Contribuisci a migliorare questa pagina
Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Per contribuire a questa guida per l'utente, scegli il GitHub link Modifica questa pagina nel riquadro destro di ogni pagina.
Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Load & Serve modelli su Amazon EKS
Suggerimento
Registrati
I passaggi di questa sezione implementano un modello di linguaggio di grandi dimensioni (LLM) su Amazon EKS, lo utilizzano con vLLM e interagiscono con l'endpoint di inferenza.
La procedura dettagliata utilizza i seguenti strumenti:
-
vLLM
: un motore di inferenza ad alto rendimento ottimizzato per il servizio LLM e la gestione della memoria GPU. -
Run:ai Model Streamer
: trasmette i pesi dei modelli direttamente da Amazon S3 alla memoria della GPU, riducendo il tempo di caricamento da minuti a secondi. -
Open WebUI
: un frontend di chat ospitato autonomamente che si connette all'API di VLLM. OpenAI-compatible
Questa sezione utilizza il Ministral-3-8B-Instruct-2512 modello, ma puoi implementare qualsiasi modello
Importante
Usa il cluster che hai creato nella Configura il cluster Amazon EKS per i AI/ML carichi di lavoro sezione. Le istruzioni di questa procedura dettagliata sono valide sia per EKS Auto Mode che per Karpenter autogestito.
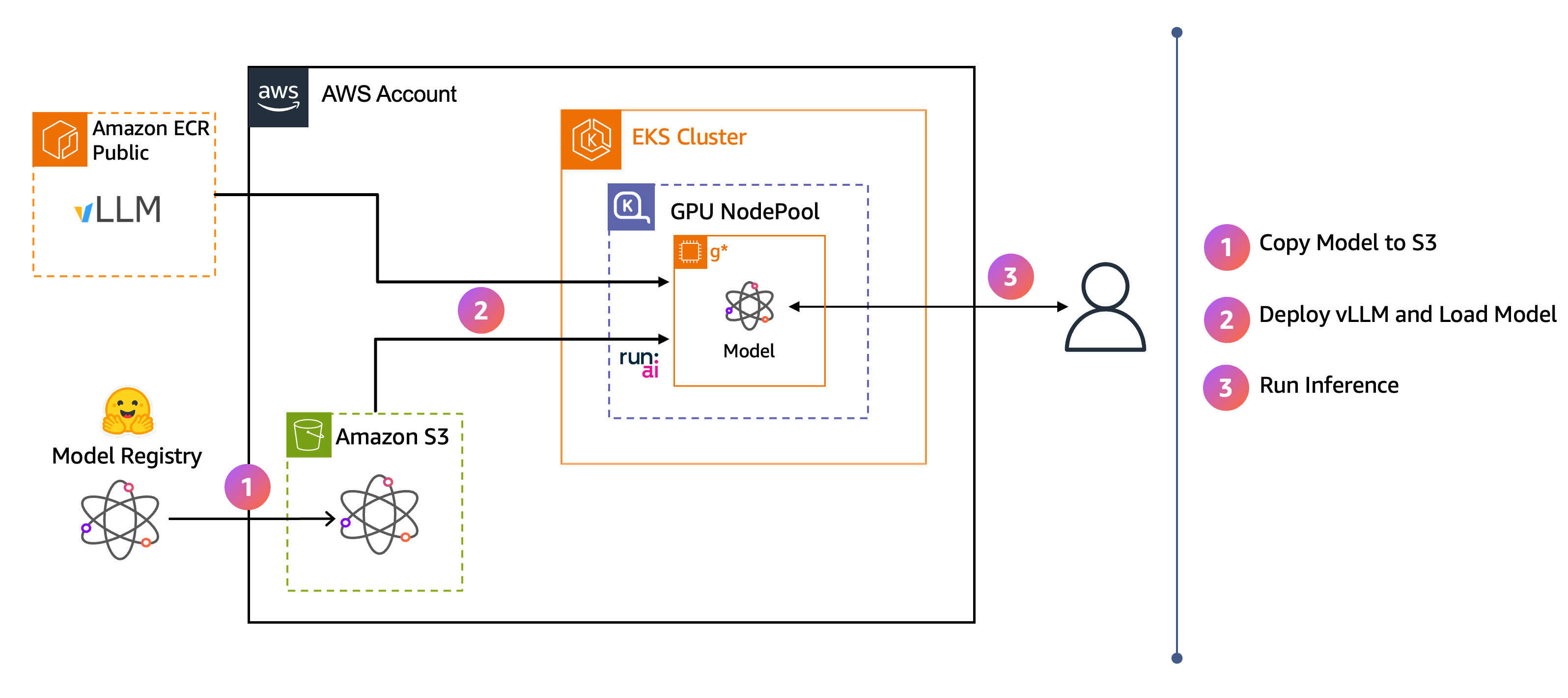
Il diagramma dell'architettura mostra il flusso end-to-end:
-
I pesi dei modelli vengono scaricati da Hugging Face ad Amazon S3.
-
VLLm trasmette il modello direttamente da S3 alla memoria della GPU utilizzando Model Streamer. Run:ai
-
Gli utenti inviano richieste di inferenza all'endpoint VLm.
Una volta completati questi passaggi, si dispone di un endpoint di inferenza VLLm che è possibile utilizzare per interagire con un modello Ministral tramite un'applicazione di chat frontend.
Prerequisiti
Completa i passaggi nella sezione Configurazione del cluster.
Se hai aperto un nuovo terminale, imposta il nome e la regione del cluster che hai usato nella sezione Configurazione del cluster tramite CLI:
export CLUSTER_NAME=ai-eks-docs export AWS_REGION=us-east-2
Cerca il bucket Model Weights che hai creato nella fase Model weights S3 bucket:
MODEL_BUCKET=$(aws s3api list-buckets \ --query "Buckets[?starts_with(Name, '${CLUSTER_NAME}-models-')].Name | [0]" \ --output text) echo "Model bucket: ${MODEL_BUCKET}"
Passaggio 1: scarica il modello da Hugging Face
In questo passaggio, distribuisci un Kubernetes Job che scarica il modello da Hugging Face e lo carica nel bucket S3 che hai creato nella sezione dei prerequisiti.
Per scaricare il modello, applica il seguente Job manifest:
Esempio Scarica il modello Job manifest
cat << EOF | kubectl apply -f - apiVersion: batch/v1 kind: Job metadata: name: model-download namespace: default labels: guide: ai-eks-docs spec: backoffLimit: 10 activeDeadlineSeconds: 3600 ttlSecondsAfterFinished: 86400 template: spec: restartPolicy: Never serviceAccountName: model-storage-sa containers: - name: downloader image: python:3.11-slim command: ["/bin/bash", "-c"] args: - | set -e pip install -q huggingface_hub boto3 echo "Downloading Ministral-3-8B-Instruct-2512 from Hugging Face..." python3 -c "from huggingface_hub import snapshot_download; snapshot_download('mistralai/Ministral-3-8B-Instruct-2512', local_dir='/tmp/mistral', allow_patterns=['*.json', '*.txt', '*.md', 'consolidated.safetensors'], ignore_patterns=['model-*.safetensors', 'model.safetensors.index.json'])" echo "Uploading to S3 bucket: \${MODEL_BUCKET}" python3 << 'PYTHON' import boto3 import os from pathlib import Path s3 = boto3.client('s3') bucket = os.environ.get('MODEL_BUCKET') local_dir = Path("/tmp/mistral") for file_path in local_dir.rglob("*"): if file_path.is_file(): if '.cache' in file_path.parts: continue s3_key = f"Ministral-3-8B-Instruct-2512/{file_path.relative_to(local_dir)}" print(f"Uploading {file_path.name}...") s3.upload_file(str(file_path), bucket, s3_key) print("Upload complete!") PYTHON env: - name: MODEL_BUCKET value: "${MODEL_BUCKET}" - name: HF_HUB_DISABLE_XET value: "1" resources: requests: memory: "2Gi" cpu: "1" limits: memory: "4Gi" cpu: "2" EOF
Attendi il completamento del Job. I pesi del modello (consolidated.safetensors) sono di circa 10,4 GB e questo passaggio richiede in genere 3-5 minuti.
kubectl wait --for=condition=complete job/model-download --timeout=600s
Output previsto:
job.batch/model-download condition met
Verifica che i pesi del modello siano stati caricati su S3:
aws s3 ls s3://$(kubectl get job model-download -o jsonpath='{.spec.template.spec.containers[0].env[?(@.name=="MODEL_BUCKET")].value}')/Ministral-3-8B-Instruct-2512/ --recursive
Output previsto:
2026-05-18 10:29:53 20311 Ministral-3-8B-Instruct-2512/README.md 2026-05-18 10:29:53 2361 Ministral-3-8B-Instruct-2512/SYSTEM_PROMPT.txt 2026-05-18 10:29:53 1903 Ministral-3-8B-Instruct-2512/config.json 2026-05-18 10:29:54 10420633176 Ministral-3-8B-Instruct-2512/consolidated.safetensors 2026-05-18 10:29:53 131 Ministral-3-8B-Instruct-2512/generation_config.json 2026-05-18 10:29:53 1185 Ministral-3-8B-Instruct-2512/params.json 2026-05-18 10:29:53 976 Ministral-3-8B-Instruct-2512/processor_config.json 2026-05-18 10:29:53 16753777 Ministral-3-8B-Instruct-2512/tekken.json 2026-05-18 10:29:53 17077402 Ministral-3-8B-Instruct-2512/tokenizer.json 2026-05-18 10:29:53 21168 Ministral-3-8B-Instruct-2512/tokenizer_config.json
Il file consolidated.safetensors contiene i pesi del modello (circa 10,4 GB). I file rimanenti sono file di configurazione e tokenizer necessari a VLLm per servire il modello.
Fase 2: Implementazione del contenitore di inferenza
In questa sezione, distribuisci VLLM come implementazione Kubernetes per servire il modello che hai caricato su Amazon S3.
Questa sezione utilizza AWS Deep Learning Containers
Questa distribuzione utilizza il seguente AWS DLC per VLLmpublic.ecr.aws/deep-learning-containers/vllm:0.21.0-gpu-py312-cu130-ubuntu22.04-ec2-v1.0-soci
Il tag image indica VLLm 0.21.0 con supporto GPU, Python 3.12, CUDA 13.0, Ubuntu 22.04, ottimizzato per i carichi di lavoro e per un avvio più rapido dei container. EC2-based SOCI-enabled
Questo manifest crea una distribuzione che esegue VLLm su un nodo GPU e trasmette il modello direttamente da S3 nella memoria della GPU utilizzando Model Streamer. Run:ai Il manifesto crea anche un servizio ClusterIP che espone l'endpoint VLLM sulla porta 8000 per l'accesso all'interno del cluster.
Applica il manifesto:
Esempio Distribuzione e servizio VLLM (YAML)
cat << EOF | kubectl apply -f - apiVersion: apps/v1 kind: Deployment metadata: name: vllm-inference-app labels: guide: ai-eks-docs spec: replicas: 1 selector: matchLabels: app: vllm-inference-app template: metadata: labels: app: vllm-inference-app guide: ai-eks-docs spec: serviceAccountName: model-storage-sa tolerations: - key: nvidia.com/gpu operator: Exists effect: NoSchedule nodeSelector: karpenter.sh/nodepool: gpu-inf containers: - name: vllm-inference image: public.ecr.aws/deep-learning-containers/vllm:0.21.0-gpu-py312-cu130-ubuntu22.04-ec2-v1.0-soci ports: - containerPort: 8000 args: - "--model=s3://${MODEL_BUCKET}/Ministral-3-8B-Instruct-2512/" - "--host=0.0.0.0" - "--port=8000" - "--tensor-parallel-size=1" - "--gpu-memory-utilization=0.9" - "--max-model-len=8192" - "--max-num-seqs=128" - "--load-format=runai_streamer" - "--enforce-eager" - "--tokenizer_mode=mistral" - "--config_format=mistral" - "--enable-auto-tool-choice" - "--tool-call-parser=mistral" resources: limits: nvidia.com/gpu: 1 requests: memory: "40Gi" cpu: "8" --- apiVersion: v1 kind: Service metadata: name: vllm-inference-svc namespace: default labels: app: vllm-inference-app spec: selector: app: vllm-inference-app ports: - name: http port: 8000 targetPort: 8000 protocol: TCP EOF
Verifica che il pod VLLm sia nello stato Ready:
kubectl get pod -l app=vllm-inference-app -w
Output previsto:
NAME READY STATUS RESTARTS AGE vllm-inference-app-65df5fddc8-5kmjm 1/1 Running 0 86s
Potrebbero essere necessari circa 2 minuti prima che l'immagine del contenitore venga scaricata e che VLLm trasmetta i pesi del modello da S3 alla memoria della GPU. Attendi che il contenitore venga visualizzato 1/1 nella colonna READY prima di procedere.
La combinazione di EKS, SOCI e Run:ai Model Streamer consente un avvio rapido dei pod. Per controllare l'ora di avvio di ogni fase, visualizza gli eventi del pod:
kubectl describe pod -l app=vllm-inference-app | grep -A 20 "Events:"
Output previsto:
Events: Type Reason Age From Message ---- ------ ---- ---- ------- Warning FailedScheduling 86s default-scheduler 0/2 nodes are available: 2 node(s) had untolerated taint(s). Normal Nominated 85s eks-auto-mode/compute Pod should schedule on: nodeclaim/gpu-inf-kqkq6 Normal Scheduled 55s default-scheduler Successfully assigned default/vllm-inference-app-d9d54586d-csmd7 to i-04f8792414384d2d3 Normal Pulling 52s kubelet Pulling image "public.ecr.aws/deep-learning-containers/vllm:0.21.0-gpu-py312-cu130-ubuntu22.04-ec2-v1.0-soci" Normal Pulled 4s kubelet Successfully pulled image "public.ecr.aws/deep-learning-containers/vllm:0.21.0-gpu-py312-cu130-ubuntu22.04-ec2-v1.0-soci" in 48.376s (48.376s including waiting). Image size: 8802823997 bytes. Normal Created 4s kubelet Created container vllm-inference Normal Started 4s kubelet Started container vllm-inference
In questo esempio, il provisioning del nodo GPU è stato effettuato in 30 secondi e l'immagine del contenitore da 8,8 GB è stata recuperata in circa 48 secondi utilizzando SOCI. L'acquisizione rapida delle immagini riduce i tempi di avvio a freddo per contenitori di inferenza di grandi dimensioni, il che consente di scalare i pod GPU in modo dinamico anziché sovraccaricare la capacità inattiva della GPU.
Successivamente, controlla i log vLLM per verificare il tempo di caricamento del modello:
kubectl logs $(kubectl get pod -l app=vllm-inference-app -o jsonpath='{.items[0].metadata.name}') | grep -i 'Model loading took'
Output previsto:
INFO 05-18 18:41:49 [gpu_model_runner.py:4959] Model loading took 9.81 GiB memory and 5.023344 seconds
Il registro conferma che Run:ai Model Streamer ha caricato i pesi del modello da 10,4 GB direttamente da S3 nella memoria della GPU in circa 5 secondi, consumando 9,8 GiB di memoria GPU.
Il tempo di download dell'immagine in questo esempio utilizzava un'istanza g6e.4xlarge, che ha una larghezza di banda di rete sostenuta di 20 Gbps. Il recupero delle immagini e i tempi di caricamento dei modelli variano a seconda degli altri tipi di istanza a seconda della larghezza di banda di rete disponibile.
Fase 3: Eseguire l'inferenza
Con l'implementazione VLLM in esecuzione, convalida l'endpoint di inferenza e implementa un frontend di chat per interagire con il modello.
Esegui un test di convalida del modello
Esponi l'endpoint di inferenza tramite port forward:
kubectl port-forward svc/vllm-inference-svc 8000:8000
Apri una nuova finestra di terminale, quindi verifica che il contenitore di inferenza stia rispondendo:
curl -sI -X GET http://localhost:8000/health
Output previsto:
HTTP/1.1 200 OK date: Fri, 18 May 2026 00:39:23 GMT server: uvicorn content-length: 0
Fase 4: Monitoraggio di vLLM
VLLm espone immediatamente le metriche di Prometheus, tra cui la frequenza delle richieste, il throughput dei token, la latenza end-to-end e l'utilizzo della cache KV della GPU. In questa sezione, utilizzi queste metriche con lo stack di monitoraggio impostato nelle fasi di configurazione del cluster e le visualizzi su una dashboard Grafana preconfigurata.
Importante
È necessario completare la sottosezione Monitoraggio della sezione Configurazione del cluster tramite CLI prima di continuare. Questo passaggio dipende dall'installazione di kube-prometheus-stack e dal dashboard VLLM Grafana già fornito nel file dei valori.
Applica il vLLm ServiceMonitor
A ServiceMonitor indica a Prometheus dove acquisire le metriche vLLM.
cat << EOF | kubectl apply -f - apiVersion: monitoring.coreos.com/v1 kind: ServiceMonitor metadata: name: vllm-inference-app namespace: default labels: release: kube-prometheus-stack spec: selector: matchLabels: app: vllm-inference-app endpoints: - port: http path: /metrics interval: 15s EOF
Verifica che ServiceMonitor sia stato creato:
kubectl get servicemonitor vllm-inference-app
Output previsto:
NAME AGE vllm-inference-app 5s
Per inserire metriche nella dashboard, genera traffico di inferenza sull'endpoint VLLM già esposto tramite port-forward nella fase di convalida.
Scopri il nome del modello servito:
MODEL_NAME=$(curl -s http://localhost:8000/v1/models | jq -r '.data[0].id') echo "Using model: $MODEL_NAME"
Invia 50 richieste di completamento della chat in parallelo:
for i in $(seq 1 50); do curl -s -X POST http://localhost:8000/v1/chat/completions \ -H "Content-Type: application/json" \ -d "{\"model\": \"$MODEL_NAME\", \"messages\": [{\"role\": \"user\", \"content\": \"Write a short poem about Kubernetes.\"}], \"max_tokens\": 128}" \ > /dev/null & done wait
Mentre il traffico scorre (o subito dopo), controlla le metriche del throughput dei token direttamente dall'endpoint vLLM: /metrics
curl -s http://localhost:8000/metrics | grep -E '^vllm:(prompt_tokens_total|generation_tokens_total|avg_generation_throughput_toks_per_s|avg_prompt_throughput_toks_per_s)' | head
Le vllm:generation_tokens_total metriche vllm:prompt_tokens_total e sono contatori che aumentano in modo monotono dei token di input e output serviti. Le vllm:avg_generation_throughput_toks_per_s metriche vllm:avg_prompt_throughput_toks_per_s e sono indicatori di produttività a media costante. Queste stesse metriche alimentano la dashboard Grafana che apri nella seguente sottosezione.
Visualizza la dashboard di vLLM Grafana
Il file dei valori kube-prometheus-stack della sezione Monitoring fornisce già il dashboard vLLm della community (GNetID
Per accedere a Grafana, avvia un port-forward verso il servizio Grafana:
kubectl port-forward svc/kube-prometheus-stack-grafana 3000:80 -n monitoring
Apri http://localhost:3000admin e password dal seguente comando:
kubectl --namespace monitoring get secrets kube-prometheus-stack-grafana -o jsonpath="{.data.admin-password}" | base64 -d ; echo
Passa a Dashboard > GPU Monitoring > VLLm Metrics.
Pannello di controllo VLM Grafana

La dashboard mostra la frequenza delle richieste, il throughput dei prompt e dei token di generazione, i percentili di latenza e l'utilizzo della cache KV della GPU per l'endpoint di inferenza VLLm.
Fase 5: Implementazione dell'applicazione di chat
In questo passaggio, si implementa Open WebUI come interfaccia di chat per interagire con il modello. Open WebUI è un'interfaccia AI open source e ospitata autonomamente che OpenAI-compatible supporta le API e fornisce un'interfaccia di chat con cronologia delle conversazioni e rendering dei markdown. Poiché VLLM espone un' OpenAI-compatible API, Open WebUI si connette direttamente ad essa come backend.
Per distribuire l'applicazione Open WebUI, applica il seguente manifesto:
Esempio Distribuzione e servizio Open WebUI YAML
cat << 'EOF' | kubectl apply -f - apiVersion: apps/v1 kind: Deployment metadata: name: open-webui namespace: default labels: app: open-webui guide: ai-eks-docs spec: replicas: 1 selector: matchLabels: app: open-webui template: metadata: labels: app: open-webui guide: ai-eks-docs spec: containers: - name: open-webui image: ghcr.io/open-webui/open-webui:v0.9.2 ports: - containerPort: 8080 resources: requests: cpu: "500m" memory: "500Mi" limits: cpu: "1000m" memory: "1Gi" env: - name: OPENAI_API_BASE_URLS value: "http://vllm-inference-svc:8000/v1" - name: OPENAI_API_KEY value: "dummy" - name: WEBUI_AUTH value: "False" - name: ENABLE_OLLAMA_API value: "False" - name: ENABLE_EVALUATION_ARENA_MODELS value: "False" - name: RAG_EMBEDDING_ENGINE value: "" volumeMounts: - name: webui-volume mountPath: /app/backend/data volumes: - name: webui-volume emptyDir: {} --- apiVersion: v1 kind: Service metadata: name: open-webui namespace: default labels: app: open-webui spec: type: ClusterIP selector: app: open-webui ports: - protocol: TCP port: 80 targetPort: 8080 EOF
Attendi che il pod Open WebUI sia pronto:
kubectl wait --for=condition=ready pod -l app=open-webui --timeout=300s
Output previsto:
pod/open-webui-6cbfc9867f-jf9w9 condition met
Per accedere all'applicazione, configura il port forwarding:
kubectl port-forward svc/open-webui 8080:80
Apri http://localhost:8080
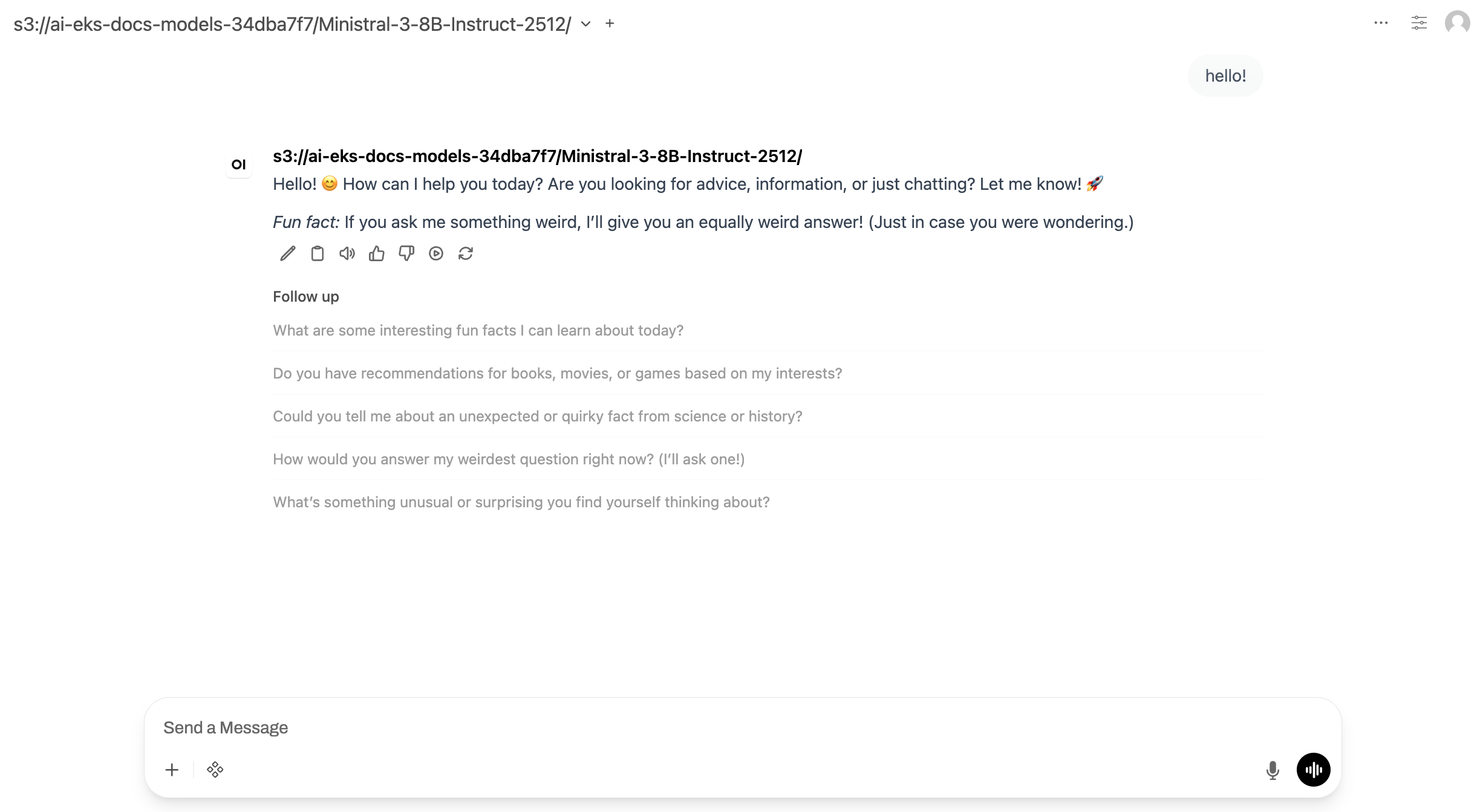
Viene visualizzata l'interfaccia di chat in cui è possibile interagire con il modello Ministral.
Al termine del test, interrompi il port-forward con kbd: [Ctrl+C].
Eliminazione
Per rimuovere le risorse del carico di lavoro create in questa sezione, eliminate l'applicazione Open WebUI, il server di inferenza VLLm e il Job di download del modello:
kubectl delete deployment open-webui kubectl delete service open-webui kubectl delete deployment vllm-inference-app kubectl delete service vllm-inference-svc kubectl delete servicemonitor vllm-inference-app kubectl delete job model-download
