vengono poi combinati. In altri termini, prima valuta l'intera colonna e poi applica l'operatore. Questo comportamento predefinito viene spiegato di seguito con un esempio:
# Dataset +------+------+ |myCol1|myCol2| +------+------+ | 2| 1| | 0| 3| +------+------+ # Overall outcome +----------------------------------------------------------+-------+ |Rule |Outcome| +----------------------------------------------------------+-------+ |(ColumnValues "myCol1" > 1) OR (ColumnValues "myCol2" > 2)|Failed | +----------------------------------------------------------+-------+
Nell'esempio precedente, AWS Glue Data Quality valuta innanzitutto (ColumnValues "myCol1" > 1), che darà esito negativo. Quindi valuterà (ColumnValues "myCol2" > 2), che darà anch'esso esito negativo. La combinazione di entrambi i risultati verrà contrassegnata come FAILED.
Tuttavia, se si preferisce un comportamento simile a SQL, in cui è necessario valutare l'intera riga, è necessario impostare esplicitamente il parametro ruleEvaluation.scope come mostrato in additionalOptions nel frammento di codice riportato di seguito.
object GlueApp { val datasource = glueContext.getCatalogSource( database="<db>", tableName="<table>", transformationContext="datasource" ).getDynamicFrame() val ruleset = """ Rules = [ (ColumnValues "age" >= 26) OR (ColumnLength "name" >= 4) ] """ val dq_results = EvaluateDataQuality.processRows( frame=datasource, ruleset=ruleset, additionalOptions=JsonOptions(""" { "compositeRuleEvaluation.method":"ROW" } """ ) ) }
In AWS Glue Data Catalog, è possibile configurare facilmente questa opzione nell'interfaccia utente come illustrato di seguito.
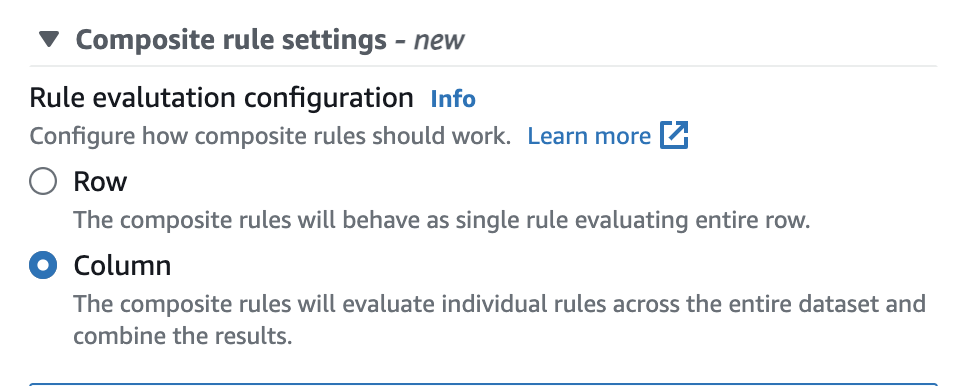
Una volta impostate, le regole composite si comporteranno come una singola regola che valuta l'intera riga. Nell'esempio seguente viene descritto questo comportamento.
# Row Level outcome +------+------+------------------------------------------------------------+---------------------------+ |myCol1|myCol2|DataQualityRulesPass |DataQualityEvaluationResult| +------+------+------------------------------------------------------------+---------------------------+ |2 |1 |[(ColumnValues "myCol1" > 1) OR (ColumnValues "myCol2" > 2)]|Passed | |0 |3 |[(ColumnValues "myCol1" > 1) OR (ColumnValues "myCol2" > 2)]|Passed | +------+------+------------------------------------------------------------+---------------------------+
Alcune regole non possono essere supportate in questa funzionalità perché il loro risultato complessivo dipende da soglie o coefficienti. Le soglie e i coefficienti sono elencati di seguito.
Regole che dipendono da coefficienti:
-
Completezza
-
DatasetMatch
-
ReferentialIntegrity
-
Univocità
Regole che dipendono da soglie:
Quando le seguenti regole includono una soglia, non sono supportate. Tuttavia, le regole che non prevedono with threshold continuano a essere supportate.
-
ColumnDataType
-
ColumnValues
-
CustomSQL
Espressioni
Se un tipo di regola non produce una risposta booleana, è necessario fornire un'espressione come parametro per creare una risposta booleana. Ad esempio, la regola seguente controlla la media di tutti i valori di una colonna rispetto a un'espressione per restituire un risultato vero o falso.
Mean "colA" between 80 and 100
Alcuni tipi di regole, ad esempio IsUnique e IsComplete, restituiscono già una risposta booleana.
Nella tabella seguente sono riportate le espressioni che è possibile utilizzare nelle regole DQDL.
| Expression | Description | Esempio |
|---|---|---|
=x |
Risolve true se la risposta del tipo di regola è uguale a. x |
|
!=x
|
x Risolve a true se la risposta del tipo di regola non è uguale a. x |
|
> x |
Risolve true se la risposta del tipo di regola è maggiore di. x |
|
< x |
Risolve true se la risposta del tipo di regola è inferiore a. x |
|
>= x |
Risolve true se la risposta del tipo di regola è maggiore o uguale a. x |
|
<= x |
Risolve true se la risposta del tipo di regola è minore o uguale a. x |
|
tra e x y |
Si risolve in true se la risposta del tipo di regola rientra in un intervallo specificato (esclusivo). Utilizza questo tipo di espressione solo per i tipi numerici e data. |
|
non tra x e y |
Si risolve in true se il tipo di risposta del tipo di regola non rientra in un intervallo specificato (inclusivo). È necessario utilizzare questo tipo di espressione solo per i tipi numerici e data. |
|
in [a, b, c, ...] |
Si risolve in true se la risposta del tipo di regola è nel set specificato. |
|
non in [a, b, c, ...] |
Si risolve in true se la risposta del tipo di regola non è nel set specificato. |
|
fiammiferi /ab+c/i |
Si risolve in true se la risposta del tipo di regola corrisponde a un'espressione regolare. |
|
non corrisponde /ab+c/i |
Si risolve in true se la risposta del tipo di regola non corrisponde a un'espressione regolare. |
|
now() |
Funziona solo con il tipo di regola ColumnValues per creare un'espressione di data. |
|
matches/in […]/not matches/notin [...] with threshold |
Specifica la percentuale di valori che corrispondono alle condizioni della regola. Funziona solo con i tipi di regola ColumnValues, ColumnDataType e CustomSQL. |
|
Parole chiave per NULL, EMPTY e WHITESPACES_ONLY
Se vuoi verificare se una colonna di stringhe contiene un valore null, vuoto o una stringa con solo spazi bianchi, puoi utilizzare le seguenti parole chiave:
-
NULL / null: questa parola chiave restituisce il valore true per un valore
nullin una colonna di stringhe.ColumnValues "colA" != NULL with threshold > 0.5restituisce il valore true se oltre il 50% dei dati non contiene valori null.(ColumnValues "colA" = NULL) or (ColumnLength "colA" > 5)restituisce il valore true per tutte le righe che hanno un valore null o una lunghezza >5. Nota che ciò richiederà l'uso dell'opzione «compositeRuleEvaluation.method» = «ROW». -
EMPTY / empty: questa parola chiave restituisce il valore true per un valore di stringa vuoto ("") in una colonna di stringhe. Alcuni formati di dati trasformano i valori null di una colonna di stringhe in stringhe vuote. Questa parola chiave consente di filtrare le stringhe vuote presenti nei dati.
(ColumnValues "colA" = EMPTY) or (ColumnValues "colA" in ["a", "b"])restituisce il valore true se una riga è vuota, "a" o "b". Nota che ciò richiede l'uso dell'opzione «compositeRuleEvaluation.method» = «ROW». -
WHITESPACES_ONLY / whitespaces_only: questa parola chiave restituisce il valore true per una stringa contenente solo spazi bianchi (" ") in una colonna di stringhe.
ColumnValues "colA" not in ["a", "b", WHITESPACES_ONLY]restituisce il valore true se una riga non è né "a" né "b" né solo spazi bianchi.Regole supportate:
Per un'espressione numerica o basata sulla data, se si desidera verificare se una colonna contiene un valore null, è possibile utilizzare le seguenti parole chiave.
-
NULL / null: questa parola chiave restituisce il valore true per un valore null in una colonna di stringhe.
ColumnValues "colA" in [NULL, "2023-01-01"]restituisce il valore true se una delle date nella colonna è2023-01-01o null.(ColumnValues "colA" = NULL) or (ColumnValues "colA" between 1 and 9)restituisce il valore true per tutte le righe che hanno un valore null o valori compresi tra 1 e 9. Nota che ciò richiederà l'uso dell'opzione «compositeRuleEvaluation.method» = «ROW».Regole supportate:
Filtraggio con la clausola Where
Nota
Where Clause è supportato solo in AWS Glue 4.0.
È possibile filtrare i dati durante la creazione delle regole. È utile quando si vuole applicare regole condizionali.
<DQDL Rule> where "<valid SparkSQL where clause> "
Il filtro deve essere specificato con la parola chiave where seguita da un'istruzione SparkSQL valida racchiusa tra virgolette ("").
Se si desidera aggiungere la clausola where a una regola con una soglia, la clausola where deve essere specificata prima della condizione di soglia.
<DQDL Rule> where "valid SparkSQL statement>" with threshold <threshold condition>
Con questa sintassi è possibile scrivere regole come quelle riportate di seguito.
Completeness "colA" > 0.5 where "colB = 10" ColumnValues "colB" in ["A", "B"] where "colC is not null" with threshold > 0.9 ColumnLength "colC" > 10 where "colD != Concat(colE, colF)"
Valuteremo se l'istruzione SparkSQL fornita è valida. Se non è valida, la valutazione della regola avrà esito negativo e verrà generato un IllegalArgumentException con il seguente formato:
Rule <DQDL Rule> where "<invalid SparkSQL>" has provided an invalid where clause : <SparkSQL Error>
Comportamento della clausola Where quando è attivata l'identificazione dei record di errore a livello di riga
Con AWS Glue Data Quality, puoi identificare record specifici che hanno avuto esito negativo. Quando si applica una clausola where alle regole che supportano risultati a livello di riga, le righe filtrate dalla clausola where vengono contrassegnate come Passed.
Se si preferisce contrassegnare separatamente le righe filtrate come SKIPPED, è possibile impostare le seguenti additionalOptions per il processo ETL.
object GlueApp { val datasource = glueContext.getCatalogSource( database="<db>", tableName="<table>", transformationContext="datasource" ).getDynamicFrame() val ruleset = """ Rules = [ IsComplete "att2" where "att1 = 'a'" ] """ val dq_results = EvaluateDataQuality.processRows( frame=datasource, ruleset=ruleset, additionalOptions=JsonOptions(""" { "rowLevelConfiguration.filteredRowLabel":"SKIPPED" } """ ) ) }
A titolo esemplificativo, fare riferimento alla regola e al dataframe riportati di seguito:
IsComplete att2 where "att1 = 'a'"
| id | att1 | att2 | Risultati a livello di riga (impostazione predefinita) | Risultati a livello di riga (opzione ignorata) | Commenti |
|---|---|---|---|---|---|
| 1 | a | f | PASSED | PASSED | |
| 2 | b | d | PASSED | SKIPPED | La riga viene esclusa in quanto att1 non è "a" |
| 3 | a | null | NON RIUSCITO | NON RIUSCITO | |
| 4 | a | f | PASSED | PASSED | |
| 5 | b | null | PASSED | SKIPPED | La riga viene esclusa in quanto att1 non è "a" |
| 6 | a | f | PASSED | PASSED |
Costanti
In DQDL, è possibile definire valori costanti e farvi riferimento in tutto lo script. Questo aiuta a prevenire problemi relativi ai limiti di dimensione delle query, ad esempio quando si lavora con istruzioni SQL di grandi dimensioni che potrebbero superare i limiti consentiti. Assegnando questi valori a Constants, è possibile semplificare il DQDL ed evitare di raggiungere tali limiti.
L'esempio seguente mostra come definire e utilizzare una costante:
mySql = "select count(*) from primary" Rules = [ CustomSql $mySql between 0 and 100 ]
In questo esempio, la query SQL viene assegnata alla costantemySql, a cui viene quindi fatto riferimento nella regola utilizzando il $ prefisso.
Etichette
Le etichette offrono un modo efficace per organizzare e analizzare i risultati di qualità dei dati. È possibile interrogare i risultati in base a etichette specifiche per identificare le regole non corrette all'interno di determinate categorie, contare i risultati delle regole per team o dominio e creare report mirati per le diverse parti interessate.
Ad esempio, puoi applicare tutte le regole relative al team finanziario con un'etichetta "team=finance" e generare un report personalizzato per mostrare le metriche di qualità specifiche del team finanziario. È possibile etichettare le regole ad alta priorità con cui dare priorità alle azioni "criticality=high" correttive. Le etichette possono essere create come parte del DQDL. È possibile interrogare le etichette come parte dei risultati delle regole, dei risultati a livello di riga e delle risposte delle API, semplificando l'integrazione con i flussi di lavoro di monitoraggio e reporting esistenti.
Nota
Le etichette sono disponibili solo in AWS Glue ETL e non sono disponibili in Data Quality basato su AWS Glue Data Catalog.
Sintassi per le etichette DQDL
DQDL supporta etichette predefinite e specifiche per regole. Le etichette predefinite sono definite a livello di set di regole e si applicano automaticamente a tutte le regole all'interno di quel set di regole. Le singole regole possono anche avere le proprie etichette e, poiché le etichette sono implementate come coppie chiave-valore, le etichette specifiche delle regole possono sovrascrivere le etichette predefinite quando si utilizza la stessa chiave.
L'esempio seguente mostra come utilizzare etichette predefinite e specifiche per regole:
DefaultLabels=["frequency"="monthly"] Rules = [ // Auto includes the default label ["frequency"="monthly"] ColumnValues "col" > 21, // Add ["foo"="bar"] to default label. Labels for this rule would be ["frequency"="monthly", "foo"="bar"] RowCount > 0 with threshold > 0.8 labels=["foo"="bar"], // Override default label. Labels for this rule would be ["frequency"="daily", "foo"="bar"] ColumnValues "colA" in ["A", "B"] with threshold > 0.8 labels=["foo"="bar", "frequency"="daily"] // Labels must be applied to the entire composite rule (parentheses required) (isComplete "col" AND RowCount > 0) labels=["foo"="bar] ]
L'esempio seguente mostra una sintassi non valida con etichette e regole composite:
(isComplete "colA") AND (RowCount > 0) labels=["foo"="bar"] (isComplete "colA" labels=["foo"="bar"]) AND (RowCount > 0) isComplete "col" AND RowCount > 0 labels=["foo"="bar]
Vincoli relativi alle etichette
Le etichette presentano i seguenti vincoli:
-
Un massimo di 10 etichette per regola DQDL.
-
Le etichette sono specificate come un elenco di coppie chiave-valore.
-
La chiave dell'etichetta e il valore dell'etichetta fanno distinzione tra maiuscole e minuscole.
-
La lunghezza massima della chiave dell'etichetta è di 128 caratteri. La chiave dell'etichetta non deve essere vuota o nulla.
-
La lunghezza massima del valore dell'etichetta è 256 caratteri. Il valore dell'etichetta può essere vuoto o nullo.
Recupero delle etichette DQDL
È possibile recuperare le etichette DQDL dai risultati delle regole, dai risultati a livello di riga e dalle risposte delle API.
Risultati delle regole
Le etichette DQDL sono sempre visibili nei risultati delle regole. Non è necessaria alcuna configurazione aggiuntiva per abilitarle.
Risultati a livello di riga
Le etichette DQDL sono disabilitate per impostazione predefinita nei risultati a livello di riga, ma possono essere abilitate utilizzando in. AdditionalOptions EvaluateDataQuality
L'esempio seguente mostra come abilitare le etichette nei risultati a livello di riga:
val evaluateResult = EvaluateDataQuality.processRows( frame=AmazonS3_node1754591511068, ruleset=example_ruleset, publishingOptions=JsonOptions("""{ "dataQualityEvaluationContext": "evaluateResult", "enableDataQualityCloudWatchMetrics": "true", "enableDataQualityResultsPublishing": "true" }"""), additionalOptions=JsonOptions("""{ "performanceTuning.caching":"CACHE_NOTHING", "observations.scope":"ALL", "rowLevelConfiguration.ruleWithLabels":"ENABLED" }""") )
Se abilitato, il dataframe dei risultati a livello di riga include le etichette per ogni regola nelle colonne, e. DataQualityRulesPass DataQualityRulesFail DataQualityRulesSkip
Risposta API
Le etichette DQDL sono sempre visibili nelle risposte API in un nuovo campo Labels dell'RuleResultsoggetto.
L'esempio seguente mostra le etichette in una risposta API:
{ "ResultId": "dqresult-example", "ProfileId": "dqprofile-example", "Score": 0.6666666666666666, "RulesetName": "EvaluateDataQuality_node1754591514205", "EvaluationContext": "EvaluateDataQuality_node1754591514205", "StartedOn": "2025-08-22T19:36:10.448000+00:00", "CompletedOn": "2025-08-22T19:36:16.368000+00:00", "JobName": "anniezc-test-labels", "JobRunId": "jr_068f6d7a45074d9105d14e4dee09db12c3b95664b45f6ee44fa29ed7e5619ba8", "RuleResults": [ { "Name": "Rule_0", "Description": "IsComplete colA", "EvaluationMessage": "Input data does not include column colA!", "Result": "FAIL", "EvaluatedMetrics": {}, "EvaluatedRule": "IsComplete colA", "Labels": { "frequency": "monthly" } }, { "Name": "Rule_1", "Description": "Rule 1 with threshold > 0.8", "Result": "PASS", "EvaluatedMetrics": {}, "EvaluatedRule": "Rule 1 with threshold > 0.8", "Labels": { "frequency": "monthly", "foo": "bar" } }, { "Name": "Rule_3", "Description": "Rule 2 with threshold > 0.8", "Result": "PASS", "EvaluatedMetrics": {}, "EvaluatedRule": "Rule 2 with threshold > 0.8", "Labels": { "frequency": "daily", "foo": "bar" } } ] }
Regole dinamiche
Nota
Le regole dinamiche sono supportate solo in AWS Glue ETL e non sono supportate in AWS Glue Data Catalog.
Ora puoi creare regole dinamiche per confrontare le metriche correnti prodotte dalle tue regole con i relativi valori storici. Questi confronti storici sono abilitati utilizzando l'operatore last() nelle espressioni. Ad esempio, la regola RowCount >
last() avrà esito positivo se il numero di righe nell'esecuzione corrente è maggiore del conteggio precedente più recente delle righe per lo stesso set di dati. last() utilizza un argomento facoltativo relativo ai numeri naturali che descrive il numero di metriche precedenti da prendere in considerazione; last(k) dove k
>= 1 farà riferimento alle ultime k metriche.
-
Se non sono disponibili punti dati,
last(k)restituirà il valore predefinito 0,0. -
Se sono disponibili meno di
kmetriche,last(k)restituirà tutte quelle precedenti.
Utilizza last(k) per formare espressioni valide, dove k > 1 richiede una funzione di aggregazione per ridurre più risultati storici a un unico numero. Ad esempio, RowCount > avg(last(5)) controllerà se il conteggio delle righe del set di dati corrente è strettamente maggiore della media dei conteggi delle ultime cinque righe per lo stesso set di dati. RowCount > last(5) produrrà un errore perché il conteggio delle righe del set di dati corrente non può essere confrontato in modo significativo con un elenco.
Funzioni di aggregazione supportate:
-
avg -
median -
max -
min -
sum -
std(deviazione standard) -
abs(valore assoluto) -
index(last(k), i)consentirà di selezionare ili° valore più recente tra gli ultimik.iè indicizzato a zero, quindiindex(last(3), 0)restituirà il punto dati più recente eindex(last(3), 3)genererà un errore poiché ci sono solo tre punti dati, mentre noi cerchiamo di indicizzare il 4° punto dati più recente.
Espressioni di esempio
ColumnCorrelation
ColumnCorrelation "colA" "colB" < avg(last(10))
DistinctValuesCount
DistinctValuesCount "colA" between min(last(10))-1 and max(last(10))+1
La maggior parte dei tipi di regole con condizioni o soglie numeriche supporta regole dinamiche; consulta la tabella fornita, Analizzatori e regole, per determinare se le regole dinamiche sono supportate per il tuo tipo di regola.
Escludere le statistiche dalle regole dinamiche
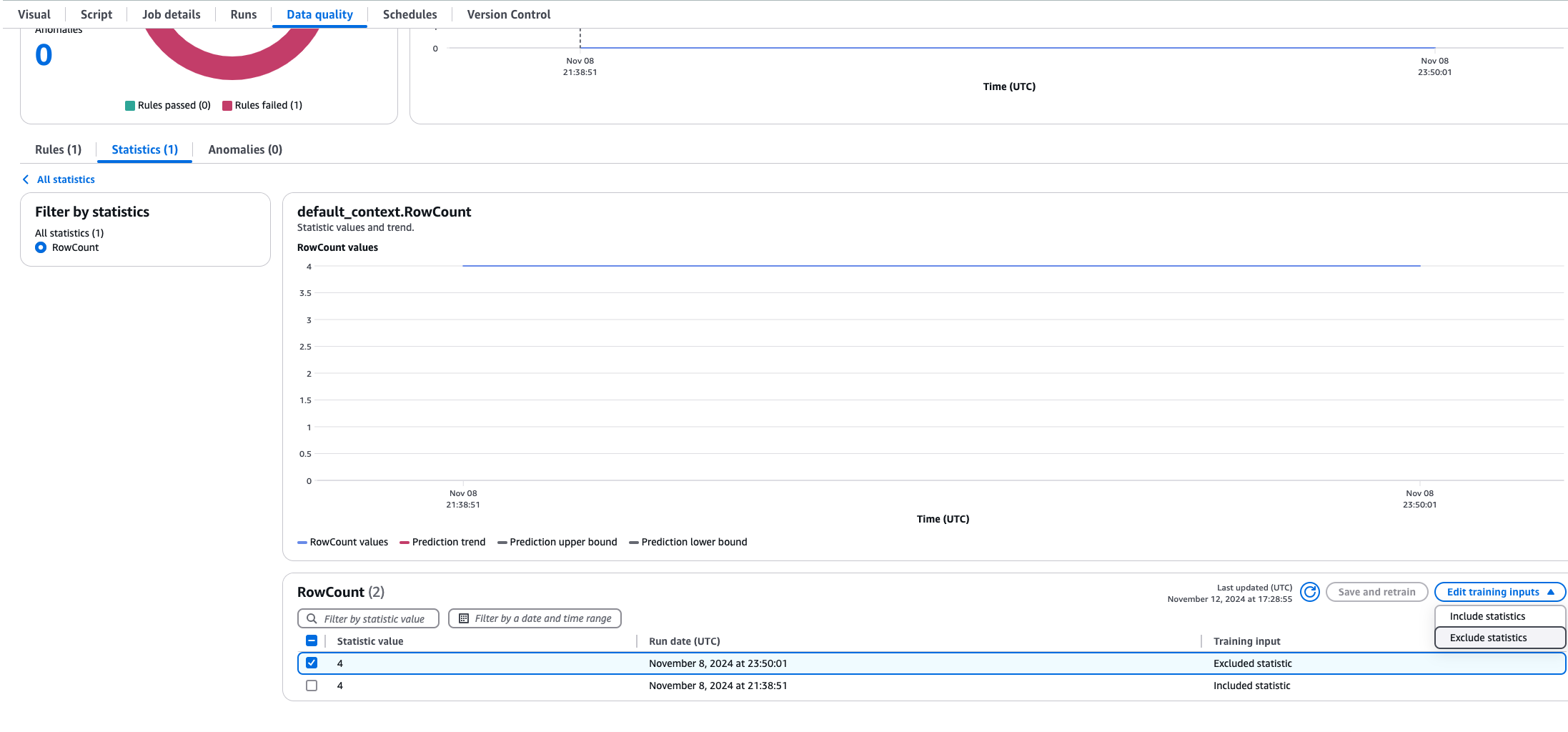
A volte è necessario escludere le statistiche sui dati dai calcoli delle regole dinamiche. Supponiamo che tu abbia caricato dei dati storici e non desideri che ciò influisca sulle tue medie. Per fare ciò, apri il lavoro in AWS Glue ETL e scegli la scheda Data Quality, quindi scegli Statistiche e seleziona le statistiche che desideri escludere. Potrai visualizzare un grafico delle tendenze insieme a una tabella delle statistiche. Scegli i valori che desideri escludere e seleziona Escludi statistiche. Ora le statistiche escluse non saranno incluse nei calcoli delle regole dinamiche.
Analizzatori
Nota
Gli analizzatori non sono supportati in AWS Glue Data Catalog.
Le regole DQDL utilizzano funzioni chiamate analizzatori per raccogliere informazioni sui dati. Queste informazioni vengono utilizzate dall'espressione booleana di una regola per determinare se quest'ultima deve avere esito positivo o negativo. Ad esempio, la RowCount regola RowCount > 5 utilizzerà un analizzatore del conteggio delle righe per scoprire il numero di righe nel set di dati e confronterà tale conteggio con l'espressione > 5 per verificare se nel set di dati corrente esistono più di cinque righe.
A volte, invece di creare regole, consigliamo di creare analizzatori e fare in modo che generino statistiche da utilizzare per rilevare anomalie. In questi casi, puoi creare analizzatori. Gli analizzatori differiscono dalle regole nei modi indicati di seguito.
| Caratteristica | Analizzatori | Regole |
|---|---|---|
| Parte del set di regole | Sì | Sì |
| Genera statistiche | Sì | Sì |
| Genera osservazioni | Sì | Sì |
| Può valutare e verificare una condizione | No | Sì |
| È possibile configurare operazioni come l'interruzione dei processi in caso di errore o la prosecuzione di un processo di elaborazione | No | Sì |
Gli analizzatori possono esistere indipendentemente senza regole, quindi puoi configurarli in modo rapido e creare regole di qualità dei dati in modo progressivo.
Alcuni tipi di regole possono essere inseriti nel blocco Analyzers del set di regole per eseguire quelle richieste per gli analizzatori e raccogliere informazioni senza applicare controlli per alcuna condizione. Esistono analizzatori che non sono associati ad alcuna regola e che possono essere inseriti solo nel blocco Analyzers. La tabella seguente indica se ogni elemento è supportato come regola o come analizzatore autonomo, insieme a dettagli aggiuntivi per ogni tipo di regola.
Esempio di set di regole con Analyzer
Il seguente set di regole utilizza:
-
una regola dinamica per verificare se un set di dati è in crescita rispetto alla media finale delle ultime tre esecuzioni del processo
-
un analizzatore
DistinctValuesCountper registrare il numero di valori distinti nella colonna delNamedel set di dati -
un analizzatore
ColumnLengthper tracciare le dimensioni minime e massime delNamenel tempo
I risultati delle metriche dell'analizzatore per l'esecuzione del processo possono essere visualizzati nella scheda Qualità dei dati.
Rules = [ RowCount > avg(last(3)) ] Analyzers = [ DistinctValuesCount "Name", ColumnLength "Name" ]
AWS Glue Data Quality supporta i seguenti analizzatori.
| Nome dell'analizzatore | Funzionalità |
|---|---|
RowCount |
Calcola il conteggio delle righe per un set di dati |
Completeness |
Calcola la percentuale di completezza di una colonna |
Uniqueness |
Calcola la percentuale di unicità di una colonna |
Mean |
Calcola la media di una colonna numerica |
Sum |
Calcola la somma di una colonna numerica |
StandardDeviation |
Calcola la deviazione standard di una colonna numerica |
Entropy |
Calcola l'entropia di una colonna numerica |
DistinctValuesCount |
Calcola il numero di valori distinti in una colonna |
UniqueValueRatio |
Calcola il rapporto di valori univoci in una colonna |
ColumnCount |
Calcola il numero di colonne in un set di dati |
ColumnLength |
Calcola la lunghezza di una colonna |
ColumnValues |
Calcola il valore minimo e il valore massimo per le colonne numeriche. Calcola il valore minimo ColumnLength e massimo ColumnLength per le colonne non numeriche |
ColumnCorrelation |
Calcola le correlazioni tra determinate colonne |
CustomSql |
Calcola le statistiche restituite da CustomSQL |
AllStatistics |
Calcola le seguenti statistiche:
|
Commenti
È possibile usare il carattere '#' per aggiungere un commento al documento DQDL. Tutto ciò che segue il carattere '#' e fino alla fine della riga viene ignorato da DQDL.
Rules = [ # More items should generally mean a higher price, so correlation should be positive ColumnCorrelation "price" "num_items" > 0 ]
