Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Modèles de parallélisation et de diffusion
De nombreuses tâches avancées de raisonnement et de génération, telles que la synthèse de documents volumineux, l'évaluation de plusieurs solutions ou la comparaison de points de vue variés, tirent parti de l'exécution parallèle des instructions. Les flux de travail séquentiels traditionnels sont insuffisants lorsque l'évolutivité, la réactivité et la tolérance aux pannes sont requises. Pour surmonter ce problème, la parallélisation basée sur le LLM peut être réinventée à l'aide d'un modèle de collecte par dispersion piloté par des événements, dans lequel les tâches sont réparties dynamiquement vers des agents autonomes et les résultats synthétisés de manière intelligente.
Le schéma suivant est un exemple de flux de travail de parallélisation LLM :
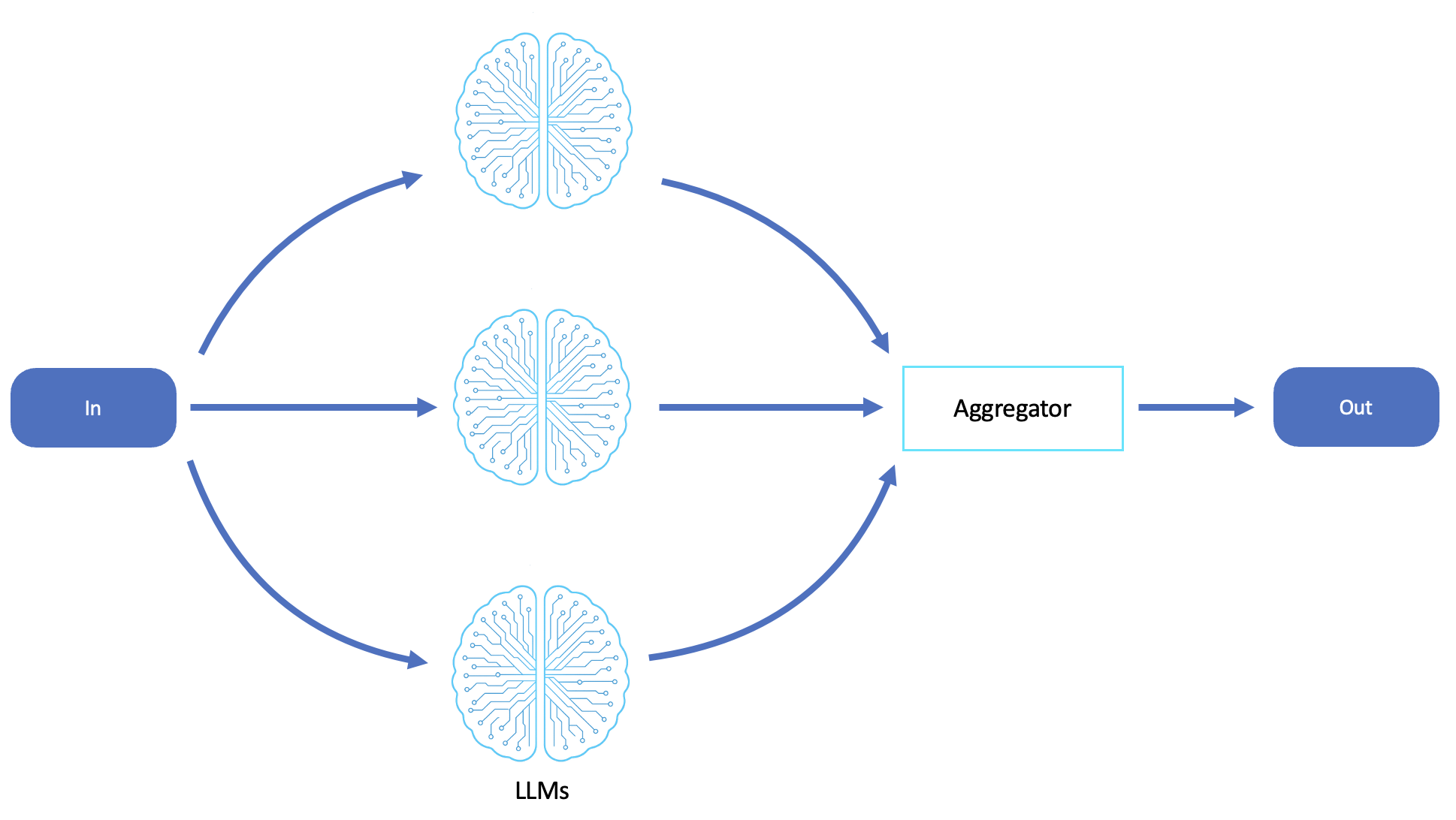
Dispersez et collectez
Dans les systèmes distribués, un modèle de collecte par dispersion envoie des tâches à plusieurs services ou unités de traitement en parallèle, attend leurs réponses, puis agrège les résultats dans une sortie consolidée. Contrairement au fan-out, le scatter-gather est coordonné car il attend des réponses et applique généralement une logique pour combiner, comparer et sélectionner les résultats.
Les implémentations courantes pour la parallélisation et le scatter-gather sont les suivantes :
-
AWS Step Functions mapper un état pour l'exécution de tâches en parallèle
-
AWS Lambda avec simultanéité, coordination des résultats de plusieurs fonctions invoquées
-
Amazon EventBridge avec des flux de travail IDs de corrélation et d'agrégation
-
Modèle de contrôleur personnalisé pour gérer le fan-out et recueillir des résultats à l'aide d'Amazon Simple Storage Service (Amazon S3), d'Amazon DynamoDB ou de files d'attente
Le schéma suivant est un exemple de scatter-gather :
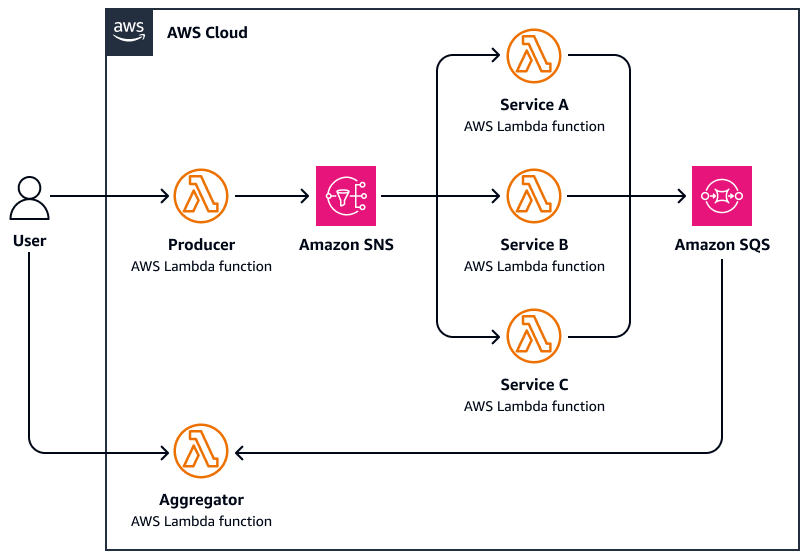
-
Un utilisateur envoie une demande à une fonction de coordination centrale qui répartit la tâche en publiant des messages parallèles sur une rubrique Amazon Simple Notification Service (Amazon SNS).
-
Chaque message inclut les métadonnées des tâches et est acheminé vers un travailleur AWS Lambda spécialisé.
-
Chaque collaborateur traite AWS Lambda indépendamment la sous-tâche qui lui est assignée (par exemple, interroger une API externe, traiter un document et analyser des données).
-
Les résultats sont écrits sur une couche de stockage commune, telle qu'Amazon Simple Queue Service (Amazon SQS).
-
La fonction d'agrégation attend que toutes les réponses soient terminées, puis elle effectue les opérations suivantes :
-
Rassemble et agrège les résultats (par exemple, fusionne les résumés, sélectionne les meilleures correspondances)
-
Envoie une réponse finale ou déclenche un flux de travail en aval
-
Les cas d'utilisation courants des modèles de dispersion sont les suivants :
-
Recherche fédérée
-
Moteurs de comparaison de prix
-
Analyse des données agrégées
-
Inférence multimodèle
Parallélisation basée sur le LLM (cognition par diffusion)
Dans les systèmes agentiques, la parallélisation reflète étroitement la diffusion en répartissant les sous-tâches entre plusieurs appels ou agents LLM, chacun abordant indépendamment une partie du problème. Les résultats renvoyés sont collectés et synthétisés par un processus d'agrégation, qui est souvent un autre LLM ou agent de contrôle.
Parallélisation des agents
-
Un agent soumet une demande « Résumez les informations issues de ces 10 rapports ».
-
Il répartit les rapports en 10 tâches de synthèse LLM parallèles.
-
Lorsqu'il renvoie tous les résumés, l'agent effectue les opérations suivantes :
-
Regroupe les résumés dans un briefing unifié
-
Identifie les thèmes ou les contradictions
-
Envoie la sortie synthétisée à l'utilisateur
-
Ce flux de travail agentique permet un raisonnement parallèle évolutif, modulaire et adaptatif. C'est idéal pour les cas d'utilisation nécessitant un débit cognitif élevé.
Le schéma suivant est un exemple de parallélisation d'agents :
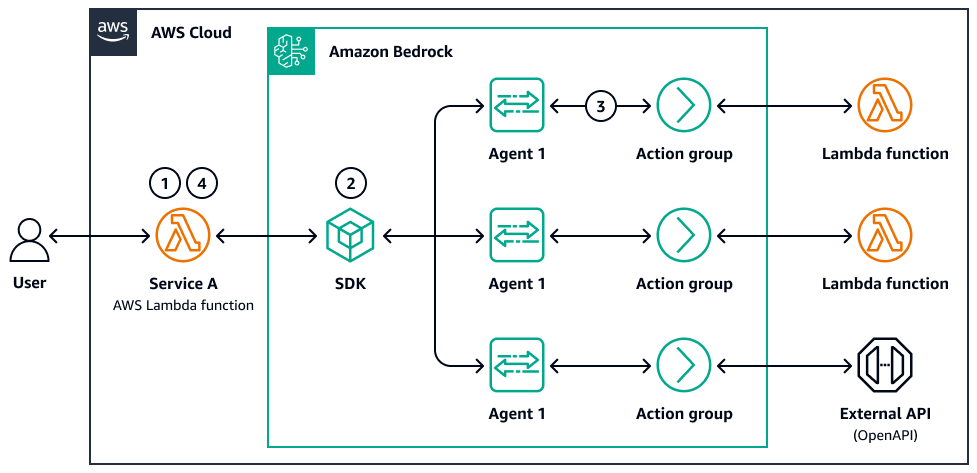
-
Un utilisateur soumet une requête ou un ensemble de documents en plusieurs parties.
-
Un contrôleur AWS Lambda ou une fonction d'étape distribue les sous-tâches. Chaque tâche appelle un appel ou un sous-agent Amazon Bedrock LLM avec sa propre invite.
-
Lorsque les appels et les sous-tâches sont terminés, les résultats sont stockés (par exemple, dans Amazon S3 ou dans une mémoire), et une étape d'agrégation fusionne, compare ou filtre les sorties.
-
Le système renvoie la réponse finale à l'utilisateur ou à l'agent en aval.
Ce système comporte une boucle de raisonnement distribuée avec traçabilité, tolérance aux pannes et logique optionnelle de pondération ou de sélection des résultats.
Plats à emporter
La parallélisation agentique utilise des modèles de dispersion pour distribuer les tâches LLM, permettant ainsi un traitement parallèle et une synthèse intelligente des résultats.
