Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Clusters de bases de données Amazon Aurora
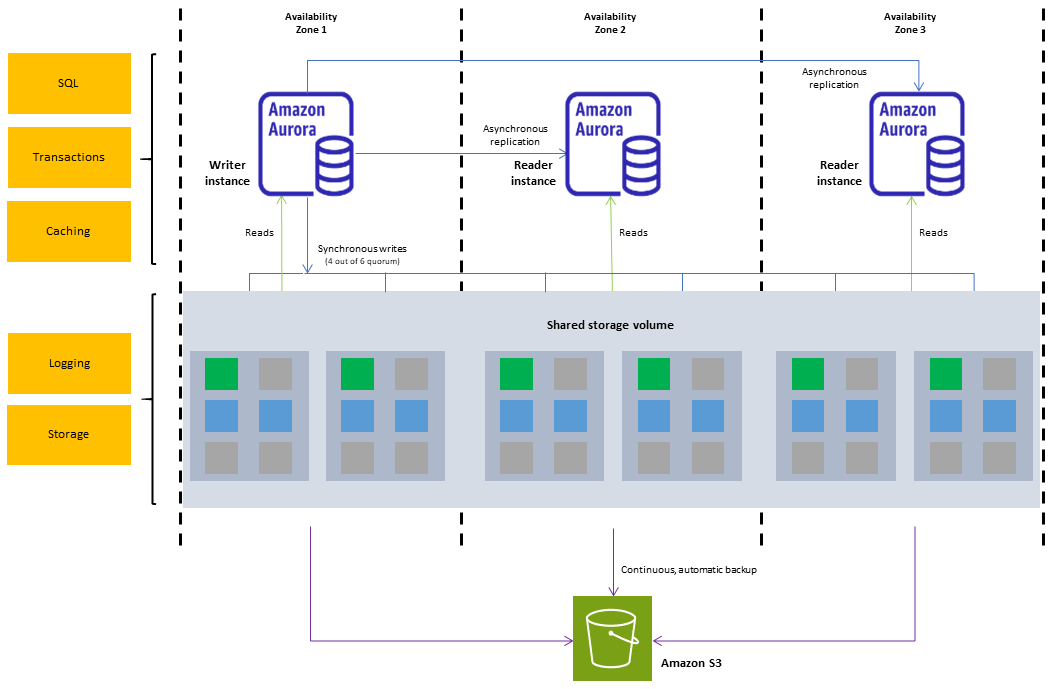
Un cluster de bases de données Amazon Aurora se compose d’une ou plusieurs instances de base de données et d’un volume de cluster qui gère les données de ces instances. Un volume de cluster Aurora est un volume de stockage de base de données virtuel qui couvre plusieurs zones de disponibilité, chacune d’entre elles ayant une copie des données du cluster de bases de données. Deux types d’instances de base de données composent un cluster de bases de données Aurora :
-
Instance de base de données principale (enregistreur) : prend en charge les opérations de lecture et d’écriture, et effectue toutes les modifications de données du volume de cluster. Chaque cluster de bases de données Aurora possède une seule instance de base de données principale.
-
Réplica Aurora (instance de base de données de lecteur) : se connecte au même volume de stockage que l’instance de base de données principale et prend uniquement en charge les opérations de lecture. Chaque cluster de bases de données Aurora peut avoir jusqu’à 15 réplicas Aurora en plus de l’instance de base de données principale. Maintenez une haute disponibilité en plaçant les réplicas Aurora dans des zones de disponibilité distinctes. Aurora bascule automatiquement vers un réplica Aurora si l’instance de base de données principale devient indisponible. Vous pouvez spécifier la priorité de basculement pour les réplicas Aurora. Les réplicas Aurora peuvent également décharger l’instance de base de données principale des charges de travail en lecture.
Le schéma suivant illustre les relations entre le volume de cluster, l’instance de base de données d’enregistreur et les instances de base de données de lecteur dans un cluster Aurora.
Note
Les informations précédentes s'appliquent à tous les clusters de base de données Aurora : provisionnés, requête parallèle, base de données globale AuroraAurora Serverless, Aurora et Aurora MySQL-Compatible. PostgreSQL-Compatible
Le cluster de bases de données Aurora illustre la séparation de la capacité de calcul et du stockage. Par exemple, une configuration Aurora avec seulement une instance de base de données unique est quand même un cluster, car le volume de stockage sous-jacent implique plusieurs nœuds de stockage répartis entre plusieurs zones de disponibilité.
Input/output (I/O) les opérations dans les clusters de base de données Aurora sont comptées de la même manière, qu'elles se trouvent sur une instance de base de données d'écriture ou de lecture. Pour de plus amples informations, veuillez consulter Configurations de stockage pour les clusters de bases de données Amazon Aurora.
