Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Ajouter un Région AWS vers une base de données mondiale Amazon Aurora
Vous pouvez utiliser la procédure suivante pour ajouter un cluster secondaire supplémentaire à une base de données globale existante. Vous pouvez également créer une base de données globale à partir d'un cluster de base de données Aurora autonome en utilisant cette procédure pour ajouter la première AWS région secondaire.
Une base de données globale Aurora a besoin d'au moins un cluster de base de données Aurora secondaire dans un cluster de base de données Aurora Région AWS différent du cluster de base de données Aurora principal. Vous pouvez attacher jusqu’à 10 clusters de bases de données secondaires à une base de données Aurora globale. Répétez la procédure suivante pour chaque nouveau cluster de bases de données secondaire. Pour chaque cluster de bases de données secondaire que vous ajoutez à votre base de données Aurora globale, retranchez un pour obtenir le nombre de réplicas Aurora autorisés pour le cluster de bases de données principal.
Par exemple, si votre base de données Aurora globale comporte 10 régions secondaires, votre cluster de bases de données principal ne peut avoir que cinq réplicas Aurora (au lieu de 15). Pour plus d’informations, consultez Configuration requise pour une base de données Amazon Aurora globale.
Le nombre de réplicas Aurora (instances de lecteur) dans le cluster de bases de données principal détermine le nombre de clusters de bases de données secondaires que vous pouvez ajouter. Le nombre total d’instances de lecteur dans le cluster de bases de données primaire plus le nombre de clusters secondaires ne peut pas dépasser le nombre de 15. Par exemple, si vous avez 14 instances de lecteur dans le cluster de bases de données primaire et un cluster secondaire, vous ne pouvez pas ajouter de cluster secondaire supplémentaire à la base de données globale.
Note
Pour Aurora MySQL version 3, lorsque vous créez un cluster secondaire, assurez-vous que la valeur de lower_case_table_names correspond à la valeur du cluster principal. Ce paramètre est un paramètre de base de données qui affecte la façon dont le serveur gère la sensibilité à la casse de l’identifiant. Pour plus d’informations sur les paramètres de la base de données, consultez Groupes de paramètres pour Amazon Aurora.
Lorsque vous créez un cluster secondaire, nous vous recommandons d’utiliser la même version du moteur de base de données pour le principal et le secondaire. Si nécessaire, mettez à niveau la version principale pour qu’elle soit identique à la version secondaire. Pour plus d’informations, consultez Compatibilité des niveaux de correctif pour les bascules ou basculements gérés entre régions.
Pour ajouter un Région AWS vers une base de données mondiale Aurora
Connectez-vous à la console Amazon RDS AWS Management Console et ouvrez-la à https://console.aws.amazon.com/rds/
l'adresse. -
Dans le volet de navigation du AWS Management Console, choisissez Databases.
-
Sélectionnez la base de données Aurora globale qui a besoin d’un cluster de bases de données Aurora secondaire. Assurez-vous que le cluster de bases de données Aurora principal est
Available. -
Pour Actions, choisissez Ajouter une AWS région.
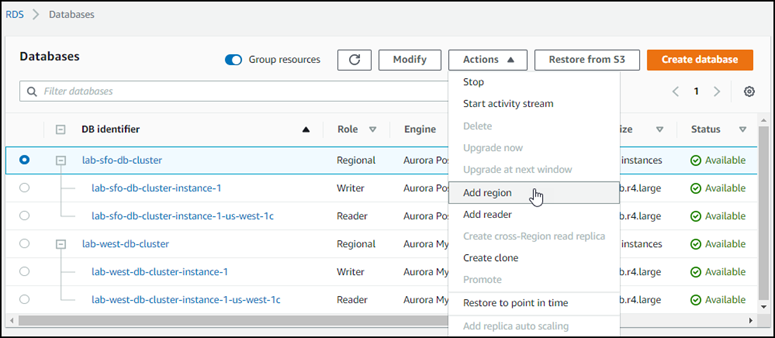
-
Sur la page Ajouter une région, choisissez la région secondaire Région AWS.
Vous ne pouvez pas en choisir un Région AWS qui possède déjà un cluster de base de données Aurora secondaire pour la même base de données globale Aurora. De plus, il ne peut pas s’agir de la même région que le cluster de bases de données Aurora principal.
Note
Les bases de données globales Babelfish pour Aurora PostgreSQL ne fonctionnent dans les régions secondaires que si les paramètres qui contrôlent les préférences de Babelfish sont activés dans ces régions. Pour de plus amples informations, consultez Paramètres du groupe de paramètres de cluster de bases de données pour Babelfish.
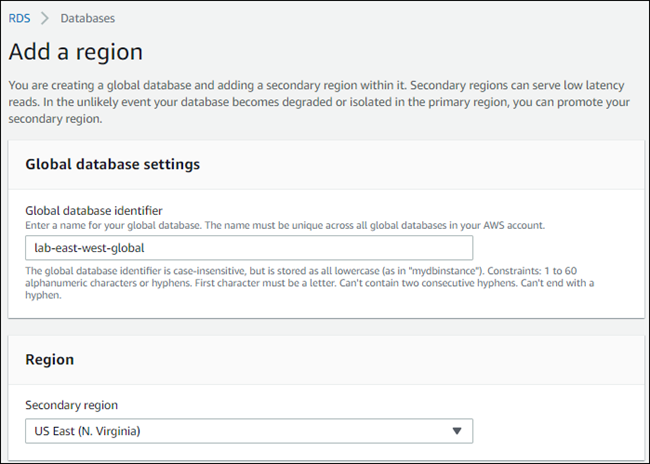
-
Remplissez les champs restants pour le cluster Aurora secondaire dans la nouvelle région AWS . Il s’agit des mêmes options de configuration que pour n’importe quelle instance de cluster de bases de données Aurora, à l’exception de l’option suivante pour les bases de données Aurora globales basées sur Aurora MySQL :
Activer le transfert d’écriture du réplica en lecture : ce paramètre facultatif permet aux clusters de bases de données secondaires de votre base de données Aurora globale de transférer les opérations d’écriture vers le cluster principal. Pour de plus amples informations, veuillez consulter Utilisation du transfert d'écriture dans une base de données globale Amazon Aurora.

Choisissez Ajouter une AWS région.
Une fois que vous avez terminé d'ajouter la région à votre base de données globale Aurora, vous pouvez la voir dans la liste des bases de données, AWS Management Console comme indiqué sur la capture d'écran.

Pour ajouter un secondaire Région AWS vers une base de données mondiale Aurora
Pour ajouter un cluster secondaire à votre base de données globale à l’aide de la CLI, vous devez déjà disposer de l’objet conteneur du cluster global. Si vous n’avez pas encore exécuté la commande create-global-cluster, consultez la procédure spécifique à la CLI dans Création d’une base de données Amazon Aurora globale.
-
Utilisez la commande
create-db-clusterde l’interface de ligne de commande avec le nom (--global-cluster-identifier) de votre base de données Aurora globale. Pour les autres paramètres, procédez comme suit : Pour
--region, choisissez une région différente Région AWS de celle de votre région principale d'Aurora.-
Choisissez des valeurs spécifiques pour les paramètres
--engineet--engine-version. Ces valeurs sont les mêmes que celles du cluster de bases de données Aurora principal de votre base de données Aurora globale. Pour un cluster chiffré, spécifiez votre cluster principal Région AWS comme étant le cluster
--source-regionde chiffrement.
L’exemple suivant crée un nouveau cluster de bases de données Aurora et l’attache à une base de données Aurora globale en tant que cluster Aurora secondaire en lecture seule. Dans la dernière étape, une instance de base de données Aurora est ajoutée au nouveau cluster Aurora.
Pour Linux, macOS ou Unix :
aws rds --regionsecondary_region\ create-db-cluster \ --db-cluster-identifiersecondary_cluster_id\ --global-cluster-identifierglobal_database_id\ --engineaurora-mysql | aurora-postgresql\ --engine-versionversionaws rds --regionsecondary_region\ create-db-instance \ --db-instance-classinstance_class\ --db-cluster-identifiersecondary_cluster_id\ --db-instance-identifierdb_instance_id\ --engineaurora-mysql | aurora-postgresql
Pour Windows :
aws rds --regionsecondary_region^ create-db-cluster ^ --db-cluster-identifiersecondary_cluster_id^ --global-cluster-identifierglobal_database_id_id^ --engineaurora-mysql | aurora-postgresql^ --engine-versionversionaws rds --regionsecondary_region^ create-db-instance ^ --db-instance-classinstance_class^ --db-cluster-identifiersecondary_cluster_id^ --db-instance-identifierdb_instance_id^ --engineaurora-mysql | aurora-postgresql
Pour ajouter un nouveau élément Région AWS à une base de données globale Aurora à l'aide de l'API RDS, exécutez l'opération CreateDBCluster. Spécifiez l’identifiant de la base de données globale existante à l’aide du paramètre GlobalClusterIdentifier.
