Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Exemple : utilisation d’Application Signals pour résoudre un problème d’état de fonctionnement
Le scénario suivant fournit un exemple de la manière dont Application Signals peuvent être utilisés pour surveiller vos services et identifier les problèmes de qualité de service. Effectuez une analyse approfondie pour identifier les causes profondes potentielles et prendre les mesures nécessaires pour résoudre le problème. Cet exemple se concentre sur une application de clinique pour animaux de compagnie composée de plusieurs microservices qui font appel, par Services AWS exemple, à DynamoDB.
Jane fait partie d'une DevOps équipe qui supervise la santé opérationnelle d'une application de clinique pour animaux de compagnie. L’équipe de Jane s’engage à faire en sorte que l’application soit hautement disponible et réactive. Ils utilisent des objectifs de niveau de service (SLO) pour mesurer les performances des applications par rapport à ces engagements métier. Elle reçoit une alerte concernant plusieurs indicateurs de niveau de service (SLI) non sains. Elle ouvre la CloudWatch console et accède à la page Services, où elle constate que plusieurs services ne fonctionnent pas correctement.

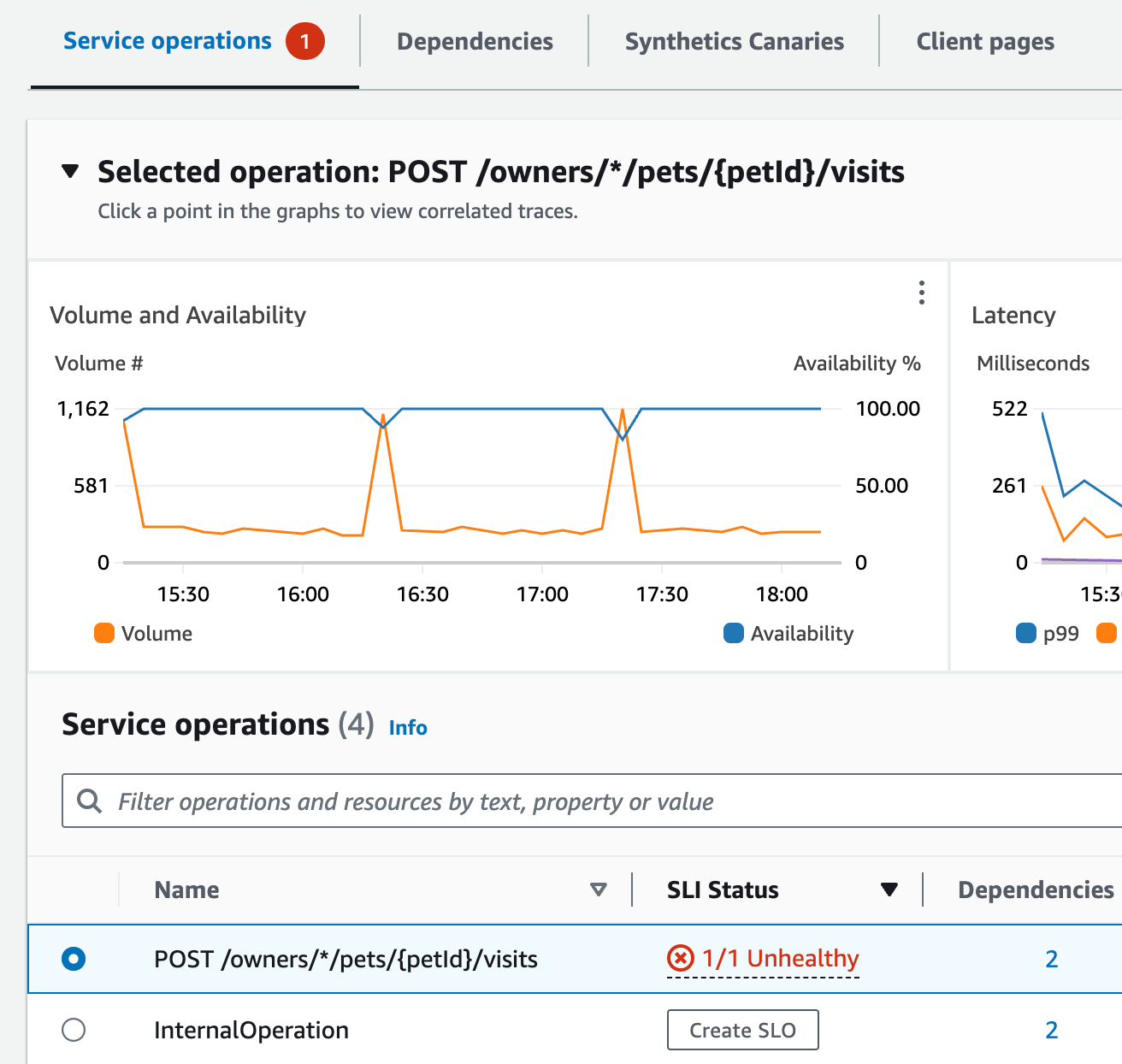
En haut de la page, Jane constate que visits-service est le service qui enregistre le plus grand nombre de défaillances. Elle sélectionne le lien dans le graphique, qui ouvre la page Détails du service correspondant. Elle constate qu’il y a une opération non saine dans le tableau des opérations du service. Elle sélectionne cette opération et constate dans le graphique du volume et de la disponibilité qu’il existe des pics de volume d’appels périodiques qui semblent être liés à des baisses de disponibilité.
Afin d’examiner de plus près les baisses de disponibilité des services, Jane sélectionne l’un des points de données de disponibilité dans le graphique. Un tiroir s'ouvre et affiche les X-Ray traces corrélées au point de données sélectionné. Elle constate qu’il existe de multiples suivis contenant des défaillances.
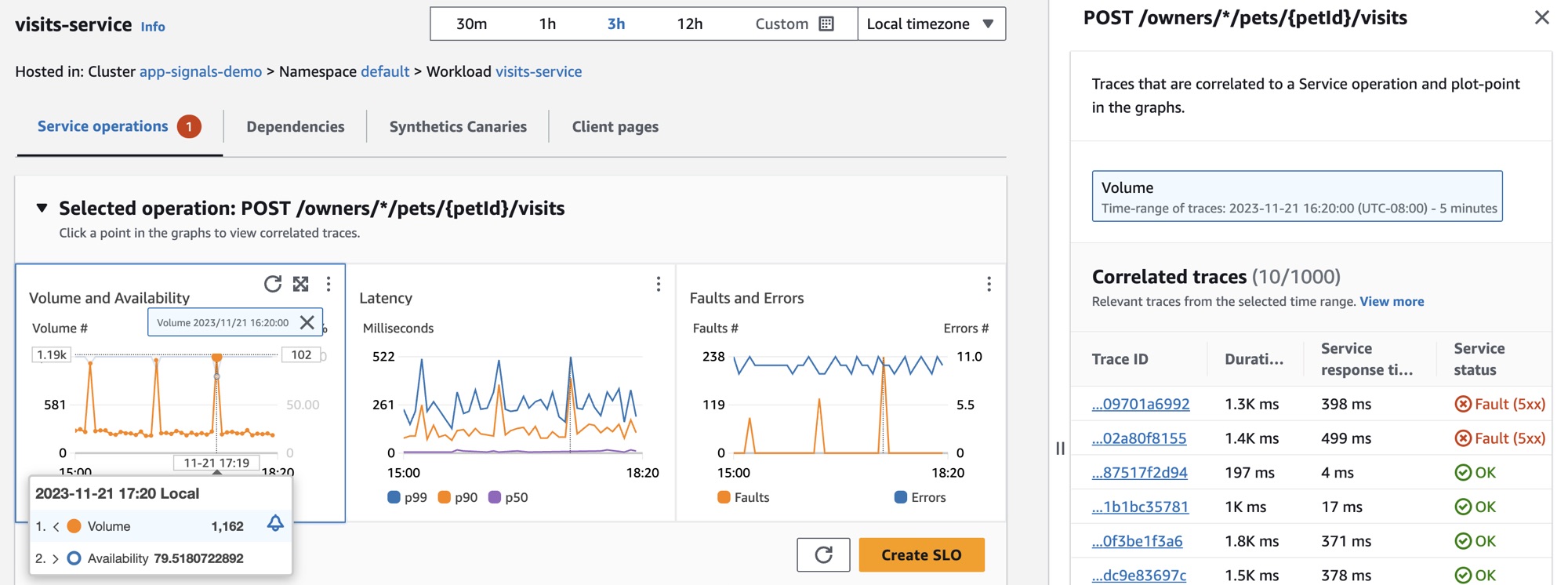
Jane sélectionne l'un des tracés corrélés présentant un état d'erreur, ce qui ouvre la page de détail du X-Ray tracé pour le tracé sélectionné. Jane fait défiler la page jusqu’à la section Chronologie des segments et suit le chemin des appels jusqu’à ce qu’elle constate que les appels à une table DynamoDB renvoient des erreurs. Elle sélectionne le segment DynamoDB et accède à l’onglet Exceptions du tiroir de droite.

Jane constate qu’une ressource DynamoDB est mal configurée, ce qui entraîne des erreurs lors des pics de demandes des clients. Le niveau de débit provisionné de la table DynamoDB est régulièrement dépassé, ce qui entraîne des problèmes de disponibilité des services et des SLI non sains. Sur la base de ces informations, son équipe est en mesure de configurer un niveau supérieur de débit provisionné et de garantir une haute disponibilité de l’application.
