Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Plan de requête dans Amazon Redshift
Un plan de requête est une liste d'instructions que le moteur d'exécution doit suivre pour exécuter une requête sur les données. Vous pouvez créer un plan de requête en exécutant la commande EXPLAIN suivie du texte de la requête, comme le montre l'exemple de requête suivant :
EXPLAIN select s.s_name, sum(li.l_quantity) as quantity from tpch.lineitem li join tpch.orders o on o.o_orderkey = li.l_orderkey and o.o_orderdate > '1992-05-01' join tpch.supplier s on s.s_suppkey = li.l_suppkey group by s.s_name order by quantity desc limit 10;
Si vous exécutez la EXPLAIN commande correspondant à l'exemple de requête ci-dessus, vous obtenez le résultat suivant :
XN Limit (cost=1004400430902.15..1004400430902.17 rows=10 width=39) -> XN Merge (cost=1004400430902.15..1004400430926.97 rows=9928 width=39) Merge Key: sum(li.l_quantity) -> XN Network (cost=1004400430902.15..1004400430926.97 rows=9928 width=39) Send to leader -> XN Sort (cost=1004400430902.15..1004400430926.97 rows=9928 width=39) Sort Key: sum(li.l_quantity) -> XN HashAggregate (cost=4400430218.24..4400430243.06 rows=9928 width=39) -> XN Hash Join DS_BCAST_INNER (cost=21489.58..4400401726.35 rows=5698378 width=39) Hash Cond: ("outer".l_suppkey = "inner".s_suppkey) -> XN Hash Join DS_DIST_NONE (cost=21364.58..273387.85 rows=5698378 width=14) Hash Cond: ("outer".l_orderkey = "inner".o_orderkey) -> XN Seq Scan on lineitem li (cost=0.00..60012.15 rows=6001215 width=22) -> XN Hash (cost=17803.81..17803.81 rows=1424306 width=8) -> XN Seq Scan on orders o (cost=0.00..17803.81 rows=1424306 width=8) Filter: (o_orderdate > '1992-05-01'::date) -> XN Hash (cost=100.00..100.00 rows=10000 width=33) -> XN Seq Scan on supplier s (cost=0.00..100.00 rows=10000 width=33)
Note
L'exemple de sortie du plan de requête est une vue simplifiée de haut niveau de l'exécution des requêtes. L'exemple de plan n'illustre pas les détails du traitement parallèle des requêtes. Pour obtenir des informations détaillées, exécutez la requête, puis utilisez les vues SVL_QUERY_SUMMARY ou SVL_QUERY_REPORT pour obtenir les informations récapitulatives de la requête.
Éditeur de requête Amazon Redshift v2
Vous pouvez également consulter les plans de requêtes dans Amazon Redshift en utilisant l'option Explain de l'éditeur de requêtes v2. Pour obtenir des instructions, consultez la section Utilisation de l'éditeur de requêtes v2 dans la documentation Amazon Redshift.
Le plan de requête généré par l'éditeur de requêtes v2 inclut les informations suivantes :
-
Quelles opérations le moteur d'exécution effectue, en lisant les résultats de bas en haut
-
Quel type d'étape effectue chaque opération
-
Quelles tables et colonnes sont utilisées dans chaque opération
-
Quantité de données traitée lors de chaque opération, en termes de nombre de lignes et de largeur des données en octets
-
Le coût relatif de l'opération (le coût) est une mesure qui compare les temps d'exécution relatifs des étapes d'un plan. Le coût ne fournit pas d'informations précises sur les temps d'exécution réels ou la consommation de mémoire, et ne fournit pas non plus de comparaison significative entre les plans d'exécution. Le coût vous donne toutefois une indication des opérations d'une requête qui consomment le plus de ressources.)
EXPLIQUEZ les plans
Vous pouvez utiliser la table système STL_EXPLAIN pour afficher le EXPLAIN plan d'une requête soumise pour exécution. Dans l'ensemble, l'utilisation STL_EXPLAIN peut contribuer à améliorer les performances, l'efficacité et la rentabilité de vos requêtes Amazon Redshift.
Les avantages de l'utilisation STL_EXPLAIN sont les suivants :
-
Optimisation des performances :
STL_EXPLAINpermet d'identifier les zones d'une requête qui peuvent être optimisées pour de meilleures performances. -
Planification des requêtes :
STL_EXPLAINpeut fournir des informations sur la manière dont Amazon Redshift exécute la requête et peut aider à identifier les goulots d'étranglement potentiels liés à la requête. -
Débogage :
STL_EXPLAINpermet de diagnostiquer les problèmes liés à une requête en indiquant les étapes suivies par Amazon Redshift pour exécuter cette requête. -
Comprendre le comportement d'Amazon Redshift
STL_EXPLAINpeut fournir des informations sur la manière dont Amazon Redshift traite les requêtes. Cela peut vous aider à mieux comprendre le comportement d'Amazon Redshift. -
Optimisation des coûts :
STL_EXPLAINpeut fournir des informations sur le coût estimé d'une requête. Cela peut vous aider à identifier les domaines dans lesquels vous pouvez optimiser les coûts.
La requête suivante est un exemple qui renvoie les nœuds du plan pour une requête donnée :
select nodeid as id, plannode, info from stl_explain where query=1042904 order by nodeid;
La requête précédente renvoie le résultat suivant.
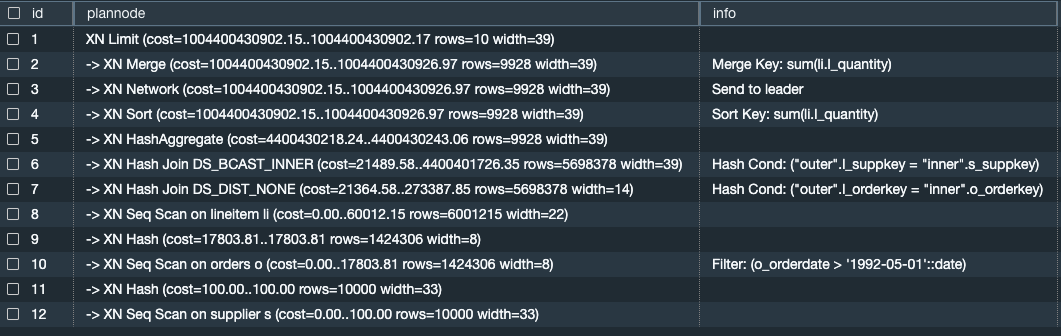
Le EXPLAIN plan renvoie des mesures utiles pour chaque opération, notamment des mesures relatives au coût, aux lignes et à la largeur. Par exemple, la ligne 7 de la requête précédente renvoie ce qui suit :
-> XN Hash Join DS_DIST_NONE (cost=21364.58..273387.85 rows=5698378 width=14)
Coût
Le coût est une valeur relative utile pour comparer les opérations au sein d'un plan. Le coût se compose de deux valeurs décimales séparées par deux points. Dans cet exemple, le coût est égal à21364.58..273387.85. Éléments à prendre en compte :
-
La première valeur (dans ce cas,
21364.58) indique le coût relatif du renvoi de la première ligne pour cette opération. -
La deuxième valeur (dans ce cas,
273387.85) indique le coût relatif de l'exécution de l'opération.
Les coûts du plan de requête sont cumulatifs et cumulés des lignes inférieures aux lignes supérieures. Dans l'exemple de sortie ci-dessus, la ligne 7 inclut le coût des autres opérations dans les lignes situées en dessous (c'est-à-dire les lignes 8 à 12 et au-delà).
Lignes
Le nombre de lignes est le nombre estimé de lignes à renvoyer. Dans cet exemple, le scan devrait renvoyer 5 698 378 lignes. L'estimation des lignes est basée sur les statistiques disponibles générées par la ANALYZE commande. Si ANALYZE elle n'a pas été réalisée récemment, l'estimation est moins fiable.
Largeur
La largeur est la largeur estimée de la ligne moyenne, en octets. Dans cet exemple, la largeur moyenne d'une ligne devrait être de 14 octets.
