Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Cluster database Amazon Aurora
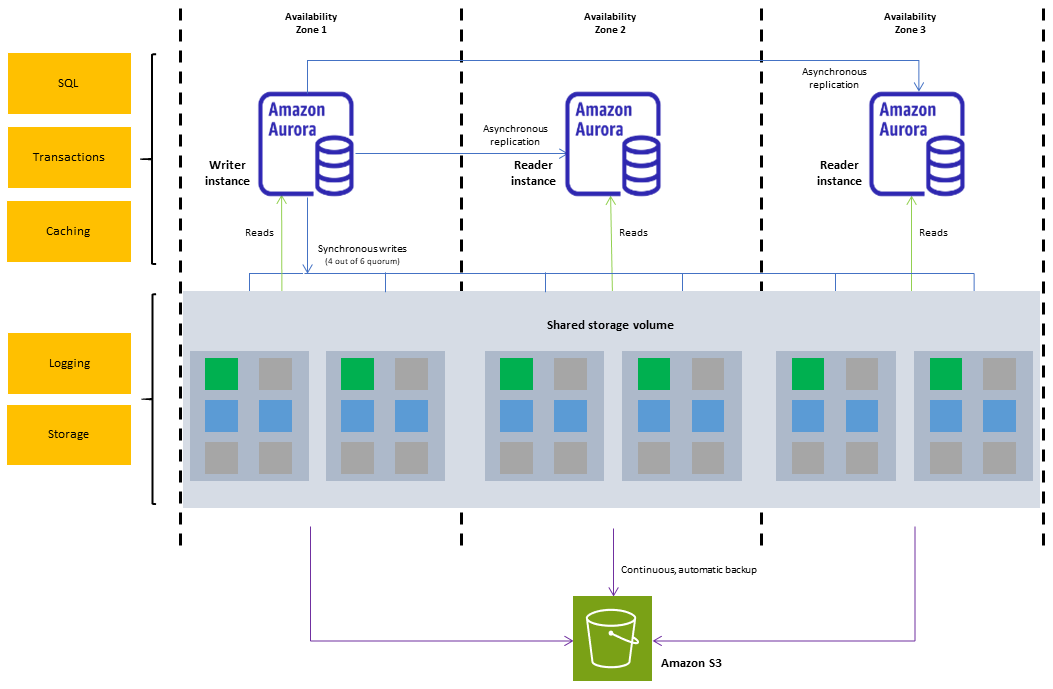
Un cluster database Amazon Aurora è composto da una o più istanze database e da un volume del cluster che gestisce i dati per tali istanze. Un volume del cluster Aurora è uno storage di database virtuale che si estende su più zone di disponibilità, ciascuna delle quali include una copia dei dati del cluster database. Un cluster database Aurora è formato da due tipi di istanze:
-
Istanza database primaria (di scrittura): supporta operazioni di lettura e scrittura ed esegue tutte le modifiche ai dati del volume del cluster. Ciascun cluster database Aurora ha un'istanza database primaria.
-
Replica Aurora (istanza database di lettura): si connette allo stesso volume di archiviazione dell’istanza database primaria ma supporta solo operazioni di lettura. Oltre all'istanza database primaria, ciascun cluster database Aurora può avere fino a 15 repliche di Aurora. È possibile mantenere l'alta disponibilità posizionando le repliche Aurora in zone di disponibilità separate. Aurora esegue automaticamente il failover in una replica di Aurora nel caso in cui l'istanza database principale non sia più disponibile. È possibile specificare la priorità di failover per le repliche di Aurora. Le repliche di Aurora possono anche effettuare l'offload dei carichi di lavoro in lettura dall'istanza database primaria.
Il diagramma seguente mostra la relazione tra il volume del cluster, l’istanza database di scrittura e le istanze database di lettura in un cluster di database Aurora.
Nota
Le informazioni precedenti si applicano a tutti i cluster Aurora DB: provisioned, parallel query, Aurora Global DatabaseAurora Serverless, Aurora e Aurora. MySQL-Compatible PostgreSQL-Compatible
Il cluster di database Aurora illustra la separazione tra capacità di calcolo e archiviazione. Ad esempio, una configurazione Aurora con una sola istanza database è comunque un cluster, poiché il volume dello storage sottostante riguarda più nodi di storage distribuiti in più zone di disponibilità (AZ).
Input/output (I/O) le operazioni nei cluster Aurora DB vengono conteggiate allo stesso modo, indipendentemente dal fatto che si trovino su un'istanza DB writer o reader. Per ulteriori informazioni, consulta Configurazioni dell'archiviazione per i cluster database Amazon Aurora.
