Contribuisci a migliorare questa pagina
Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Per contribuire a questa guida per l'utente, scegli il GitHub link Modifica questa pagina nel riquadro destro di ogni pagina.
Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Configura il cluster Amazon EKS per i AI/ML carichi di lavoro utilizzando le CLI
Suggerimento
Registrati
Questa sezione illustra i passaggi per creare l'infrastruttura necessaria per eseguire carichi di lavoro di formazione o inferenza su Amazon EKS tramite comandi CLI. I passaggi includono la creazione di un cluster EKS, GPU-enabled nodi con EKS Auto Mode o Karpenter, uno stack di monitoraggio con Prometheus e Grafana e lo storage Amazon S3 per i pesi dei modelli.
Consulta la documentazione per EKS Auto Mode e Karpenter
High-level architettura e flusso di lavoro
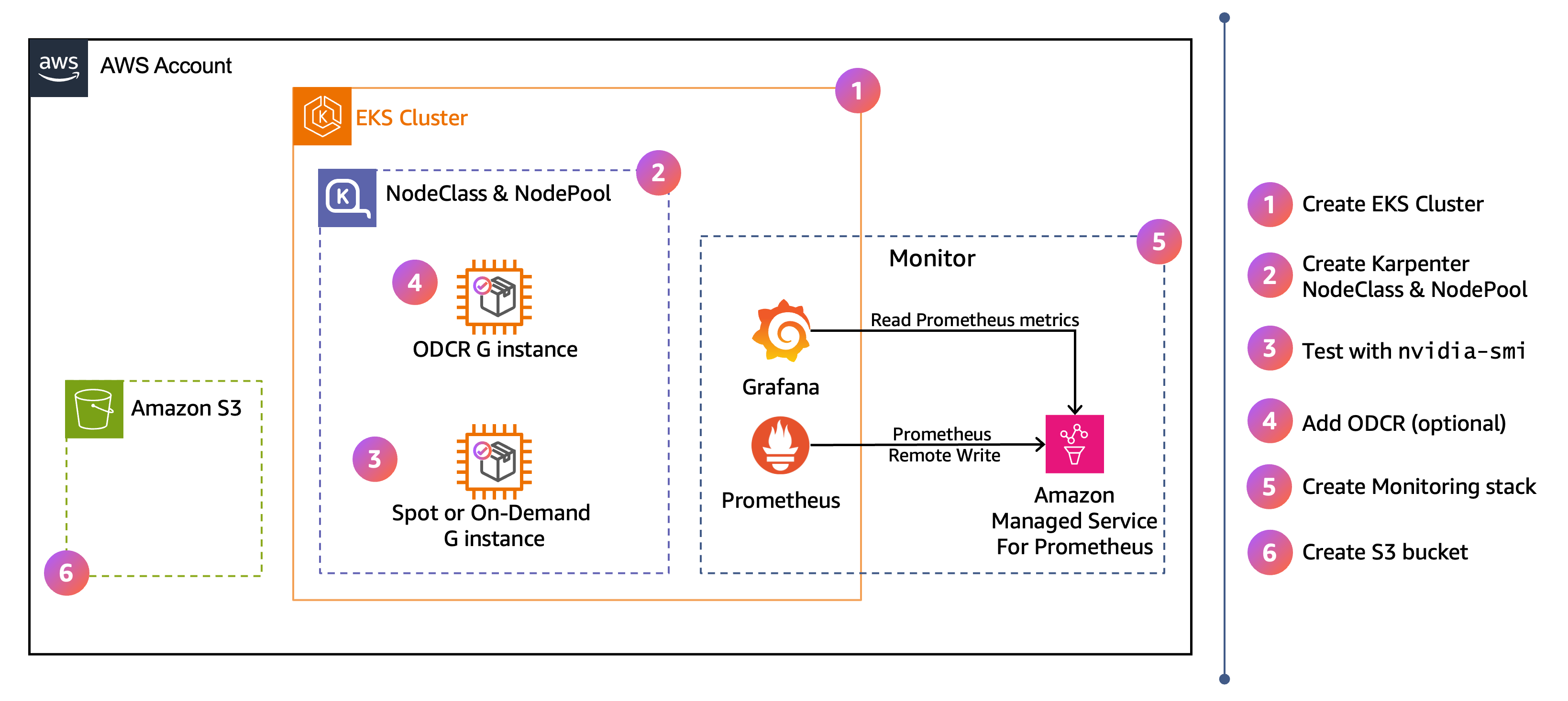
Il AWS diagramma mostra l'architettura di alto livello per la configurazione di questa sezione. I passaggi numerati sulla destra indicano l'ordine in cui si completa la configurazione nei passaggi seguenti.
Prerequisiti
-
kubectl>= 1,35. Per le istruzioni di configurazione, vedere. Configura kubectl ed eksctl -
AWS CLI = 2,27. Per le istruzioni di configurazione, consulta Installazione.
-
Elmo >= 3.14. Per le istruzioni di configurazione, vedere Setup Helm.
-
jq. Per le istruzioni di configurazione, consulta Download jq. -
eksctl>= 0.27,0. Per le istruzioni di configurazione, vedere Installazionenella documentazione. eksctl
Verifica la tua eksctl versione:
eksctl version
Se utilizzi una versione precedente alla 0.227.0, segui la guida all'installazione di eksctl per
Impostazione delle variabili di ambiente
Mantieni coerenti il nome e la AWS regione del cluster seguenti durante questi passaggi. La modifica potrebbe far sì che i comandi successivi indirizzino al cluster EKS sbagliato.
export CLUSTER_NAME=ai-eks-docs export AWS_REGION=us-east-2
L'utilizzo di tutti gli AZ disponibili migliora la tolleranza agli errori e aumenta le possibilità di ottenere la capacità della GPU:
export AZS=$(aws ec2 describe-availability-zones \ --region ${AWS_REGION} \ --query "AvailabilityZones[?ZoneId!='use1-az3' && ZoneId!='usw1-az2' && ZoneId!='cac1-az3'].ZoneName" \ --output text | tr '\t' ',') echo $AZS
Importante
Le zone di disponibilità use1-az3usw1-az2, e cac1-az3 sono escluse perché Amazon EKS non supporta il posizionamento del piano di controllo in tali zoneUnsupportedAvailabilityZoneException
Output previsto:
us-east-2a,us-east-2b,us-east-2c
Le AZ nell'output varieranno in base alla regione. Questo esempio mostra le AZ disponibili per us-east-2 regione.
Crea cluster e GPU NodePool
Questa sezione fornisce due percorsi per la creazione del cluster e GPU-enabled dei nodi EKS, illustrati nel diagramma seguente. Scegli una sola opzione in tutta la guida.
-
EKS Auto Mode: oltre ai principali componenti aggiuntivi di rete, archiviazione e bilanciamento del carico, EKS Auto Mode include e gestisce le seguenti funzionalità per i carichi di lavoro di addestramento e inferenza: agente di monitoraggio dei nodi EKS, riparazione automatica dei nodi, snapshotter SOCI per il prelievo
rapido dei container e disponibilità della GPU per l'impostazione predefinita. NodeClass Il plug-in per dispositivi NVIDIA è incluso nell'AMI accelerata Bottlerocket utilizzata da EKS Auto Mode per i nodi. GPU-enabled -
Self-managed Karpenter: su un cluster EKS senza EKS Auto Mode, l'utente è responsabile dell'installazione e della configurazione dei componenti necessari per i carichi di lavoro di addestramento e inferenza. Ciò include componenti aggiuntivi di rete (VPC CNI, CoredNS, kube-proxy), Karpenter, l'agente di monitoraggio dei nodi EKS, il plug-in del dispositivo NVIDIA e lo snapshotter SOCI per il prelievo rapido dei container.
Opzioni del cluster EKS: EKS Auto Mode e Karpenter autogestito
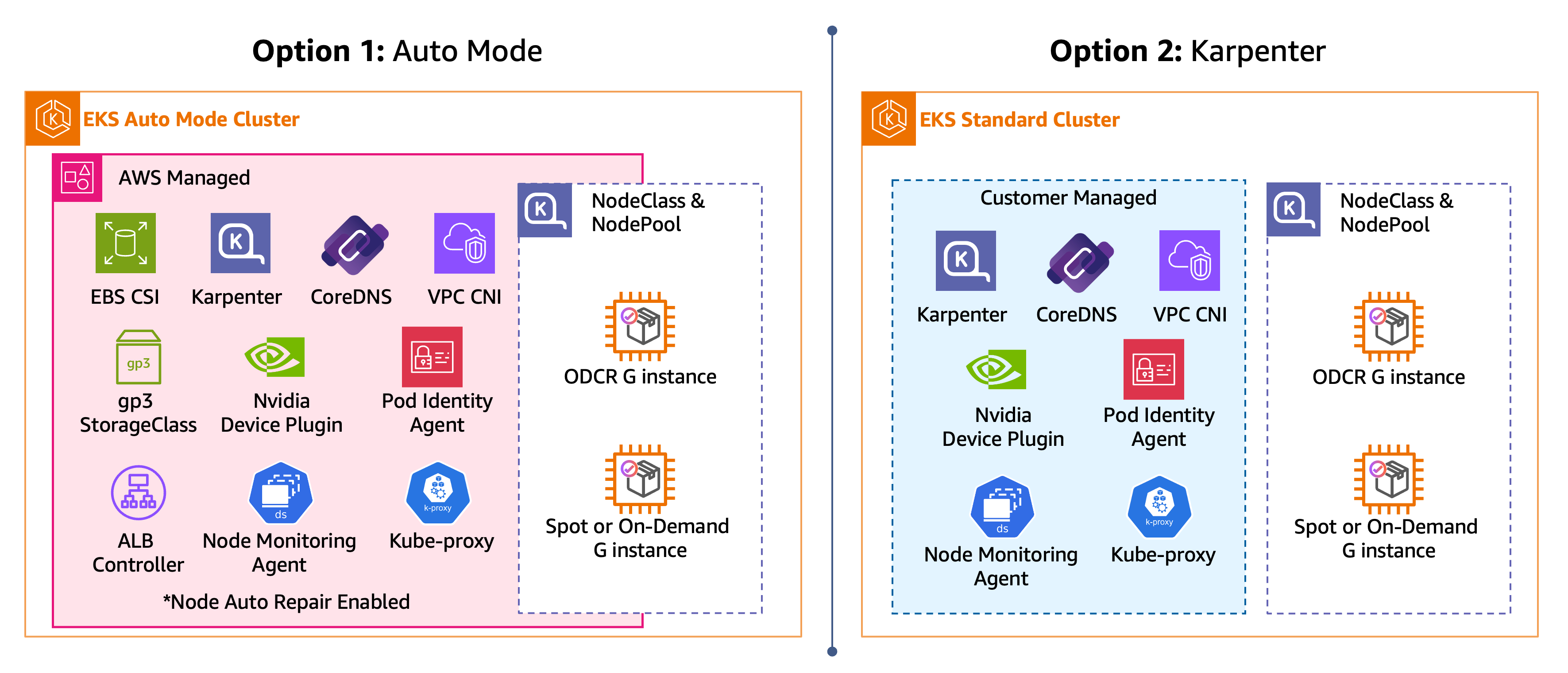
In ciascuno dei passaggi seguenti, scegliete un percorso (EKS Auto Mode, Karpenter) e seguitelo per tutto il tempo. Dopo aver completato i passaggi per il percorso scelto, avrai un cluster EKS con una GPU NodePool pronto per pianificare i carichi di lavoro della GPU.
Fase 1: Creazione del cluster
Inizia creando il tuo cluster EKS e installando i componenti del cluster necessari per i carichi di lavoro GPU.
Con EKS Auto Mode, un solo eksctl create cluster --enable-auto-mode comando effettua il provisioning di un cluster EKS pronto per i carichi di lavoro GPU.
Con Karpenter autogestito, il eksctl create cluster comando fornisce i componenti aggiuntivi di rete di base, quindi sono necessari passaggi aggiuntivi per abilitare la riparazione automatica dei nodi tramite un feature gate Karpenter, installare l'agente di monitoraggio dei nodi EKS e installare il plug-in del dispositivo NVIDIA.
avvertimento
Sia per la modalità automatica EKS che per i percorsi Karpenter autogestiti, la riparazione automatica dei nodi si comporta allo stesso modo per i nodi forniti da. NodePools La riparazione automatica dei nodi in EKS Auto Mode e Karpenter è un metodo di interruzione forzato che aggira l'annotazione e. PodDisruptionBudgets karpenter.sh/do-not-disrupt terminationGracePeriod La riparazione automatica dei nodi attende 10 minuti prima di sostituire un nodo con la AcceleratedHardwareReady condizione impostata su e 30 minuti per le altre condizioni di False riparazione.
Fase 2: Creare una GPU dinamica NodePool
Definisci una NodePool soluzione che effettui il provisioning dinamico di istanze G-family GPU con una generazione superiore a 4, utilizzando la capacità Spot come alternativa. On-Demand I percorsi EKS Auto Mode e Karpenter utilizzano entrambi la stessa NodePool API con l'unica differenza che indica. NodeClass In EKS Auto Mode, il pacchetto seleziona default NodeClass già l'AMI giusta e configura il pull parallelo SOCI, quindi NodePool è l'unico oggetto che crei. In Karpenter autogestito, è inoltre necessario un dispositivo personalizzato EC2NodeClass che colleghi l'AMI e ottimizzi il SOCI.
Convalida il file che è stato creato NodePool :
kubectl get nodepool gpu-inf
Output previsto:
NAME NODECLASS NODES READY AGE gpu-inf default 0 True 8s
Nel percorso Karpenter autogestito, la colonna NODECLASS mostra invece di. gpu-inf default
Fase 3: Esegui il test con un Pod campione
Testa la NodePool configurazione della GPU con un nvidia-smi Pod.
cat << EOF | kubectl apply -f - apiVersion: v1 kind: Pod metadata: name: nvidia-smi labels: guide: ai-eks-docs spec: tolerations: - key: "nvidia.com/gpu" operator: "Exists" effect: "NoSchedule" containers: - name: nvidia-smi image: public.ecr.aws/amazonlinux/amazonlinux:2023-minimal command: ["nvidia-smi"] resources: limits: nvidia.com/gpu: 1 restartPolicy: OnFailure EOF
Verifica che il Pod sia pianificato e completato correttamente.
kubectl get pods
Output previsto:
NAME READY STATUS RESTARTS AGE nvidia-smi 0/1 Completed 0 67s
Lo STATUS: Completato indica che il comando nvidia-smi è stato eseguito ed è uscito. Controlla i log del Pod per vedere la GPU rilevata dal nodo.
kubectl logs nvidia-smi
Output previsto:
+-----------------------------------------------------------------------------------------+ | NVIDIA-SMI 580.126.09 Driver Version: 580.126.09 CUDA Version: 13.0 | +-----------------------------------------+------------------------+----------------------+ | GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC | | Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. | | | | MIG M. | |=========================================+========================+======================| | 0 NVIDIA RTX PRO 6000 Blac... On | 00000000:2B:00.0 Off | 0 | | N/A 30C P0 81W / 600W | 0MiB / 97887MiB | 0% Default | | | | Disabled | +-----------------------------------------+------------------------+----------------------+
L'output mostra il modello di GPU, la versione del driver, la versione CUDA e la memoria disponibile. In questo esempio, Karpenter ha fornito un'istanza G7e con una GPU NVIDIA RTX PRO 6000 Blackwell con 96 GB di memoria. 30°C è la temperatura attuale della GPU e P0 indica che la GPU è al massimo delle prestazioni (inattiva ma pronta). Il valore 81 W/600 W mostra l'attuale consumo energetico rispetto alla capacità massima, mentre 0 MiB/97887 MiB mostra la memoria GPU attualmente utilizzata rispetto alla quantità totale disponibile. Poiché il Pod ha appena eseguito nvidia-smi ed è uscito, nessun carico di lavoro utilizza la GPU, quindi la memoria è a 0 e l'alimentazione è inattiva. La versione del driver GPU NVIDIA (580.126.09) proviene dall'AMI Bottlerocket, mentre la versione CUDA (13.0) proviene dall'immagine del contenitore. Il modello di GPU e la memoria varieranno a seconda del tipo di istanza selezionato da Karpenter. Le istanze G5 hanno GPU NVIDIA A10G (24 GB), le istanze G6e hanno GPU NVIDIA L40S (48 GB) e le istanze G7e hanno GPU NVIDIA RTX PRO 6000 (96 GB).
Per capire in che modo Karpenter e lo scheduler Kubernetes si sono coordinati per fornire un nodo e posizionare il Pod, controlla gli eventi del ciclo di vita del Pod:
kubectl describe po nvidia-smi
Output previsto:
Events: Type Reason Age From Message ---- ------ ---- ---- ------- Warning FailedScheduling 60s default-scheduler 0/2 nodes are available: 2 node(s) had untolerated taint(s). no new claims to deallocate, preemption: 0/2 nodes are available: 2 Preemption is not helpful for scheduling. Normal Nominated 59s eks-auto-mode/compute Pod should schedule on: nodeclaim/gpu-inf-vxcnj Normal Scheduled 24s default-scheduler Successfully assigned default/nvidia-smi to i-0fb17a09bc4203164 Warning FailedCreatePodSandBox 21s kubelet Failed to create pod sandbox: rpc error: code = Unknown desc = failed to setup network for sandbox "7f85e25b220c8fb245187758dbbbc8efb3d40f3e49e13054404880daf4c3b2f0": plugin type="aws-cni" name="aws-cni" failed (add): add cmd: failed to setup network policy Normal Pulling 7s kubelet spec.containers{nvidia-smi}: Pulling image "public.ecr.aws/amazonlinux/amazonlinux:2023-minimal" Normal Pulled 5s kubelet spec.containers{nvidia-smi}: Successfully pulled image "public.ecr.aws/amazonlinux/amazonlinux:2023-minimal" in 1.237s (1.237s including waiting). Image size: 37442701 bytes. Normal Created 5s kubelet spec.containers{nvidia-smi}: Container created Normal Started 5s kubelet spec.containers{nvidia-smi}: Container started
Questi eventi mostrano la sequenza di pianificazione del Pod: il Pod inizialmente non riesce a pianificare perché non esistono nodi GPU (FailedScheduling), Karpenter ne nomina uno nuovo NodeClaim (Nominato), lo scheduler assegna il Pod una volta che il nodo è pronto (Pianificato), quindi l'immagine del contenitore viene estratta e avviata. EKS Auto Mode viene fornito con il pull parallelo SOCI (Seekable OCI) installato e configurato immediatamente su istanze G, P e Trn. Nota: grazie all'estrazione parallela SOCI, l'immagine del contenitore è stata estratta dall'ECR in meno di 2 secondi (1,237 secondi).
A NodeClaim è una richiesta che Karpenter crea per fornire un nodo specifico. Mostra il tipo di istanza, il tipo di capacità, AZ e se il nodo è pronto.
kubectl get nodeclaims
NodeClaim Output previsto:
NAME TYPE CAPACITY ZONE NODE READY AGE gpu-inf-xxxxx g7e.2xlarge spot us-east-2a i-0xxxxxxxxxxxx True 2m
Il tipo di istanza e la AZ varieranno. Qualsiasi G-family istanza con generazione > 4 è idonea.
L'FailedCreatePodSandBoxavviso in entrata kubectl describe pod nvidia-smi è transitorio e previsto. Il VPC CNI si inizializza in modo asincrono dopo l'unione del nodo e il kubelet riprova automaticamente. Se il Pod rimane acceso, controlla gli eventi del nodo con. ContainerCreating kubectl describe node <node-name>
Suggerimento
Se non viene visualizzato alcun nodo, verifica la presenza di errori di capacità insufficiente:
kubectl get events | grep InsufficientCapacityError
Karpenter memorizza nella cache le offerte non disponibili per 3 minuti. L'ampliamento dei tipi di istanze e delle AZ consentiti NodePool aumenta le possibilità di atterraggio.
Nota
Le istanze Spot lanciate da Karpenter non verranno visualizzate nella console Spot Requests di EC2. Karpenter utilizza l'API EC2 con. CreateFleettype: instant Le istanze vengono visualizzate nella console EC2 Instances con un ciclo di vita. spot
Fase 4: Aggiungere capacità riservata a (opzionale) NodePool
Per utilizzare innanzitutto la capacità riservata con il Spot/On-Demand fallback, crea un On-Demand Capacity Reservation (ODCR) e collegalo al tuo NodeClass, quindi aggiorna la dinamica NodePool dalla Fase 2 per consentire reserved anche la capacità. La chiamata all'API di prenotazione è la stessa per entrambi i percorsi; l' NodeClass allegato è diverso perché EKS Auto Mode e Karpenter autogestito utilizzano tipi diversi. NodeClass
avvertimento
Il comando seguente comporta un addebito per il tipo di istanza riservato fino a quando non lo si annulla con. aws ec2 cancel-capacity-reservation --capacity-reservation-id <id>
Crea la prenotazione della capacità:
CR_AZ="us-east-2a" INSTANCE_TYPE="g6e.4xlarge" aws ec2 create-capacity-reservation \ --instance-type $INSTANCE_TYPE \ --instance-platform Linux/UNIX \ --availability-zone "$CR_AZ" \ --instance-count 1 \ --instance-match-criteria open \ --end-date-type unlimited
Se ricevi un InsufficientInstanceCapacity errore, passa CR_AZ a un'altra AZ e riprova.
Cerca l'ID di prenotazione della capacità e memorizzalo in una variabile di shell per i seguenti passaggi:
CAPACITY_RESERVATION_ID=$(aws ec2 describe-capacity-reservations \ --filters "Name=state,Values=active" "Name=instance-type,Values=${INSTANCE_TYPE}" \ --query 'CapacityReservations[0].CapacityReservationId' \ --output text \ --region ${AWS_REGION}) echo "Capacity reservation ID: ${CAPACITY_RESERVATION_ID}"
Quindi applica le NodePool modifiche NodeClass e al tuo percorso:
Karpenter la considera l'opzione reserved più economica e la lancia per prima. Una volta completata la prenotazione, torna a Spot o. On-Demand
Dopo aver applicato le modifiche, verifica che Karpenter dia la priorità alla capacità riservata e torni a utilizzare Spot o. On-Demand Implementa una distribuzione a 2 repliche che richiede 1 GPU per Pod. L'ODCR è per 1 istanza, quindi il primo Pod attiva Karpenter per avviare un nodo riservato. Il secondo Pod non può entrare nel nodo riservato e attiva Karpenter per avviare un altro nodo da Spot o dalla capacità. On-Demand
cat << 'EOF' | kubectl apply -f - apiVersion: apps/v1 kind: Deployment metadata: name: gpu-overflow-test labels: guide: ai-eks-docs spec: replicas: 2 selector: matchLabels: app: gpu-overflow-test template: metadata: labels: app: gpu-overflow-test guide: ai-eks-docs spec: tolerations: - key: nvidia.com/gpu operator: Exists effect: NoSchedule containers: - name: nvidia-smi image: public.ecr.aws/amazonlinux/amazonlinux:2023-minimal command: ["sh", "-c", "nvidia-smi && sleep infinity"] resources: limits: nvidia.com/gpu: 1 EOF
A differenza del nvidia-smi test Pod dello Step 3, che veniva eseguito e chiuso, questa implementazione mantiene i Pod in funzione (sleep infinity) in modo da contenere la GPU e non rilasciare il nodo.
Verifica i Pod pianificati su nodi diversi:
kubectl get pods -l app=gpu-overflow-test -o wide
Output previsto:
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES gpu-overflow-test-59b97944fb-lq56c 1/1 Running 0 2m42s 192.168.186.240 i-057692590480155da <none> <none> gpu-overflow-test-59b97944fb-z4zcx 1/1 Running 0 2m42s 192.168.130.64 i-0521ecd1849fa0578 <none> <none>
I due pod sono in esecuzione, ciascuno su un nodo diverso.
Controlla NodeClaims per vedere i tipi di capacità:
kubectl get nodeclaims
Output previsto:
NAME TYPE CAPACITY ZONE NODE READY AGE gpu-inf-shg5w g6e.xlarge reserved us-east-2a i-0ea91fdeef65b8cb6 True 2m2s gpu-inf-ssnqf g7e.2xlarge spot us-east-2b i-00ccf7ce65cf3f6ca True 112s
Il nodo riservato è stato avviato per primo, seguito da uno Spot o da un On-Demand nodo una volta completata la prenotazione.
Pulisci la distribuzione del test:
kubectl delete deployment gpu-overflow-test
Monitoraggio
Installa uno stack di monitoraggio che raccolga i parametri di cluster, nodi e GPU in Amazon Managed Service for Prometheus (AMP) e visualizzali con Grafana. Il grafico kube-prometheus-stack Helm utilizza Prometheus per lo scraping e la scrittura remota delle metriche su AMP, oltre a Grafana autogestita per i dashboard. NVIDIA DCGM Exporter aggiunge parametri (utilizzo, memoria, temperatura, potenza, NVLink, attività del tensore). GPU-specific
Prometheus, Grafana e l'operatore accedono per impostazione predefinita a nodi non GPU perché i nodi GPU sono portatori della contaminazione. nvidia.com/gpu:NoSchedule Node-exporter e DCGM Exporter funzionano entrambi su nodi GPU, quindi possiamo analizzare le metriche dell'host e della GPU a livello di flotta.
Se hai aperto un nuovo terminale, imposta il nome e la regione del cluster:
export CLUSTER_NAME=ai-eks-docs export AWS_REGION=us-east-2
Crea lo spazio di lavoro AMP
Crea uno spazio di lavoro AMP per archiviare le metriche:
aws amp create-workspace \ --alias "amp-ws-${CLUSTER_NAME}" \ --region ${AWS_REGION}
Ottieni l'ID dell'area di lavoro:
AMP_WORKSPACE_ID=$(aws amp list-workspaces \ --alias "amp-ws-${CLUSTER_NAME}" \ --query 'workspaces[0].workspaceId' \ --output text \ --region ${AWS_REGION}) echo "AMP Workspace ID: ${AMP_WORKSPACE_ID}"
Ottieni l'endpoint di scrittura remota:
AMP_ENDPOINT=$(aws amp describe-workspace \ --workspace-id ${AMP_WORKSPACE_ID} \ --query 'workspace.prometheusEndpoint' \ --output text \ --region ${AWS_REGION}) echo "AMP Endpoint: ${AMP_ENDPOINT}"
Crea policy IAM e associazioni EKS Pod Identity
Crea una policy IAM che consenta a Prometheus di scrivere metriche in remoto e a Grafana di interrogarle:
ACCOUNT_ID=$(aws sts get-caller-identity --query Account --output text) AMP_POLICY_ARN=$(aws iam create-policy \ --policy-name "${CLUSTER_NAME}-amp-grafana-policy" \ --policy-document "{\"Version\": \"2012-10-17\", \"Statement\": [{\"Sid\": \"AllowAMPReadWrite\", \"Effect\": \"Allow\", \"Action\": [\"aps:ListWorkspaces\", \"aps:DescribeWorkspace\", \"aps:GetMetricMetadata\", \"aps:GetSeries\", \"aps:QueryMetrics\", \"aps:RemoteWrite\", \"aps:GetLabels\"], \"Resource\": \"arn:aws:aps:${AWS_REGION}:${ACCOUNT_ID}:workspace/*\"}, {\"Sid\": \"AllowCloudWatchMetrics\", \"Effect\": \"Allow\", \"Action\": [\"cloudwatch:DescribeAlarmsForMetric\", \"cloudwatch:ListMetrics\", \"cloudwatch:GetMetricData\", \"cloudwatch:GetMetricStatistics\"], \"Resource\": \"*\"}]}" \ --query 'Policy.Arn' \ --output text) echo "AMP Policy ARN: ${AMP_POLICY_ARN}"
Crea il namespace di monitoraggio e gli account di servizio per Prometheus e Grafana:
kubectl create namespace monitoring kubectl create serviceaccount amp-iamproxy-ingest-service-account -n monitoring kubectl create serviceaccount grafana-sa -n monitoring
Crea le associazioni EKS Pod Identity per collegare gli account di servizio alla policy IAM:
eksctl create podidentityassociation \ --cluster ${CLUSTER_NAME} \ --namespace monitoring \ --service-account-name amp-iamproxy-ingest-service-account \ --role-name "${CLUSTER_NAME}-amp-ingest-role" \ --permission-policy-arns ${AMP_POLICY_ARN} \ --region ${AWS_REGION} eksctl create podidentityassociation \ --cluster ${CLUSTER_NAME} \ --namespace monitoring \ --service-account-name grafana-sa \ --role-name "${CLUSTER_NAME}-grafana-role" \ --permission-policy-arns ${AMP_POLICY_ARN} \ --region ${AWS_REGION}
Verifica che entrambe le associazioni EKS Pod Identity siano state create:
eksctl get podidentityassociation --cluster ${CLUSTER_NAME} --region ${AWS_REGION}
L'output previsto dovrebbe includere entrambi amp-iamproxy-ingest-service-account e grafana-sa nel monitoring namespace.
Installa kube-prometheus-stack
Aggiungi il repository Helm:
helm repo add prometheus-community https://prometheus-community.github.io/helm-charts helm repo update
Questo file di valori omette un NodeSelector per Prometheus, Grafana e l'operatore: la contaminazione dei nodi GPU li tiene lontani dai nodi nvidia.com/gpu:NoSchedule GPU, quindi per impostazione predefinita finiscono sul sistema o sul pool generico. Node-exporter utilizza una tolleranza wildcard in modo da funzionare su ogni nodo, compresi i nodi GPU, per raccogliere metriche a livello di flotta.
Crea il file dei valori:
Esempio file di valori kube-prometheus-stack
cat << EOF > /tmp/kube-prometheus-values.yaml alertmanager: enabled: false prometheus-adapter: enabled: false prometheus: serviceAccount: create: false name: amp-iamproxy-ingest-service-account prometheusSpec: serviceAccountName: amp-iamproxy-ingest-service-account enableRemoteWriteReceiver: true retention: 2h scrapeInterval: 30s evaluationInterval: 30s podMonitorSelectorNilUsesHelmValues: false serviceMonitorSelectorNilUsesHelmValues: false resources: requests: cpu: 500m memory: 1Gi limits: memory: 8Gi remoteWrite: - url: "${AMP_ENDPOINT}api/v1/remote_write" sigv4: region: "${AWS_REGION}" queueConfig: maxSamplesPerSend: 1000 maxShards: 200 capacity: 2500 nodeSelector: node-role: system prometheusOperator: resources: requests: cpu: 100m memory: 128Mi limits: memory: 256Mi nodeSelector: node-role: system admissionWebhooks: patch: nodeSelector: node-role: system kube-state-metrics: resources: requests: cpu: 50m memory: 128Mi limits: memory: 512Mi nodeSelector: node-role: system grafana: enabled: true serviceAccount: create: false name: grafana-sa resources: requests: cpu: 100m memory: 256Mi limits: memory: 1Gi nodeSelector: node-role: system grafana.ini: auth.sigv4: enabled: true sidecar: datasources: defaultDatasourceEnabled: false plugins: - grafana-amazonprometheus-datasource additionalDataSources: - name: Amazon-Managed-Prometheus type: grafana-amazonprometheus-datasource access: proxy url: "${AMP_ENDPOINT}" isDefault: true jsonData: sigV4Auth: true defaultRegion: "${AWS_REGION}" sigV4Region: "${AWS_REGION}" editable: true dashboardProviders: dashboardproviders.yaml: apiVersion: 1 providers: - name: default orgId: 1 folder: 'GPU Monitoring' type: file disableDeletion: false editable: true options: path: /var/lib/grafana/dashboards/default dashboards: default: nvidia-dcgm: gnetId: 25261 revision: 1 datasource: - name: DS_PROMETHEUS value: Amazon-Managed-Prometheus vllm: gnetId: 25263 revision: 1 datasource: - name: DS_PROMETHEUS value: Amazon-Managed-Prometheus vllm-load-analysis: gnetId: 25494 revision: 1 datasource: - name: DS_PROMETHEUS value: Amazon-Managed-Prometheus prometheus-node-exporter: resources: requests: cpu: 50m memory: 64Mi limits: memory: 128Mi tolerations: - operator: Exists EOF
Verifica che le variabili siano state compilate correttamente:
grep -E "url:|region:" /tmp/kube-prometheus-values.yaml
Dovresti vedere l'URL completo dell'endpoint AMP (che inizia conhttps://aps-workspaces…) e la tua regione. Se una delle due è vuota, riesporta le variabili e ricrea il file.
Installa il grafico:
helm install kube-prometheus-stack prometheus-community/kube-prometheus-stack \ --namespace monitoring \ -f /tmp/kube-prometheus-values.yaml
Verifica che i pod funzionino:
kubectl get pods -n monitoring
Output previsto:
NAME READY STATUS RESTARTS AGE kube-prometheus-stack-grafana-7c58f54f77-rftrj 3/3 Running 0 4m kube-prometheus-stack-kube-state-metrics-d68dcbc84-5smxq 1/1 Running 0 4m kube-prometheus-stack-operator-5895df479f-ttm47 1/1 Running 0 4m kube-prometheus-stack-prometheus-node-exporter-t9q7s 1/1 Running 0 4m kube-prometheus-stack-prometheus-node-exporter-x6vfb 1/1 Running 0 4m prometheus-kube-prometheus-stack-prometheus-0 2/2 Running 0 4m
Lo stack distribuisce i seguenti componenti:
-
Prometheus StatefulSet (): analizza le metriche e le scrive in remoto su AMP
-
Grafana: dashboard e visualizzazione, preconfigurate con l'origine dati AMP
-
kube-state-metrics: genera metriche sullo stato degli oggetti Kubernetes (Pod status, resource, states) requests/limits NodeClaim
-
node-exporter (DaemonSet, uno per nodo): raccoglie metriche a livello di host (CPU, memoria, disco, rete)
-
operatore: gestisce le risorse personalizzate di Prometheus e Alertmanager
Alertmanager è disabilitato in questa configurazione.
Accedi a Grafana
Apri un terminale e un port-forward separati per accedere a Grafana:
kubectl port-forward svc/kube-prometheus-stack-grafana 3000:80 -n monitoring
Apri http://localhost:3000admin e password usando il seguente comando:
kubectl --namespace monitoring get secrets kube-prometheus-stack-grafana -o jsonpath="{.data.admin-password}" | base64 -d ; echo
Per verificare che la pipeline di metriche funzioni dall'inizio alla fine:
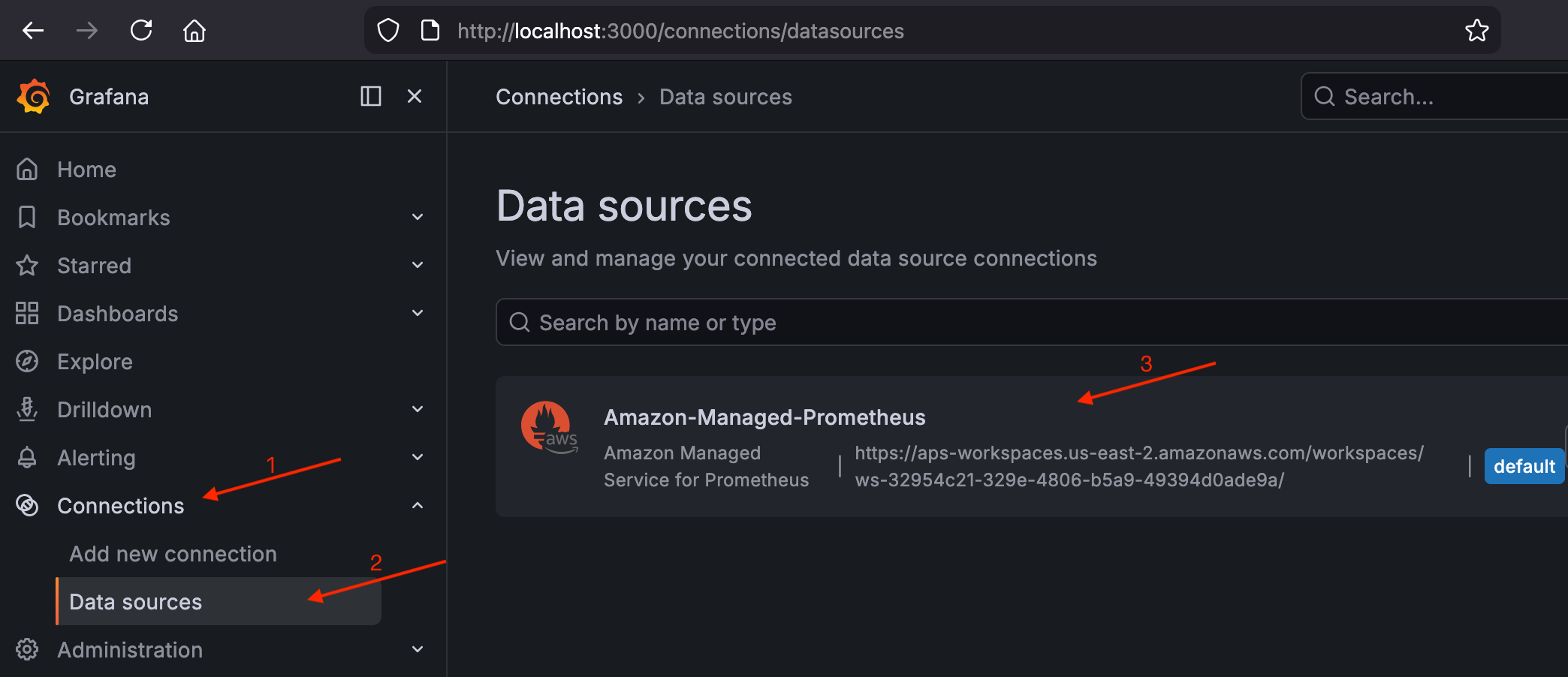
-
Passa a Connessioni > Sorgenti dati e conferma
Amazon-Managed-Prometheusche sia elencata come origine dati predefinita.Convalida l'origine dati AMP a Grafana
-
Vai a Drilldown > Metriche e cerca la metrica.
upDovresti vedere i risultati degli scrape target del tuo cluster.Convalida la
upmetrica in Grafana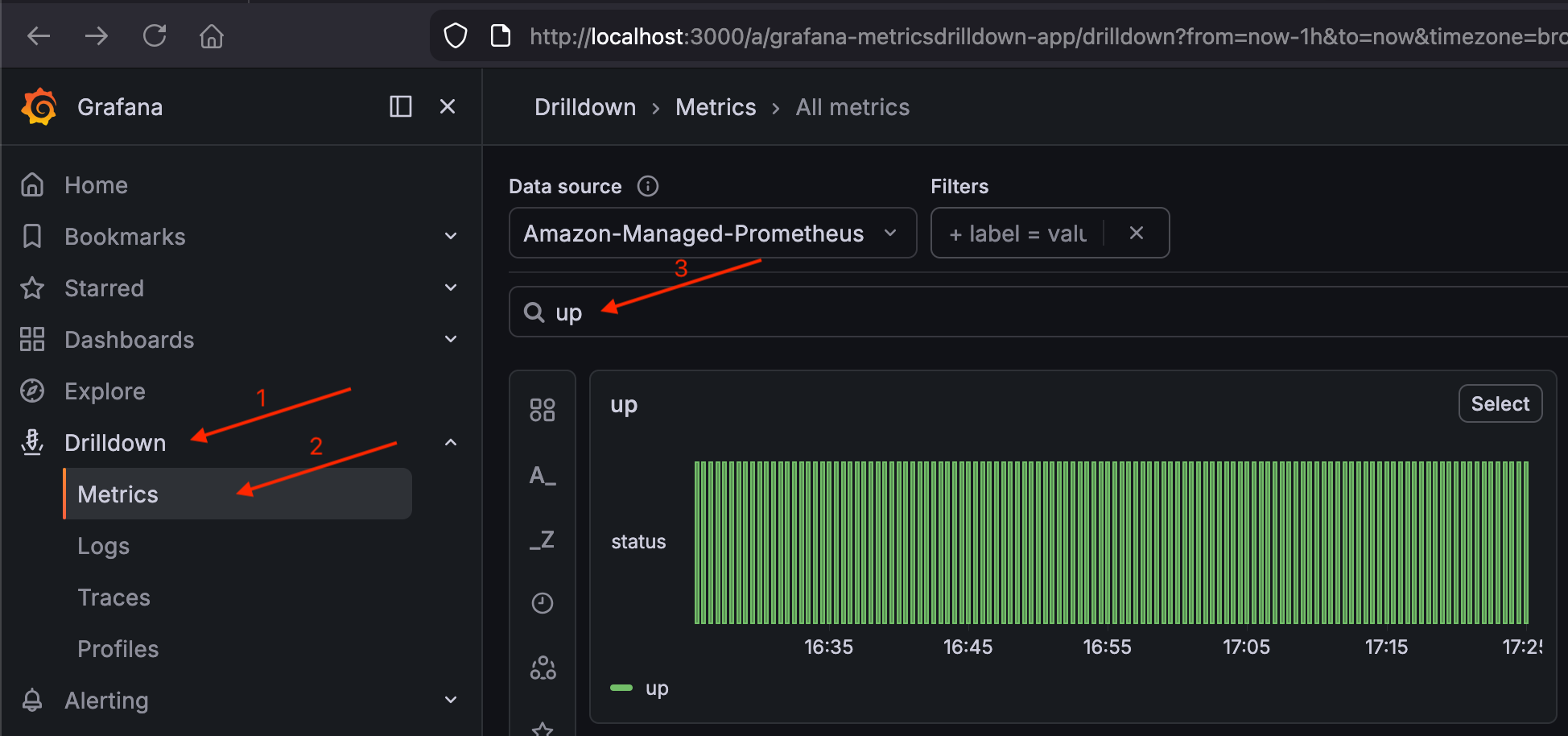
Se up mostra risultati, la pipeline (cluster → Prometheus → AMP → Grafana) funziona.
Implementa DCGM Exporter per le metriche della GPU
Il kube-prometheus-stack raccoglie i parametri della CPU e della memoria a livello di nodo ma non i parametri della GPU. NVIDIA DCGM Exporter aggiunge l'utilizzo della GPU, l'utilizzo della memoria, la temperatura, l'assorbimento di potenza, la larghezza di banda NVLink e l'attività dei tensori.
helm repo add gpu-helm-charts https://nvidia.github.io/dcgm-exporter/helm-charts helm repo update
Imposta la chiave di selezione del nodo GPU per il tuo percorso. EKS Auto Mode e Karpenter autogestito utilizzano chiavi di etichetta diverse per il produttore della GPU.
Crea il file dei valori dell'esportatore DCGM:
Esempio file di valori dcgm-exporter
cat << EOF > /tmp/dcgm-exporter-values.yaml resources: requests: memory: "512Mi" cpu: "100m" limits: memory: "1Gi" cpu: "500m" serviceMonitor: enabled: true additionalLabels: release: kube-prometheus-stack nodeSelector: ${GPU_NODE_SELECTOR_KEY}: nvidia tolerations: - key: "nvidia.com/gpu" operator: "Exists" effect: "NoSchedule" customMetrics: | # Clocks DCGM_FI_DEV_SM_CLOCK, gauge, SM clock frequency (in MHz). DCGM_FI_DEV_MEM_CLOCK, gauge, Memory clock frequency (in MHz). # Temperature DCGM_FI_DEV_MEMORY_TEMP, gauge, Memory temperature (in C). DCGM_FI_DEV_GPU_TEMP, gauge, GPU temperature (in C). # Power DCGM_FI_DEV_POWER_USAGE, gauge, Power draw (in W). DCGM_FI_DEV_TOTAL_ENERGY_CONSUMPTION, counter, Total energy consumption since boot (in mJ). # PCIe DCGM_FI_PROF_PCIE_TX_BYTES, counter, Number of bytes transmitted through PCIe TX (in KB) via NVML. DCGM_FI_PROF_PCIE_RX_BYTES, counter, Number of bytes received through PCIe RX (in KB) via NVML. DCGM_FI_DEV_PCIE_REPLAY_COUNTER, counter, Total number of PCIe retries. # Utilization (the sample period varies depending on the product) DCGM_FI_DEV_GPU_UTIL, gauge, GPU utilization (in %). DCGM_FI_DEV_MEM_COPY_UTIL, gauge, Memory utilization (in %). DCGM_FI_DEV_ENC_UTIL, gauge, Encoder utilization (in %). DCGM_FI_DEV_DEC_UTIL, gauge, Decoder utilization (in %). # Errors and violations DCGM_FI_DEV_XID_ERRORS, gauge, Value of the last XID error encountered. DCGM_EXP_XID_ERRORS_COUNT, gauge, Value of count of XID errors encountered. DCGM_FI_DEV_POWER_VIOLATION, counter, Throttling duration due to power constraints (in us). DCGM_FI_DEV_THERMAL_VIOLATION, counter, Throttling duration due to thermal constraints (in us). DCGM_FI_DEV_SYNC_BOOST_VIOLATION, counter, Throttling duration due to sync-boost constraints (in us). DCGM_FI_DEV_BOARD_LIMIT_VIOLATION, counter, Throttling duration due to board limit constraints (in us). DCGM_FI_DEV_LOW_UTIL_VIOLATION, counter, Throttling duration due to low utilization (in us). DCGM_FI_DEV_RELIABILITY_VIOLATION, counter, Throttling duration due to reliability constraints (in us). # Memory usage DCGM_FI_DEV_FB_FREE, gauge, Framebuffer memory free (in MiB). DCGM_FI_DEV_FB_USED, gauge, Framebuffer memory used (in MiB). # Retired pages DCGM_FI_DEV_RETIRED_SBE, counter, Total number of retired pages due to single-bit errors. DCGM_FI_DEV_RETIRED_DBE, counter, Total number of retired pages due to double-bit errors. DCGM_FI_DEV_RETIRED_PENDING, counter, Total number of pages pending retirement. # NVLink DCGM_FI_DEV_NVLINK_BANDWIDTH_TOTAL, counter, Total number of NVLink bandwidth counters for all lanes. DCGM_FI_PROF_NVLINK_TX_BYTES, counter, The rate of data transmitted over NVLink not including protocol headers in bytes per second. DCGM_FI_PROF_NVLINK_RX_BYTES, counter, The rate of data received over NVLink not including protocol headers in bytes per second. # DCP metrics DCGM_FI_PROF_GR_ENGINE_ACTIVE, gauge, Ratio of time the graphics engine is active (in %). DCGM_FI_PROF_SM_ACTIVE, gauge, The ratio of cycles an SM has at least 1 warp assigned (in %). DCGM_FI_PROF_SM_OCCUPANCY, gauge, The ratio of number of warps resident on an SM (in %). DCGM_FI_PROF_PIPE_TENSOR_ACTIVE, gauge, Ratio of cycles the tensor (HMMA) pipe is active (in %). DCGM_FI_PROF_DRAM_ACTIVE, gauge, Ratio of cycles the device memory interface is active sending or receiving data (in %). DCGM_FI_DEV_CLOCK_THROTTLE_REASONS, gauge, Current clock throttle reasons (bitmask of DCGM_CLOCKS_THROTTLE_REASON_*). DCGM_FI_DEV_GPU_NVLINK_ERRORS, gauge, Identifies a GPU NVLink error type returned by DCGM_FI_DEV_GPU_NVLINK_ERRORS. ## NVLink DCGM_FI_DEV_NVLINK_BANDWIDTH_L0, counter, The number of bytes of active NVLink rx or tx data including both header and payload. ## Remapped rows DCGM_FI_DEV_UNCORRECTABLE_REMAPPED_ROWS, counter, Number of remapped rows for uncorrectable errors. DCGM_FI_DEV_CORRECTABLE_REMAPPED_ROWS, counter, Number of remapped rows for correctable errors. DCGM_FI_DEV_ROW_REMAP_FAILURE, gauge, whether remapping of rows has failed. ## Profiling metrics DCGM_FI_PROF_PIPE_FP64_ACTIVE, gauge, Ratio of cycles the fp64 pipes are active (in %). DCGM_FI_PROF_PIPE_FP32_ACTIVE, gauge, Ratio of cycles the fp32 pipes are active (in %). DCGM_FI_PROF_PIPE_FP16_ACTIVE, gauge, Ratio of cycles the fp16 pipes are active (in %). # ECC DCGM_FI_DEV_ECC_SBE_VOL_TOTAL, counter, Total number of single-bit volatile ECC errors. DCGM_FI_DEV_ECC_DBE_VOL_TOTAL, counter, Total number of double-bit volatile ECC errors. EOF
Il customMetrics campo sostituisce il set di parametri predefinito dell'esportatore DCGM con uno esteso che include la larghezza di banda NVLink, l'attività del tensore, il throughput PCIe, gli errori ECC e la limitazione termica. Per i carichi di lavoro di inferenza, consentono di capire se le unità di calcolo della GPU sono completamente utilizzate, se la GPU è inattiva tra una richiesta e l'altra a causa delle basse dimensioni dei batch, se il trasferimento di dati tra CPU e GPU è un collo di bottiglia, se la limitazione termica causa picchi di latenza e quanto spazio di memoria della GPU rimane per batch più grandi.
Installa l'esportatore DCGM:
helm install dcgm-exporter gpu-helm-charts/dcgm-exporter \ --namespace monitoring \ -f /tmp/dcgm-exporter-values.yaml
Quindi tolerations consenti all'esportatore di funzionare sui GPU-tainted nodi che hai fornito nel passaggio 2. L'serviceMonitorrelease: kube-prometheus-stacketichetta assicura che Prometheus lo scopra e lo cancelli automaticamente.
Verifica l'esportatore DCGM: DaemonSet
kubectl get daemonset dcgm-exporter -n monitoring
Una volta che un nodo GPU è in esecuzione, dovresti vedere un Pod pronto. Per convalidare le metriche DCGM, vai su Drilldown > Metriche in Grafana e cerca. DCGM_
Convalida le metriche DCGM in Grafana
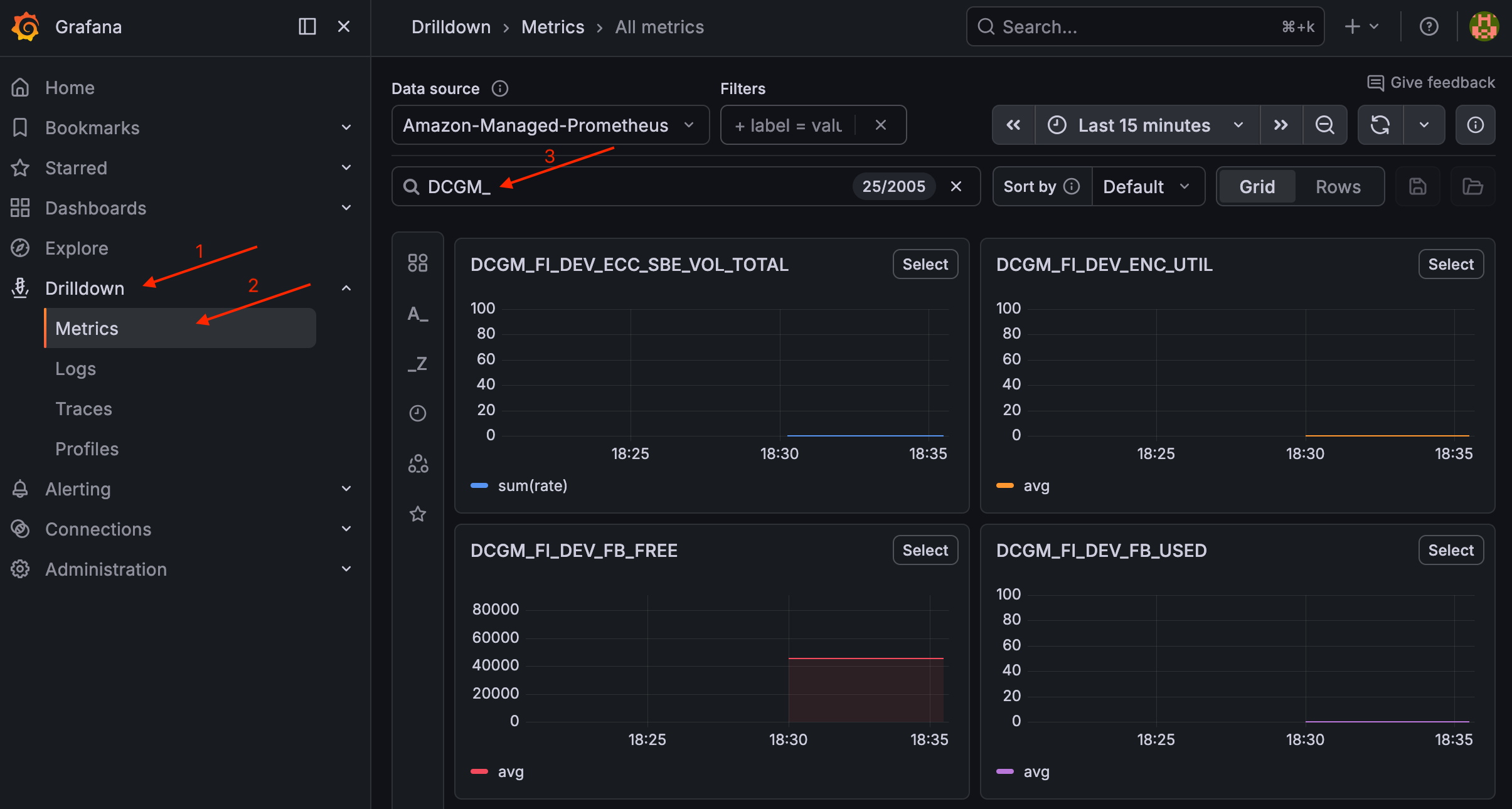
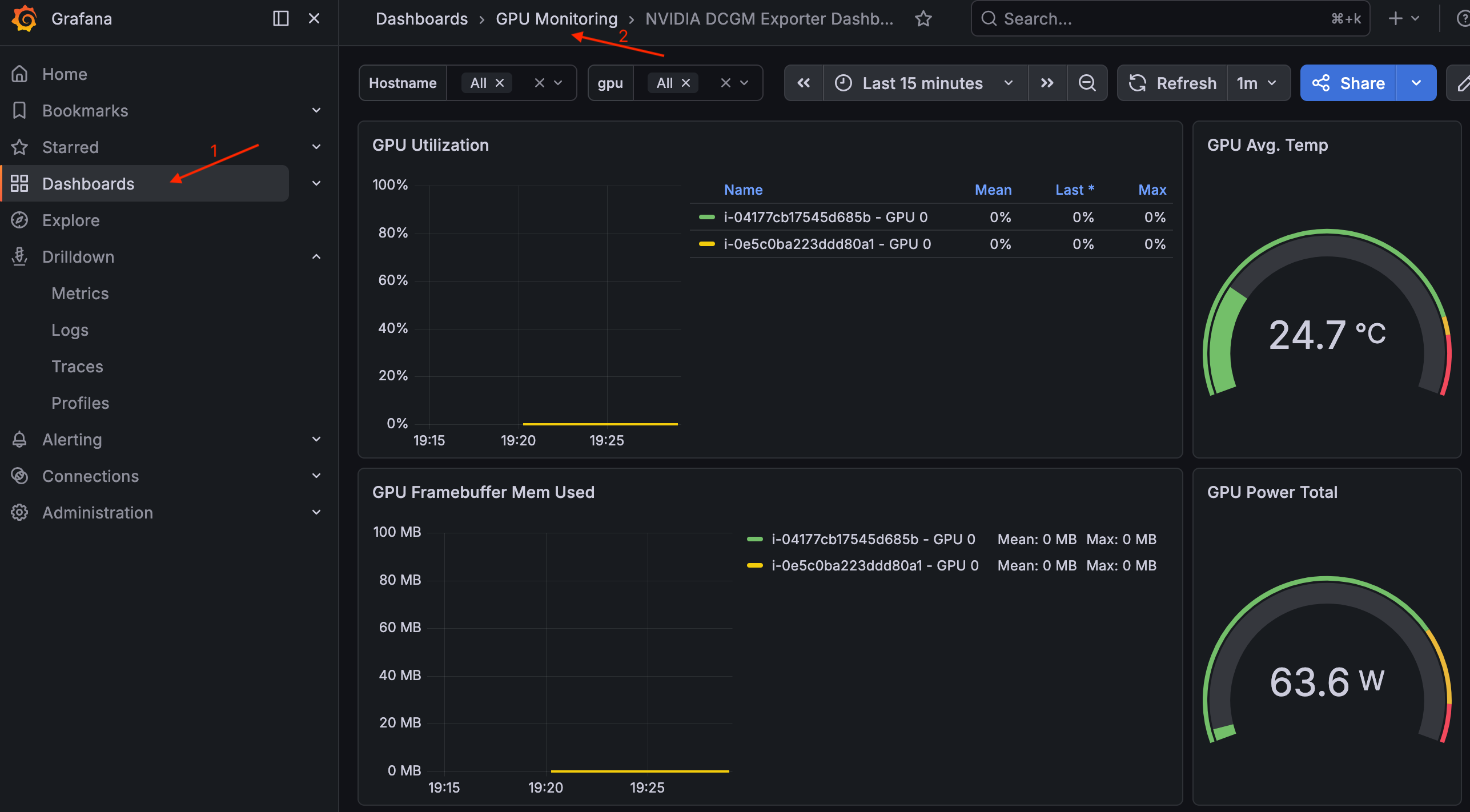
Per visualizzare la dashboard, vai a Dashboard > GPU Monitoring > NVIDIA DCGM Exporter Dashboard.
Dashboard di NVIDIA DCGM Exporter a Grafana
Pesi del modello S3 bucket
Crea un bucket Amazon S3 per archiviare i pesi dei modelli e configura un'EKS Pod Identity Association in modo che i pod del carico di lavoro possano leggerlo e scriverlo.
Se hai aperto un nuovo terminale, imposta il nome e la regione del cluster:
export CLUSTER_NAME=ai-eks-docs export AWS_REGION=us-east-2
Crea il bucket S3
Crea il bucket con un suffisso casuale per evitare collisioni di nomi:
BUCKET_SUFFIX=$(head -c 4 /dev/urandom | od -An -tx1 | tr -d ' \n') MODEL_BUCKET="${CLUSTER_NAME}-models-${BUCKET_SUFFIX}" aws s3 mb s3://${MODEL_BUCKET} --region ${AWS_REGION}
I bucket S3 creati dopo gennaio 2023 hanno la crittografia lato server (AES256) e il blocco dell'accesso pubblico abilitati per impostazione predefinita.
Configura EKS Pod Identity per l'accesso a S3
Crea un model-storage-sa ServiceAccount nel default namespace, una policy IAM relativa al bucket del modello e un'associazione EKS Pod Identity che li colleghi. I pod di carico di lavoro impostati serviceAccountName: model-storage-sa saranno in grado di leggere e scrivere nel bucket.
kubectl create serviceaccount model-storage-sa
Crea la policy IAM:
POLICY_ARN=$(aws iam create-policy \ --policy-name "${CLUSTER_NAME}-model-storage-policy" \ --policy-document "{\"Version\": \"2012-10-17\", \"Statement\": [{\"Effect\": \"Allow\", \"Action\": [\"s3:GetObject\", \"s3:PutObject\", \"s3:ListBucket\", \"s3:DeleteObject\"], \"Resource\": [\"arn:aws:s3:::${MODEL_BUCKET}\", \"arn:aws:s3:::${MODEL_BUCKET}/*\"]}]}" \ --query 'Policy.Arn' \ --output text) echo "Policy ARN: ${POLICY_ARN}"
Nota
Questa politica concede s3:DeleteObject e s3:PutObject per la fase di convalida. Per i pod di inferenza di produzione che leggono solo i pesi dei modelli, s3:PutObject rimuovete e seguite least-privilege. s3:DeleteObject
Crea l'EKS Pod Identity Association. eksctlcrea il ruolo IAM con la politica di fiducia corretta e lo collega a ServiceAccount:
eksctl create podidentityassociation \ --cluster ${CLUSTER_NAME} \ --namespace default \ --service-account-name model-storage-sa \ --role-name "${CLUSTER_NAME}-model-storage-role" \ --permission-policy-arns ${POLICY_ARN} \ --region ${AWS_REGION}
Verifica l'associazione:
eksctl get podidentityassociation --cluster ${CLUSTER_NAME} --region ${AWS_REGION}
L'output dovrebbe includere l'model-storage-saassociazione nel default namespace.
Esegui un Pod singolo con l'immagine AWS CLI, utilizzando model-storage-sa ServiceAccount, per confermare che EKS Pod Identity è cablato e l'accesso S3 funziona:
cat << EOF | kubectl apply -f - apiVersion: v1 kind: Pod metadata: name: s3-test labels: guide: ai-eks-docs spec: serviceAccountName: model-storage-sa containers: - name: aws-cli image: public.ecr.aws/aws-cli/aws-cli:2.27.0 command: - sh - -c - | echo "=== Caller Identity ===" aws sts get-caller-identity echo "" echo "=== S3 Write Test ===" echo "pod identity works" | aws s3 cp - s3://${MODEL_BUCKET}/test.txt echo "" echo "=== S3 List Test ===" aws s3 ls s3://${MODEL_BUCKET}/ echo "" echo "=== S3 Delete Test ===" aws s3 rm s3://${MODEL_BUCKET}/test.txt restartPolicy: Never EOF
Attendi il completamento del Pod e controlla i log:
kubectl wait --for=jsonpath='{.status.phase}'=Succeeded pod/s3-test --timeout=300s kubectl logs s3-test
Output previsto:
=== Caller Identity ===
{
"UserId": "AROA...:eks-ai-eks-docs-model-s-...",
"Account": "123456789012",
"Arn": "arn:aws:sts::123456789012:assumed-role/ai-eks-docs-model-storage-role/eks-ai-eks-docs-model-s-..."
}
=== S3 Write Test ===
upload: - to s3://ai-eks-docs-models-01234567/test.txt
=== S3 List Test ===
2026-05-04 12:00:00 19 test.txt
=== S3 Delete Test ===
delete: s3://ai-eks-docs-models-01234567/test.txtL'identità del chiamante conferma che il Pod ha assunto il ${CLUSTER_NAME}-model-storage-role ruolo tramite EKS Pod Identity. I comandi S3 confermano l'accesso in lettura e scrittura.
Pulisci il test Pod:
kubectl delete pod s3-test
Fasi successive
Con il cluster pronto, puoi passare al modello Load & Serve per implementare un modello linguistico di grandi dimensioni e interagire con l'endpoint di inferenza.
Pulizia
Suggerimento
Se intendi continuare con le sezioni successive di questa guida, salta la pulizia completa. Eseguilo solo quando hai finito.
export CLUSTER_NAME=ai-eks-docs export AWS_REGION=us-east-2
kubectl delete pod nvidia-smi --ignore-not-found kubectl delete deployment gpu-overflow-test --ignore-not-found
Se hai creato un ODCR, annullalo prima. Cerca l'ID della prenotazione:
INSTANCE_TYPE="g6e.4xlarge" CAPACITY_RESERVATION_ID=$(aws ec2 describe-capacity-reservations \ --filters "Name=state,Values=active" "Name=instance-type,Values=${INSTANCE_TYPE}" \ --query 'CapacityReservations[0].CapacityReservationId' \ --output text \ --region ${AWS_REGION}) echo "Capacity reservation ID: ${CAPACITY_RESERVATION_ID}"
Annulla la prenotazione:
aws ec2 cancel-capacity-reservation --capacity-reservation-id ${CAPACITY_RESERVATION_ID}
Importante
L'annullamento di una prenotazione non interrompe le istanze in esecuzione. Continuano alle On-Demand tariffe standard fino alla loro cessazione. Elimina prima la distribuzione per svuotare il nodo riservato prima di annullarla.
Cerca l'ARN della policy IAM:
AMP_POLICY_ARN=$(aws iam list-policies \ --scope Local \ --query "Policies[?PolicyName=='${CLUSTER_NAME}-amp-grafana-policy'].Arn" \ --output text) echo "AMP Policy ARN: ${AMP_POLICY_ARN}"
Cerca l'ID dell'area di lavoro AMP:
AMP_WORKSPACE_ID=$(aws amp list-workspaces \ --alias "amp-ws-${CLUSTER_NAME}" \ --query 'workspaces[0].workspaceId' \ --output text \ --region ${AWS_REGION}) echo "AMP Workspace ID: ${AMP_WORKSPACE_ID}"
Disinstalla la versione Helm dell'esportatore DCGM:
helm uninstall dcgm-exporter -n monitoring
Disinstalla la versione kube-prometheus-stack Helm:
helm uninstall kube-prometheus-stack -n monitoring
Elimina l'associazione EKS Pod Identity per l'account del servizio di ingest Prometheus:
eksctl delete podidentityassociation \ --cluster ${CLUSTER_NAME} \ --namespace monitoring \ --service-account-name amp-iamproxy-ingest-service-account \ --region ${AWS_REGION}
Eliminare l'associazione EKS Pod Identity per l'account del servizio Grafana:
eksctl delete podidentityassociation \ --cluster ${CLUSTER_NAME} \ --namespace monitoring \ --service-account-name grafana-sa \ --region ${AWS_REGION}
Elimina la policy IAM utilizzata da Prometheus e Grafana:
aws iam delete-policy --policy-arn ${AMP_POLICY_ARN}
Elimina l'area di lavoro AMP:
aws amp delete-workspace --workspace-id ${AMP_WORKSPACE_ID} --region ${AWS_REGION}
Elimina lo spazio dei nomi di monitoraggio:
kubectl delete namespace monitoring
Cerca il nome del bucket del modello:
MODEL_BUCKET=$(aws s3api list-buckets \ --query "Buckets[?starts_with(Name, '${CLUSTER_NAME}-models-')].Name | [0]" \ --output text) echo "Model bucket: ${MODEL_BUCKET}"
Cerca l'ARN della policy IAM:
POLICY_ARN=$(aws iam list-policies \ --scope Local \ --query "Policies[?PolicyName=='${CLUSTER_NAME}-model-storage-policy'].Arn" \ --output text) echo "Policy ARN: ${POLICY_ARN}"
Elimina il bucket del modello S3 e tutti i suoi oggetti:
aws s3 rb s3://${MODEL_BUCKET} --force
Eliminare l'associazione EKS Pod Identity:
eksctl delete podidentityassociation \ --cluster ${CLUSTER_NAME} \ --namespace default \ --service-account-name model-storage-sa \ --region ${AWS_REGION}
Elimina la politica IAM:
aws iam delete-policy --policy-arn ${POLICY_ARN}
Elimina Kubernetes: ServiceAccount
kubectl delete serviceaccount model-storage-sa
kubectl delete nodepool gpu-inf --ignore-not-found kubectl delete nodeclass gpu-inf --ignore-not-found kubectl delete ec2nodeclass gpu-inf --ignore-not-found eksctl delete cluster --name=$CLUSTER_NAME --region=$AWS_REGION
