Nous ne mettons plus à jour le service Amazon Machine Learning et n'acceptons plus de nouveaux utilisateurs pour celui-ci. Cette documentation est disponible pour les utilisateurs existants, mais nous ne la mettons plus à jour. Pour plus d'informations, consultez Qu'est-ce qu'Amazon Machine Learning ?
Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Création d'une source de données avec Amazon Redshift Data (console)
La console Amazon ML propose deux méthodes pour créer une source de données à l'aide des données Amazon Redshift. Vous pouvez créer une source de données en suivant l'assistant de création de source de données ou, si vous avez déjà créé une source de données à partir des données Amazon Redshift, vous pouvez copier la source de données d'origine et modifier ses paramètres. La copie d'une source de données vous permet de facilement créer plusieurs sources de données similaires.
Pour plus d'informations sur la création d'une source de données à l'aide de l'API, consultez CreateDataSourceFromRedshift.
Pour plus d'informations sur les paramètres utilisés dans les procédures suivantes, consultez Paramètres obligatoires pour l'assistant de création de sources de données.
Création d'une source de données (console)
Pour décharger des données d'Amazon Redshift vers une source de données Amazon ML, utilisez l'assistant de création de source de données.
Pour créer une source de données à partir de données dans Amazon Redshift
Ouvrez la console Amazon Machine Learning à l'adresse https://console.aws.amazon.com/machinelearning/
. -
Sur le tableau de bord Amazon ML, sous Entités, choisissez Create new... , puis choisissez Datasource.
-
Sur la page des données d'entrée, sélectionnez Amazon Redshift.
-
Dans l'assistant de création de sources de données, pour Cluster identifier, tapez le nom de votre cluster.
-
Dans Nom de la base de données, saisissez le nom de la base de données Amazon Redshift.
-
Pour Database user name, tapez votre nom d'utilisateur de base de données.
-
Pour Database password, tapez votre mot de passe de base de données.
-
Pour Rôle IAM, choisissez votre rôle IAM. Si vous n'en avez pas déjà un, choisissez Créer un nouveau rôle. Amazon ML crée un rôle IAM Amazon Redshift pour vous.
-
Pour tester vos paramètres Amazon Redshift, choisissez Test Access (à côté du rôle IAM). Si Amazon ML ne parvient pas à se connecter à Amazon Redshift avec les paramètres fournis, vous ne pouvez pas continuer à créer une source de données. Pour bénéficier d'une aide à la résolution des problèmes, consultez Dépannage des erreurs.
-
Pour SQL query, tapez votre requête SQL.
-
Pour l'emplacement du schéma, indiquez si vous souhaitez qu'Amazon ML crée un schéma pour vous. Si vous avez créé un schéma vous-même, saisissez le chemin Amazon S3 vers votre fichier de schéma.
-
Pour l'emplacement intermédiaire d'Amazon S3, saisissez le chemin Amazon S3 vers le compartiment dans lequel vous souhaitez qu'Amazon ML place les données qu'il décharge depuis Amazon Redshift.
-
(Facultatif) Pour Datasource name, tapez un nom pour votre source de données.
-
Choisissez Vérifier. Amazon ML vérifie qu'il peut se connecter à votre base de données Amazon Redshift.
-
Dans la page Schema, passez en revue les types de données pour tous les attributs et corrigez-les, si nécessaire.
-
Sélectionnez Continuer.
-
Si vous voulez utiliser cette source de données pour créer ou évaluer un modèle d'apprentissage-machine, pour Do you plan to use this dataset to create or evaluate an ML model?, choisissez Yes. Si vous choisissez Yes, choisissez votre ligne cible. Pour en savoir plus sur les cibles, consultez Utilisation du targetAttributeName terrain.
Si vous voulez utiliser cette source de données avec un modèle que vous avez déjà créé, afin de créer des prédictions, choisissez No.
-
Sélectionnez Continuer.
-
Pour Does your data contain an identifier ?, si vos données ne contiennent pas d'identifiant de ligne, choisissez No.
Si vos données contiennent un identifiant de ligne, choisissez Yes. Pour obtenir des informations sur les identifiants de ligne, consultez Utilisation du champ rowID.
-
Choisissez Examiner.
-
Dans la page Révision, passez en revue vos paramètres, puis choisissez Terminer.
Une fois que vous avez créé une source de données, vous pouvez l'utiliser pour create an ML model. Si vous avez déjà créé un modèle, vous pouvez utiliser la source de données pour evaluate an ML model ou generate predictions.
Copie d'une source de données (console)
Lorsque vous souhaitez créer une source de données similaire à une source de données existante, vous pouvez utiliser la console Amazon ML pour copier la source de données d'origine et modifier ses paramètres. Par exemple, vous pouvez choisir de commencer par une source de données existante, puis de modifier le schéma de données pour qu'il corresponde mieux à vos données, de modifier la requête SQL utilisée pour décharger les données d'Amazon Redshift ou de spécifier un Gestion des identités et des accès AWS autre utilisateur (IAM) pour accéder au cluster Amazon Redshift.
Pour copier et modifier une source de données Amazon Redshift
Ouvrez la console Amazon Machine Learning à l'adresse https://console.aws.amazon.com/machinelearning/
. -
Sur le tableau de bord Amazon ML, sous Entités, choisissez Create new... , puis choisissez Datasource.
-
Sur la page Données d'entrée, pour Où sont vos données ? , choisissez Amazon Redshift. Si vous avez déjà créé une source de données à partir des données Amazon Redshift, vous avez la possibilité de copier les paramètres d'une autre source de données.
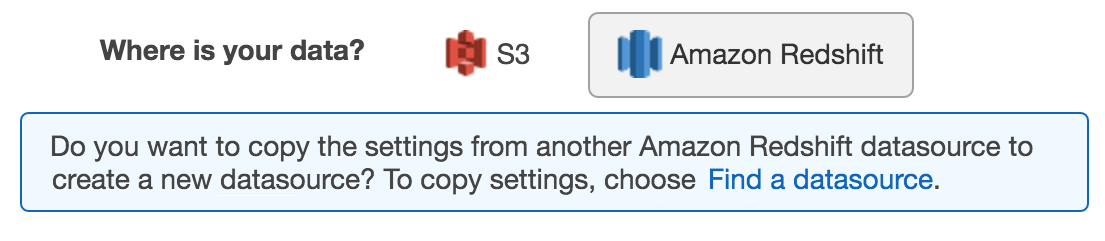
Si vous n'avez pas encore créé de source de données à partir des données Amazon Redshift, cette option n'apparaît pas.
-
Choisissez Find a datasource.
-
Sélectionnez la source de données que vous souhaitez copier, puis choisissez Copier les paramètres. Amazon ML remplit automatiquement la plupart des paramètres de la source de données avec les paramètres de la source de données d'origine. Il ne copie pas le mot de passe de la base de données, l'emplacement du schéma ni le nom de la source de données à partir de la source de données d'origine.
-
Modifiez tous les paramètres renseignés automatiquement que vous souhaitez. Par exemple, si vous souhaitez modifier les données déchargées par Amazon ML depuis Amazon Redshift, modifiez la requête SQL.
-
Pour Database password, tapez votre mot de passe de base de données. Amazon ML ne stocke ni ne réutilise votre mot de passe. Vous devez donc toujours le fournir.
-
(Facultatif) Pour l'emplacement du schéma, Amazon ML présélectionne Je veux qu'Amazon ML génère un schéma recommandé pour vous. Si vous avez déjà créé un schéma, choisissez Je souhaite utiliser le schéma que j'ai créé et stocké dans Amazon S3 et saisissez le chemin d'accès à votre fichier de schéma dans Amazon S3.
-
(Facultatif) Pour Datasource name, tapez un nom pour votre source de données. Dans le cas contraire, Amazon ML génère un nouveau nom de source de données pour vous.
-
Choisissez Vérifier. Amazon ML vérifie qu'il peut se connecter à votre base de données Amazon Redshift.
-
(Facultatif) Si Amazon ML a déduit le schéma pour vous, sur la page Schéma, passez en revue les types de données pour tous les attributs et corrigez-les si nécessaire.
-
Sélectionnez Continuer.
-
Si vous voulez utiliser cette source de données pour créer ou évaluer un modèle d'apprentissage-machine, pour Do you plan to use this dataset to create or evaluate an ML model?, choisissez Yes. Si vous choisissez Yes, choisissez votre ligne cible. Pour en savoir plus sur les cibles, consultez Utilisation du targetAttributeName terrain.
Si vous voulez utiliser cette source de données avec un modèle que vous avez déjà créé, afin de créer des prédictions, choisissez No.
-
Sélectionnez Continuer.
-
Pour Does your data contain an identifier ?, si vos données ne contiennent pas d'identifiant de ligne, choisissez No.
Si vos données contiennent un identifiant de ligne, choisissez Oui et sélectionnez la ligne que vous souhaitez utiliser comme identifiant. Pour obtenir des informations sur les identifiants de ligne, consultez Utilisation du champ rowID.
-
Choisissez Examiner.
-
Passez en revue vos paramètres, puis choisissez Terminer.
Une fois que vous avez créé une source de données, vous pouvez l'utiliser pour create an ML model. Si vous avez déjà créé un modèle, vous pouvez utiliser la source de données pour evaluate an ML model ou generate predictions.
