Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Connessione a Database globale Amazon Aurora
Ogni Database globale Aurora è dotato di un endpoint di scrittura che viene aggiornato automaticamente da Aurora per instradare le richieste all’istanza di scrittura corrente del cluster di database primario. Con l’endpoint di scrittura, non è necessario modificare la stringa di connessione dopo aver cambiato la posizione della Regione primaria utilizzando le funzionalità gestite di switchover e failover del Database globale Aurora. Per ulteriori informazioni sull’utilizzo dell’endpoint di scrittura insieme allo switchover e al failover del Database globale Aurora, consulta Utilizzo dello switchover o failover in un Database globale Amazon Aurora. Per informazioni sulla connessione a un Database globale Aurora con Server proxy per RDS, consulta Utilizzo del Server proxy per RDS con i database globali Aurora.
Argomenti
Scelta dell’endpoint che soddisfa le esigenze dell’applicazione
La connessione a un Database globale Aurora dipende dalla necessità di leggere o scrivere dal database e dalla Regione AWS a cui indirizzare le richieste. Ecco alcuni casi d’uso tipici:
-
Instradamento delle richieste all’istanza di scrittura: connettiti all’endpoint di scrittura Database globale Aurora se devi eseguire istruzioni DML (Data Manipulation Language) e DDL (Data Definition Language) o se ti serve una forte coerenza tra letture e scritture. Tale endpoint instrada le richieste all’istanza di scrittura nel cluster primario del database globale. Questo endpoint viene aggiornato automaticamente per instradare le richieste all’istanza di scrittura, eliminando la necessità di aggiornare l’applicazione ogni volta che si modifica la posizione di scrittura nel cluster globale. Puoi anche utilizzare l'endpoint globale per inviare read/write richieste interregionali al tuo scrittore.
Nota
Se hai configurato il database globale prima che l’endpoint di scrittura del Database globale Aurora fosse disponibile, l’applicazione potrebbe connettersi all’endpoint cluster del cluster primario. In questo caso, è consigliabile modificare le impostazioni di connessione in modo da utilizzare l’endpoint di scrittura globale. In questo modo si evita la necessità di modificare le impostazioni di connessione dopo ogni switchover o failover di Database globale Aurora.
La prima parte del nome dell’endpoint di scrittura è il nome del Database globale Aurora. Pertanto, se il Database globale Aurora viene rinominato, il nome dell’endpoint di scrittura cambia ed è necessario aggiornare tutto il codice che lo utilizza con il nuovo nome.
-
Ridimensionamento delle letture più vicino alla regione dell'applicazione: per ridimensionare le richieste di sola lettura nella stessa AWS regione o nelle vicinanze dell'applicazione, connettiti all'endpoint di lettura dei cluster Aurora primari o secondari.
-
Scalare le letture con scritture occasionali tra Regioni: per istruzioni DML occasionali, ad esempio per la manutenzione e la pulizia dei dati, connettiti all’endpoint di lettura di un cluster secondario con l’inoltro di scrittura abilitato. Con l’inoltro di scrittura, Aurora inoltra automaticamente le istruzioni di scrittura all’endpoint di scrittura nella Regione primaria del Database globale Aurora. L’inoltro di scrittura offre i seguenti vantaggi:
-
Non sono necessarie operazioni complesse per stabilire la connettività tra i cluster secondari e primari per inviare scritture tra Regioni.
-
Non è necessario dividere le richieste di lettura e scrittura nell’applicazione.
-
Non è necessario sviluppare una logica complessa per gestire la coerenza delle richieste di lettura dopo la scrittura.
Tuttavia, con l’inoltro di scrittura, è necessario aggiornare il codice o la configurazione dell’applicazione per connettersi all’endpoint di lettura della Regione primaria appena promossa dopo avere eseguito un failover o uno switchover tra Regioni. È consigliabile monitorare la latenza delle operazioni eseguite tramite l’inoltro di scrittura per controllare il sovraccarico di elaborazione delle richieste di scrittura. Infine, l’inoltro di scrittura non supporta determinate operazioni di MySQL o PostgreSQL, come l’esecuzione di modifiche DDL (Data Definition Language) o istruzioni
SELECT FOR UPDATE.Per ulteriori informazioni sull'utilizzo dell'inoltro della scrittura tra regioni, consulta. AWS Utilizzo dell'inoltro di scrittura in un database globale Amazon Aurora
-
Per dettagli sui diversi tipi di endpoint Aurora, consulta Connessione a un cluster database Amazon Aurora.
Visualizzazione degli endpoint di un database globale Amazon Aurora
Quando nella console è presente un Database globale Aurora, è possibile visualizzare tutti gli endpoint generici associati a tutti i relativi cluster. La figura seguente mostra un esempio dei tipi di endpoint che vengono mostrati quando si visualizzano i dettagli del cluster di database primario:
-
Global writer: l' read/write endpoint singolo che punta sempre all'istanza DB Writer corrente per il cluster di database globale.
-
Writer: l'endpoint di connessione per read/write le richieste al cluster DB primario nel cluster di database globale.
-
Endpoint di lettura: l’endpoint di connessione per le richieste di sola lettura a un cluster di database primario o secondario nel cluster di database globale. Per ridurre al minimo la latenza, scegli l'endpoint di lettura più vicino a te Regione AWS o a quello più vicino a te. Regione AWS
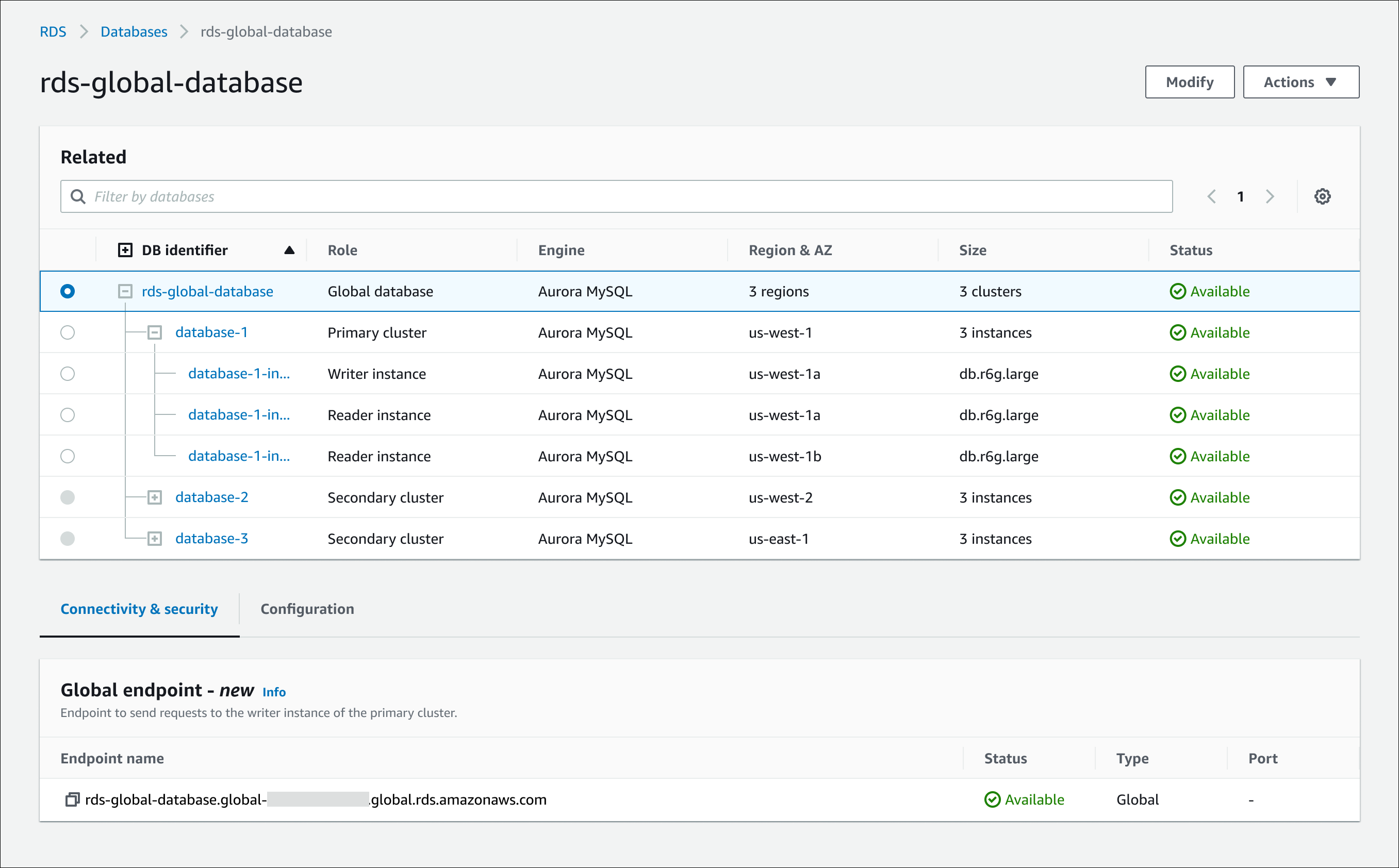
Per visualizzare gli endpoint di un database globale
-
Accedi a Console di gestione AWS e apri la console Amazon RDS all'indirizzo https://console.aws.amazon.com/rds/
. -
Nel pannello di navigazione, seleziona Database.
-
Nell’elenco scegli il database globale o il cluster di database primario o secondario di cui vuoi visualizzare gli endpoint.
-
Scegli la scheda Connettività e sicurezza per visualizzare i dettagli dell’endpoint. Gli endpoint visualizzati dipendono dal tipo di cluster selezionato, come indicato di seguito:
-
Database globale: l’endpoint di scrittura globale.
-
Cluster di database primario: l’endpoint di scrittura globale e l’endpoint del cluster e l’endpoint di lettura per il cluster primario.
-
Cluster di database secondario: l’endpoint del cluster e l’endpoint di lettura per il cluster secondario. In un cluster secondario, lo stato dell’endpoint del cluster è inattivo perché non gestisce le richieste di scrittura. È comunque possibile connettersi all’endpoint del cluster, ma solo per le query di lettura.
-
Per visualizzare l’endpoint di scrittura del cluster globale, usa il comando AWS CLI describe-global-clusters, come nell’esempio seguente.
aws rds describe-global-clusters --regionaws_region{ "GlobalClusters": [ { "GlobalClusterIdentifier": "global_cluster_id", "GlobalClusterResourceId": "cluster-unique_string", "GlobalClusterArn": "arn:aws:rds::123456789012:global-cluster:global_cluster_id", "Status": "available", "Engine": "aurora-mysql", "EngineVersion": "5.7.mysql_aurora.2.11.2", "GlobalClusterMembers": [ ... ], "Endpoint": "global_cluster_id.global-unique_string.global.rds.amazonaws.com" } ] }
Per visualizzare gli endpoint del cluster e di lettura per i cluster di database che fanno parte del cluster globale, usa il comando AWS CLI
describe-db-clusters, come nell’esempio seguente. I valori restituiti per Endpoint e ReaderEndpoint sono rispettivamente gli endpoint del cluster e di lettura.
aws rds describe-db-clusters --regionprimary_region--db-cluster-identifierdb_cluster_id{ "DBClusters": [ { "AllocatedStorage": 1, "AvailabilityZones": [ "az_1", "az_2", "az_3" ], "BackupRetentionPeriod": 1, "DBClusterIdentifier": "db_cluster_id", "DBClusterParameterGroup": "default.aurora-mysql5.7", "DBSubnetGroup": "default", "Status": "available", "EarliestRestorableTime": "2023-08-01T18:21:11.301Z", "Endpoint": "db_cluster_id.cluster-unique_string.primary_region.rds.amazonaws.com", "ReaderEndpoint": "db_cluster_id.cluster-ro-unique_string.primary_region.rds.amazonaws.com", "MultiAZ": false, "Engine": "aurora-mysql", "EngineVersion": "5.7.mysql_aurora.2.11.2", "ReadReplicaIdentifiers": [ "arn:aws:rds:secondary_region:123456789012:cluster:db_cluster_id" ], "DBClusterMembers": [ { "DBInstanceIdentifier": "db_instance_id", "IsClusterWriter": true, "DBClusterParameterGroupStatus": "in-sync", "PromotionTier": 1 } ], ... "TagList": [], "GlobalWriteForwardingRequested": false } ] }
Per visualizzare l'endpoint writer del cluster globale, utilizza l'operazione API RDS. DescribeGlobalClusters Per visualizzare gli endpoint del cluster e di lettura per i cluster di database che fanno parte del cluster globale, utilizza l’operazione DescribeDBClusters dell’API RDS.
Considerazioni sull’utilizzo degli endpoint di scrittura globali
Per utilizzare gli endpoint di scrittura del Database globale Aurora in modo efficiente, segui queste linee guida e best practice:
-
Per ridurre al minimo le interruzioni dopo un failover o uno switchover tra regioni, puoi configurare la connettività VPC tra l'elaborazione dell'applicazione e le regioni primarie e secondarie. AWS Ad esempio, supponiamo di avere applicazioni o sistemi client in esecuzione nello stesso VPC del cluster primario. Se il cluster secondario viene promosso, l’endpoint di scrittura globale cambia automaticamente in modo da puntare a quel cluster. Sebbene l'endpoint global writer consenta di evitare di modificare le impostazioni di connessione per l'applicazione, le applicazioni non possono accedere agli indirizzi IP nel VPC della AWS regione primaria appena promossa finché non si configura la rete tra i due VPC. Consulta le opzioni di connettività di Amazon VPC-to-Amazon VPC per valutare diverse opzioni per configurare questa connettività.
-
L’aggiornamento dell’endpoint di scrittura globale dopo uno switchover o un failover globale del database può richiedere molto tempo a seconda della durata della memorizzazione nella cache DNS (Domain Name Service). Per ulteriori informazioni, consulta Amazon Aurora MySQL Database Administrator’s Handbook. Il Database globale Aurora emette un evento RDS quando rileva la modifica del DNS sull’endpoint di scrittura globale. È possibile utilizzare l’evento per elaborare strategie per garantire che la cache DNS non si estenda oltre il periodo successivo alla generazione dell’evento. Per ulteriori informazioni, consulta Eventi di cluster di database.
-
Il Database globale Aurora replica i dati in modo asincrono. I metodi di failover tra Regioni possono comportare la presenza di dati delle transazioni di scrittura non replicati nella secondaria scelta prima dell’inizio del failover. Sebbene Aurora tenti con il massimo impegno di bloccare le scritture nella AWS regione primaria originale, il failover può essere soggetto a problemi di split-brain. Le considerazioni per ridurre al minimo la perdita di dati e il rischio di split-brain si applicano anche agli endpoint di scrittura del Database globale Aurora. Per ulteriori informazioni, consulta Esecuzione di failover gestiti per database globali Aurora.
