Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Architecture d’Aurora PostgreSQL Limitless Database
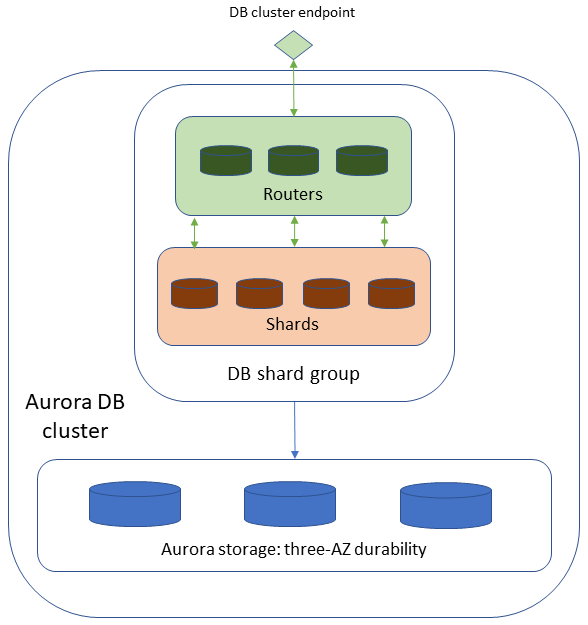
Limitless Database assure sa montée en charge grâce à une architecture à deux couches constituée de multiples nœuds de base de données. Les nœuds sont soit des routeurs, soit des partitions.
-
Les partitions sont des instances de base de données Aurora PostgreSQL qui stockent chacune un sous-ensemble des données de votre base de données, permettant ainsi un traitement parallèle pour obtenir un débit d’écriture plus élevé.
-
Les routeurs gèrent la nature distribuée de la base de données et présentent une image de base de données unique aux clients de base de données. Les routeurs gèrent les métadonnées relatives à l’emplacement de stockage des données, analysent les commandes SQL entrantes et envoient ces commandes aux partitions. Ils agrègent ensuite les données provenant des différentes partitions pour renvoyer un résultat unique au client, tout en gérant les transactions distribuées afin d’assurer la cohérence de l’ensemble de la base de données distribuée.
Aurora PostgreSQL Limitless Database se distingue de la Clusters DB Aurora standard en utilisant un groupe de partitions de base de données plutôt qu’une instance de base de données d’écriture et plusieurs instances de base de données de lecture. Tous les nœuds qui constituent votre architecture Limitless Database sont contenus dans le groupe de partitions de base de données. Les partitions et routeurs individuels du groupe de partitions de base de données ne sont pas visibles dans votre. Compte AWS Vous utilisez le point de terminaison du cluster de bases de données pour accéder à Limitless Database.
La figure suivante illustre l’architecture générale d’Aurora PostgreSQL Limitless Database.
Pour plus d'informations sur l'architecture de la base de données Aurora PostgreSQL Limitless et sur la façon dont vous pouvez l'utiliser, regardez cette vidéo sur le canal Events sur AWS : YouTube
Pour plus d’informations sur l’architecture d’un cluster de bases de données Aurora Standard, consultez Clusters de bases de données Amazon Aurora.
Termes clés relatifs à Aurora PostgreSQL Limitless Database
- Groupe de partitions de base de données
-
Un conteneur pour les nœuds de Limitless Database (partitions et routeurs).
- Routeur
-
Nœud qui accepte les connexions SQL des clients, envoie des commandes SQL aux partitions, assure la cohérence à l’échelle du système et renvoie les résultats aux clients.
- Partition
-
Nœud qui stocke un sous-ensemble de tables partitionnées, des copies complètes des tables de référence et des tables standard. Accepte les requêtes des routeurs, sans autoriser de connexions directes depuis les clients.
- Table partitionnée
-
Une table dont les données sont réparties entre plusieurs partitions.
- Clé de partition
-
Colonne ou ensemble de colonnes d’une table partitionnée utilisée pour déterminer le partitionnement entre les partitions.
- Tables colocalisées
-
Deux tables partitionnées qui partagent la même clé de partition et sont explicitement déclarées comme colocalisées. Toutes les données correspondant à la même valeur de clé de partition sont envoyées à la même partition.
- Table de référence
-
Une table dont les données sont copiées intégralement sur chaque partition.
- Table standard
-
Type de table par défaut dans une base de données Limitless. Vous pouvez convertir des tables standard en tables partitionnées et en tables de référence.
Toutes les tables standard sont stockées sur la même partition sélectionnée par le système, ce qui permet d’effectuer des jointures entre tables standard au sein d’une seule partition. Cependant, les tables standard sont limitées par la capacité maximale de la partition (128 Tio). Cette partition stocke également les données des tables partitionnées et de référence, de sorte que la limite effective des tables standard est inférieure à 128 Tio.
Types de tables pour Aurora PostgreSQL Limitless Database
Aurora PostgreSQL Limitless Database prend en charge trois types de tables partitionnées référence et standard.
Les données des tables partitionnées sont réparties sur toutes les partitions du groupe de partitions de base de données. Limitless Database effectue cette opération automatiquement à l’aide d’une clé de partition, c’est-à-dire une colonne ou un ensemble de colonnes que vous définissez lors du partitionnement de la table. Toutes les données correspondant à la même valeur de clé de partition sont envoyées à la même partition. Le partitionnement est basé sur le hachage, et non sur des plages de valeurs ou des listes.
Voici quelques exemples de cas d’utilisation adaptés aux tables partitionnées :
-
L’application fonctionne avec un sous-ensemble de données distinct.
-
La table est très volumineuse.
-
La table est susceptible de croître plus rapidement que les autres tables.
Les tables partitionnées peuvent être colocalisées, c’est-à-dire qu’elles partagent une clé de partition commune ; ainsi, les données présentant la même valeur de clé de partition dans les deux tables sont envoyées sur la même partition. Si vous colocalisez des tables et les joignez à l’aide de la clé de partition, la jointure peut s’effectuer sur une seule partition, puisque toutes les données nécessaires s’y trouvent.
Les tables de référence contiennent une copie complète de toutes leurs données sur chaque partition du groupe de partitions de base de données. Les tables de référence sont généralement utilisées pour les tables plus petites, dont le volume d’écriture est limité, mais qui nécessitent des jointures fréquentes et ne conviennent pas au partitionnement. Parmi les exemples de tables de référence figurent les tables de dates ainsi que les tables de données géographiques, telles que celles des États, des villes et des codes postaux.
Les tables standard constituent le type de table par défaut dans Aurora PostgreSQL Limitless Database. Ce ne sont pas des tables distribuées. Aurora PostgreSQL Limitless Database prend en charge les jointures entre les tables standard, ainsi qu’entre les tables standard, partitionnées et de référence.
Facturation relative à Aurora PostgreSQL Limitless Database
Pour en savoir plus sur la facturation d’Aurora PostgreSQL Limitless Database, consultez Facturation d'une instance de base de données pour Aurora.
Pour obtenir des informations sur la tarification Aurora, consultez la page de tarification Aurora
