Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Utilizzo dello switchover o failover in un Database globale Amazon Aurora
La funzionalità Database globale Aurora offre una maggiore protezione a livello di continuità aziendale e disaster recovery (BCDR) rispetto alla disponibilità elevata standard fornita da un cluster di database Aurora in una singola Regione AWS. Database globale Aurora consente di pianificare un ripristino più rapido in caso di rari eventi non pianificati o di interruzioni complete dei livelli di servizio a livello regionale.
È possibile consultare le seguenti linee guida e procedure per pianificare, testare e implementare la strategia BCDR utilizzando la funzionalità Database globale Aurora.
Argomenti
Pianificazione della continuità aziendale e del disaster recovery
Per pianificare la strategia di continuità aziendale e disaster recovery, è utile comprendere la seguente terminologia di settore e il modo in cui tali termini si applicano alle funzionalità del Database globale Aurora.
Il ripristino di emergenza è in genere determinato dai due obiettivi aziendali seguenti:
-
Obiettivo del tempo di ripristino (RTO): il tempo necessario a un sistema per tornare a uno stato funzionante dopo un guasto o un'interruzione del servizio. In altre parole, l'RTO misura i tempi di inattività. Per Database globale Aurora, l’RTO può essere nell’ordine di minuti.
-
Obiettivo del punto di ripristino (RPO): la quantità di dati che può venire persa (misurata nel tempo) dopo un guasto o un'interruzione del servizio. Questa perdita di dati è in genere dovuta al ritardo della replica asincrona. Per un database globale Aurora, l'RPO viene in genere misurato in secondi. Con un database globale basato su Aurora PostgreSQL–, puoi utilizzare il parametro
rds.global_db_rpoper impostare e tenere traccia del limite superiore su RPO, ma ciò potrebbe influire sull'elaborazione delle transazioni sul nodo writer del cluster primario. Per ulteriori informazioni, consulta Gestione degli RPO per database globali basati su Aurora PostgreSQL–.
L’esecuzione di uno switchover o failover con Database globale Aurora implica la promozione di un cluster di database secondario a cluster di database primario. Il termine "interruzione a livello regionale" viene spesso utilizzato per descrivere una serie di scenari di errore. Lo scenario peggiore potrebbe essere un'interruzione generalizzata causata da un evento catastrofico che interessa un'area geografica particolarmente estesa. Tuttavia, la maggior parte delle interruzioni è molto più localizzata e riguarda solo un piccolo sottoinsieme di servizi cloud o sistemi dei clienti. Valuta l'ambito dell'interruzione nel suo insieme per assicurarti che il failover tra regioni rappresenti la soluzione più appropriata e scegli il metodo di failover più adatto alla situazione. L'utilizzo del failover o dello switchover dipende dallo scenario di interruzione specifico:
-
Failover: utilizza questo approccio per il ripristino dopo un'interruzione non pianificata. Con questo approccio, puoi eseguire un failover tra regioni su uno dei cluster database secondari del database globale Aurora. Il valore RPO, espresso in secondi, per questo approccio è in genere diverso da zero. La quantità di perdita di dati dipende dal ritardo di replica del database globale di Aurora Regioni AWS al momento dell'errore. Per ulteriori informazioni, consulta Ripristino di un database globale Amazon Aurora da un'interruzione non pianificata.
-
Switchover: questa operazione era precedentemente denominata “failover pianificato gestito”. Usa questo approccio per scenari controllati, ad esempio la manutenzione operativa e altre procedure operative pianificate, in cui tutti i cluster Aurora e gli altri servizi con cui interagiscono sono in stato integro. Poiché questa funzionalità sincronizza i cluster di database secondari con il primario prima di apportare altre modifiche, l’RPO è 0 (nessuna perdita di dati). Per ulteriori informazioni, consulta Esecuzione di switchover per database globali Amazon Aurora.
Nota
Se desideri eseguire lo switchover o il failover su un cluster di database Aurora secondario headless, devi prima aggiungervi un’istanza database. Per ulteriori informazioni sui cluster database headless, consulta Creazione di un cluster database Aurora headless in una regione secondaria.
Esecuzione di switchover per database globali Amazon Aurora
Nota
Gli switchover erano precedentemente denominati failover pianificati gestiti.
Utilizzando gli switchover, è possibile modificare regolarmente la Regione del cluster primario. Questo approccio è destinato agli scenari controllati, ad esempio durante la manutenzione operativa e altre procedure operative pianificate.
Esistono tre casi d'uso comuni per l'utilizzo degli switchover.
-
Per i requisiti relativi alla "rotazione regionale" imposti a settori specifici. Ad esempio, le normative sui servizi finanziari potrebbero imporre che i sistemi di livello 0 passino a un'altra regione per diversi mesi per garantire l'esecuzione regolare delle procedure di ripristino di emergenza.
-
Per applicazioni con approccio "follow-the-sun" in più regioni. Ad esempio, un'azienda potrebbe voler fornire scritture con latenza inferiore in diverse regioni in base all'orario di lavoro nei vari fusi orari.
-
Come metodo senza perdita di dati per eseguire il failback alla regione principale originale dopo un failover.
Nota
Gli switchover sono progettati per essere utilizzati su un Database globale Aurora in cui tutti i cluster Aurora e gli altri servizi con cui interagiscono sono in stato integro. Per eseguire il ripristino da un'interruzione non pianificata, puoi eseguire la procedura appropriata descritta in Ripristino di un database globale Amazon Aurora da un'interruzione non pianificata.
È possibile eseguire switchover gestiti tra Regioni con il Database globale Aurora solo se i cluster di database primario e secondario hanno le stesse versioni principale e secondaria del motore. A seconda del motore e delle versioni del motore, può essere necessario che i livelli di patch siano identici oppure possono essere diversi. Per un elenco dei motori e delle versioni dei motori che consentono queste operazioni tra cluster primari e secondari con diversi livelli di patch, consulta Compatibilità del livello di patch per switchover e failover gestiti tra regioni. Prima di iniziare lo switchover, controlla le versioni del motore nel cluster globale per assicurarti che supportino lo switchover gestito tra regioni e, se necessario, aggiornale.
Durante uno switchover, Aurora imposta il cluster nella Regione secondaria scelta come cluster primario. Il meccanismo di switchover mantiene la topologia di replica esistente del database globale: ha ancora lo stesso numero di cluster Aurora nelle stesse Regioni. Prima di avviare il processo di switchover, Aurora attende che tutti i cluster della Regione secondaria di destinazione siano completamente sincronizzati con il cluster della Regione primaria. In seguito, il cluster di database nella Regione primaria diventa di sola lettura. Il cluster secondario scelto promuove uno dei suoi nodi di sola lettura allo stato di scrittura completo, consentendo così al cluster secondario di assumere il ruolo di cluster primario. Poiché tutti i cluster secondari di destinazione sono stati sincronizzati con quello primario all’inizio del processo, il nuovo primario continua le operazioni per il Database globale Aurora senza perdere alcun dato. Il database non è disponibile per un breve periodo, mentre i cluster primario e secondario selezionati assumono i loro nuovi ruoli.
Nota
Per gestire gli slot di replica per Aurora PostgreSQL dopo aver eseguito uno switchover, consulta Gestione degli slot logici per Aurora PostgreSQL.
Per ottimizzare la disponibilità delle applicazioni, è consigliabile eseguire le seguenti operazioni prima di utilizzare questa funzionalità:
-
Esegui questa operazione durante le ore non di punta o in un altro momento quando le scritture nel cluster DB primario sono minime.
-
Controllare i tempi di ritardo per tutti i cluster di database Aurora secondari nel database globale Aurora. Per tutti i database PostgreSQL-based globali Aurora e per i database MySQL-based globali Aurora a partire dalle versioni del motore 3.04.0 e successive o 2.12.0 e successive, usa CloudWatch Amazon per visualizzare la metrica per tutti
AuroraGlobalDBRPOLagi cluster DB secondari. Per le versioni minori inferiori dei database MySQL-based globali di Aurora, visualizza invece laAuroraGlobalDBReplicationLagmetrica. Questa metrica indica il ritardo (in millisecondi) della replica tra un cluster secondario e il cluster database primario. Il suo valore è direttamente proporzionale al tempo necessario ad Aurora per completare lo switchover. Di conseguenza, maggiore è il valore del ritardo, maggiore sarà il tempo necessario per lo switchover. Quando esamini queste metriche, procedi dal cluster primario corrente.Per ulteriori informazioni sulle CloudWatch metriche per Aurora, consulta. Cluster-level metriche per Amazon Aurora
-
Il cluster di database secondario promosso durante uno switchover potrebbe avere impostazioni di configurazione diverse rispetto al cluster di database primario precedente. È consigliabile mantenere i seguenti tipi di impostazioni di configurazione coerenti tra tutti i cluster nei cluster di Database globale Aurora. Questo consente di ridurre al minimo i problemi con le prestazioni, le incompatibilità dei carichi di lavoro e gli altri comportamenti anomali che seguono uno switchover.
-
Configura il gruppo di parametri del cluster di database Aurora per il nuovo cluster primario, se necessario: quando si promuove un cluster di database secondario perché assuma il ruolo di primario, il gruppo di parametri del secondario potrebbe essere configurato in modo diverso rispetto al cluster primario. In tal caso, modifica il gruppo di parametri del cluster di database secondario promosso in modo che sia conforme alle impostazioni del cluster primario. Per scoprire come, consulta Modifica dei parametri per un database globale Aurora.
-
Configura strumenti e opzioni di monitoraggio, come Amazon CloudWatch Events e allarmi: configura il cluster DB promosso con la stessa capacità di registrazione, gli allarmi e così via necessari per il database globale. Come per i gruppi di parametri, la configurazione di queste funzionalità non viene ereditata dal ruolo primario durante il processo di switchover. Alcune CloudWatch metriche, come il ritardo di replica, sono disponibili solo per le regioni secondarie. Pertanto, uno switchover modifica il modo in cui visualizzare tali metriche e impostare i relativi allarmi e potrebbe richiedere modifiche da apportare a qualsiasi dashboard predefinito. Per ulteriori informazioni sui cluster di database Aurora e sul monitoraggio, consulta Monitoraggio Amazon Aurora metriche con Amazon CloudWatch.
-
Configura le integrazioni con altri AWS servizi: se il tuo database globale Aurora si integra AWS con servizi Gestione dei segreti AWS come AWS Identity and Access Management Amazon S3 AWS Lambda e, assicurati di configurare le integrazioni con questi servizi in base alle esigenze. Per ulteriori informazioni sull'integrazione dei database globali Aurora con IAM, Amazon S3 e Lambda, consulta Utilizzo dei database globali di Amazon Aurora con altri servizi AWS. Per ulteriori informazioni su Secrets Manager, consulta Come automatizzare la replica dei segreti in Gestione dei segreti AWS across
. Regioni AWS
-
Se utilizzi l’endpoint di scrittura del Database globale Aurora, non occorre cambiare le impostazioni di connessione nell’applicazione. Verifica che le modifiche al DNS si siano propagate e che sia possibile connettersi ed eseguire operazioni di scrittura sul nuovo cluster primario. Potrai quindi riprendere la piena operatività dell’applicazione.
Supponiamo che le connessioni alle applicazioni utilizzino l’endpoint cluster del cluster primario precedente, anziché l’endpoint di scrittura globale. In tal caso, assicurati di modificare le impostazioni di connessione dell’applicazione in modo da utilizzare l’endpoint cluster del nuovo cluster primario. Se hai accettato i nomi forniti al momento della creazione del database globale Aurora, puoi modificare l'endpoint rimuovendo -ro dalla stringa endpoint del cluster promosso nell'applicazione. Ad esempio, l'endpoint del cluster secondario my-global.cluster-ro-aaaaaabbbbbb.us-west-1.rds.amazonaws.com diventa my-global.cluster-aaaaaabbbbbb.us-west-1.rds.amazonaws.com quando tale cluster viene promosso a primario.
Se utilizzi RDS Proxy, assicurati di reindirizzare le operazioni di scrittura dell'applicazione all' read/write endpoint appropriato del proxy associato al nuovo cluster primario. Questo endpoint proxy potrebbe essere l'endpoint predefinito o un endpoint personalizzato. read/write Per ulteriori informazioni, consulta Come funzionano gli endpoint Server proxy per RDS con i database globali.
È possibile eseguire uno switchover di Aurora Global Database utilizzando l'API Console di gestione AWS AWS CLI, the o RDS.
Esecuzione dello switchover nel database globale Aurora
Accedi a Console di gestione AWS e apri la console Amazon RDS all'indirizzo https://console.aws.amazon.com/rds/
. -
Scegli Database e individua il Database globale Aurora in cui intendi eseguire lo switchover.
-
Scegli Switchover o failover database globale nel menu Operazioni.
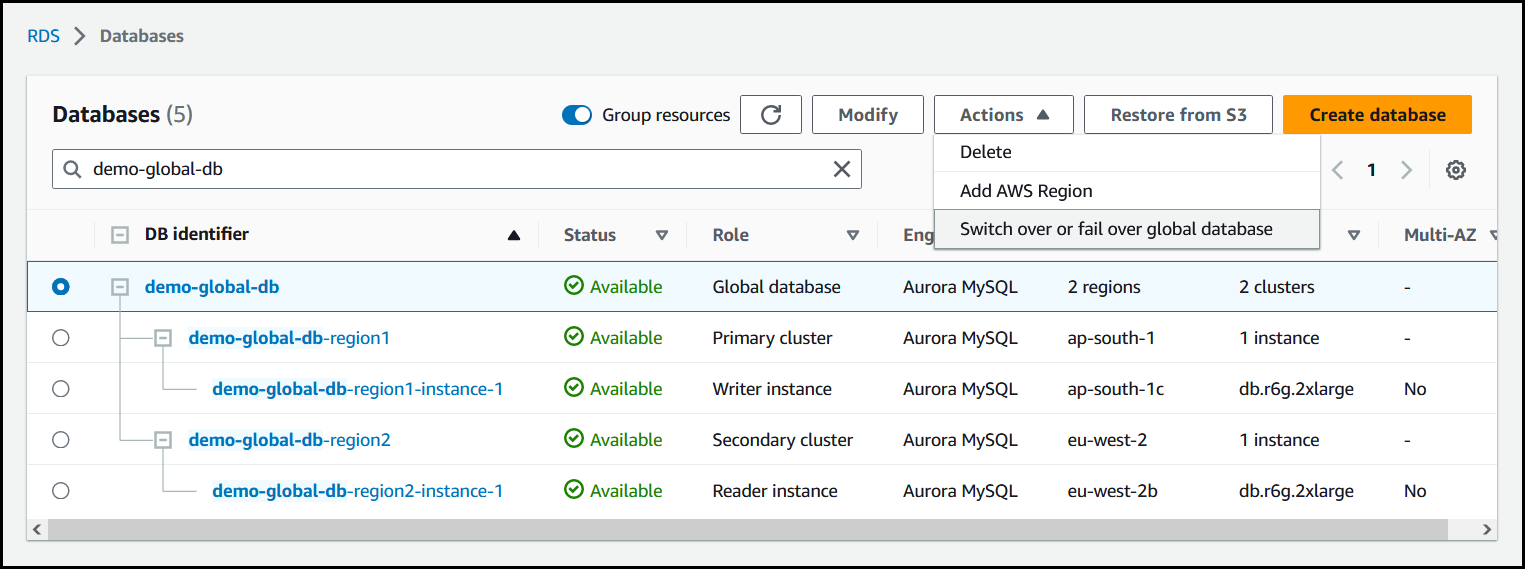
-
Scegli Switchover.
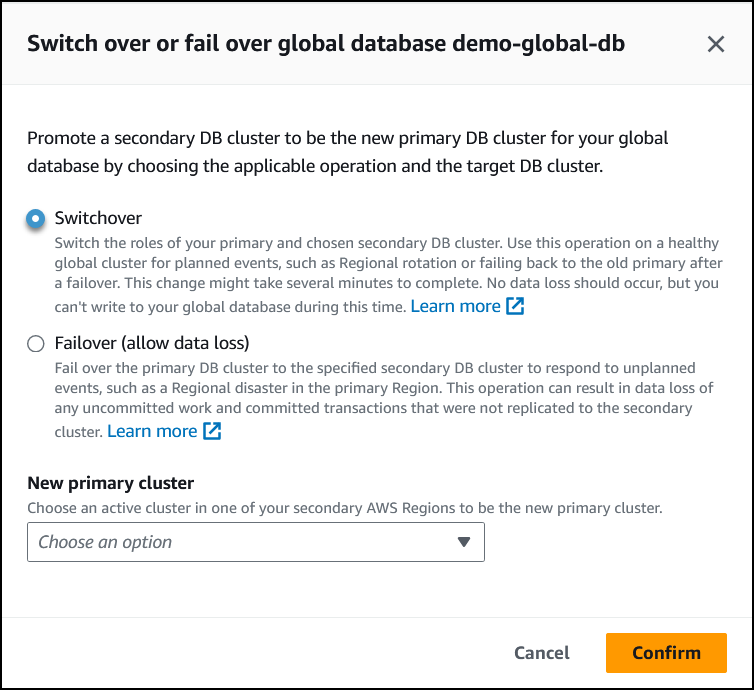
-
In Nuovo cluster primario, scegli un cluster attivo in una delle Regioni AWS secondarie da promuovere a nuovo cluster primario.
-
Scegli Conferma.
Al termine dello switchover, potrai visualizzare i cluster database Aurora e il relativo stato corrente nell'elenco Database, come illustrato nella figura seguente.
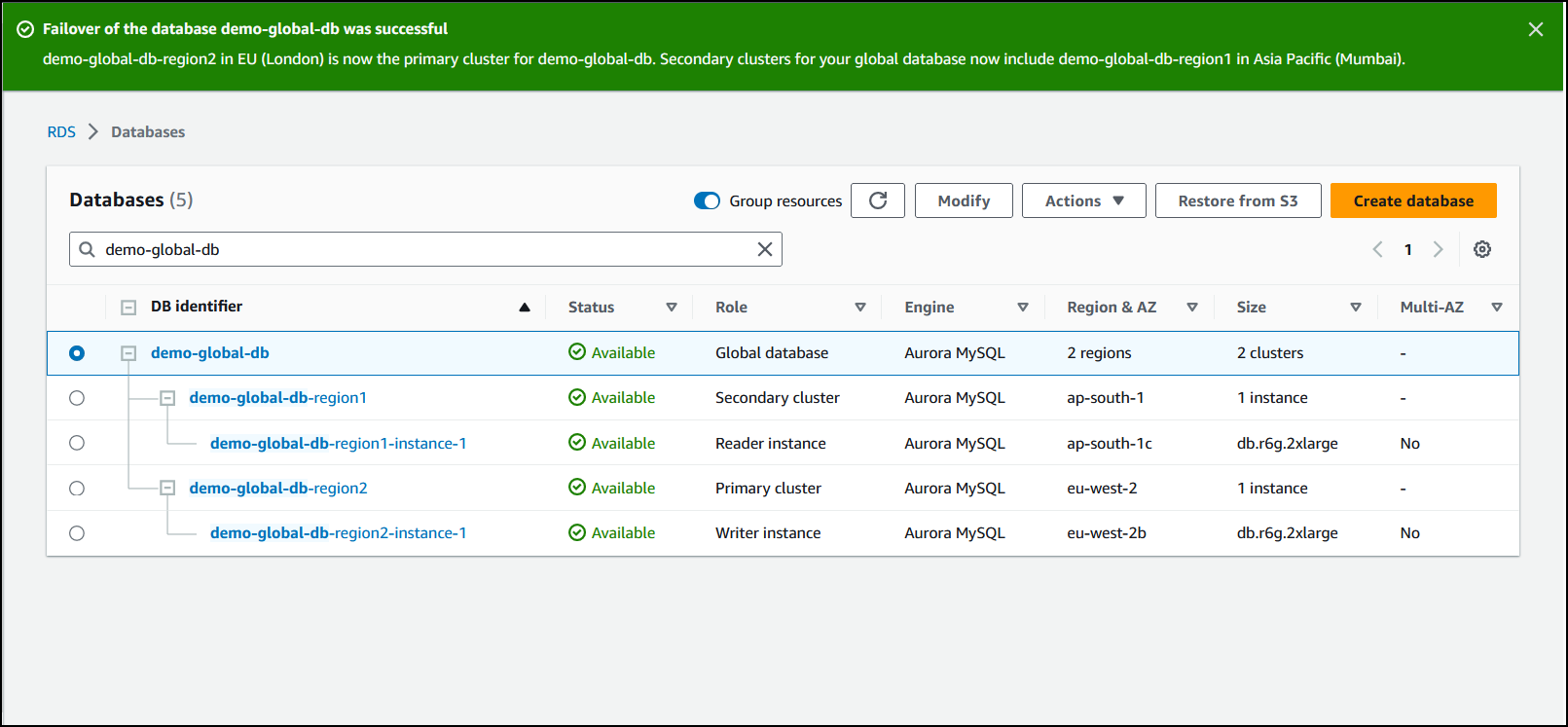
Esecuzione dello switchover nel database globale Aurora
Utilizza il comando CLI switchover-global-cluster per eseguire lo switchover per il Database globale Aurora. Questo comando consente di passare i valori per i seguenti parametri.
-
--region— Specificare la Regione AWS posizione in cui è in esecuzione il cluster DB primario del database globale Aurora. -
--global-cluster-identifier– Specifica il nome del database globale Aurora. -
--target-db-cluster-identifier– Specifica l'Amazon Resource Name (ARN) del cluster di database Aurora che si desidera promuovere come principale per il database globale Aurora.
Per Linux, macOS o Unix:
aws rds --regionregion_of_primary\ switchover-global-cluster --global-cluster-identifierglobal_database_id\ --target-db-cluster-identifierarn_of_secondary_to_promote
Per Windows:
aws rds --regionregion_of_primary^ switchover-global-cluster --global-cluster-identifierglobal_database_id^ --target-db-cluster-identifierarn_of_secondary_to_promote
Per eseguire uno switchover per Aurora Global Database, esegui l'operazione API. SwitchoverGlobalCluster
Ripristino di un database globale Amazon Aurora da un'interruzione non pianificata
In rare occasioni, il database globale Aurora potrebbe subire un'interruzione imprevista del database primario. Regione AWS In questo caso, il cluster database Aurora primario e il relativo nodo di scrittura non sono disponibili e la replica tra il cluster database primario e secondari viene interrotta. Per ridurre al minimo i tempi di inattività (RTO) e la perdita di dati (RPO), puoi eseguire un failover tra regioni.
Database globale Aurora offre due metodi di failover da utilizzare in una situazione di disaster recovery:
-
Failover gestito: questo metodo è consigliato in situazioni che prevedono il ripristino di emergenza. Quando si utilizza questo metodo, Aurora aggiunge automaticamente la vecchia regione primaria al database globale come regione secondaria quando diventa nuovamente disponibile. Pertanto, viene mantenuta la topologia originale del cluster globale. Per informazioni su come utilizzare questo metodo, consulta Esecuzione di failover gestiti per database globali Aurora.
-
Failover manuale: questo metodo alternativo può essere utilizzato quando il failover gestito non è un'opzione, ad esempio quando le regioni primarie e secondarie utilizzano versioni del motore non compatibili. Per informazioni su come utilizzare questo metodo, consulta Esecuzione di failover manuali per i Database globali Aurora.
Importante
Entrambi i metodi di failover possono comportare la perdita dei dati delle transazioni di scrittura che non sono stati replicati sul dispositivo secondario scelto prima che si verificasse l'evento di failover. Tuttavia, il processo di ripristino che promuove un'istanza database sul cluster database secondario scelto come istanza database di scrittura principale garantisce che i dati si trovino in uno stato transazionale coerente. I failover sono inoltre soggetti a problemi di tipo split-brain.
Esecuzione di failover gestiti per database globali Aurora
Questo approccio è destinato alla continuità aziendale in caso di una reale emergenza a livello regionale o di un'interruzione completa del livello di servizio.
Durante un failover gestito, il cluster secondario nella Regione secondaria scelta diventa il nuovo cluster primario. Il cluster secondario scelto promuove uno dei suoi nodi di sola lettura allo stato di istanza di scrittura completa. Questo passaggio consente al cluster di assumere il ruolo di cluster primario. Il database non sarà disponibile per un breve periodo di tempo mentre il cluster sta assumendo il suo nuovo ruolo. Non appena la precedente Regione primaria è di nuovo integra e disponibile, Aurora la aggiunge automaticamente al cluster globale come Regione secondaria. Pertanto, viene mantenuta la topologia di replica esistente del Database globale Aurora.
Nota
Per gestire gli slot di replica per Aurora PostgreSQL dopo aver eseguito un failover, consulta Gestione degli slot logici per Aurora PostgreSQL.
Nota
È possibile eseguire failover gestiti tra Regioni con il Database globale Aurora solo se i cluster di database primario e secondario hanno le stesse versioni principale e secondaria del motore. A seconda del motore e delle versioni del motore, può essere necessario che i livelli di patch siano identici oppure possono essere diversi. Per un elenco dei motori e delle versioni dei motori che consentono queste operazioni tra cluster primari e secondari con diversi livelli di patch, consulta Compatibilità del livello di patch per switchover e failover gestiti tra regioni. Prima di iniziare il failover, controlla le versioni del motore nel cluster globale per assicurarti che supportino lo switchover gestito tra Regioni e, se necessario, aggiornale. Se le versioni dei motori richiedono livelli di patch identici ma utilizzano livelli di patch diversi, puoi eseguire il failover manualmente tramite la procedura indicata in Esecuzione di failover manuali per i Database globali Aurora.
Il failover gestito non attende la sincronizzazione dei dati tra la Regione secondaria scelta e la Regione primaria corrente. Poiché Aurora Global Database replica i dati in modo asincrono, è possibile che non tutte le transazioni siano state replicate AWS nella regione secondaria scelta prima che questa venga promossa ad accettare tutte le funzionalità. read/write
Per garantire che i dati siano in uno stato coerente, Aurora crea un nuovo volume di archiviazione per la precedente Regione primaria dopo il ripristino. Prima di creare il nuovo volume di archiviazione nella AWS regione, Aurora tenta di scattare un'istantanea del vecchio volume di archiviazione nel punto in cui si è verificato l'errore. Questo consente di ripristinare lo snapshot e recuperare i dati mancanti. Se questa operazione ha esito positivo, Aurora inserisce questo snapshot denominato rds:unplanned-global-failover- nella sezione Snapshot della Console di gestione AWS. È inoltre possibile utilizzare il name-of-old-primary-DB-cluster-timestampdescribe-db-cluster-snapshots AWS CLI comando o l'operazione DescribeDBClusterSnapshots API per visualizzare i dettagli dell'istantanea.
Quando si avvia un failover gestito, Aurora tenta anche di arrestare il traffico di scrittura nel livello di archiviazione Aurora ad alta disponibilità. Questo meccanismo è chiamato “write fencing”. Se il processo ha esito positivo, Aurora emette un evento RDS per indicare che le scritture sono state interrotte. Nell’improbabile eventualità che si verifichino più errori AZ in una Regione, è possibile che il processo di write fencing non abbia esito positivo tempestivamente. In tal caso, Aurora emette un evento RDS che informa l’utente che si è verificato il timeout del processo di interruzione delle scritture. Se il cluster primario precedente è raggiungibile sulla rete, Aurora vi registra questi eventi. In caso contrario, Aurora registra gli eventi sul nuovo cluster primario. Per ulteriori informazioni su questi eventi, consulta Eventi di cluster di database. Poiché il fencing di scritture è un tentativo migliore possibile, è possibile che le scritture vengano momentaneamente accettate nella Regione primaria precedente, causando problemi di tipo split-brain.
È consigliabile completare le seguenti attività prima di eseguire un failover con Database globale Aurora. In questo modo si riduce al minimo l’incidenza di problemi di tipo split-brain o il ripristino di dati non replicati dallo snapshot del cluster primario precedente.
-
Per impedire l’invio di scrittura al cluster primario del Database globale Aurora, metti offline le applicazioni.
-
Assicurati che tutte le applicazioni che si connettono al cluster di database primario utilizzino l’endpoint di scrittura globale. Questo endpoint ha un valore che rimane invariato anche quando una nuova Regione diventa il cluster primario a causa dello switchover o del failover. Aurora implementa misure di protezione aggiuntive per ridurre al minimo la possibilità di perdita di dati per le operazioni di scrittura inviate tramite l’endpoint globale. Per ulteriori informazioni sugli endpoint di scrittura globali, consulta Connessione a Database globale Amazon Aurora.
-
Se utilizzi l’endpoint di scrittura globale e i livelli applicativi o di rete memorizzano nella cache i valori DNS, imposta il time-to-live (TTL) della cache DNS su un valore più basso, ad esempio 5 secondi. In questo modo, l’applicazione registra rapidamente le modifiche DNS con l’endpoint di scrittura globale. Sebbene Aurora tenti di bloccare le scritture nella vecchia Regione primaria, non è garantito che l’azione riesca. La riduzione della durata della cache DNS riduce ulteriormente la probabilità di problemi di tipo split-brain. In alternativa, puoi verificare la presenza dell’evento RDS che ti indica quando Aurora ha osservato le modifiche DNS per l’endpoint di scrittura globale. In questo modo, puoi verificare che l’applicazione abbia registrato anche la modifica DNS prima di riavviare il traffico di scrittura dell’applicazione.
-
Controllare i tempi di ritardo per tutti i cluster di database Aurora secondari nel Database globale Aurora. La scelta della regione secondaria con il minor ritardo di replica può ridurre al minimo la perdita di dati relativamente all'attuale regione primaria in stato di errore.
Per tutte le versioni dei database PostgreSQL-based globali Aurora e per i database MySQL-based globali Aurora a partire dalle versioni del motore 3.04.0 e successive o 2.12.0 e successive, usa CloudWatch Amazon per visualizzare la metrica per tutti
AuroraGlobalDBRPOLagi cluster DB secondari. Per le versioni minori inferiori dei database MySQL-based globali di Aurora, visualizza invece laAuroraGlobalDBReplicationLagmetrica. Questa metrica indica il ritardo (in millisecondi) della replica tra un cluster secondario e il cluster database primario.Per ulteriori informazioni sulle CloudWatch metriche per Aurora, consulta. Cluster-level metriche per Amazon Aurora
Durante un failover gestito, il cluster database secondario scelto viene promosso al nuovo ruolo primario. Tuttavia, non eredita le varie opzioni di configurazione del cluster di database primario. Una mancata corrispondenza nella configurazione può causare problemi di prestazioni, incompatibilità dei carichi di lavoro e altri comportamenti anomali. Per evitare tali problemi, è consigliabile risolvere le differenze tra i cluster di database globali Aurora per quanto segue:
-
Configura il gruppo di parametri del cluster di database Aurora per il nuovo primario, se necessario – Puoi configurare i gruppi di parametri del cluster di database Aurora in modo indipendente per ogni cluster Aurora del Database globale Aurora. Pertanto, quando si promuove un cluster database secondario perché assuma il ruolo primario, il gruppo di parametri dal cluster secondario potrebbe essere configurato in modo diverso rispetto al cluster primario. In tal caso, modifica il gruppo di parametri del cluster di database secondario promosso in modo che sia conforme alle impostazioni del cluster primario. Per scoprire come, consulta Modifica dei parametri per un database globale Aurora.
-
Configura strumenti e opzioni di monitoraggio, come Amazon CloudWatch Events e allarmi: configura il cluster DB promosso con la stessa capacità di registrazione, gli allarmi e così via necessari per il database globale. Come per i gruppi di parametri, la configurazione di queste funzionalità non viene ereditata dal primario durante il processo di failover. Alcune CloudWatch metriche, come il ritardo di replica, sono disponibili solo per le regioni secondarie. Pertanto, un failover modifica il modo in cui visualizzare tali metriche e impostare i relativi allarmi e potrebbe richiedere modifiche da apportare a qualsiasi dashboard predefinito. Per ulteriori informazioni sul monitoraggio dei cluster di database Aurora, consulta Monitoraggio Amazon Aurora metriche con Amazon CloudWatch.
-
Configura le integrazioni con altri AWS servizi: se Aurora Global Database si integra con AWS altri servizi, Gestione dei segreti AWS come AWS Identity and Access Management Amazon S3 AWS Lambda e, devi assicurarti che questi siano configurati come richiesto per l'accesso da qualsiasi regione secondaria. Per ulteriori informazioni sull'integrazione dei database globali Aurora con IAM, Amazon S3 e Lambda, consulta Utilizzo dei database globali di Amazon Aurora con altri servizi AWS. Per ulteriori informazioni su Secrets Manager, consulta Come automatizzare la replica dei segreti in Gestione dei segreti AWS across
. Regioni AWS
In genere, il cluster secondario scelto assume il ruolo primario entro pochi minuti. Non appena l’istanza database di scrittura della nuova Regione primaria è disponibile, puoi connettervi le tue applicazioni e riprendere i tuoi carichi di lavoro. Dopo aver promosso il nuovo cluster primario, Aurora ricostruisce automaticamente tutti i cluster secondari regionali aggiuntivi.
Poiché i database globali Aurora utilizzano la replica asincrona, il ritardo di replica in ciascuna regione secondaria può variare. Aurora ricostruisce queste regioni secondarie in modo che abbiano esattamente gli stessi dati point-in-time del nuovo cluster regionale primario. La durata dell'attività di ricostruzione completa può richiedere da alcuni minuti a diverse ore, a seconda delle dimensioni del volume di archiviazione e della distanza tra regioni. Quando i cluster regionali secondari terminano la ricostruzione in base alla nuova regione primaria, diventano disponibili per l'accesso in lettura.
Non appena la nuova istanza di scrittura primaria viene promossa e risulta disponibile, il cluster della nuova regione primaria può gestire le operazioni di lettura e scrittura per il database globale Aurora.
Se utilizzi l’endpoint globale, non occorre cambiare le impostazioni di connessione nell’applicazione. Verifica che le modifiche al DNS si siano propagate e che sia possibile connettersi ed eseguire operazioni di scrittura sul nuovo cluster primario. Potrai quindi riprendere la piena operatività dell’applicazione.
Se non utilizzi l’endpoint globale, assicurati di modificare l’endpoint dell’applicazione in modo che utilizzi l’endpoint del cluster per il cluster di database primario appena promosso. Se hai accettato i nomi forniti al momento della creazione del database globale Aurora, puoi modificare l'endpoint rimuovendo -ro dalla stringa endpoint del cluster promosso nell'applicazione.
Ad esempio, l'endpoint del cluster secondario my-global.cluster-ro-aaaaaabbbbbb.us-west-1.rds.amazonaws.com diventa my-global.cluster-aaaaaabbbbbb.us-west-1.rds.amazonaws.com quando tale cluster viene promosso a primario.
Se utilizzi RDS Proxy, assicurati di reindirizzare le operazioni di scrittura dell'applicazione all' read/write endpoint appropriato del proxy associato al nuovo cluster primario. Questo endpoint proxy potrebbe essere l'endpoint predefinito o un endpoint personalizzato. read/write Per ulteriori informazioni, consulta Come funzionano gli endpoint Server proxy per RDS con i database globali.
Per ripristinare la topologia originale del cluster database globale, Aurora monitora la disponibilità della vecchia regione primaria. Non appena tale regione è di nuovo integra e disponibile, Aurora la aggiunge automaticamente al cluster globale come regione secondaria. Prima di creare il nuovo volume di archiviazione nella vecchia regione primaria, Aurora tenta di acquisire uno snapshot del vecchio volume di archiviazione nel punto in cui si è verificato l'errore. Ciò consente di usare lo snapshot per recuperare i dati mancanti. Se questa operazione ha esito positivo, Aurora crea uno snapshot denominato rds:unplanned-global-failover-. Questo snapshot è disponibile nella sezione Snapshot di Console di gestione AWS. Puoi anche vedere questa istantanea elencata nelle informazioni restituite dall'operazione API. DescribeDBClusterSnapshots name-of-old-primary-DB-cluster-timestamp
Nota
Lo snapshot del vecchio volume di archiviazione è uno snapshot del sistema soggetto al periodo di conservazione del backup configurato sul vecchio cluster primario. Per conservare questo snapshot oltre il periodo di conservazione, puoi copiarlo e salvarlo come snapshot manuale. Per ulteriori informazioni sulla copia degli snapshot, inclusi i prezzi, consulta Copia di uno snapshot del cluster di database.
Dopo il ripristino della topologia originale, puoi eseguire il failback del database globale nella regione primaria originale eseguendo un'operazione di switchover nel momento più opportuno per l'azienda e il carico di lavoro. A tale scopo, segui la procedura in Esecuzione di switchover per database globali Amazon Aurora.
È possibile eseguire un failover con Aurora Global Database utilizzando Console di gestione AWS l'API, AWS CLI the o RDS.
Esecuzione del failover gestito nel database globale Aurora
Accedi a Console di gestione AWS e apri la console Amazon RDS all'indirizzo https://console.aws.amazon.com/rds/
. -
Scegli Database e individua il Database globale Aurora di cui desideri eseguire il failover.
-
Scegli Switchover o failover database globale nel menu Operazioni.
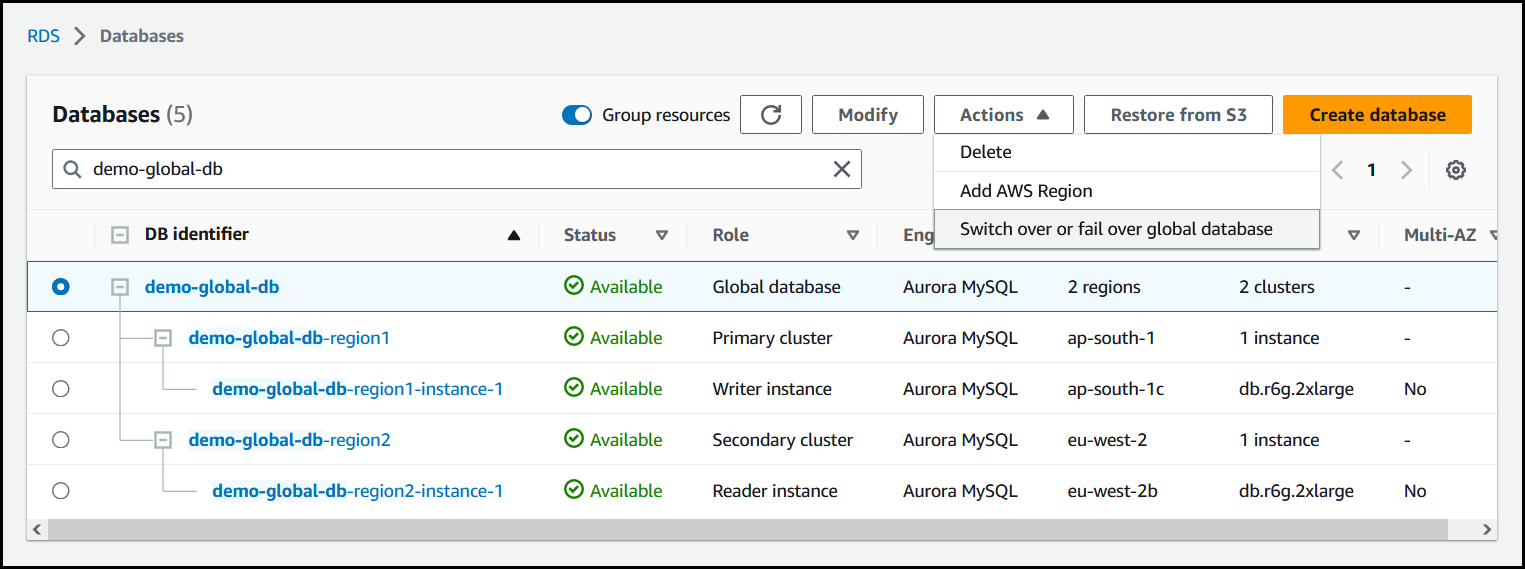
-
Scegli Failover (consenti perdita di dati).

-
In Nuovo cluster primario, scegli un cluster attivo in una delle Regioni AWS secondarie da promuovere a nuovo cluster primario.
-
Immetti
confirm, quindi scegli Conferma.
Al termine del failover, potrai visualizzare i cluster di database Aurora e il relativo stato corrente nell’elenco Database, come illustrato nella figura seguente.
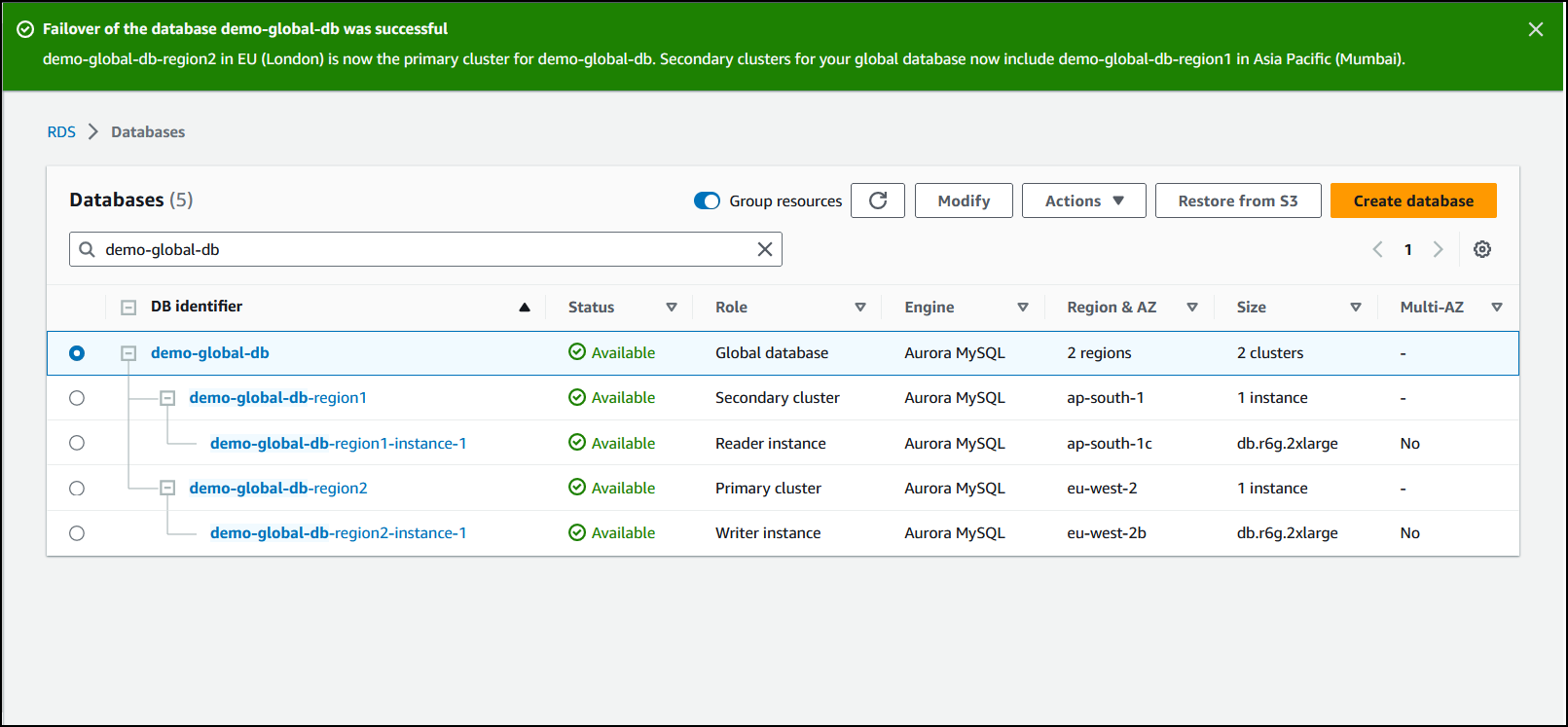
Esecuzione del failover gestito nel database globale Aurora
Utilizza il comando della CLI failover-global-cluster per eseguire il failover con il Database globale Aurora. Questo comando consente di passare i valori per i seguenti parametri.
-
--region— Specificare la posizione Regione AWS in cui è in esecuzione il cluster DB secondario che si desidera utilizzare come nuovo primario per il database globale Aurora. -
--global-cluster-identifier– Specifica il nome del database globale Aurora. -
--target-db-cluster-identifier: specifica il nome della risorsa Amazon (ARN) del cluster database Aurora che desideri promuovere a nuovo cluster primario per il database globale Aurora. -
--allow-data-loss: imposta in modo esplicito un'operazione di failover anziché un'operazione di switchover. Un'operazione di failover può causare una perdita di dati se i componenti della replica asincrona non hanno completato l'invio di tutti i dati replicati alla regione secondaria.
Per Linux, macOS o Unix:
aws rds --regionregion_of_selected_secondary\ failover-global-cluster --global-cluster-identifierglobal_database_id\ --target-db-cluster-identifierarn_of_secondary_to_promote\ --allow-data-loss
Per Windows:
aws rds --regionregion_of_selected_secondary^ failover-global-cluster --global-cluster-identifierglobal_database_id^ --target-db-cluster-identifierarn_of_secondary_to_promote^ --allow-data-loss
Per eseguire un failover con Aurora Global Database, esegui FailoverGlobalClusterl'operazione API.
Esecuzione di failover manuali per i Database globali Aurora
In alcuni scenari, puoi non essere in grado di utilizzare il processo di failover gestito. Un esempio è quando i cluster database primario e secondari non utilizzano versioni del motore compatibili. In questo caso, puoi usare questa procedura manuale per eseguire un failover nella Regione secondaria di destinazione.
Suggerimento
Si consiglia di comprendere questo processo prima di utilizzarlo. Prepara un piano per procedere rapidamente al primo segno di Region-wide problema. Puoi essere pronto a identificare la regione secondaria con il minor ritardo di replica utilizzando Amazon CloudWatch regolarmente per tenere traccia dei tempi di ritardo per i cluster secondari. Assicurati di testare il piano per verificare che le procedure siano complete e accurate e che il personale sia addestrato per eseguire un failover in caso di ripristino di emergenza prima che ciò avvenga realmente.
Per eseguire un failover manuale in un cluster secondario dopo un’interruzione non pianificata nella Regione primaria
-
Interrompi l'emissione di istruzioni DML e altre operazioni di scrittura sul cluster di database Aurora primario nella Regione AWS con l'interruzione.
-
Identifica un cluster Aurora DB da un secondario da Regione AWS utilizzare come nuovo cluster DB primario. Se hai due o più file secondari Regioni AWS nel tuo database globale Aurora, scegli il cluster secondario con il minor ritardo di replica.
-
Scollega il cluster di database secondario scelto dal database globale Aurora.
La rimozione di un cluster DB secondario da un database globale Aurora interrompe immediatamente la replica dal primario a questo secondario e la promuove in un cluster Aurora DB con provisioning autonomo con funzionalità complete. read/write Tutti gli altri cluster di database Aurora secondari associati al cluster primario nella regione con interruzione sono ancora disponibili e possono accettare chiamate dall'applicazione. Inoltre consumano risorse. Poiché si sta ricreando il database globale Aurora, rimuovi gli altri cluster di database secondari prima di creare il nuovo database globale Aurora nei passaggi seguenti. In questo modo, si evitano incongruenze di dati tra i cluster di database nel database globale Aurora (problemi di split-brain).
Per i passaggi dettagliati per lo scollegamento, consulta Rimozione di un cluster da un database globale Amazon Aurora.
-
Riconfigura l'applicazione per inviare tutte le operazioni di scrittura a questo cluster di database Aurora ora autonomo utilizzando il nuovo endpoint. Se sono stati accettati i nomi forniti al momento della creazione del database globale Aurora, puoi modificare l'endpoint rimuovendo
-rodalla stringa endpoint del cluster nell'applicazione.Ad esempio, l'endpoint del cluster secondario
my-global.cluster-ro-aaaaaabbbbbb---us-west-1---rds.amazonaws.com.rproxy.govskope.cadiventamy-global---cluster-aaaaaabbbbbb---us-west-1---rds.amazonaws.com.rproxy.govskope.caquando tale cluster viene scollegato dal database globale Aurora.Questo cluster di database Aurora diventa il cluster primario di un nuovo database globale Aurora quando si inizia ad aggiungere regioni nel passaggio successivo.
Se utilizzi RDS Proxy, assicurati di reindirizzare le operazioni di scrittura dell'applicazione all' read/write endpoint appropriato del proxy associato al nuovo cluster primario. Questo endpoint proxy potrebbe essere l'endpoint predefinito o un endpoint personalizzato. read/write Per ulteriori informazioni, consulta Come funzionano gli endpoint Server proxy per RDS con i database globali.
-
Aggiungi un Regione AWS al cluster DB. Quando esegui questa operazione, inizia il processo di replica da primario a secondario. Per i passaggi dettagliati per aggiungere una regione, consulta Aggiungere un Regione AWS a un database globale di Amazon Aurora.
-
Aggiungine altro Regioni AWS se necessario per ricreare la topologia necessaria per supportare l'applicazione.
Assicurati che le scritture delle applicazioni vengano inviate al cluster di database Aurora corretto prima, durante e dopo aver apportato queste modifiche. In questo modo, si evitano incongruenze di dati tra i cluster di database nel database globale Aurora (problemi di split-brain).
Se la riconfigurazione è avvenuta in risposta a un'interruzione in un Regione AWS Regione AWS A tale scopo, aggiungete il vecchio Regione AWS al nuovo database globale e quindi utilizzate il processo di passaggio per cambiarne il ruolo. Il database globale Aurora deve utilizzare una versione di Aurora PostgreSQL o Aurora MySQL che supporti gli switchover. Per ulteriori informazioni, consulta Esecuzione di switchover per database globali Amazon Aurora.
Gestione degli RPO per database globali basati su Aurora PostgreSQL–
Con un database globale basato su Aurora PostgreSQL, puoi gestire l'obiettivo del punto di ripristino (RPO) per il database globale Aurora utilizzando il parametro rds.global_db_rpo. RPO rappresenta la quantità massima di dati che possono essere persi in caso di interruzione.
Quando si imposta un RPO per il database globale basato su Aurora PostgreSQL–, Aurora controlla il tempo di ritardo RPO di tutti i cluster secondari per assicurarsi che almeno un cluster secondario rimanga all'interno della finestra RPO di destinazione. Il tempo di ritardo RPO è un altro parametro basato sul tempo.
L'RPO viene utilizzato quando il database riprende le operazioni in uno nuovo dopo un failover. Regione AWS Aurora valuta i tempi di ritardo RPO e RPO per eseguire il commit (o il blocco) delle transazioni sulla regione principale come segue:
-
Conferma la transazione se almeno un cluster di database secondario ha un tempo di ritardo RPO inferiore rispetto all'RPO.
-
Blocca la transazione se tutti i cluster di database secondari hanno tempi di ritardo RPO superiori all'RPO. Registra inoltre l'evento nel file di log di PostgreSQL ed emette eventi di “attesa” che mostrano le sessioni bloccate.
In altre parole, se tutti i cluster secondari sono dietro l'RPO di destinazione, Aurora sospende le transazioni sul cluster primario fino al raggiungimento di almeno uno dei cluster secondari. Le transazioni in pausa vengono nuovamente eseguite non appena il tempo di ritardo di almeno un cluster di database secondario diventa inferiore all'RPO. Il risultato è che nessuna transazione può eseguire il commit fino al raggiungimento dell'RPO.
Il parametro rds.global_db_rpo è dinamico. Se decidi che non vuoi che tutte le transazioni di scrittura si blocchino fino a quando il ritardo non diminuisce a un livello sufficiente, puoi ripristinarlo rapidamente. In questo caso, Aurora riconosce e implementa la modifica dopo un breve ritardo.
Importante
In un database globale con solo due AWS regioni, si consiglia di mantenere il valore predefinito del rds.global_db_rpo parametro nel gruppo di parametri della regione secondaria. In caso contrario, l'esecuzione di un failover dovuto alla perdita della AWS regione principale potrebbe causare la sospensione delle transazioni da parte di Aurora. Attendi invece che Aurora completi la ricostruzione del cluster nella vecchia AWS regione in cui si è verificata l'errore prima di modificare questo parametro per imporre un RPO massimo.
Se imposti questo parametro come descritto di seguito, puoi monitorare anche le metriche generate. Puoi eseguire questa operazione utilizzando psql o un altro strumento per interrogare il cluster di database primario del database globale Aurora e ottenere informazioni dettagliate sulle operazioni del database globale basato su Aurora PostgreSQL–. Per scoprire come, consulta Monitoraggio dei database globali di Aurora PostgreSQL-based.
Argomenti
Impostazione dell'obiettivo del punto di ripristino
Il parametro rds.global_db_rpo controlla l'impostazione RPO per un database PostgreSQL. Questo parametro è supportato da Aurora PostgreSQL. I valori validi per rds.global_db_rpo vanno da 20 secondi a 2.147.483.647 secondi (68 anni). Scegli un valore realistico per soddisfare le tue esigenze aziendali e il caso d'uso. Ad esempio, puoi consentire fino a 10 minuti per l'RPO, nel qual caso si imposta il valore su 600.
Puoi impostare questo valore per il database globale basato su Aurora PostgreSQL utilizzando la Console di gestione AWS, la AWS CLI o l’API RDS.
Per impostare l'RPO
Accedi a Console di gestione AWS e apri la console Amazon RDS all'indirizzo https://console.aws.amazon.com/rds/
. -
Sceglie il cluster primario del database Aurora globale e apri la scheda Configurazione per trovare il relativo gruppo di parametri del cluster di database. Ad esempio, il gruppo di parametri predefinito per un cluster di database primario che esegue Aurora PostgreSQL 11.7 è
default.aurora-postgresql11.I gruppi di parametri non possono essere modificati direttamente. Puoi invece procedere come descritto di seguito:
-
Crea un gruppo di parametri cluster di database personalizzato utilizzando il gruppo di parametri predefinito appropriato come punto di partenza. Ad esempio, crea un gruppo di parametri cluster di database personalizzato basato su
default.aurora-postgresql11. -
Nel gruppo di parametri database personalizzato, imposta il valore del parametro rds.global_db_rpo in modo da soddisfare il caso d'uso. I valori validi vanno da 20 secondi fino al valore intero massimo di 2.147.483.647 (68 anni).
-
Applica il gruppo di parametri del cluster di database modificato al cluster di database Aurora.
-
Per ulteriori informazioni, consulta Modifica dei parametri in un gruppo di parametri del cluster DB in Amazon Aurora.
Per impostare il parametro rds.global_db_rpo, utilizza il comando della CLI modify-db-cluster-parameter-group. Nel comando specifica il nome del gruppo di parametri del cluster primario e i valori per il parametro RPO.
Nell'esempio seguente l'RPO viene impostato su 600 secondi per il gruppo di parametri cluster di database primario denominato my_custom_global_parameter_group.
Per Linux, macOS o Unix:
aws rds modify-db-cluster-parameter-group \ --db-cluster-parameter-group-namemy_custom_global_parameter_group\ --parameters "ParameterName=rds.global_db_rpo,ParameterValue=600,ApplyMethod=immediate"
Per Windows:
aws rds modify-db-cluster-parameter-group ^ --db-cluster-parameter-group-namemy_custom_global_parameter_group^ --parameters "ParameterName=rds.global_db_rpo,ParameterValue=600,ApplyMethod=immediate"
Per modificare il rds.global_db_rpo parametro, utilizza l'operazione dell'ModifyDBClusterParameterGroupAPI Amazon RDS.
Visualizzazione dell'obiettivo del punto di ripristino
L'obiettivo del punto di ripristino (RPO) di un database globale viene memorizzato nel parametro rds.global_db_rpo. Puoi connettersi all'endpoint per il cluster secondario che si desidera visualizzare e utilizzare per psql eseguire una query sull'istanza per questo valore.
show rds.global_db_rpo;db-name=>
Se questo parametro non è impostato, la query restituirà quanto segue:
rds.global_db_rpo
-------------------
-1
(1 row)Questa risposta successiva proviene da un cluster di database secondario con impostazione RPO di 1 minuto.
rds.global_db_rpo
-------------------
60
(1 row) Puoi inoltre utilizzare la CLI per ottenere valori per scoprire se rds.global_db_rpo è attivo su uno qualsiasi dei cluster di database Aurora utilizzando l'interfaccia a riga di comando per ottenere i valori di tutti i parametri user per il cluster.
Per Linux, macOS o Unix:
aws rds describe-db-cluster-parameters \ --db-cluster-parameter-group-namelab-test-apg-global\ --source user
Per Windows:
aws rds describe-db-cluster-parameters ^ --db-cluster-parameter-group-namelab-test-apg-global* --source user
Il comando restituisce un output simile al seguente per tutti i parametri user che non sono parametri del cluster di database default-engine o system.
{
"Parameters": [
{
"ParameterName": "rds.global_db_rpo",
"ParameterValue": "60",
"Description": "(s) Recovery point objective threshold, in seconds, that blocks user commits when it is violated.",
"Source": "user",
"ApplyType": "dynamic",
"DataType": "integer",
"AllowedValues": "20-2147483647",
"IsModifiable": true,
"ApplyMethod": "immediate",
"SupportedEngineModes": [
"provisioned"
]
}
]
}
Per ulteriori informazioni sulla visualizzazione dei parametri del gruppo di parametri del cluster, consulta Visualizzazione dei valori dei parametri per un gruppo di parametri del cluster DB in Amazon Aurora.
Disattivazione dell'obiettivo del punto di ripristino
Per disabilitare l'RPO, reimpostare il parametro rds.global_db_rpo. È possibile reimpostare i parametri utilizzando Console di gestione AWS, AWS CLI o l’API RDS.
Per disabilitare l'RPO
Accedi a Console di gestione AWS e apri la console Amazon RDS all'indirizzo https://console.aws.amazon.com/rds/
. -
Nel riquadro di navigazione scegliere Parameter groups (Gruppi di parametri).
-
Nell'elenco scegliere il gruppo di parametri cluster DB primario.
-
Scegliere Edit parameters (Modifica parametri).
-
Scegliere la casella accanto al parametro rds.global_db_rpo.
-
Scegliere Reimposta.
-
Quando la schermata mostra Reimposta parametri nel gruppo di parametri DB, scegliere Reimposta parametri.
Per ulteriori informazioni su come reimpostare un parametro con la console, vedere Modifica dei parametri in un gruppo di parametri del cluster DB in Amazon Aurora.
Per reimpostare il parametro rds.global_db_rpo, utilizzare il comando reset-db-cluster-parameter-group.
Per Linux, macOS o Unix:
aws rds reset-db-cluster-parameter-group \ --db-cluster-parameter-group-nameglobal_db_cluster_parameter_group\ --parameters "ParameterName=rds.global_db_rpo,ApplyMethod=immediate"
Per Windows:
aws rds reset-db-cluster-parameter-group ^ --db-cluster-parameter-group-nameglobal_db_cluster_parameter_group^ --parameters "ParameterName=rds.global_db_rpo,ApplyMethod=immediate"
Per reimpostare il rds.global_db_rpo parametro, utilizza l'ResetDBClusterParameterGroupoperazione dell'API Amazon RDS.
