Contribuisci a migliorare questa pagina
Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Per contribuire a questa guida per l'utente, scegli il GitHub link Modifica questa pagina nel riquadro destro di ogni pagina.
Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Concetti di Kubernetes per nodi ibridi
Questa pagina descrive in dettaglio i concetti chiave di Kubernetes alla base dell’architettura di sistema dei nodi ibridi EKS.
Piano di controllo EKS nel VPC
Gli IP del piano di controllo EKS ENI sono memorizzati nell’oggetto kubernetes Endpoints nel namespace default. Quando EKS crea nuovi ENI o rimuove quelli più vecchi, EKS aggiorna questo oggetto in modo che l’elenco degli IP sia sempre aggiornato.
È possibile utilizzare questi endpoint tramite il Servizio kubernetes, anche nel namespace default. A questo servizio, di tipo ClusterIP, viene sempre assegnato il primo IP del servizio CIDR del cluster. Ad esempio, per il servizio CIDR 172.16.0.0/16, l’IP del servizio sarà 172.16.0.1.
In genere, questo è il modo in cui i pod (indipendentemente dal fatto che siano in esecuzione nel cloud o nei nodi ibridi) accedono al server API EKS Kubernetes. I pod utilizzano l’IP del servizio come IP di destinazione, che viene tradotto negli IP effettivi di uno degli ENI del piano di controllo EKS. L’eccezione principale è kube-proxy, perché imposta la traduzione.
Endpoint del server API EKS
L’IP del servizio kubernetes non è l’unico modo per accedere al server API EKS. EKS crea anche un nome DNS Route53 quando si crea il cluster. Questo è il campo endpoint del cluster EKS quando si richiama l’azione dell’API EKS DescribeCluster.
{ "cluster": { "endpoint": "https://xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx.gr7.us-west-2.eks.amazonaws.com", "name": "my-cluster", "status": "ACTIVE" } }
In un cluster di accesso pubblico agli endpoint o in uno di accesso pubblico e privato agli endpoint, i nodi ibridi risolveranno questo nome DNS in un IP pubblico per impostazione predefinita, instradabile tramite Internet. In un cluster privato di accesso agli endpoint, il nome DNS si risolve negli IP privati del piano di controllo EKS ENI.
Ecco come kubelet e kube-proxy accedono al server dell’API Kubernetes. Se desideri che tutto il traffico del cluster Kubernetes fluisca attraverso il VPC, devi configurare il cluster in modalità di accesso privato o modificare il server DNS on-premises per risolvere l’endpoint del cluster EKS sugli IP privati del piano di controllo EKS ENI.
Endpoint kubelet
Il kubelet espone diversi endpoint REST, consentendo ad altre parti del sistema di interagire e raccogliere informazioni da ciascun nodo. Nella maggior parte dei cluster, la maggior parte del traffico diretto al server kubelet proviene dal piano di controllo, ma anche alcuni agenti di monitoraggio potrebbero interagire con esso.
Tramite questa interfaccia, kubelet gestisce varie richieste: recupero dei log (kubectl logs), esecuzione di comandi all’interno dei container (kubectl exec) e inoltro del traffico (kubectl port-forward). Ognuna di queste richieste interagisce con il runtime del container sottostante attraverso il kubelet, risultando perfetta per gli amministratori e gli sviluppatori del cluster.
Il consumatore più comune di questa API è il server API Kubernetes. Quando utilizzi uno dei comandi kubectl menzionati in precedenza, kubectl invia una richiesta API al server API, che quindi chiama l’API kubelet del nodo su cui è in esecuzione il pod. Questo è il motivo principale per cui l’IP del nodo deve essere raggiungibile dal piano di controllo EKS e perché, anche se i pod sono in funzione, non sarà possibile accedere ai loro log o exec se il percorso del nodo non è configurato correttamente.
IP del nodo
Quando il piano di controllo EKS comunica con un nodo, utilizza uno degli indirizzi riportati nello stato dell’oggetto Node (status.addresses).
Con i nodi cloud EKS, è normale che il kubelet riporti l’IP privato dell’istanza EC2 come un InternalIP durante la registrazione del nodo. Questo IP viene quindi convalidato dal Cloud Controller Manager (CCM) assicurandosi che appartenga all’istanza EC2. Inoltre, il CCM in genere aggiunge gli IP (come ExternalIP) pubblici e i nomi DNS (InternalDNSe ExternalDNS) dell’istanza allo stato del nodo.
Tuttavia, non esiste un CCM per i nodi ibridi. Quando si registra un nodo ibrido con EKS Hybrid Nodes CLI (nodeadm), configura il kubelet per riportare l’IP della macchina direttamente nello stato del nodo, senza CCM.
apiVersion: v1 kind: Node metadata: name: my-node-1 spec: providerID: eks-hybrid:///us-west-2/my-cluster/my-node-1 status: addresses: - address: 10.1.1.236 type: InternalIP - address: my-node-1 type: Hostname
Se la macchina ha più IP, il kubelet ne selezionerà uno seguendo la propria logica. Puoi controllare l’IP selezionato con il flag --node-ip, che puoi passare in configurazione nodeadm in spec.kubelet.flags. Solo l’IP riportato nell’oggetto Node necessita di un percorso dal VPC. Le tue macchine possono avere altri IP che non sono raggiungibili dal cloud.
kube-proxy
kube-proxy è responsabile dell’implementazione dell’astrazione del servizio a livello di rete di ciascun nodo. Funziona come proxy di rete e bilanciatore del carico per il traffico destinato ai servizi Kubernetes. Monitorando continuamente il server API Kubernetes per rilevare eventuali modifiche relative ai servizi e agli endpoint, kube-proxy aggiorna dinamicamente le regole di rete dell’host sottostante per garantire che il traffico venga indirizzato correttamente.
In modalità iptables, kube-proxy programma diverse catene netfilter per gestire il traffico di servizio. Le regole formano la seguente gerarchia:
-
Catena KUBE-SERVICES: il punto di ingresso per tutto il traffico di servizio. Ha regole che corrispondono a ogni
ClusterIPe porta del servizio. -
Catene KUBE-SVC-XXX: le catene specifiche dei servizi hanno regole di bilanciamento del carico per ogni servizio.
-
Catene KUBE-SEP-XXX: le catene specifiche per endpoint hanno le regole effettive.
DNAT
Esaminiamo cosa succede per un servizio test-server nel namespace default: * Service ClusterIP: 172.16.31.14 * Service port: 80 * Backing pods: 10.2.0.110, 10.2.1.39, e 10.2.2.254
Quando controlliamo le regole iptables (usando iptables-save –0— grep -A10 KUBE-SERVICES):
-
Nella catena KUBE-SERVICES, troviamo una regola corrispondente al servizio:
-A KUBE-SERVICES -d 172.16.31.14/32 -p tcp -m comment --comment "default/test-server cluster IP" -m tcp --dport 80 -j KUBE-SVC-XYZABC123456-
Questa regola corrisponde ai pacchetti destinati a 172.16.31.14:80
-
Il commento indica a cosa serve questa regola:
default/test-server cluster IP -
I pacchetti corrispondenti saltano alla catena
KUBE-SVC-XYZABC123456
-
-
La catena KUBE-SVC-XYZABC123456 ha regole di bilanciamento del carico basate sulla probabilità:
-A KUBE-SVC-XYZABC123456 -m statistic --mode random --probability 0.33333333349 -j KUBE-SEP-POD1XYZABC -A KUBE-SVC-XYZABC123456 -m statistic --mode random --probability 0.50000000000 -j KUBE-SEP-POD2XYZABC -A KUBE-SVC-XYZABC123456 -j KUBE-SEP-POD3XYZABC-
Prima regola: 33,3% di probabilità di saltare a
KUBE-SEP-POD1XYZABC -
Seconda regola: 50% di probabilità che il traffico rimanente (33,3% del totale) passi a
KUBE-SEP-POD2XYZABC -
Ultima regola: tutto il traffico rimanente (33,3% del totale) passa a
KUBE-SEP-POD3XYZABC
-
-
Le singole catene KUBE-SEP-XXX eseguono il DNAT (Destination NAT):
-A KUBE-SEP-POD1XYZABC -p tcp -m tcp -j DNAT --to-destination 10.2.0.110:80 -A KUBE-SEP-POD2XYZABC -p tcp -m tcp -j DNAT --to-destination 10.2.1.39:80 -A KUBE-SEP-POD3XYZABC -p tcp -m tcp -j DNAT --to-destination 10.2.2.254:80-
Queste regole DNAT riscrivono l’IP e la porta di destinazione per indirizzare il traffico verso pod specifici.
-
Ogni regola gestisce circa il 33,3% del traffico, garantendo un bilanciamento uniforme del carico tra
10.2.0.110,10.2.1.39e10.2.2.254.
-
Questa struttura a catena a più livelli consente a kube-proxy di implementare in modo efficiente il bilanciamento e il reindirizzamento del carico di servizio mediante la manipolazione dei pacchetti a livello di kernel, senza richiedere un processo proxy nel percorso dei dati.
Impatto sulle operazioni di Kubernetes
Un’interruzione kube-proxy su un nodo impedisce a quel nodo di indirizzare correttamente il traffico del Servizio, causando timeout o connessioni non riuscite per i pod che si basano sui servizi del cluster. Ciò può essere particolarmente problematico quando un nodo viene registrato per la prima volta. Il CNI deve comunicare con il server dell’API Kubernetes per ottenere informazioni, come il pod CIDR del nodo, prima di poter configurare qualsiasi rete di pod. A tale scopo, utilizza l’IP del servizio kubernetes. Tuttavia, se kube-proxy non è riuscito ad avviarlo o a impostare le regole iptables corrette, le richieste inviate all’IP del servizio kubernetes non vengono tradotte negli IP effettivi degli ENI del piano di controllo EKS. Di conseguenza, il CNI entrerà in un ciclo di arresto e nessuno dei pod sarà in grado di funzionare correttamente.
Sappiamo che i pod utilizzano l’IP del servizio kubernetes per comunicare con il server dell’API Kubernetes, ma kube-proxy deve prima impostare le regole iptables per farlo funzionare.
Come kube-proxy comunica con il server API?
kube-proxy deve essere configurato per utilizzare gli IP/s effettivi del server dell’API Kubernetes o un nome DNS che li risolva. Nel caso di EKS, EKS configura il predefinito kube-proxy in modo che punti al nome DNS Route53 creato da EKS quando si crea il cluster. Puoi vedere questo valore nella ConfigMap kube-proxy nel namespace kube-system. Il contenuto di questa ConfigMap è un kubeconfig che viene iniettato nel pod kube-proxy, quindi cerca il campo clusters–0—.cluster.server. Questo valore corrisponderà al campo endpoint del cluster EKS (quando chiama l’API DescribeCluster di EKS).
apiVersion: v1 data: kubeconfig: |- kind: Config apiVersion: v1 clusters: - cluster: certificate-authority: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt server: https://xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx.gr7.us-west-2.eks.amazonaws.com name: default contexts: - context: cluster: default namespace: default user: default name: default current-context: default users: - name: default user: tokenFile: /var/run/secrets/kubernetes.io/serviceaccount/token kind: ConfigMap metadata: name: kube-proxy namespace: kube-system
CIDR dei pod remoti instradabili
La pagina Concetti di rete per nodi ibridi descrive in dettaglio i requisiti per eseguire webhook su nodi ibridi o per far sì che i pod in esecuzione su nodi cloud comunichino con quelli in esecuzione su nodi ibridi. Il requisito fondamentale è che il router on-premises debba sapere quale nodo è responsabile di un particolare pod IP. Esistono diversi modi per raggiungere questo obiettivo, tra cui Border Gateway Protocol (BGP), route statiche e proxy ARP (Address Resolution Protocol). Le diverse fasi vengono illustrate nelle sezioni seguenti.
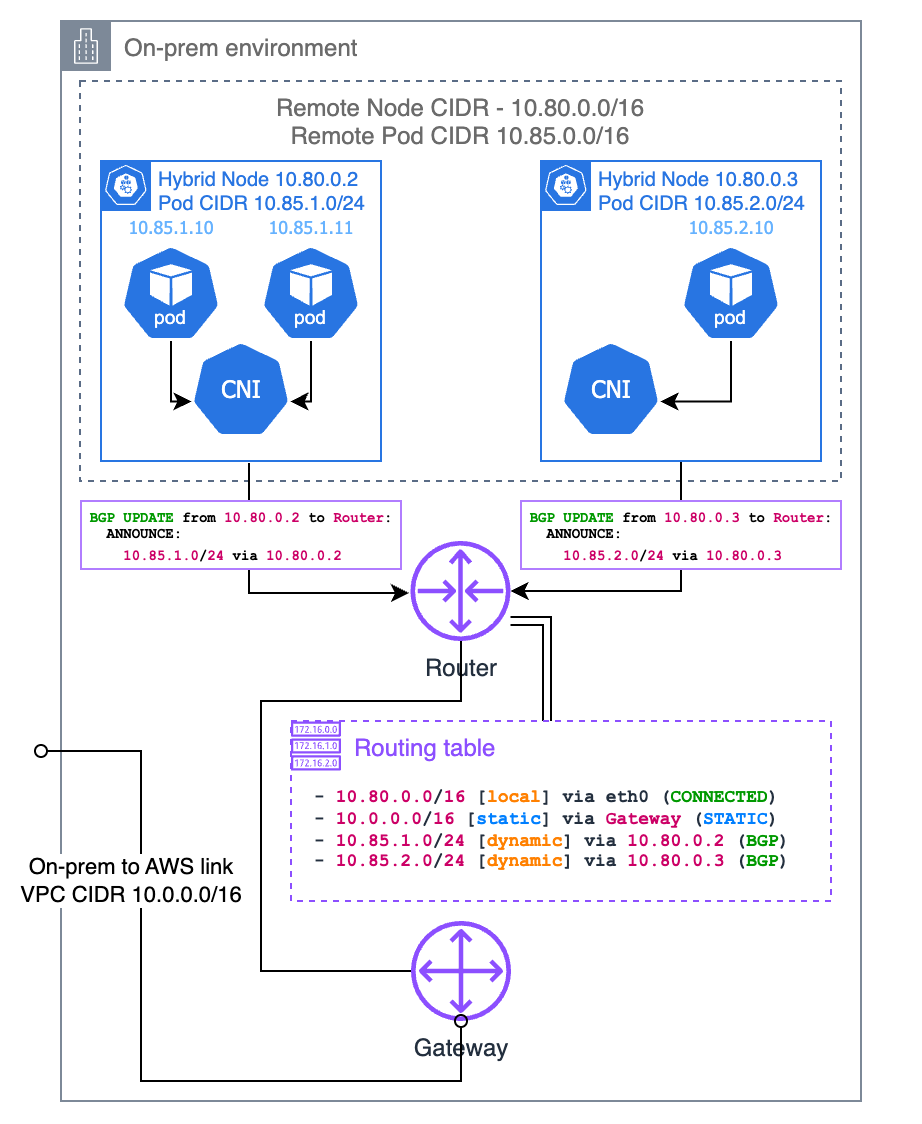
Border Gateway Protocol (BGP)
Se il tuo CNI lo supporta (come Cilium e Calico), puoi utilizzare la modalità BGP del tuo CNI per propagare le route ai tuoi pod CIDR per nodo dai nodi al router locale. Quando si utilizza la modalità BGP del CNI, quest’ultimo funge da router virtuale, quindi il router locale ritiene che il pod CIDR appartenga a una sottorete diversa e il nodo sia il gateway di accesso a quella sottorete.
Route statiche
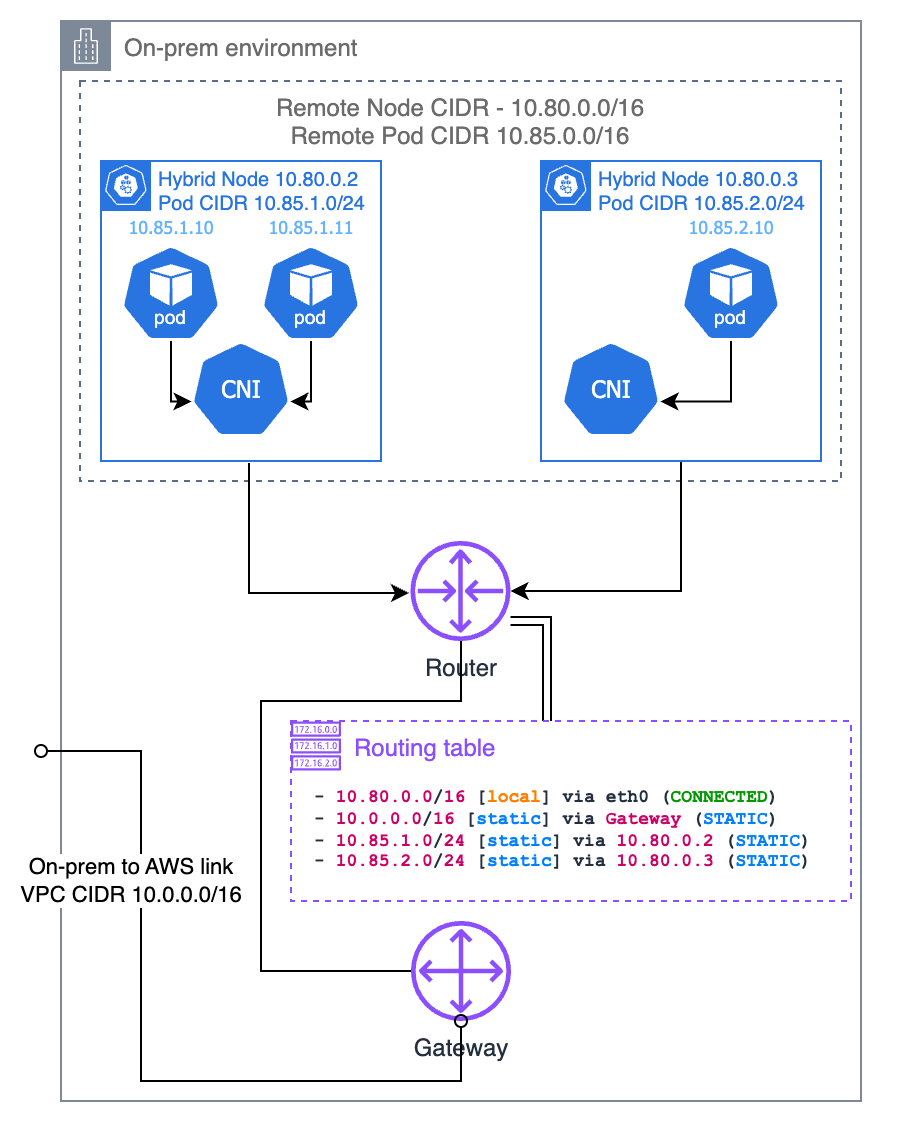
In alternativa, puoi configurare percorsi statici nel router locale. Questo è il modo più semplice per indirizzare il pod CIDR on-premises al tuo VPC, ma è anche il più soggetto a errori e difficile da gestire. È necessario assicurarsi che i percorsi siano sempre aggiornati con i nodi esistenti e i pod CIDR a loro assegnati. Se il numero di nodi è ridotto e l’infrastruttura è statica, questa è un’opzione valida e elimina la necessità del supporto BGP nel router. Se scegli questa opzione, ti consigliamo di configurare il tuo CNI con la slice CIDR del pod che desideri assegnare a ciascun nodo invece di lasciare che sia l’IPAM a decidere.
Proxy ARP (Address Resolution Protocol)
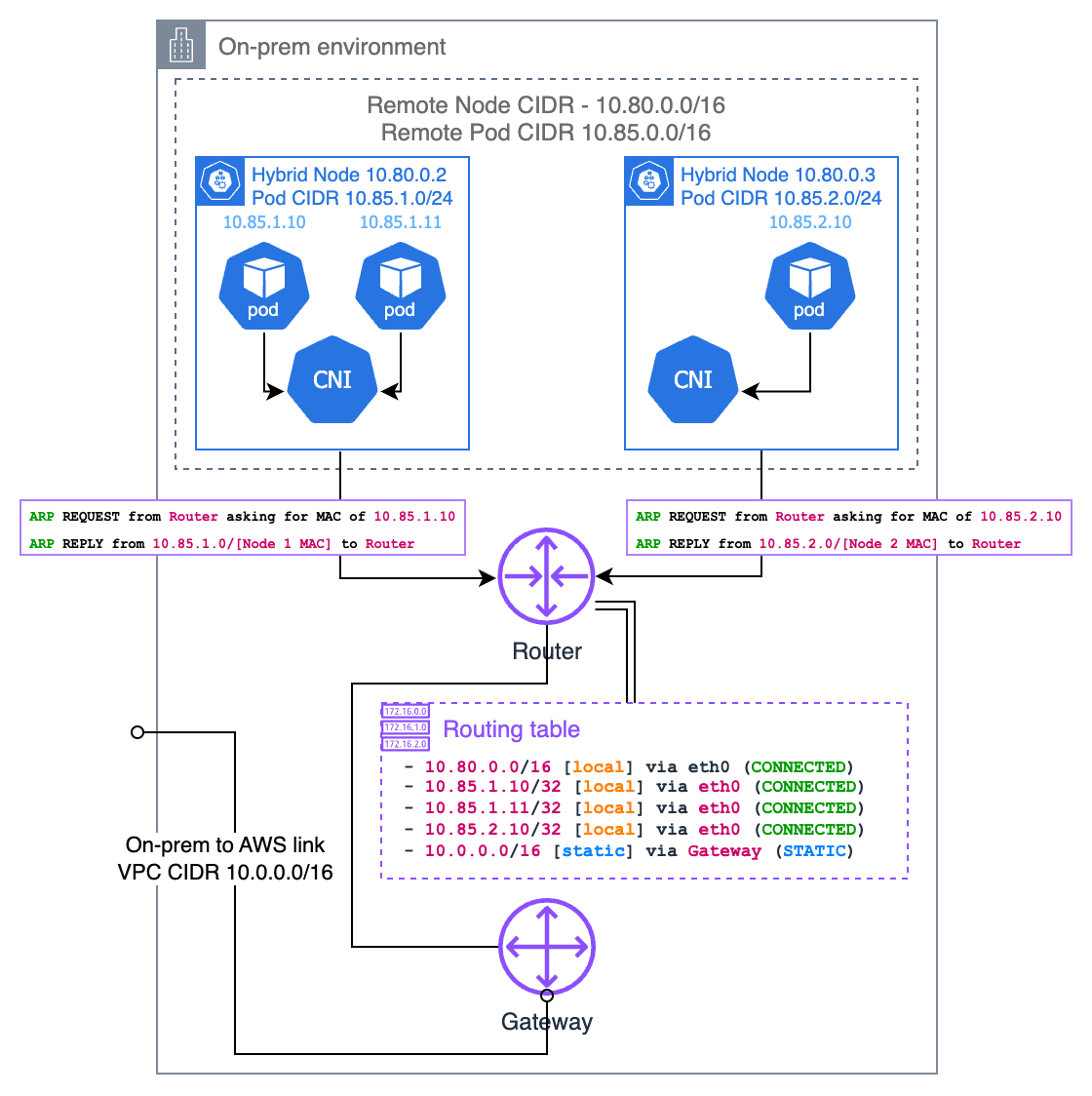
Il proxy ARP è un altro approccio per rendere instradabili gli IP dei on-premises, particolarmente utile quando i nodi ibridi si trovano sulla stessa rete di livello 2 del router locale. Con il proxy ARP abilitato, un nodo risponde alle richieste ARP per gli IP dei pod che ospita, anche se tali IP appartengono a una sottorete diversa.
Quando un dispositivo sulla rete locale tenta di raggiungere un pod IP, invia innanzitutto una richiesta ARP che chiede “Chi ha questo IP?”. Il nodo ibrido che ospita il pod risponderà con il proprio indirizzo MAC, dicendo “Posso gestire il traffico per quell’IP”. Questo crea un percorso diretto tra i dispositivi della rete locale e i pod senza richiedere la configurazione del router.
Perché ciò funzioni, il CNI deve supportare la funzionalità proxy ARP. Cilium ha un supporto integrato per il proxy ARP che puoi abilitare tramite la configurazione. La considerazione fondamentale è che il pod CIDR non deve sovrapporsi a nessun’altra rete dell’ambiente, poiché ciò potrebbe causare conflitti di routing.
Questo approccio presenta diversi vantaggi: * Non è necessario configurare il router con BGP o mantenere percorsi statici * Funziona bene in ambienti in cui non si ha il controllo sulla configurazione del router
Incapsulamento da pod a pod
Negli ambienti on-premises, i CNI utilizzano in genere protocolli di incapsulamento per creare reti overlay in grado di funzionare sulla rete fisica senza la necessità di riconfigurarla. Questa sezione spiega come funziona questo incapsulamento. Tieni presente che alcuni dettagli potrebbero variare a seconda del CNI che stai utilizzando.
L’incapsulamento avvolge i pacchetti della rete di pod originali all’interno di un altro pacchetto di rete che può essere instradato attraverso la rete fisica sottostante. Ciò consente ai pod di comunicare tra i nodi che eseguono lo stesso CNI senza che la rete fisica sappia come instradare quei pod CIDR.
Il protocollo di incapsulamento più comune utilizzato con Kubernetes è Virtual Extensible LAN (VXLAN), sebbene siano disponibili anche altri (come Geneve) a seconda del CNI utilizzato.
Incapsulamento VXLAN
VXLAN incapsula i frame Ethernet di livello 2 all’interno di pacchetti UDP. Quando un pod invia traffico a un altro pod su un nodo diverso, il CNI esegue le seguenti operazioni:
-
Il CNI intercetta i pacchetti dal Pod A.
-
Il CNI avvolge il pacchetto originale in un’intestazione VXLAN.
-
Questo pacchetto avvolto viene quindi inviato attraverso lo stack di rete normale del nodo al nodo di destinazione.
-
Il CNI sul nodo di destinazione scarta il pacchetto e lo consegna al Pod B.
Ecco cosa succede alla struttura dei pacchetti durante l’incapsulamento VXLAN:
Pacchetto originale da pod a pod:
+-----------------+---------------+-------------+-----------------+ | Ethernet Header | IP Header | TCP/UDP | Payload | | Src: Pod A MAC | Src: Pod A IP | Src Port | | | Dst: Pod B MAC | Dst: Pod B IP | Dst Port | | +-----------------+---------------+-------------+-----------------+
Dopo l’incapsulamento VXLAN
+-----------------+-------------+--------------+------------+---------------------------+ | Outer Ethernet | Outer IP | Outer UDP | VXLAN | Original Pod-to-Pod | | Src: Node A MAC | Src: Node A | Src: Random | VNI: xx | Packet (unchanged | | Dst: Node B MAC | Dst: Node B | Dst: 4789 | | from above) | +-----------------+-------------+--------------+------------+---------------------------+
Il VXLAN Network Identifier (VNI) distingue tra diverse reti di sovrapposizione.
Scenari di comunicazione dei pod
Pod sullo stesso nodo ibrido
Quando i pod sullo stesso nodo ibrido comunicano, in genere non è necessario alcun incapsulamento. Il CNI imposta percorsi locali che indirizzano il traffico tra i pod attraverso le interfacce virtuali interne del nodo:
Pod A -> veth0 -> node's bridge/routing table -> veth1 -> Pod B
Il pacchetto non lascia mai il nodo e non richiede l’incapsulamento.
Pod su diversi nodi ibridi
La comunicazione tra pod su diversi nodi ibridi richiede l’incapsulamento:
Pod A -> CNI -> [VXLAN encapsulation] -> Node A network -> router or gateway -> Node B network -> [VXLAN decapsulation] -> CNI -> Pod B
Ciò consente al traffico dei pod di attraversare l’infrastruttura di rete fisica senza che la rete fisica comprenda il routing IP dei pod.
