Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Cos’è Amazon Data Firehose?
Amazon Data Firehose è un servizio completamente gestito per la distribuzione di dati di streaming
Per ulteriori informazioni sulle soluzioni per i AWS big data, consulta Big Data on AWS
Scopri i concetti chiave
Quando inizi a usare Amazon Data Firehose, puoi trarre vantaggio dalla comprensione dei seguenti concetti.
- Flusso Firehose
-
L'entità sottostante di Amazon Data Firehose. Puoi utilizzare Amazon Data Firehose creando uno stream Firehose e inviandogli dati. Per ulteriori informazioni, consultare Tutorial: Creare uno stream Firehose dalla console e Inviare dati a uno stream Firehose.
- Registra
-
I dati di interesse che il produttore di dati invia a uno stream Firehose. Un record può avere dimensioni fino a 1.000 KB.
- Produttore di dati
-
I produttori inviano i dischi agli stream di Firehose. Ad esempio, un server Web che invia dati di registro a un flusso Firehose è un produttore di dati. Puoi anche configurare lo stream Firehose per leggere automaticamente i dati da un flusso di dati Kinesis esistente e caricarli nelle destinazioni. Per ulteriori informazioni, consulta Inviare dati a uno stream Firehose.
- Dimensione e intervallo del buffer
-
Amazon Data Firehose memorizza nel buffer i dati di streaming in entrata fino a una certa dimensione o per un determinato periodo di tempo prima di consegnarli alle destinazioni. Buffer Sizeè in MBs e lo è in pochi Buffer Interval secondi.
Comprendi il flusso di dati in Amazon Data Firehose
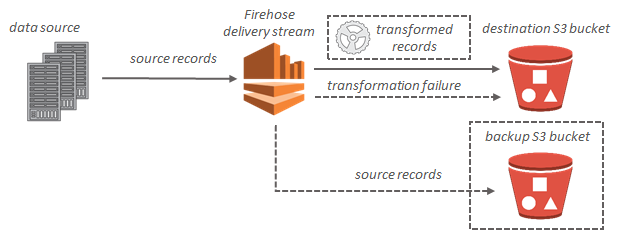
Per le destinazioni Amazon S3, i dati in streaming vengono distribuiti sul bucket S3. Se è abilitata la trasformazione dei dati, puoi scegliere di eseguire il backup dei dati di origine su un altro bucket Amazon S3.
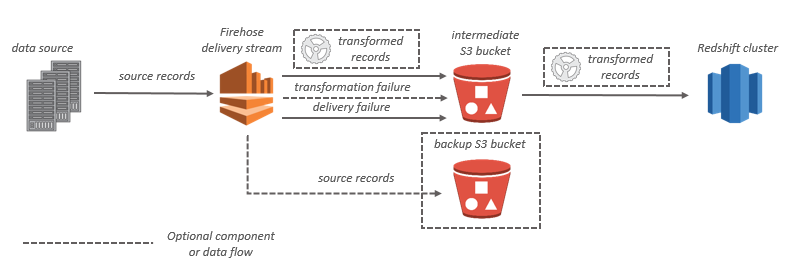
Per le destinazioni Amazon Redshift, i dati in streaming vengono distribuiti prima sul bucket S3. Amazon Data Firehose emette quindi un comando Amazon COPY Redshift per caricare i dati dal bucket S3 al cluster Amazon Redshift. Se è abilitata la trasformazione dei dati, puoi scegliere di eseguire il backup dei dati di origine su un altro bucket Amazon S3.
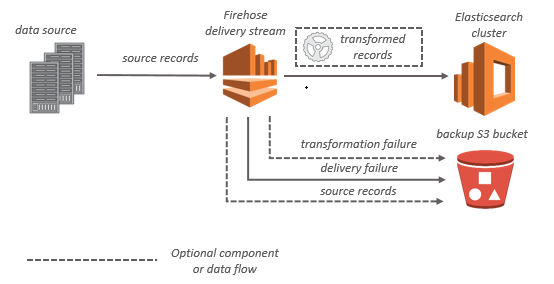
Per le destinazioni OpenSearch del servizio, i dati in streaming vengono distribuiti al cluster di OpenSearch servizio e, facoltativamente, possono essere sottoposti a backup contemporaneamente nel bucket S3.
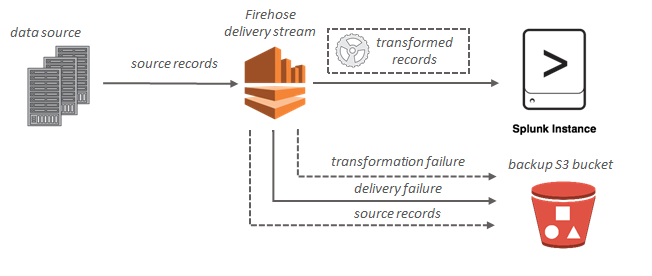
Per le destinazioni Splunk, i dati in streaming vengono distribuiti su Splunk e se ne può eseguire contemporaneamente il backup sul bucket S3.