Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Architettura di Aurora PostgreSQL Limitless Database
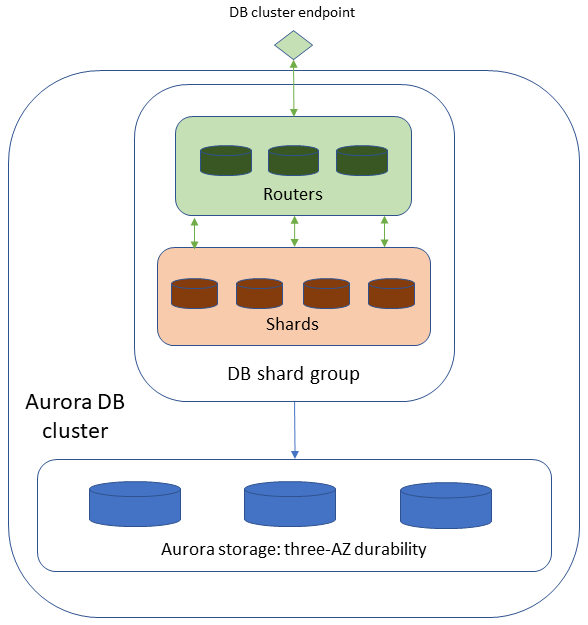
Limitless Database raggiunge la scalabilità con un’architettura a due livelli composta da più nodi di database. I nodi sono router o shard.
-
Gli shard sono istanze database Aurora PostgreSQL, ognuno dei quali archivia un sottoinsieme di dati per il database, consentendo l’elaborazione simultanea per ottenere un throughput di scrittura più elevato.
-
I router gestiscono la natura distribuita del database e presentano un’unica immagine del database ai client del database. I router conservano i metadati relativi alla posizione in cui sono archiviati i dati, analizzano i comandi SQL in entrata e li inviano agli shard. Successivamente aggregano i dati dagli shard per restituire un singolo risultato al cliente e gestiscono le transazioni distribuite per mantenere la coerenza nell’intero database distribuito.
Aurora PostgreSQL Limitless Database differisce dai Cluster di database Aurora standard perché dispone di un gruppo di shard del database invece di un’istanza database di scrittura e istanze database di lettura. Tutti i nodi che compongono l’architettura di Limitless Database sono contenuti nel gruppo di shard del database. I singoli shard e router del gruppo di shard DB non sono visibili nel tuo. Account AWS Per accedere a Limitless Database, utilizzi l’endpoint del cluster di database.
La figura seguente mostra l’architettura di alto livello di Aurora PostgreSQL Limitless Database.
Per ulteriori informazioni sull'architettura di Aurora PostgreSQL Limitless Database e su come utilizzarlo, guarda questo video sul canale Eventi su: AWS YouTube
Per ulteriori informazioni sull’architettura di un cluster di database Aurora standard, consulta Cluster database Amazon Aurora.
Termini chiave per Aurora PostgreSQL Limitless Database
- Gruppo di shard del database
-
Un container per i nodi di Limitless Database (shard e router).
- Router
-
Un nodo che accetta connessioni SQL dai client, invia comandi SQL agli shard, mantiene la coerenza a livello di sistema e restituisce i risultati ai client.
- Shard
-
Un nodo che archivia un sottoinsieme di tabelle sottoposte a sharding, copie complete di tabelle di riferimento e tabelle standard. Accetta query dai router, ma non può essere connesso direttamente dai client.
- Tabella sottoposta a sharding
-
Una tabella i cui dati sono partizionati tra gli shard.
- Chiave di shard
-
Una colonna o un insieme di colonne in una tabella sottoposta a sharding utilizzata per determinare la partizione tra gli shard.
- Tabelle co-localizzate
-
Due tabelle sottoposte a sharding che condividono la stessa chiave di shard e sono dichiarate esplicitamente come co-localizzate. Tutti i dati con lo stesso valore della chiave di shard vengono inviati allo stesso shard.
- Tabella di riferimento
-
Una tabella i cui dati sono copiati completamente su ogni shard.
- Tabella standard
-
Il tipo di tabella predefinito in Limitless Database. Puoi convertire le tabelle standard in tabelle sottoposte a sharding e tabelle di riferimento.
Tutte le tabelle standard sono archiviate sullo stesso shard selezionato dal sistema, consentendo i collegamenti tra tabelle standard all’interno di un singolo shard. Tuttavia, le tabelle standard sono limitate dalla capacità massima dello shard (128 TiB). Questo shard archivia anche dati di tabelle sottoposte a sharding e di riferimento, quindi il limite effettivo per le tabelle standard è inferiore a 128 TiB.
Tipi di tabelle per Aurora PostgreSQL Limitless Database
Aurora PostgreSQL Limitless Database supporta tre tipi di tabella: sottoposta a sharding, di riferimento e standard.
Le tabelle sottoposte a sharding distribuiscono i dati tra tutti gli shard nel gruppo di shard del database. Limitless Database esegue questa operazione automaticamente utilizzando una chiave di shard, che è una colonna specificata o un set di colonne specificato durante il partizionamento della tabella. Tutti i dati con lo stesso valore per la chiave di shard vengono inviati allo stesso shard. Lo sharding è basato su hash, non su intervalli o elenchi.
I seguenti sono casi d’uso consigliati per le tabelle sottoposte a sharding:
-
L’applicazione lavora con un sottoinsieme distinto di dati.
-
La tabella è molto grande.
-
La tabella cresce potenzialmente più velocemente rispetto ad altre tabelle.
Le tabelle sottoposte a sharding possono essere co-localizzate, vale a dire che condividono la stessa chiave di shard, in modo che tutti i dati di entrambe le tabelle con lo stesso valore della chiave di shard siano inviati allo stesso shard. Se co-localizzi le tabelle e le unisci utilizzando la chiave di shard, il collegamento può essere eseguito su un singolo shard perché tutti i dati necessari sono presenti su quello shard.
Le tabelle di riferimento hanno una copia completa di tutti i relativi dati su ogni shard nel gruppo di shard del database. Le tabelle di riferimento sono comunemente utilizzate per tabelle più piccole con basso volume di scrittura, ma che devono essere frequentemente collegate e non si prestano allo sharding. Esempi di tabelle di riferimento includono tabelle di date e tabelle di dati geografici come stato, città e codice postale.
Le tabelle standard sono il tipo di tabella predefinito in Aurora PostgreSQL Limitless Database. Non sono tabelle distribuite. Aurora PostgreSQL Limitless Database supporta i collegamenti tra tabelle standard e tabelle standard, sottoposte a sharding e di riferimento.
Fatturazione per Aurora PostgreSQL Limitless Database
Per informazioni su come vengono addebitati i costi per Aurora PostgreSQL Limitless Database, consulta Fatturazione delle istanze database per Aurora.
Per informazioni sui prezzi di Aurora, consulta la pagina dei prezzi di Aurora
