Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Agents de raisonnement de base
Un agent de raisonnement de base est la forme la plus simple d'IA agentique qui effectue une inférence logique ou prend des décisions en réponse à une requête. Il accepte les entrées d'un utilisateur ou d'un système, traite les requêtes et génère des réponses à l'aide d'instructions structurées.
Ce modèle est utile pour les tâches qui nécessitent un raisonnement, une classification ou une synthèse en une seule étape en fonction d'un contexte donné. Il n'utilise pas de mémoire, d'outils ou de gestion d'état, ce qui le rend apatride, léger et hautement composable dans les grands flux de travail.
Architecture
Le flux d'un agent de raisonnement de base est illustré dans le schéma suivant :
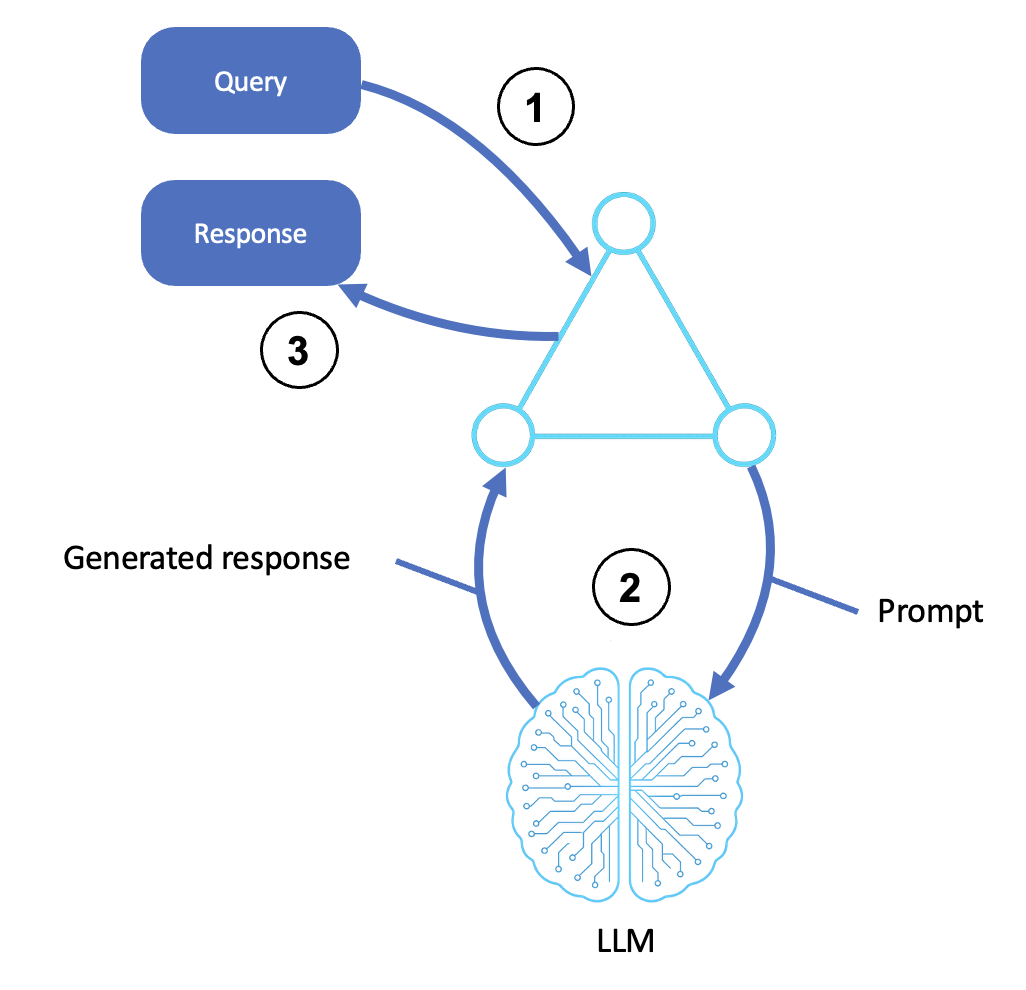
Description
-
Reçoit une entrée
-
Un utilisateur, un système ou un agent en amont soumet une requête ou une instruction.
-
L'entrée est transmise au shell de l'agent ou à la couche d'orchestration.
-
Cette étape inclut tout prétraitement, la création de modèles d'invite et l'identification des objectifs.
-
-
Invoque le LLM
-
L'agent transforme la requête en une invite structurée et l'envoie à un LLM (par exemple, via Amazon Bedrock).
-
Le LLM génère une réponse basée sur l'invite en utilisant des connaissances et un contexte préformés.
-
Le résultat généré peut inclure des étapes de raisonnement (chaîne de pensée), des réponses finales ou des options classées.
-
-
Renvoie une réponse
-
La sortie générée est transmise à l'interface de l'agent.
-
Cela peut inclure le formatage, le post-traitement ou une réponse d'API.
-
Fonctionnalités
-
Supporte le langage naturel ou la saisie structurée
-
Utilise une ingénierie rapide pour guider le comportement
-
Apatride et évolutif
-
Peut être intégré dans l'interface utilisateur, la CLI, les API et les pipelines
Limitations
-
Absence de mémoire ou de conscience historique
-
Aucune interaction avec des outils ou des sources de données externes
-
Limité à ce que le LLM sait au moment de l'inférence
Cas d’utilisation courants
-
Questions et réponses conversationnelles
-
Explications et résumés des politiques
-
Conseils pour la prise de décisions
-
Des flux de chatbot légers et automatisés
-
Classification, étiquetage et notation
Directives d’implémentation
Vous pouvez utiliser les outils et services suivants pour créer un agent de raisonnement de base :
-
Amazon Bedrock pour l'invocation du LLM (Anthropic, AI21, Meta)
-
Amazon API Gateway ou AWS Lambda pour l'exposer en tant que microservice apatride
-
Modèles d'invite stockés dans le Parameter Store ou sous forme de code AWS Secrets Manager
Résumé
L'agent de raisonnement de base est fondamental en raison de sa structure simple. Il possède des capacités de base qui transforment les objectifs en voies de raisonnement menant à des résultats intelligents. Ce modèle est souvent le point de départ de modèles avancés, tels que les agents basés sur des outils et les agents utilisant la génération augmentée par récupération (RAG). C'est également un composant fiable et modulaire des grands flux de travail.
Agent RAG
Retrieval-augmented La génération (RAG) est une technique qui combine la récupération d'informations avec la génération de texte pour créer des réponses précises et contextuelles. RAG permet aux agents de récupérer des informations externes pertinentes avant d'engager le LLM. Il étend la mémoire effective et la précision du raisonnement d'un agent en fondant ses décisions sur des informations actualisées, factuelles ou spécifiques à un domaine. Contrairement aux LLM apatrides qui s'appuient uniquement sur des poids prédéterminés, RAG dispose d'une couche de recherche de connaissances externe qui améliore dynamiquement les instructions en fonction du contexte.
Architecture
La logique du modèle RAG est illustrée dans le schéma suivant :
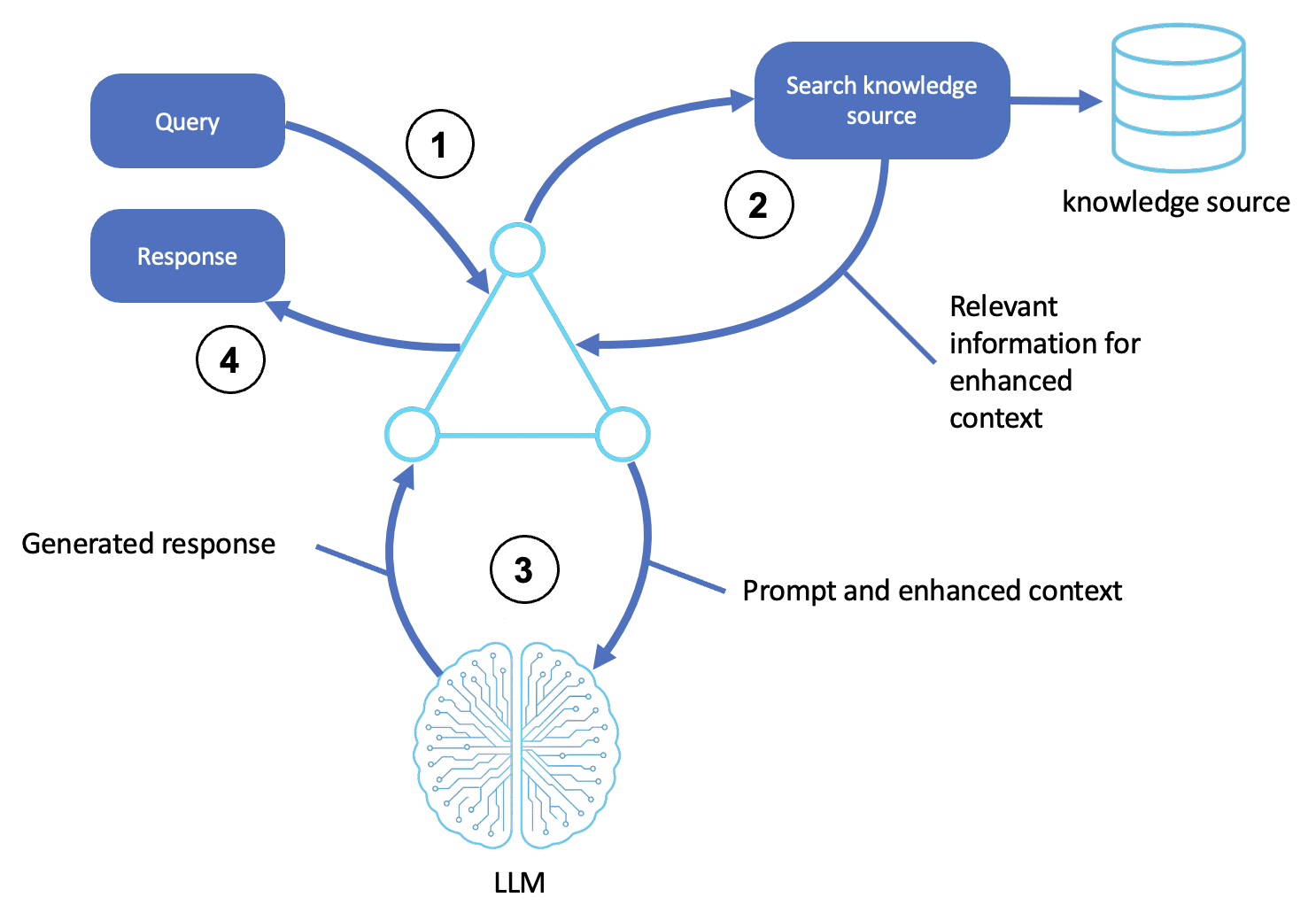
Description
-
Reçoit une requête
-
Un utilisateur ou un système en amont soumet une requête ou un objectif à l'agent.
-
Le shell de l'agent accepte la demande et la met en forme comme une invite à raisonner.
-
-
Recherche dans une source externe
-
L'agent identifie les concepts et l'intention à partir de la requête.
-
Il interroge une source de connaissances, telle qu'un magasin de vecteurs, une base de données ou un index de documents, à l'aide d'une recherche sémantique ou d'une correspondance de mots clés.
-
Les passages, documents ou entités les plus pertinents sont récupérés pour être utilisés à l'étape suivante.
-
-
Génère une réponse contextuelle
-
L'agent complète l'invite avec les informations récupérées, formant ainsi une entrée contextuelle améliorée pour le LLM.
-
Le LLM traite toutes les entrées en utilisant un raisonnement génératif (par exemple, chaîne de pensée ou réflexion) pour produire une réponse précise.
-
-
Renvoie le résultat final
-
L'agent prépare le résultat en l'encapsulant dans n'importe quel en-tête de communication ou dans le formatage requis, puis le renvoie à l'utilisateur ou au système d'appel.
-
(Facultatif) Les documents récupérés et la sortie LLM peuvent être enregistrés, notés et stockés en mémoire pour de futures requêtes.
-
Fonctionnalités
-
Fact-grounded production même dans des domaines à long terme ou spécifiques à l'entreprise
-
Extension de mémoire sans réglage précis du modèle
-
Contexte dynamique basé sur chaque requête et l'état de l'utilisateur
-
Entièrement compatible avec les bases de données vectorielles, les index sémantiques et le filtrage des métadonnées
Cas d’utilisation courants
-
Assistants du savoir d'entreprise
-
Bots de conformité réglementaire
-
Copilotes du support client
-
Search-enhanced chatbots
-
Agents de documentation pour développeurs
Directives d’implémentation
Utilisez les outils et services suivants pour créer un agent utilisant RAG :
-
Amazon Bedrock pour l'invocation d'un LLM
-
Amazon Kendra ou Amazon Aurora pour la documentation ou une recherche de données structurées OpenSearch
-
Amazon Simple Storage Service (Amazon S3) pour le stockage de documents
-
AWS Lambda pour orchestrer la recherche, l'invite et l'inférence LLM
-
Knowledge-based intégrations avec des agents (en utilisant des plugins de mémoire, des récupérateurs sémantiques ou Amazon Bedrock)
Résumé
L'agent RAG associe le raisonnement du modèle statique à l'intelligence dynamique du monde réel. Il permet aux agents de rechercher ce qu'ils ne savent pas, de synthétiser les réponses à partir des connaissances récupérées et de produire des réponses vérifiables et fiables.
Les modèles RAG constituent la base de la création d'agents intelligents capables d'étendre l'accès aux connaissances sans avoir à se recycler. Il est souvent le précurseur de modèles d'orchestration plus complexes impliquant l'utilisation d'outils, la planification et la mémoire à long terme.
