Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Qu’est-ce qu’Amazon Data Firehose ?
Amazon Data Firehose est un service entièrement géré permettant de diffuser des données
Pour plus d'informations sur les solutions de AWS mégadonnées, voir Big Data sur AWS
Découvrez les concepts clés
Lorsque vous débutez avec Amazon Data Firehose, vous pouvez tirer parti de la compréhension des concepts suivants.
- Flux Firehose
-
L'entité sous-jacente d'Amazon Data Firehose. Vous utilisez Amazon Data Firehose en créant un flux Firehose, puis en lui envoyant des données. Pour plus d’informations, consultez Tutoriel : Création d'un stream Firehose depuis la console et Envoyer des données vers un flux Firehose.
- Enregistrer
-
Les données présentant un intérêt que votre producteur de données envoie à un flux Firehose. La taille d'un enregistrement peut atteindre 1 000 Ko.
- Producteur de données
-
Les producteurs envoient leurs disques aux streams Firehose. Par exemple, un serveur Web qui envoie des données de journal à un flux Firehose est un producteur de données. Vous pouvez également configurer votre flux Firehose pour lire automatiquement les données d'un flux de données Kinesis existant et les charger dans des destinations. Pour de plus amples informations, veuillez consulter Envoyer des données vers un flux Firehose.
- Taille de la mémoire tampon et intervalle entre la mémoire tampon
-
Amazon Data Firehose met en mémoire tampon les données de streaming entrantes jusqu'à une certaine taille ou pendant une certaine période avant de les diffuser vers les destinations. Buffer Sizeest en MBs et Buffer Interval est en secondes.
Comprendre le flux de données dans Amazon Data Firehose
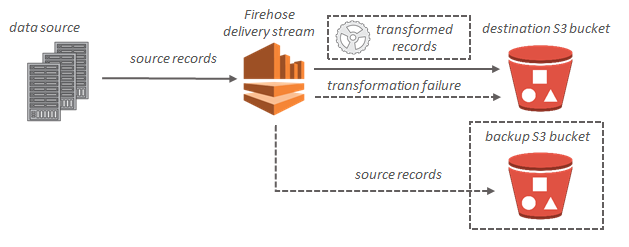
Pour les destinations Amazon S3, les données de streaming sont délivrées à votre compartiment S3. Si la transformation de données est activée, vous pouvez éventuellement sauvegarder les données source dans un autre compartiment Amazon S3.
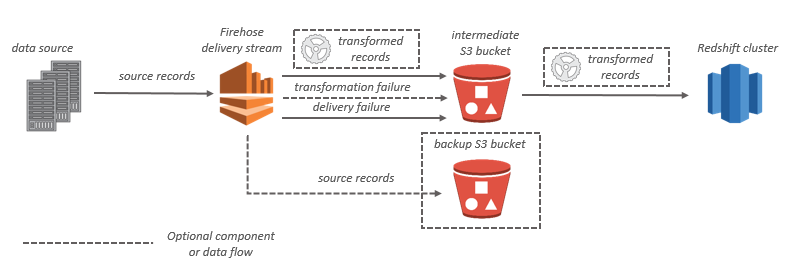
Pour les destinations Amazon Redshift, les données de streaming sont d'abord délivrées à votre compartiment S3. Amazon Data Firehose émet ensuite une commande Amazon COPY Redshift pour charger les données de votre compartiment S3 vers votre cluster Amazon Redshift. Si la transformation de données est activée, vous pouvez éventuellement sauvegarder les données source dans un autre compartiment Amazon S3.
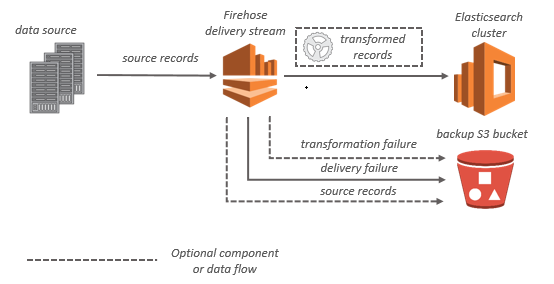
Pour les destinations de OpenSearch service, les données de streaming sont transmises à votre cluster de OpenSearch services et peuvent éventuellement être sauvegardées simultanément dans votre compartiment S3.
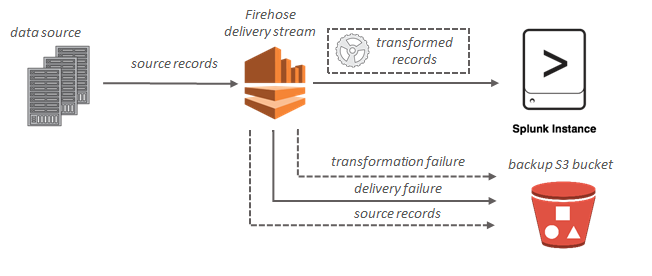
Pour les destinations Splunk, les données de streaming sont remises à Splunk et peuvent éventuellement être sauvegardées dans votre compartiment S3 simultanément.