Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Scelta di un servizio di AWS analisi
Fare il primo passo
|
Scopo
|
Aiutaci a determinare quali servizi di AWS analisi sono più adatti alla tua organizzazione.
|
|
Ultimo aggiornamento
|
24 settembre 2025
|
|
Servizi coperti
|
|
Introduzione
I dati sono fondamentali per il business moderno. Le persone e le applicazioni devono accedere e analizzare in modo sicuro i dati, che provengono da fonti nuove e diverse. Inoltre, il volume dei dati è in costante aumento, il che può causare difficoltà alle organizzazioni nell'acquisizione, archiviazione e analisi di tutti i dati necessari.
Affrontare queste sfide significa creare un'architettura di dati moderna che abbatta tutti i silos di dati per analisi e approfondimenti, compresi i dati di terze parti, e li renda accessibili a tutti i membri dell'organizzazione, in un unico posto e con governance. end-to-end Inoltre, è sempre più importante collegare i sistemi di analisi e machine learning (ML) per consentire l'analisi predittiva.
Questa guida decisionale ti aiuta a porre le domande giuste per costruire la tua moderna architettura di dati sui AWS servizi. Spiega come scomporre i silos di dati (collegando il data lake e i data warehouse), i silos di sistema (collegando ML e analisi) e i silos di persone (mettendo i dati nelle mani di tutti i membri dell'organizzazione).
Comprendi i AWS servizi di analisi
Una moderna strategia dei dati è costruita con una serie di elementi tecnologici che ti aiutano a gestire, accedere, analizzare e agire sui dati. Offre inoltre diverse opzioni per la connessione alle fonti di dati. Una moderna strategia di gestione dei dati dovrebbe consentire ai team di:
-
Usa gli strumenti o le tecniche che preferisci
-
Usa l'intelligenza artificiale (AI) per aiutarti a trovare risposte a domande specifiche sui tuoi dati
-
Gestisci chi ha accesso ai dati con i controlli adeguati di sicurezza e governance dei dati
-
Abbatti i silos di dati per offrirti il meglio sia dai data lake che dagli archivi di dati creati appositamente
-
Archivia qualsiasi quantità di dati, a basso costo e in formati di dati aperti e basati su standard
-
Connect data lake, data warehouse, database operativi, applicazioni e fonti di dati federate in un insieme coerente
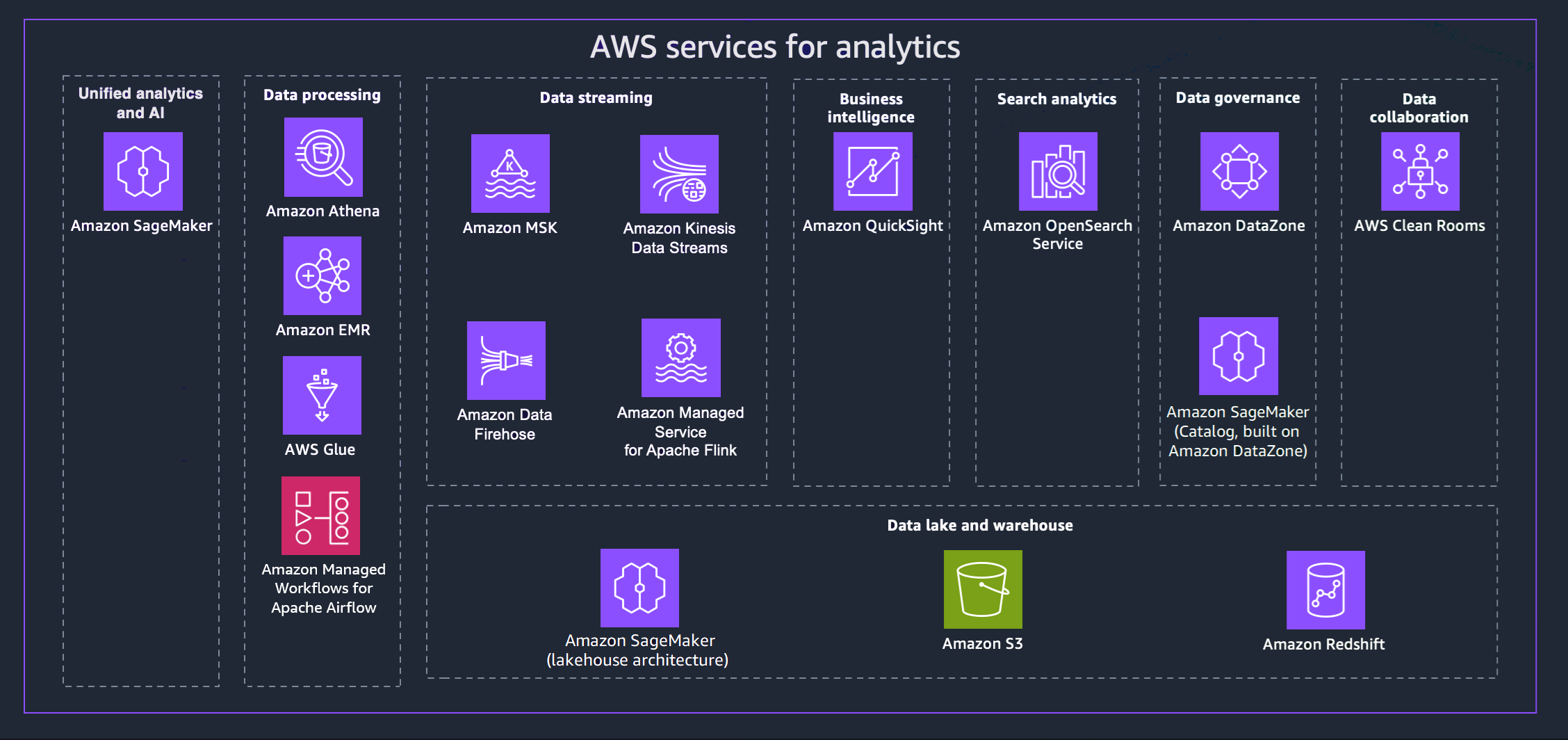
AWS offre una varietà di servizi per aiutarti a realizzare una strategia di dati moderna. Il diagramma seguente illustra i AWS servizi di analisi coperti da questa guida. Le schede che seguono forniscono dettagli aggiuntivi.
- Unified analytics and AI
-
La nuova generazione di Amazon SageMaker combina funzionalità di AWS machine learning (ML) e analisi ampiamente adottate per offrire un'esperienza integrata per l'analisi e l'intelligenza artificiale, fornendo un accesso unificato a tutti i tuoi dati. Con Amazon SageMaker Unified Studio, puoi collaborare e creare più velocemente con AWS strumenti familiari per lo sviluppo di modelli, lo sviluppo di applicazioni AI generative, l'elaborazione dei dati e l'analisi SQL, il tutto accelerato da Amazon Q Developer, il nostro assistente generativo di intelligenza artificiale per lo sviluppo di software. Accedi ai tuoi dati da data lake, data warehouse o fonti terze e federate, con una governance integrata per soddisfare i requisiti di sicurezza aziendali.
- Data processing
-
-
Amazon Athena ti aiuta ad analizzare dati non strutturati, semistrutturati e strutturati archiviati in Amazon S3. Tra gli esempi figurano CSV, JSON o formati di dati colonnari come Apache Parquet e Apache ORC. È possibile usare Athena per eseguire query ad-hoc con ANSI SQL, senza la necessità di aggregare o caricare i dati in Athena. Athena si integra con Quick Suite e altri AWS Glue Data Catalog servizi. AWS Puoi anche analizzare i dati su larga scala con Trino, senza dover gestire l'infrastruttura, e creare analisi in tempo reale utilizzando Apache Flink e Apache Spark.
-
Amazon EMR è una piattaforma cluster gestita che semplifica l'esecuzione di framework di big data, come Apache Hadoop e Apache Spark, per elaborare e analizzare grandi quantità di dati. AWS Utilizzando questi framework e i relativi progetti open source, è possibile elaborare i dati per scopi di analisi e carichi di lavoro di business intelligence. Amazon EMR consente inoltre di trasformare e spostare grandi quantità di dati da e verso altri archivi di AWS dati e database, come Amazon S3.
-
Con AWS Glue, puoi scoprire e connetterti a più di 100 fonti di dati diverse e gestire i tuoi dati in un catalogo di dati centralizzato. Puoi creare, eseguire e monitorare visivamente le pipeline ETL per caricare i dati nei tuoi data lake. Inoltre, puoi cercare e interrogare immediatamente i dati catalogati utilizzando Athena, Amazon EMR e Amazon Redshift Spectrum.
-
Amazon Managed Workflows for Apache Airflow (MWAA) è un'implementazione completamente gestita di Apache Airflow che semplifica la creazione, la pianificazione e il monitoraggio dei flussi di lavoro di dati nel cloud. MWAA ridimensiona automaticamente la capacità del flusso di lavoro per soddisfare le tue esigenze e si integra con i servizi di sicurezza. AWS
Puoi utilizzare MWAA per orchestrare i flussi di lavoro tra i tuoi servizi di analisi, tra cui l'elaborazione dei dati, i lavori ETL e le pipeline di apprendimento automatico.
- Data streaming
-
Con Amazon Managed Streaming for Apache Kafka (Amazon MSK), puoi creare ed eseguire applicazioni che utilizzano Apache Kafka per elaborare dati di streaming. Amazon MSK fornisce le operazioni del piano di controllo, ad esempio quelle per la creazione, l'aggiornamento e l'eliminazione di cluster. Consente di utilizzare operazioni del piano dati Apache Kafka, come quelle per la produzione e il consumo di dati.
Con Amazon Kinesis Data Streams, puoi raccogliere ed elaborare grandi flussi di record di dati in tempo reale. Il tipo di dati utilizzato può includere dati di logo dell'infrastruttura IT, log di applicazioni, social media, feed di dati di mercato e dati clickstream Web.
Amazon Data Firehose è un servizio completamente gestito per la distribuzione di dati di streaming in tempo reale a destinazioni come Amazon S3, Amazon Redshift, OpenSearch Amazon Service, Splunk e Apache Iceberg Tables. Puoi anche inviare dati a qualsiasi endpoint HTTP personalizzato o endpoint HTTP di proprietà di fornitori di servizi terzi supportati, tra cui Datadog, Dynatrace, MongoDB, New Relic LogicMonitor, Coralogix ed Elastic.
Con Amazon Managed Service for Apache Flink, puoi usare Java, Scala, Python o SQL per elaborare e analizzare i dati in streaming. Puoi creare ed eseguire codice su sorgenti di streaming e fonti statiche per eseguire analisi di serie temporali, alimentare dashboard e metriche in tempo reale.
- Business intelligence
-
Quick Suite offre ai responsabili delle decisioni l'opportunità di esplorare e interpretare le informazioni in un ambiente visivo interattivo. In un'unica dashboard di dati, Quick Suite può includere AWS dati, dati di terze parti, big data, dati di fogli di calcolo, dati SaaS, dati B2B e altro ancora. Con Quick Suite Q, puoi usare il linguaggio naturale per porre domande sui tuoi dati e ricevere una risposta. Ad esempio, «Quali sono le categorie più vendute in California?»
- Search analytics
-
Amazon OpenSearch Service fornisce tutte le risorse per il OpenSearch cluster e lo avvia. Inoltre, rileva e sostituisce automaticamente i nodi di OpenSearch servizio guasti, riducendo il sovraccarico associato alle infrastrutture autogestite. Puoi utilizzare OpenSearch Service Direct Query per analizzare i dati in Amazon S3 e altri AWS servizi.
- Data governance
-
Con Amazon DataZone, puoi gestire e governare l'accesso ai dati utilizzando controlli granulari. Questi controlli aiutano a garantire l'accesso con il giusto livello di privilegi e contesto. Amazon DataZone semplifica la tua architettura integrando servizi di gestione dei dati, tra cui Amazon Redshift, Athena, Quick AWS Glue Suite, fonti locali e fonti di terze parti.
- Data collaboration
-
AWS Clean Roomsè uno spazio di lavoro di collaborazione sicuro in cui è possibile analizzare set di dati collettivi senza fornire l'accesso ai dati grezzi. Puoi collaborare con altre aziende scegliendo i partner con cui desideri collaborare, selezionando i relativi set di dati e configurando controlli per il miglioramento della privacy per tali partner. Quando esegui query, AWS Clean Rooms legge i dati dalla posizione originale dei dati e applica regole di analisi integrate per aiutarti a mantenere il controllo su tali dati.
- Data lake and data warehouse
-
La nuova generazione di Amazon SageMaker è completamente compatibile con Apache Iceberg e consente di unificare i dati tra i data lake di Amazon Simple Storage Service (Amazon S3) e i data warehouse Amazon Redshift. Ciò consente di creare applicazioni di analisi e intelligenza artificiale e machine learning (ML) su un'unica copia dei dati. Tramite integrazioni zero-ETL, puoi trasmettere dati da fonti operative quasi in tempo reale, eseguire query federate su più fonti e accedere ai dati con strumenti compatibili con Apache Iceberg. Puoi proteggere i tuoi dati definendo autorizzazioni dettagliate che vengono applicate a tutti gli strumenti e i motori di analisi e ML.
Amazon S3 può archiviare e proteggere praticamente qualsiasi quantità e tipo di dati, che puoi utilizzare per le fondamenta del tuo data lake. Amazon S3 offre caratteristiche di gestione che consentono di ottimizzare, organizzare e configurare l'accesso ai dati per soddisfare specifici requisiti aziendali, organizzativi e di conformità. Le tabelle Amazon S3 forniscono uno storage S3 ottimizzato per i carichi di lavoro di analisi. Utilizzando istruzioni SQL standard, puoi interrogare le tue tabelle con motori di query che supportano Iceberg, come Athena, Amazon Redshift e Apache Spark.
Amazon Redshift è un servizio di data warehouse con capacità di petabyte completamente gestito. Amazon Redshift può essere collegato a un data lakehouse in SageMaker Amazon, consentendoti di utilizzare le sue potenti funzionalità di analisi SQL sui tuoi dati unificati nei data warehouse Amazon Redshift e nei data lake Amazon S3. Puoi anche usare Amazon Q in Amazon Redshift, che semplifica la creazione di SQL tramite il linguaggio naturale.
Prendi in considerazione i criteri per i servizi di analisi AWS
Esistono molte ragioni per basare l'analisi dei dati AWS. Potrebbe essere necessario supportare un progetto pilota o un progetto pilota come primo passo nel percorso di migrazione al cloud. In alternativa, potresti migrare un carico di lavoro esistente con il minor numero di interruzioni possibile. Qualunque sia il tuo obiettivo, le seguenti considerazioni possono essere utili per fare la tua scelta.
- Assess data sources and data types
-
Analizza le fonti di dati e i tipi di dati disponibili per acquisire una comprensione completa della diversità, della frequenza e della qualità dei dati. Comprendi le potenziali sfide nell'elaborazione e nell'analisi dei dati. Questa analisi è fondamentale perché:
-
Le fonti di dati sono diverse e provengono da vari sistemi, applicazioni, dispositivi e piattaforme esterne.
-
Le fonti di dati hanno una struttura, un formato e una frequenza di aggiornamento dei dati unici. L'analisi di queste fonti aiuta a identificare metodi e tecnologie di raccolta dati adeguati.
-
L'analisi dei tipi di dati, come dati strutturati, semistrutturati e non strutturati, determina gli approcci appropriati per l'elaborazione e l'archiviazione dei dati.
-
L'analisi delle fonti e dei tipi di dati facilita la valutazione della qualità dei dati e consente di anticipare potenziali problemi di qualità dei dati: valori mancanti, incongruenze o imprecisioni.
- Data processing requirements
-
Determina i requisiti di elaborazione dei dati per il modo in cui i dati vengono acquisiti, trasformati, puliti e preparati per l'analisi. Le considerazioni chiave includono:
-
Trasformazione dei dati: determina le trasformazioni specifiche necessarie per rendere i dati grezzi adatti all'analisi. Ciò implica attività come l'aggregazione, la normalizzazione, il filtraggio e l'arricchimento dei dati.
-
Pulizia dei dati: valuta la qualità dei dati e definisci i processi per gestire i dati mancanti, imprecisi o incoerenti. Implementa tecniche di pulizia dei dati per garantire dati di alta qualità per approfondimenti affidabili.
-
Frequenza di elaborazione: determina se è necessaria l'elaborazione in tempo reale, quasi in tempo reale o in batch in base alle esigenze analitiche. L'elaborazione in tempo reale consente informazioni immediate, mentre l'elaborazione in batch può essere sufficiente per analisi periodiche.
-
Scalabilità e produttività: valuta i requisiti di scalabilità per la gestione dei volumi di dati, la velocità di elaborazione e il numero di richieste di dati simultanee. Garantisci che l'approccio di elaborazione scelto sia in grado di adattarsi alle crescite future.
-
Latenza: considera la latenza accettabile per l'elaborazione dei dati e il tempo necessario dall'ingestione dei dati ai risultati dell'analisi. Ciò è particolarmente importante per le analisi in tempo reale o sensibili al fattore tempo.
- Storage requirements
-
Determina le esigenze di storage determinando come e dove i dati vengono archiviati lungo la pipeline di analisi. Le considerazioni importanti includono:
-
Volume di dati: valuta la quantità di dati generati e raccolti e stima la crescita futura dei dati per pianificare una capacità di storage sufficiente.
-
Conservazione dei dati: definisce la durata per la quale i dati devono essere conservati per scopi di analisi storica o di conformità. Determina le politiche di conservazione dei dati appropriate.
-
Modelli di accesso ai dati: scopri come verrà effettuato l'accesso ai dati e come verranno interrogati per scegliere la soluzione di archiviazione più adatta. Prendi in considerazione le operazioni di lettura e scrittura, la frequenza di accesso ai dati e la località dei dati.
-
Sicurezza dei dati: dai priorità alla sicurezza dei dati valutando le opzioni di crittografia, i controlli di accesso e i meccanismi di protezione dei dati per salvaguardare le informazioni sensibili.
-
Ottimizzazione dei costi: ottimizza i costi di storage selezionando le soluzioni di storage più convenienti in base ai modelli di accesso e all'utilizzo dei dati.
-
Integrazione con i servizi di analisi: garantisce una perfetta integrazione tra la soluzione di archiviazione scelta e gli strumenti di elaborazione e analisi dei dati nella pipeline.
- Types of data
-
Quando scegli i servizi di analisi per la raccolta e l'inserimento dei dati, prendi in considerazione vari tipi di dati pertinenti alle esigenze e agli obiettivi della tua organizzazione. I tipi di dati più comuni che potresti dover prendere in considerazione includono:
-
Dati transazionali: includono informazioni sulle interazioni o transazioni individuali, come acquisti dei clienti, transazioni finanziarie, ordini online e registri delle attività degli utenti.
-
Dati basati su file: si riferisce a dati strutturati o non strutturati archiviati in file, come file di registro, fogli di calcolo, documenti, immagini, file audio e file video. I servizi di analisi devono supportare l'inserimento di diversi formati di file.
-
Dati sugli eventi: acquisiscono eventi o incidenti significativi, come le azioni degli utenti, gli eventi di sistema, gli eventi delle macchine o gli eventi aziendali. Gli eventi possono includere tutti i dati che arrivano ad alta velocità e che vengono acquisiti per l'elaborazione a valle o a valle.
- Operational considerations
-
La responsabilità operativa è condivisa tra voi e AWS la divisione delle responsabilità varia a seconda dei diversi livelli di modernizzazione. Hai la possibilità di gestire autonomamente la tua infrastruttura di analisi AWS o di sfruttare i numerosi servizi di analisi serverless per ridurre il carico di gestione dell'infrastruttura.
Le opzioni autogestite garantiscono agli utenti un maggiore controllo sull'infrastruttura e sulle configurazioni, ma richiedono un maggiore impegno operativo.
Le opzioni serverless riducono gran parte del carico operativo, fornendo scalabilità automatica, alta disponibilità e solide funzionalità di sicurezza, consentendo agli utenti di concentrarsi maggiormente sulla creazione di soluzioni analitiche e sulla raccolta di informazioni piuttosto che sulla gestione dell'infrastruttura e delle attività operative. Considerate questi vantaggi delle soluzioni di analisi serverless:
-
Astrazione dell'infrastruttura: i servizi serverless astraggono la gestione dell'infrastruttura, sollevando gli utenti dalle attività di provisioning, scalabilità e manutenzione. AWS gestisce questi aspetti operativi, riducendo il sovraccarico di gestione.
-
Scalabilità e prestazioni automatiche: i servizi serverless ridimensionano automaticamente le risorse in base alle richieste del carico di lavoro, garantendo prestazioni ottimali senza interventi manuali.
-
Alta disponibilità e disaster recovery: AWS
offrono un'elevata disponibilità per i servizi serverless. AWS gestisce la ridondanza, la replica e il disaster recovery dei dati per migliorare la disponibilità e l'affidabilità dei dati.
-
Sicurezza e conformità: AWS gestisce le misure di sicurezza, la crittografia dei dati e la conformità per i servizi serverless, aderendo agli standard e alle migliori pratiche del settore.
-
Monitoraggio e registrazione: AWS offre funzionalità integrate di monitoraggio, registrazione e avviso per i servizi serverless. Gli utenti possono accedere a metriche e log dettagliati tramite Amazon. CloudWatch
- Type of workload
-
Quando si crea una pipeline di analisi moderna, decidere i tipi di carico di lavoro da supportare è fondamentale per soddisfare efficacemente le diverse esigenze analitiche. I punti decisionali chiave da considerare per ogni tipo di carico di lavoro includono:
Carico di lavoro in batch
-
Volume e frequenza dei dati: l'elaborazione in batch è adatta per grandi volumi di dati con aggiornamenti periodici.
-
Latenza dei dati: l'elaborazione in batch potrebbe introdurre qualche ritardo nella fornitura di informazioni rispetto all'elaborazione in tempo reale.
Analisi interattiva
-
Complessità delle interrogazioni sui dati: l'analisi interattiva richiede risposte a bassa latenza per un feedback rapido.
-
Visualizzazione dei dati: valuta la necessità di strumenti interattivi di visualizzazione dei dati per consentire agli utenti aziendali di esplorare i dati visivamente.
Carichi di lavoro in streaming
-
Velocità e volume dei dati: i carichi di lavoro in streaming richiedono l'elaborazione in tempo reale per gestire dati ad alta velocità.
-
Finestratura dei dati: definisci le finestre dei dati e le aggregazioni basate sul tempo per lo streaming dei dati al fine di estrarre informazioni pertinenti.
- Type of analysis needed
-
Definisci chiaramente gli obiettivi aziendali e le informazioni che intendi ricavare dalle analisi. Diversi tipi di analisi hanno scopi diversi. Ad esempio:
-
L'analisi descrittiva è ideale per ottenere una panoramica storica
-
L'analisi diagnostica aiuta a comprendere le ragioni alla base degli eventi passati
-
L'analisi predittiva prevede i risultati futuri
-
L'analisi prescrittiva fornisce consigli per azioni ottimali
Abbina i tuoi obiettivi aziendali ai tipi di analisi pertinenti. Ecco alcuni criteri decisionali chiave per aiutarti a scegliere i tipi di analisi giusti:
-
Disponibilità e qualità dei dati: l'analisi descrittiva e diagnostica si basa su dati storici, mentre l'analisi predittiva e prescrittiva richiede dati storici sufficienti e dati di alta qualità per creare modelli accurati.
-
Volume e complessità dei dati: l'analisi predittiva e prescrittiva richiede notevoli risorse computazionali e di elaborazione dei dati. Assicurati che l'infrastruttura e gli strumenti siano in grado di gestire il volume e la complessità dei dati.
-
Complessità decisionale: se le decisioni coinvolgono più variabili, vincoli e obiettivi, l'analisi prescrittiva può essere più adatta a guidare azioni ottimali.
-
Tolleranza al rischio: l'analisi prescrittiva può fornire raccomandazioni, ma comporta incertezze associate. Assicurati che i responsabili delle decisioni comprendano i rischi associati ai risultati dell'analisi.
- Evaluate scalability and performance
-
Valuta le esigenze di scalabilità e prestazioni dell'architettura. Il design deve gestire volumi di dati crescenti, richieste degli utenti e carichi di lavoro analitici. I fattori decisionali chiave da considerare includono:
-
Volume e crescita dei dati: valuta il volume di dati attuale e anticipa le crescite future.
-
Velocità dei dati e requisiti in tempo reale: stabilisci se i dati devono essere elaborati e analizzati in tempo reale o quasi.
-
Complessità dell'elaborazione dei dati: analizza la complessità delle attività di elaborazione e analisi dei dati. Per attività ad alta intensità di calcolo, servizi come Amazon EMR forniscono un ambiente scalabile e gestito per l'elaborazione di big data.
-
Concorrenza e carico utente: considera il numero di utenti simultanei e il livello di carico degli utenti sul sistema.
-
Funzionalità di auto-scaling: prendi in considerazione i servizi che offrono funzionalità di auto-scaling, che consentono alle risorse di scalare automaticamente verso l'alto o verso il basso in base alla domanda. Ciò garantisce un utilizzo efficiente delle risorse e l'ottimizzazione dei costi.
-
Distribuzione geografica: prendi in considerazione i servizi con replica globale e accesso ai dati a bassa latenza se la tua architettura dei dati deve essere distribuita su più aree o località.
-
Compromesso tra costi e prestazioni: bilanciate le esigenze prestazionali con le considerazioni relative ai costi. I servizi ad alte prestazioni possono avere un costo maggiore.
-
Accordi sui livelli di servizio (SLAs): verifica i servizi SLAs forniti dai AWS servizi per assicurarti che soddisfino le tue aspettative di scalabilità e prestazioni.
- Data governance
-
La governance dei dati è l'insieme di processi, politiche e controlli che è necessario implementare per garantire una gestione, qualità, sicurezza e conformità efficaci delle risorse di dati. I punti decisionali chiave da considerare includono:
-
Politiche di conservazione dei dati: definisci le politiche di conservazione dei dati in base ai requisiti normativi e alle esigenze aziendali e stabilisci processi per lo smaltimento sicuro dei dati quando non sono più necessari.
-
Audit trail e registrazione: decidi i meccanismi di registrazione e controllo per monitorare l'accesso e l'utilizzo dei dati. Implementa audit trail completi per tenere traccia delle modifiche ai dati, dei tentativi di accesso e delle attività degli utenti per il monitoraggio della conformità e della sicurezza.
-
Requisiti di conformità: comprendi le normative di conformità dei dati specifiche del settore e geografiche che si applicano alla tua organizzazione. Assicurati che l'architettura dei dati sia in linea con queste normative e linee guida.
-
Classificazione dei dati: classifica i dati in base alla loro sensibilità e definisci i controlli di sicurezza appropriati per ogni classe di dati.
-
Disaster recovery e continuità aziendale: pianifica il disaster recovery e la continuità aziendale per garantire la disponibilità e la resilienza dei dati in caso di eventi imprevisti o guasti del sistema.
-
Condivisione dei dati con terze parti: se condividi dati con entità terze, implementa protocolli e accordi di condivisione dei dati sicuri per proteggere la riservatezza dei dati e prevenirne l'uso improprio.
- Security
-
La sicurezza dei dati nella pipeline di analisi implica la protezione dei dati in ogni fase della pipeline per garantirne la riservatezza, l'integrità e la disponibilità. I punti decisionali chiave da considerare includono:
-
Controllo e autorizzazione degli accessi: implementa solidi protocolli di autenticazione e autorizzazione per garantire che solo gli utenti autorizzati possano accedere a risorse di dati specifiche.
-
Crittografia dei dati: scegli i metodi di crittografia appropriati per i dati archiviati in database, data lake e durante lo spostamento dei dati tra i diversi componenti dell'architettura.
-
Mascheramento e anonimizzazione dei dati: considera la necessità di mascherare o anonimizzare i dati per proteggere i dati sensibili, come le informazioni personali o i dati aziendali sensibili, consentendo al contempo il proseguimento di determinati processi analitici.
-
Integrazione sicura dei dati: stabilisci pratiche sicure di integrazione dei dati per garantire che i dati scorrano in modo sicuro tra i diversi componenti dell'architettura, evitando fughe di dati o accessi non autorizzati durante lo spostamento dei dati.
-
Isolamento della rete: prendi in considerazione i servizi che supportano gli endpoint Amazon VPC per evitare di esporre le risorse alla rete Internet pubblica.
- Plan for integration and data flows
-
Definisci i punti di integrazione e i flussi di dati tra i vari componenti della pipeline di analisi per garantire un flusso di dati e un'interoperabilità senza interruzioni. I punti decisionali chiave da considerare includono:
-
Integrazione delle fonti di dati: identifica le fonti di dati da cui verranno raccolti i dati, come database, applicazioni, file o fonti esterne APIs. Decidi i metodi di inserimento dei dati (batch, in tempo reale, basati su eventi) per inserire i dati nella pipeline in modo efficiente e con una latenza minima.
-
Trasformazione dei dati: determina le trasformazioni necessarie per preparare i dati per l'analisi. Decidi gli strumenti e i processi per pulire, aggregare, normalizzare o arricchire i dati man mano che attraversano la pipeline.
-
Architettura di spostamento dei dati: scegli l'architettura appropriata per lo spostamento dei dati tra i componenti della pipeline. Prendi in considerazione l'elaborazione in batch, l'elaborazione in streaming o una combinazione di entrambe in base ai requisiti in tempo reale e al volume di dati.
-
Replica e sincronizzazione dei dati: scegli i meccanismi di replica e sincronizzazione dei dati per conservare i dati up-to-date tra tutti i componenti. Prendi in considerazione soluzioni di replica in tempo reale o sincronizzazioni periodiche dei dati a seconda dei requisiti di freschezza dei dati.
-
Qualità e convalida dei dati: implementa controlli e procedure di convalida della qualità dei dati per garantire l'integrità dei dati mentre attraversano la pipeline. Decidi le azioni da intraprendere quando i dati non vengono convalidati, ad esempio avvisi o gestione degli errori.
-
Sicurezza e crittografia dei dati: stabilisci in che modo verranno protetti i dati durante il transito e durante la conservazione. Decidi i metodi di crittografia per proteggere i dati sensibili in tutta la pipeline, considerando il livello di sicurezza richiesto in base alla sensibilità dei dati.
-
Scalabilità e resilienza: assicurati che la progettazione del flusso di dati consenta la scalabilità orizzontale e sia in grado di gestire un aumento del volume e del traffico di dati.
- Architect for cost optimization
-
Lo sviluppo della pipeline di analisi AWS offre diverse opportunità di ottimizzazione dei costi. Per garantire l'efficienza dei costi, prendi in considerazione le seguenti strategie:
-
Dimensionamento e selezione delle risorse: dimensiona correttamente le risorse in base ai requisiti effettivi del carico di lavoro. Scegli AWS servizi e tipi di istanze che soddisfino le esigenze prestazionali dei carichi di lavoro evitando al contempo l'overprovisioning.
-
Scalabilità automatica: implementa l'auto-scaling per i servizi con carichi di lavoro diversi. La scalabilità automatica regola dinamicamente il numero di istanze in base alla domanda, riducendo i costi nei periodi di traffico ridotto.
-
Istanze Spot: utilizza le istanze Amazon EC2 Spot per carichi di lavoro non critici e con tolleranza ai guasti. Le istanze Spot possono ridurre significativamente i costi rispetto alle istanze on demand.
-
Istanze riservate: prendi in considerazione l'acquisto di istanze AWS
riservate per ottenere risparmi significativi sui costi rispetto ai prezzi on demand per carichi di lavoro stabili con un utilizzo prevedibile.
-
Storage dei dati su più livelli: ottimizza i costi di storage dei dati utilizzando diverse classi di storage in base alla frequenza di accesso ai dati.
-
Politiche sul ciclo di vita dei dati: stabilisci politiche sul ciclo di vita dei dati per spostare o eliminare automaticamente i dati in base all'età e ai modelli di utilizzo. Questo aiuta a gestire i costi di storage e mantiene l'archiviazione dei dati in linea con il suo valore.
Scegli i servizi AWS di analisi
Ora che conosci i criteri per valutare le tue esigenze di analisi, sei pronto a scegliere quali servizi di AWS analisi sono più adatti alle tue esigenze organizzative. La tabella seguente allinea i set di servizi alle funzionalità e agli obiettivi aziendali comuni.
| Categories |
Per cosa è ottimizzato? |
Servizi |
Analisi e intelligenza artificiale unificate |
Analisi e sviluppo dell'intelligenza artificiale
Ottimizzato per l'utilizzo di un unico ambiente di sviluppo, Amazon SageMaker Unified Studio, per accedere a dati, analisi e funzionalità di intelligenza artificiale.
|
Amazon SageMaker |
|
Elaborazione dei dati
|
Analisi interattiva
Ottimizzata per eseguire analisi ed esplorazioni dei dati in tempo reale, che consente agli utenti di interrogare e visualizzare i dati in modo interattivo.
|
Amazon Athena
|
Elaborazione di big data
Ottimizzato per l'elaborazione, lo spostamento e la trasformazione di grandi quantità di dati.
|
Amazon EMR
|
|
Catalogo dati
Ottimizzato per fornire informazioni dettagliate sui dati disponibili, sulla loro struttura, caratteristiche e relazioni. |
AWS Glue |
|
Orchestrazione del flusso di lavoro
Ottimizzato per la creazione, la pianificazione e il monitoraggio dei flussi di lavoro di dati utilizzando Apache Airflow per coordinare i processi di analisi e i lavori ETL.
|
Amazon MWAA
|
Streaming di dati |
Elaborazione di dati in streaming con Apache Kafka
Ottimizzato per l'utilizzo delle operazioni sul piano dati di Apache Kafka e l'esecuzione di versioni open source di Apache Kafka. |
Amazon MSK |
Processamento in tempo reale
Ottimizzato per l'acquisizione e l'aggregazione rapide e continue dei dati, inclusi i dati di registro dell'infrastruttura IT, i registri delle applicazioni, i social media, i feed di dati di mercato e i dati clickstream Web.
|
Flusso di dati Amazon Kinesis |
Fornitura di dati in streaming in tempo reale
Ottimizzato per fornire dati di streaming in tempo reale a destinazioni come Amazon S3, Amazon Redshift, Service, Splunk OpenSearch , Apache Iceberg Tables e qualsiasi endpoint HTTP personalizzato o endpoint HTTP di proprietà di provider di servizi terzi supportati. |
Amazon Data Firehose |
Creazione di applicazioni Apache Flink
Ottimizzato per l'utilizzo di Java, Scala, Python o SQL per elaborare e analizzare i dati in streaming. |
Servizio gestito da Amazon per Apache Flink |
Intelligenza aziendale |
Dashboard e visualizzazioni
Ottimizzato per rappresentare visivamente set di dati complessi e fornire interrogazioni in linguaggio naturale dei dati.
|
Suite rapida
|
Analisi di ricerca |
OpenSearch Cluster gestiti
Ottimizzato per l'analisi dei log, il monitoraggio delle applicazioni in tempo reale e l'analisi del clickstream.
|
OpenSearch Servizio Amazon
|
Governance dei dati |
Gestione dell'accesso ai dati
Ottimizzato per configurare la corretta gestione, disponibilità, usabilità, integrità e sicurezza dei dati durante tutto il loro ciclo di vita. |
Amazon DataZone |
Collaborazione sui dati |
Dati sicuri, camere pulite
Ottimizzato per collaborare con altre aziende senza condividere i dati grezzi sottostanti. |
AWS Clean Rooms |
Data lake e magazzino |
Accesso unificato ai data lake e ai data warehouse
Basato su un'architettura Lakehouse per ottimizzare l'accesso ai dati tra data lake Amazon S3, data warehouse Amazon Redshift, database operativi e fonti di dati federate e di terze parti.
|
Amazon SageMaker |
|
Storage di oggetti per data lake Ottimizzato per fornire una base di data lake con scalabilità praticamente illimitata ed elevata durabilità. |
Amazon S3 |
Archiviazione dei dati
Ottimizzato per l'archiviazione, l'organizzazione e il recupero centralizzati di grandi volumi di dati strutturati e talvolta semistrutturati da varie fonti all'interno di un'organizzazione. |
Amazon Redshift
|
Utilizza i servizi di analisi AWS
Ora dovresti avere una chiara comprensione dei tuoi obiettivi aziendali e del volume e della velocità dei dati che acquisirai e analizzerai per iniziare a creare le tue pipeline di dati.
Per scoprire come utilizzare e saperne di più su ciascuno dei servizi disponibili, abbiamo fornito un percorso per scoprire come funziona ciascuno di essi. Le sezioni seguenti forniscono collegamenti a documentazione approfondita, tutorial pratici e risorse per iniziare dall'utilizzo di base a immersioni approfondite più avanzate.
- Amazon Athena
-
-
Guida introduttiva ad Amazon Athena
Scopri come usare Amazon Athena per interrogare i dati e creare una tabella basata su dati di esempio archiviati in Amazon S3, interrogare la tabella e verificare i risultati della query.
Inizia con il tutorial
-
Inizia a usare Apache Spark su Athena
Usa l'esperienza notebook semplificata nella console Athena per sviluppare applicazioni Apache Spark utilizzando Python o il notebook Athena. APIs
Inizia con il tutorial
-
Cataloga e gestisci le query federate di Athena con l'architettura Amazon Lakehouse SageMaker
Scopri come connetterti, gestire ed eseguire query federate sui dati archiviati in Amazon Redshift, DynamoDB e Snowflake tramite il data lakehouse di Amazon. SageMaker
Leggi il blog
-
Analisi dei dati in Amazon S3 con Athena
Scopri come utilizzare Athena sui log di Elastic Load Balancers, generati come file di testo in un formato predefinito. Ti mostriamo come creare una tabella, partizionare i dati in un formato usato da Athena, convertirli in Parquet e confrontare le prestazioni delle query.
Leggi il post del blog
- AWS Clean Rooms
-
-
Configurazione AWS Clean Rooms
Scopri come effettuare la configurazione AWS Clean Rooms nel tuo AWS account.
Leggi la guida
-
Sblocca le informazioni sui dati su set di dati multipartitici utilizzando AWS
Entity Resolution on AWS Clean Rooms senza condividere i dati sottostanti
Scopri come utilizzare la preparazione e la corrispondenza per migliorare la corrispondenza dei dati con i collaboratori.
Leggi il post del blog
-
In che modo la privacy differenziale aiuta a ottenere informazioni approfondite senza rivelare i dati a livello individuale
Scopri come AWS Clean Rooms Differential Privacy semplifica l'applicazione della privacy differenziale e aiuta a proteggere la privacy dei tuoi utenti.
Leggi il blog
- Amazon Data Firehose
-
-
Tutorial: Creare uno stream Firehose dalla console
Scopri come utilizzare Console di gestione AWS o un AWS SDK per creare uno stream Firehose verso la destinazione prescelta.
Leggi la guida
-
Inviare dati a uno stream Firehose
Scopri come utilizzare diverse fonti di dati per inviare dati al tuo stream Firehose.
Leggi la guida
-
Trasforma i dati di origine in Firehose
Scopri come richiamare la funzione Lambda per trasformare i dati di origine in entrata e consegnarli alle destinazioni.
Leggi la guida
- Amazon DataZone
-
-
Guida introduttiva ad Amazon DataZone
Scopri come creare il dominio DataZone root di Amazon, ottenere l'URL del portale dati, illustrare i DataZone flussi di lavoro Amazon di base per produttori e consumatori di dati.
Inizia con il tutorial
-
Annuncio della disponibilità generale della derivazione dei dati nella prossima generazione di Amazon e Amazon SageMaker DataZone
Scopri come Amazon DataZone utilizza l'acquisizione automatizzata del lignaggio per concentrarsi sulla raccolta e la mappatura automatiche delle informazioni sulla discendenza da e Amazon AWS Glue Redshift.
Leggi il blog
- Amazon EMR
-
-
Guida introduttiva ad Amazon EMR
Scopri come avviare un cluster di esempio utilizzando Spark e come eseguire un semplice PySpark script archiviato in un bucket Amazon S3.
Inizia con il tutorial
-
Guida introduttiva ad Amazon EMR su Amazon EKS
Ti mostriamo come iniziare a usare Amazon EMR su Amazon EKS distribuendo un'applicazione Spark su un cluster virtuale.
Esplora la guida
-
Inizia a usare EMR Serverless
Scopri come Amazon EMR Serverless fornisce un ambiente di runtime serverless che semplifica il funzionamento delle applicazioni di analisi che utilizzano i framework open source più recenti.
Inizia con il tutorial
- AWS Glue
-
-
Iniziare con AWS Glue DataBrew
Scopri come creare il tuo primo DataBrew progetto. Carichi un set di dati di esempio, esegui trasformazioni su quel set di dati, crei una ricetta per acquisire tali trasformazioni ed esegui un processo per scrivere i dati trasformati su Amazon S3.
Inizia con il tutorial
-
Trasforma i dati con AWS Glue DataBrew
Learn about AWS Glue DataBrew, uno strumento visivo di preparazione dei dati che consente agli analisti e ai data scientist di dati di pulire e normalizzare facilmente i dati per prepararli all'analisi e all'apprendimento automatico. Scopri come costruire un processo ETL utilizzando. AWS Glue DataBrew
Inizia con il laboratorio
-
AWS Glue DataBrew giornata di immersione
Scopri come utilizzarli per AWS Glue DataBrew pulire e normalizzare i dati per l'analisi e l'apprendimento automatico.
Inizia con il workshop
-
Iniziare con AWS Glue Data Catalog
Scopri come creare il tuo primo AWS Glue Data Catalog bucket che utilizza un bucket Amazon S3 come origine dati.
Inizia con il tutorial
-
Catalogo dati e crawler in AWS Glue
Scopri come utilizzare le informazioni del Data Catalog per creare e monitorare i tuoi lavori ETL.
Esplora la guida
- Amazon Kinesis Data Streams
-
-
Tutorial introduttivi per Amazon Kinesis Data Streams
Scopri come elaborare e analizzare i dati di borsa in tempo reale.
Inizia con i tutorial
-
Modelli architettonici per analisi in tempo reale con Amazon Kinesis Data Streams, parte 1
Scopri i modelli architettonici comuni di due casi d'uso: analisi di dati di serie temporali e microservizi basati su eventi.
Leggi il blog
-
Modelli architettonici per analisi in tempo reale con Amazon Kinesis Data Streams, parte 2
Scopri le applicazioni di intelligenza artificiale con Kinesis Data Streams in tre scenari: business intelligence generativa in tempo reale, sistemi di raccomandazione in tempo reale e streaming e inferenza di dati nell'Internet of Things.
Leggi il blog
- Amazon Managed Service for Apache Flink
-
-
Cos'è Amazon Managed Service per Apache Flink?
Comprendi i concetti fondamentali di Amazon Managed Service for Apache Flink.
Esplora la guida
-
Workshop sui servizi gestiti Amazon per Apache Flink
In questo workshop imparerai come distribuire, gestire e scalare un'applicazione Flink con Amazon Managed Service per Apache Flink.
Partecipa al workshop virtuale
- Amazon MSK
-
-
Guida introduttiva ad Amazon MSK
Scopri come creare un cluster Amazon MSK, produrre e consumare dati e monitorare lo stato del cluster utilizzando i parametri.
Inizia con la guida
-
Workshop Amazon MSK
Approfondisci questo workshop pratico su Amazon MSK.
Inizia con il workshop
- Amazon MWAA
-
-
Guida introduttiva ad Amazon MWAA
Scopri come creare il tuo primo ambiente MWAA, caricare un DAG su Amazon S3 ed eseguire il tuo primo flusso di lavoro.
Inizia con il tutorial
-
Creazione di pipeline di dati con Amazon MWAA
Scopri come creare pipeline di end-to-end dati che orchestrano altri servizi di AWS
analisi come Glue, EMR e Redshift. Questo post del blog esplora un approccio semplificato e basato sulla configurazione per orchestrare i job dbt Core utilizzando MWAA e Cosmos, con processi che eseguono trasformazioni su Amazon Redshift.
Leggi il post del blog
-
Workshop Amazon MWAA
Esplora esercizi pratici per imparare a distribuire, configurare e utilizzare Amazon MWAA per l'orchestrazione del flusso di lavoro dei dati.
Inizia con il workshop
-
Best practice per Amazon MWAA
Scopri i modelli architettonici e le best practice per usare Amazon MWAA nei flussi di lavoro di analisi.
Leggi la guida
- OpenSearch Service
-
-
Guida introduttiva all' OpenSearch assistenza
Scopri come usare Amazon OpenSearch Service per creare e configurare un dominio di prova.
Inizia con il tutorial
-
Visualizzazione delle chiamate all'assistenza clienti con OpenSearch Service e Dashboards OpenSearch
Scopri una panoramica completa della seguente situazione: un'azienda riceve un certo numero di chiamate all'assistenza clienti e desidera analizzarle. Qual è l'argomento di ogni chiamata? Quante sono state positive? Quante sono state negative? In che modo i responsabili possono cercare o analizzare le trascrizioni di queste chiamate?
Inizia con il tutorial
-
Workshop introduttivo su Amazon OpenSearch Serverless
Scopri come configurare un nuovo dominio Amazon OpenSearch Serverless nella AWS
console. Esplora i diversi tipi di query di ricerca disponibili, progetta visualizzazioni accattivanti e scopri come proteggere il tuo dominio e i tuoi documenti in base ai privilegi utente assegnati.
Inizia con il workshop
-
Database vettoriale ottimizzato in termini di costi: introduzione alle tecniche di quantizzazione OpenSearch di Amazon Service
Scopri come OpenSearch Service supporta tecniche di quantizzazione scalare e di prodotto per ottimizzare l'utilizzo della memoria e ridurre i costi operativi.
Leggi il post del blog
- Quick Suite
-
-
Guida introduttiva all'analisi dei dati di Quick Suite
Scopri come creare la tua prima analisi. Usa dati di esempio per creare un'analisi semplice o più avanzata. Oppure puoi connetterti ai tuoi dati per creare un'analisi.
Esplora la guida
-
Visualizzazione con Quick Suite
Scopri il lato tecnico della business intelligence (BI) e della visualizzazione dei dati con. AWS Scopri come incorporare dashboard in applicazioni e siti Web e gestire in modo sicuro accessi e autorizzazioni.
Inizia con il corso
-
Workshop Quick Suite
Inizia subito il tuo percorso con Quick Suite con i workshop
Inizia con i workshop
- Amazon Redshift
-
-
Inizia a usare Amazon Redshift Serverless
Comprendi il flusso di base di Amazon Redshift Serverless per creare risorse serverless, connetterti ad Amazon Redshift Serverless, caricare dati di esempio ed eseguire query sui dati.
Esplora la guida
-
Workshop di approfondimento su Amazon Redshift
Esplora una serie di esercizi che aiutano gli utenti a iniziare a utilizzare la piattaforma Amazon Redshift.
Inizia con il workshop
- Amazon S3
-
-
Guida introduttiva ad Amazon S3
Scopri come creare il tuo primo DataBrew progetto. Carichi un set di dati di esempio, esegui trasformazioni su quel set di dati, crei una ricetta per acquisire tali trasformazioni ed esegui un processo per scrivere i dati trasformati su Amazon S3.
Inizia con la guida
- Amazon SageMaker
-
-
Iniziare con SageMaker
Scopri come creare un progetto, aggiungere membri e utilizzare il JupyterLab taccuino di esempio per iniziare a creare.
Leggi la guida
-
Ti presentiamo la nuova generazione di Amazon SageMaker: il centro per tutti i tuoi dati, analisi e intelligenza artificiale
Scopri come iniziare con l'elaborazione dei dati, lo sviluppo di modelli e lo sviluppo di app di intelligenza artificiale generativa.
Leggi il blog
-
Che cos'è SageMaker Unified Studio?
Scopri le funzionalità di SageMaker Unified Studio e come accedervi quando usi Amazon SageMaker.
Leggi la guida
-
Guida introduttiva all'architettura Lakehouse di Amazon SageMaker
Scopri come creare un progetto e sfogliare, caricare e interrogare i dati per i tuoi casi d'uso aziendali in Amazon SageMaker.
Leggi la guida
-
Connessioni dati nell'architettura Lakehouse di Amazon SageMaker
Scopri come l'architettura Lakehouse offre un approccio unificato alla gestione delle connessioni dati tra AWS servizi e applicazioni aziendali.
Leggi la guida
-
Cataloga e gestisci le domande federate di Athena con l'architettura Lakehouse SageMaker
Scopri come connetterti, gestire ed eseguire query federate sui dati archiviati in Amazon Redshift, DynamoDB e Snowflake per i tuoi progetti Amazon. SageMaker
Leggi il blog
Esplora i modi di utilizzare i servizi AWS di analisi
- Editable architecture diagrams
-
Diagrammi di architettura di riferimento
Esplora i diagrammi di architettura per aiutarti a sviluppare, scalare e testare le tue soluzioni di analisi. AWS
Esplora le architetture di riferimento per l'analisi
- Ready-to-use code
-
|
Soluzione in evidenza
Analisi scalabile con Apache Druid su AWS
AWS Implementa codice integrato per aiutarti a configurare, utilizzare e gestire Apache Druid on, un ambiente di hosting economico, altamente disponibile AWS, resiliente e tollerante ai guasti.
Esplora questa soluzione
|
AWS Soluzioni
Esplora le soluzioni preconfigurate e implementabili e le relative guide all'implementazione, create da. AWS
Esplora tutte le soluzioni AWS di sicurezza, identità e governance
|
- Documentation
-
|
Whitepaper di analisi
Consulta i white paper per ulteriori approfondimenti e best practice sulla scelta, l'implementazione e l'utilizzo dei servizi di analisi più adatti alla tua organizzazione.
Esplora i white paper sull'analisi
|
AWS Blog sui Big Data
Esplora i post di blog che trattano casi d'uso specifici dei Big Data.
Esplora il blog sui AWS Big Data
|