Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Objectifs de niveau de service (SLO)
Vous pouvez utiliser la vigie applicative pour créer des objectifs de niveau de service pour les services de vos opérations ou dépendances critiques. En créant des SLO sur ces services, vous pourrez les suivre sur le tableau de bord SLO, ce qui vous donnera une vue d’ensemble de vos opérations les plus importantes.
En plus de créer un aperçu rapide que vos opérateurs peuvent utiliser pour connaître l’état actuel des opérations critiques, vous pouvez utiliser les SLO pour suivre les performances à long terme de vos services, afin de vous assurer qu’ils répondent à vos attentes. Si vous avez conclu des accords de niveau de service avec des clients, les SLO sont un excellent outil pour garantir leur respect.
L’évaluation de l’état de santé de vos services à l’aide des SLO commence par la définition d’objectifs clairs et mesurables basés sur des indicateurs de performance clés, à savoir des indicateurs de niveau de service (SLI). Un SLO suit les performances du SLI par rapport au seuil et à l’objectif que vous avez définis, et indique dans quelle mesure les performances de votre application se situent par rapport au seuil.
Application Signals vous aide à définir des SLO sur vos indicateurs de performance clés. Application Signals collecte les métriques Latency et Availability automatiquement pour chaque service et chaque opération qu’elle découvre, et ces métriques sont souvent idéales pour être utilisées en tant que SLI. Avec l’assistant de création de SLO, vous pouvez utiliser ces métriques pour vos SLO. Vous pouvez ensuite suivre l’état de tous vos SLO à l’aide des tableaux de bord d’Application Signals.
Vous pouvez définir des SLO pour des opérations ou des dépendances spécifiques que votre service appelle ou utilise. Vous pouvez utiliser n'importe quelle CloudWatch métrique ou expression métrique comme SLI, en plus d'utiliser les Availability métriques Latency et.
La création de SLO est très importante pour tirer le meilleur parti des signaux d' CloudWatchapplication. Une fois que vous avez créé des SLO, vous pouvez consulter leur état dans la console Application Signals pour voir rapidement lesquels de vos services et opérations critiques fonctionnent bien et lesquels ne le sont pas. Le fait d’avoir des SLO à suivre offre les principaux avantages suivants :
Il est plus facile pour vos opérateurs de services de voir l’état de fonctionnement actuel des services critiques par rapport au SLI. Ils peuvent ensuite rapidement trier et identifier les services et les opérations non saines.
Vous pouvez suivre les performances de vos services par rapport à des objectifs métier mesurables sur de longues périodes.
En choisissant les paramètres sur lesquels définir les SLO, vous priorisez ce qui est important pour vous. Les tableaux de bord d’Application Signals présentent automatiquement des informations sur ce que vous avez priorisé.
Lorsque vous créez un SLO, vous pouvez également choisir de créer des CloudWatch alarmes en même temps pour surveiller les SLO. Vous pouvez définir des alarmes qui surveillent les dépassements du seuil, ainsi que les niveaux d’alerte. Ces alarmes peuvent vous avertir automatiquement si les métriques SLO dépassent le seuil que vous avez défini ou s’approchent d’un seuil d’avertissement. Par exemple, un SLO proche de son seuil d’alerte peut vous indiquer que votre équipe devra peut-être ralentir le taux de désabonnement de l’application pour s’assurer que les objectifs de performance à long terme sont atteints.
Rubriques
Concepts SLO
Un SLO comprend les composants suivants :
Un indicateur de niveau de service (SLI), qui est une métrique de performance clé que vous spécifiez. Il représente le niveau de performance souhaité pour votre application. Application Signals collecte les métriques clés
LatencyetAvailabilityautomatiquement pour les services et opérations qu’elle découvre, et ces métriques sont souvent idéales pour être utilisées en tant que SLO.Vous choisissez le seuil à utiliser pour votre SLI. Par exemple, 200 ms pour la latence.
Un objectif ou un objectif d’atteinte, qui est le pourcentage de temps ou de requêtes que le SLI est censé atteindre le seuil sur chaque intervalle de temps. Les intervalles de temps peuvent être de quelques heures ou d’une année.
Les intervalles peuvent être des intervalles calendaires ou des intervalles glissants.
Les intervalles du calendrier sont alignés sur le calendrier, par exemple pour un SLO suivi par mois. CloudWatch ajuste automatiquement les chiffres de santé, de budget et de réussite en fonction du nombre de jours par mois. Les intervalles calendaires sont mieux adaptés aux objectifs métier mesurés sur une base alignée sur le calendrier.
Les intervalles glissants sont calculés sur une base continue. Les intervalles glissants sont mieux adaptés au suivi de l’expérience utilisateur récente de votre application.
La période est une unité de temps plus courte, et plusieurs périodes constituent un intervalle. Les performances de l’application sont comparées au SLI pendant chaque période comprise dans l’intervalle. Pour chaque période, il est déterminé que l’application a atteint ou non les performances nécessaires.
Par exemple, un objectif de 99 % avec un intervalle calendaire d’un jour et une période d’une minute signifie que l’application doit atteindre ou atteindre le seuil de réussite pendant 99 % des périodes d’une minute de la journée. Si c’est le cas, le SLO est atteint pour ce jour-là. Le jour suivant correspond à un nouvel intervalle d’évaluation, et l’application doit atteindre ou atteindre le seuil de réussite pendant 99 % des périodes d’une minute du deuxième jour pour atteindre le SLO du deuxième jour.
Un SLI peut être basé sur l’une des nouvelles métriques d’application standard collectées par Application Signals. Il peut également s'agir de n'importe quelle CloudWatch métrique ou expression métrique. Les métriques d’application standard que vous pouvez utiliser pour un SLI sont Latency et Availability. Availability représente le nombre de réponses réussies divisé par le nombre total de demandes. Il est calculé sous la forme (1 - taux de défaillance) * 100, les réponses aux défaillances étant des erreurs 5xx. Les réponses positives sont des réponses sans erreur 5XX. Les réponses 4XX sont considérées comme réussies.
Outre la création de SLO pour une seule opération ou pour toutes les opérations d'un service, vous pouvez créer des SLO composites qui surveillent un sous-ensemble d'opérations pour un service. Les SLO composites regroupent la Availability métrique sur plusieurs opérations, vous offrant ainsi une vue unifiée de la fiabilité d'un groupe d'opérations connexes. Vous pouvez sélectionner entre 2 et 20 opérations à inclure dans un SLO composite. Pour de plus amples informations, veuillez consulter Création d'un SLO composite sur plusieurs opérations.
Calculer le budget d’erreur et l’atteinte pour les SLO basés sur une période
Lorsque vous consultez les informations relatives à un SLO, vous pouvez voir son état de santé actuel et son budget d’erreurs. Le budget d’erreur est le laps de temps compris dans l’intervalle pendant lequel il est possible de dépasser le seuil tout en permettant d’atteindre le SLO. Le budget d’erreurs total est la quantité totale de temps de dépassement qui peut être tolérée sur l’ensemble de l’intervalle. Le budget d’erreurs restant est le temps de dépassement restant qui peut être toléré pendant l’intervalle en cours. Ceci après avoir soustrait du budget d’erreur total le temps de dépassement qui s’est déjà produit.
La figure suivante illustre les concepts de budget de réalisation et d’erreur pour un objectif avec un intervalle de 30 jours, des périodes d’une minute et un objectif de réalisation de 99 %. 30 jours comprennent 43 200 périodes d’une minute. 99 % de 43 200, c’est 42 768, donc 42 768 minutes par mois doivent être saines pour que le SLO soit atteint. Jusqu’à présent, dans l’intervalle actuel, 130 des périodes d’une minute n’étaient pas saines.
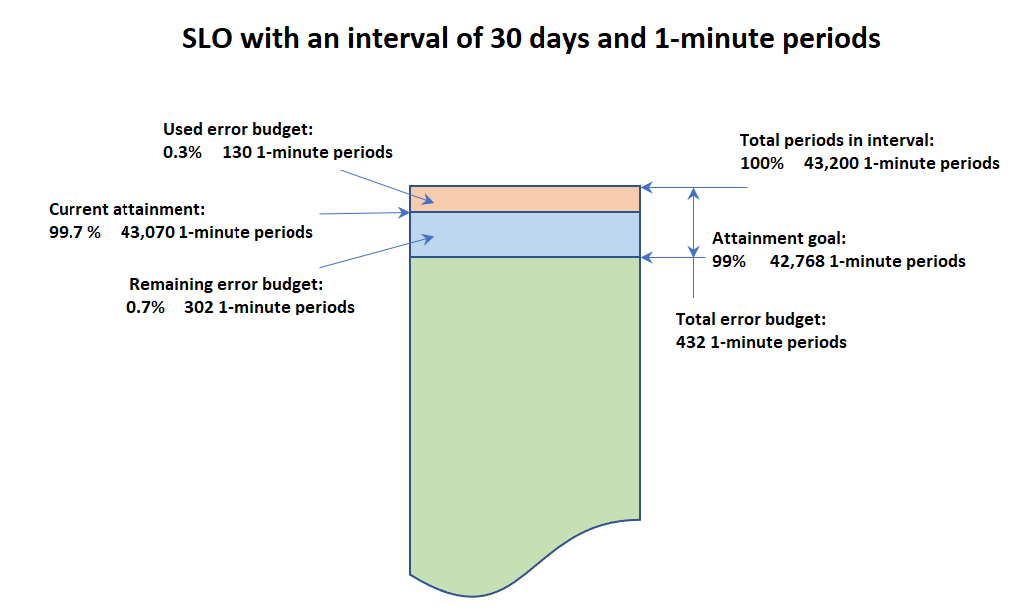
Détermination du succès au cours de chaque période
Au cours de chaque période, les données du SLI sont agrégées en un seul point de données sur la base des statistiques utilisées pour le SLI. Ce point de données représente la durée totale de la période. Ce point de données unique est comparé au seuil SLI pour déterminer si la période est saine. L’affichage sur le tableau de bord des périodes non saines pendant l’intervalle de temps en cours peut avertir vos opérateurs de services que le service doit être trié.
S’il est déterminé que la période n’est pas saine, la durée totale de la période est prise en compte comme un échec dans le calcul du budget d’erreur. Le suivi du budget d’erreurs vous permet de savoir si le service atteint les performances souhaitées sur une longue période.
Exclusions de fenêtres temporelles
Les exclusions de fenêtres temporelles correspondent à une période définie par des dates de début et de fin. Cette période est exclue des métriques de performance du SLO et vous pouvez planifier des fenêtres d’exclusions temporelles uniques ou récurrentes. Par exemple, la maintenance planifiée.
Note
Pour les SLO basés sur une période, les données SLI dans la fenêtre d’exclusion sont considérées comme non atteignables.
Pour les SLO basés sur les requêtes, toutes les requêtes bonnes et mauvaises dans la fenêtre d’exclusion sont exclues.
Lorsqu’un intervalle pour un SLO basé sur les requêtes est complètement exclu, une métrique de taux d’atteinte par défaut de 100 % est publiée.
Vous ne pouvez spécifier que des fenêtres temporelles dont la date de début se situe dans le futur.
Calculer le budget d’erreur et le taux d’atteinte pour les SLO basés sur les requêtes
Une fois que vous avez créé un SLO, vous pouvez récupérer des rapports sur le budget d’erreur. Un budget d’erreur correspond au nombre de requêtes pour lesquelles votre application peut ne pas être conforme à l’objectif du SLO, tout en atteignant l’objectif. Pour un SLO basé sur les requêtes, le budget d’erreur restant est dynamique et peut augmenter ou diminuer, en fonction du rapport entre les bonnes requêtes et le nombre total de requêtes
Le tableau suivant illustre le calcul pour un SLO basé sur les requêtes avec un intervalle de 5 jours et un objectif d’atteinte de 85 %. Dans cet exemple, nous supposons qu’il n’y a pas de trafic avant le jour 1. Le SLO n’a pas atteint l’objectif au jour 10.
Note
Pour les SLO basés sur les demandes, TotalRequestCountPerMinute et BadRequestCountPerMinute sont émis sous forme de métriques supplémentaires par rapport aux métriques SLO basées sur les périodes. Ces mesures sont fournies à des fins d'observabilité et ne sont pas utilisées comme entrées pour les calculs du taux de réussite.
Étant donné que ces mesures sont générées à partir de données métriques évaluées périodiquement, leurs valeurs peuvent parfois différer du nombre de demandes attendu en raison du calendrier ou des retards de publication des métriques. De tels écarts n'ont aucune incidence sur les calculs d'atteinte du SLO, qui sont calculés indépendamment de ces métriques émises par minute.
| Heure | Total requests (Nombre total de requêtes) | Requêtes erronées | Total cumulé des requêtes au cours des 5 derniers jours | Total cumulé des bonnes requêtes au cours des 5 derniers jours | Request-based réalisation | Total des requêtes de budget | Requêtes de budget restantes |
|---|---|---|---|---|---|---|---|
|
Jour 1 |
10 | 1 |
10 |
9 |
9/10 = 90 % |
1.5 |
0.5 |
|
Jour 2 |
5 |
1 |
15 |
13 |
13/15= 86 % |
2.3 |
0.3 |
|
Jour 3 |
1 |
1 |
16 |
13 |
13/16= 81 % |
2,4 |
-0,6 |
|
Jour 4 |
24 |
0 |
40 |
37 |
37/40= 92 % |
6.0 |
3.0 |
|
Jour 5 |
20 |
5 |
60 |
52 |
52/60= 87 % |
9.0 |
1.0 |
|
Jour 6 |
6 |
2 |
56 |
47 |
47/56= 84 % |
8,4 |
-0,6 |
|
Jour 7 |
10 |
3 |
61 |
50 |
50/61= 82 % |
9,2 |
-1,8 |
|
Jour 8 |
15 |
6 |
75 |
59 |
59/75= 79 % |
11,3 |
-4,7 |
| Jour 9 |
12 |
1 |
63 |
46 |
46/63= 73 % |
9,5 |
-7,5 |
|
Jour 10 |
5 |
57 |
40 |
40/57= 70 % |
8,5 |
-8,5 | |
|
Atteinte finale pour les 5 derniers jours |
|
70 % |
Calculer les taux de consommation et définir éventuellement des alarmes de taux de consommation
Vous pouvez utiliser la vigie applicative pour calculer les taux de consommation de vos objectifs de niveau de service. Un taux de consommation est une métrique qui indique la vitesse à laquelle le service consomme le budget d’erreur, par rapport à l’objectif d’atteinte du SLO. Ce taux est exprimé comme un facteur multiple du taux d’erreur de base.
Le taux de consommation est calculé en fonction du taux d’erreur de base, qui dépend de l’objectif d’atteinte. L’objectif d’atteinte est le pourcentage de périodes saines ou de requêtes réussies qui doit être atteint pour réaliser l’objectif du SLO. Le taux d’erreur de référence est égal à (100 % – pourcentage de l’objectif à atteindre), et ce chiffre utiliserait exactement le budget d’erreur complet à la fin de l’intervalle de temps du SLO. Ainsi, un SLO dont l’objectif d’atteinte est de 99 % aurait un taux d’erreur de base de 1 %.
Le suivi du taux de consommation nous indique à quel point nous nous éloignons du taux d’erreur de référence. Si l’on reprend l’exemple d’un objectif d’atteinte de 99 %, la règle suivante s’applique :
Taux de consommation = 1 : si le taux de consommation reste en permanence au niveau du taux d’erreur de base, nous atteignons exactement l’objectif du SLO.
Taux de consommation < 1 : si le taux de consommation est inférieur au taux d’erreur de base, nous sommes sur la bonne voie pour dépasser l’objectif du SLO.
Taux de consommation > 1 : si le taux de consommation est supérieur au taux d’erreur de base, nous risquons de ne pas atteindre l’objectif du SLO.
Lorsque vous créez des taux de combustion pour vos SLO, vous pouvez également choisir de créer des CloudWatch alarmes en même temps pour surveiller les taux de combustion. Vous pouvez définir un seuil pour les taux de consommation et les alarmes peuvent vous avertir automatiquement si les métriques du taux de consommation dépassent le seuil que vous avez défini. Par exemple, un taux de consommation proche de son seuil peut vous indiquer que le SLO consomme le budget d’erreur plus rapidement que votre équipe ne peut le tolérer et que votre équipe peut avoir besoin de ralentir la consommation dans l’application pour s’assurer que les objectifs de performance à long terme sont atteints.
La création d’alarmes entraîne des frais. Pour plus d'informations sur CloudWatch les tarifs, consultez Amazon CloudWatch Pricing
Calculer le taux de consommation
Pour calculer le taux de consommation, vous devez spécifier une fenêtre d’observation rétrospective. Cette fenêtre correspond à la durée pendant laquelle le taux d’erreur est mesuré.
burn rate = error rate over the look-back window / (100% - attainment goal)
Note
Lorsqu’il n’y a pas de données pour la période de consommation, la vigie applicative calcule le taux de consommation sur la base de l’atteinte.
Le taux d’erreur est calculé comme le rapport du nombre de mauvais événements sur le nombre total d’événements pendant la fenêtre de taux de consommation :
Pour les SLO basés sur une période, le taux d’erreur est calculé comme les mauvaises périodes divisées par le nombre total de périodes. Le nombre total de périodes représente la totalité des périodes comprises dans fenêtre d’observation rétrospective.
Pour les SLO basés sur les requêtes, il s’agit d’une mesure des mauvaises requêtes divisées par le nombre total de requêtes. Le nombre total de requêtes est le nombre de requêtes pendant la fenêtre d’observation rétrospective.
Cette fenêtre doit être un multiple de la durée de la période du SLO et doit être inférieure à l’intervalle du SLO.
Déterminer le seuil approprié pour une alarme de taux de consommation
Lorsque vous configurez une alarme de taux de consommation, vous devez choisir une valeur du taux de consommation comme seuil d’alarme. La valeur de ce seuil dépend de la durée de l’intervalle du SLO et de la fenêtre d’observation rétrospective, ainsi que de la méthode ou du modèle de raisonnement que votre équipe veut adopter. Il existe deux méthodes principales pour déterminer le seuil.
Méthode 1 : déterminez le pourcentage du budget d’erreur total estimé que votre équipe est prête à utiliser dans la fenêtre d’observation rétrospective.
Si vous voulez être alerté lorsque X % du budget d’erreur estimé est dépensé au cours des dernières heures d’observation rétrospective du taux de consommation, le seuil du taux de consommation est le suivant :
burn rate threshold = X% * SLO interval length / look-back window size
Par exemple, 5 % d’un budget d’erreur de 30 jours (720 heures) dépensés en une heure nécessitent un taux de consommation de 5% * 720 / 1 = 36. Par conséquent, si la fenêtre d’observation rétrospective du taux de consommation est de 1 heure, nous fixons le seuil du taux de consommation à 36.
Vous pouvez utiliser la CloudWatch console pour créer des alarmes de taux de combustion à l'aide de cette méthode. Vous pouvez spécifier le nombre X, et le seuil est déterminé à l’aide de la formule ci-dessus.
La durée de l’intervalle du SLO est déterminée en fonction du type d’intervalle du SLO :
Pour les SLO avec un intervalle continu, il s'agit de la durée de l'intervalle en heures.
Pour les SLO avec un intervalle basé sur le calendrier :
Si l'unité est le jour ou la semaine, il s'agit de la durée de l'intervalle en heures.
Si l’unité est en mois, nous prenons 30 jours comme durée estimée et la convertissons en heures.
Méthode 2 : déterminer le temps restant jusqu’à épuisement du budget pour l’intervalle suivant
Pour que l’alarme vous avertisse lorsque le taux d’erreur actuel dans la fenêtre d’observation rétrospective la plus récente indique qu’il reste moins de X heures avant l’épuisement du budget (en supposant que le budget restant est actuellement de 100 %), vous pouvez utiliser la formule suivante pour déterminer le seuil du taux de consommation.
burn rate threshold = SLO interval length / X
Nous insistons sur le fait que le temps restant jusqu’à épuisement du budget (X) dans la formule ci-dessus suppose que le budget total restant est actuellement de 100 %, et ne prend donc pas en compte le montant du budget qui a déjà été dépensé dans cet intervalle. Nous pouvons également considérer qu’il s’agit du temps restant jusqu’à épuisement du budget pour l’intervalle suivant.
Démonstrations pour les alarmes de taux de consommation
Prenons l’exemple d’un SLO dont l’intervalle continu est de 28 jours. La définition d’une alarme de taux de consommation pour ce SLO se fait en deux étapes :
Définir le taux de consommation et la fenêtre d’observation rétrospective.
Créez une CloudWatch alarme qui surveille le taux de combustion.
Pour commencer, déterminez la part du budget d’erreur total que le service est prêt à dépenser dans un délai spécifique. En d’autres termes, énoncez votre objectif en utilisant la phrase suivante : « Je veux être alerté lorsque X % de mon budget d’erreur total est consommé dans un délai de M minutes. »
Par exemple, vous pourriez vouloir fixer l’objectif de manière à être alerté lorsque 2 % du budget d’erreur total est consommé en 60 minutes.
Pour définir le taux de consommation, vous devez d’abord définir la fenêtre d’observation rétrospective. La fenêtre d’observation rétrospective est M, soit, dans cet exemple, 60 minutes.
Ensuite, vous créez l' CloudWatch alarme. Lors de la création, vous devez spécifier un seuil pour le taux de consommation. Si le taux de consommation dépasse ce seuil, l’alarme vous en informera. Pour trouver le seuil, utilisez la formule suivante :
burn rate threshold = X% * SLO interval length/ look-back window size
Dans cet exemple, X est égal à 2, car nous voulons être alertés si 2 % du budget d’erreur est consommé en 60 minutes. La durée de l’intervalle est de 40 320 minutes (28 jours) et 60 minutes correspond à la fenêtre d’observation rétrospective :
burn rate threshold = 2% * 40,320 / 60 = 13.44.
Dans cet exemple, vous devez définir 13,44 comme seuil d’alarme.
Alarmes multiples avec des fenêtres différentes
En définissant des alarmes sur plusieurs fenêtres d’observation rétrospectives, vous pouvez détecter rapidement les fortes augmentations du taux d’erreur avec la fenêtre courte et, en même temps, détecter les augmentations plus faibles du taux d’erreur qui finissent par épuiser le budget d’erreur si elles restent inaperçues.
En outre, vous pouvez régler une alarme composite sur une vitesse de combustion avec une fenêtre longue et sur une vitesse de combustion avec une fenêtre courte (1/12th de la fenêtre longue), et être informé uniquement lorsque les deux taux de combustion dépassent un seuil. De cette façon, vous pouvez vous assurer que vous n’êtes alerté que pour des situations qui sont encore en cours. Pour plus d'informations sur les alarmes composites dans CloudWatch, consultezCréation d’une alerte composite.
Note
Vous pouvez définir une alarme métrique sur un taux de consommation lorsque vous créez ce dernier. Pour définir une alarme composite sur plusieurs alarmes de taux de consommation, vous devez utiliser les instructions de Création d’une alerte composite.
Une stratégie d’alarme composite recommandée dans le manuel Google Site Reliability Engineering
Une alarme composite qui surveille une paire d’alarmes, l’une avec une fenêtre d’une heure et l’autre avec une fenêtre de cinq minutes.
Une deuxième alarme composite qui surveille une paire d’alarmes, l’une avec une fenêtre de six heures et l’autre avec une fenêtre de 30 minutes.
Une troisième alarme composite qui surveille une paire d’alarmes, l’une avec une fenêtre de trois jours et l’autre avec une fenêtre de six heures.
Les étapes de cette configuration sont les suivantes :
-
Créez cinq taux de consommation, avec des fenêtres de cinq minutes, 30 minutes, une heure, six heures et trois jours.
Créez les trois paires d' CloudWatch alarmes suivantes. Chaque paire comprend une fenêtre longue et une fenêtre courte appartenant à 1/12th la fenêtre longue, et les seuils sont déterminés à l'aide des étapesDéterminer le seuil approprié pour une alarme de taux de consommation. Lorsque vous calculez le seuil pour chaque alarme de la paire, utilisez la fenêtre d’observation rétrospective la plus longue de la paire dans votre calcul.
Alarmes sur les taux de consommation de 1 heure et de 5 minutes (le seuil est déterminé par 2 % du budget total)
Alarmes sur les taux de consommation de 6 heures et de 30 minutes (le seuil est déterminé par 5 % du budget total)
Alarmes sur les taux de consommation de 3 jours et de 6 heures (le seuil est déterminé par 10 % du budget total)
Pour chacune de ces paires, créez une alarme composite qui vous alertera lorsque les deux alarmes passeront à l’état ALARME. Pour plus d’informations sur la création d’alarmes composites, consultez Création d’une alerte composite.
Par exemple, si vos alarmes pour la première paire (fenêtre d'une heure et fenêtre de cinq minutes) sont nommées
OneHourBurnRateetFiveMinuteBurnRateque la règle d'alarme CloudWatch composite seraitALARM(OneHourBurnRate) AND ALARM(FiveMinuteBurnRate)
La stratégie précédente n’est possible que pour les SLO dont la durée d’intervalle est d’au moins trois heures. Pour les SLO avec des intervalles plus courts, nous vous recommandons de commencer par une paire d'alarmes de taux de combustion, l'une des alarmes ayant une fenêtre rétrospective correspondant à la fenêtre 1/12th rétrospective de l'autre alarme. Définissez ensuite une alarme composite sur cette paire.
Création d’un SLO
Nous vous recommandons de définir des SLO de latence et de disponibilité pour vos applications critiques. Ces indicateurs collectés par Application Signals correspondent aux objectifs métier communs.
Vous pouvez également définir des SLO pour n'importe quelle CloudWatch métrique ou expression mathématique de métrique aboutissant à une seule série chronologique.
La première fois que vous créez un SLO dans votre compte, le rôle AWSServiceRoleForCloudWatchApplicationSignalslié au service est CloudWatch automatiquement créé dans votre compte, s'il n'existe pas déjà. Ce rôle lié à un service permet de CloudWatch collecter des données de CloudWatch journal, des données de X-Ray suivi, des données CloudWatch métriques et des données de balisage à partir des applications de votre compte. Pour plus d'informations sur les rôles CloudWatch liés à un service, consultez. Utilisation de rôles liés à un service pour CloudWatch
Lorsque vous créez un SLO, vous indiquez s’il s’agit d’un SLO basé sur une période ou d’un SLO basé sur les requêtes. Chaque type de SLO a une façon différente d’évaluer les performances de votre application par rapport à son objectif d’atteinte.
Un SLO basé sur une période utilise des périodes définies dans un intervalle de temps total spécifié. Pour chaque période, la vigie applicative détermine si l’application a atteint son objectif. Le taux d’atteinte est calculé comme suit :
number of good periods/number of total periods.Par exemple, pour un SLO basé sur une période, atteindre un objectif de 99,9 % signifie que dans votre intervalle, votre application doit atteindre son objectif de performance pendant au moins 99,9 % des périodes.
Un SLO basé sur les requêtes n’utilise pas de périodes prédéfinies. Au lieu de cela, le SLO mesure
number of good requests/number of total requestspendant l’intervalle. À tout moment, vous pouvez trouver le rapport entre les bonnes requêtes et le total des requêtes pour l’intervalle jusqu’à l’horodatage que vous avez spécifié, et comparer ce rapport à l’objectif défini dans votre SLO.
Rubriques
Créer un SLO basé sur une période
Utilisez la procédure suivante pour créer un SLO basé sur une période.
Pour créer un SLO basé sur une période
Ouvrez la CloudWatch console à l'adresse https://console.aws.amazon.com/cloudwatch/
. Dans le panneau de navigation, sélectionnez Objectifs de niveau de service (SLO).
Choisissez Créer un SLO.
Pour Définir un indicateur de niveau de service (SLI), procédez de l’une des manières suivantes :
Pour définir le SLO sur une opération de service, toutes les opérations ou la dépendance d'un service, en utilisant l'une des métriques d'application standard
LatencyouAvailability:Dans Type, choisissez Service.
Sélectionnez un compte que ce SLO contrôlera.
Sélectionnez le service que ce SLO surveillera.
Pour Type, sélectionnez l'une des options suivantes :
Opérations de service : pour créer un SLO sur une opération de service, toutes les opérations ou un sous-ensemble d'opérations.
Dépendance du service : pour créer un SLO sur une dépendance du service.
Si vous avez choisi Service Operations, sélectionnez l'opération que ce SLO surveillera. Pour créer un SLO de niveau de service qui surveille l'état général de votre service dans toutes les opérations, sélectionnez Toutes les opérations. Sinon, sélectionnez une opération spécifique à surveiller.
Pour créer un SLO qui surveille un sous-ensemble d'opérations, voirCréation d'un SLO composite sur plusieurs opérations.
Si vous avez choisi Service Dependency, procédez comme suit :
Sous Sélectionner une opération, sélectionnez une opération spécifique ou sélectionnez Toutes les opérations pour utiliser les métriques de toutes les opérations de ce service qui appelle une dépendance.
Sous Sélectionnez une dépendance, recherchez et sélectionnez la dépendance requise dont vous souhaitez mesurer la fiabilité.
Après avoir sélectionné la dépendance, vous pouvez afficher le graphique mis à jour et les données historiques basées sur la dépendance.
Pour Sélectionner une méthode de calcul, sélectionnez Périodes.
Les listes déroulantes Sélectionner un service et Sélectionner une opération contiennent les services et les opérations qui ont été actifs au cours des dernières 24 heures.
Choisissez Disponibilité ou Latence, puis définissez le seuil.
Pour définir le SLO sur une CloudWatch métrique ou une expression mathématique de CloudWatch métrique, procédez comme suit :
Dans Type, choisissez CloudWatch Metric.
Choisissez Sélectionner une CloudWatch métrique.
L’écran Sélectionner une métrique apparaît. Utilisez les onglets Parcourir ou Requête pour trouver la métrique souhaitée, ou créez une expression mathématique de métrique.
Après avoir sélectionné la métrique souhaitée, choisissez l’onglet Graphiques des métriques et sélectionnez la Statistique et la Période à utiliser pour le SLO. Ensuite, choisissez Select metric (Sélectionner une métrique).
Pour plus d’informations sur ces écrans, veuillez consulter Représenter graphiquement une métrique et Ajouter une expression mathématique à un CloudWatch graphique.
Pour Sélectionner une méthode de calcul, sélectionnez Périodes.
Pour Définir la condition, sélectionnez un opérateur de comparaison et un seuil que le SLO utilisera comme indicateur de réussite.
Si vous avez sélectionné Service à l'étape 4, définissez la durée de cette SLO.
Saisissez un nom pour le SLO. L’inclusion du nom d’un service ou d’une opération, ainsi que des mots clés appropriés tels que la latence ou la disponibilité, vous aidera à identifier rapidement ce que l’état du SLO indique lors du triage.
Définissez l’intervalle et l’objectif de réalisation pour le SLO. Pour plus d’informations sur les intervalles et les objectifs de réalisation et la manière dont ils fonctionnent ensemble, veuillez consulter.la rubrique Concepts SLO.
(Facultatif) Pour Définir les taux de consommation du SLO, procédez comme suit :
Définissez la durée (en minutes) de la fenêtre d’observation rétrospective du taux de consommation. Pour plus d’informations sur le choix de cette durée, consultez Démonstrations pour les alarmes de taux de consommation.
Pour créer d’autres taux de consommation pour ce SLO, sélectionnez Ajouter d’autres taux de consommation et définissez la fenêtre d’observation rétrospective pour les taux de consommation supplémentaires.
(Facultatif) Créez des alarmes de taux de consommation en procédant comme suit :
Sous Définir des alarmes de taux de consommation, cochez la case de chaque taux de consommation pour lequel vous voulez créer une alarme. Pour chacune de ces alarmes, procédez comme suit :
Spécifiez la rubrique Amazon SNS à utiliser pour les notifications lorsque l’alarme passe à l’état ALARME.
Définissez un seuil de taux de consommation ou indiquez le pourcentage du budget total estimé consommé dans la dernière fenêtre d’observation rétrospective que vous voulez rester en dessous. Si vous définissez le pourcentage du budget total estimé consommé, le seuil de taux de consommation est calculé pour vous et utilisé dans l’alarme. Pour décider du seuil à fixer ou pour comprendre comment cette option est utilisée pour calculer le seuil du taux de consommation, consultez Déterminer le seuil approprié pour une alarme de taux de consommation.
(Facultatif) Définissez une ou plusieurs CloudWatch alarmes ou un seuil d'avertissement pour le SLO.
CloudWatch les alarmes peuvent utiliser Amazon SNS pour vous avertir de manière proactive si une application est défectueuse en fonction de ses performances SLI.
Pour créer une alarme, cochez l’une des cases d’alarme et saisissez ou créez la rubrique Amazon SNS à utiliser pour les notifications lorsque l’alarme passe à l’état
ALARM. Pour plus d'informations sur les CloudWatch alarmes, consultezUtilisation des CloudWatch alarmes Amazon. La création d’alarmes entraîne des frais. Pour plus d'informations sur CloudWatch les tarifs, consultez Amazon CloudWatch Pricing. Si vous définissez un seuil d’avertissement, celui-ci apparaît dans les écrans d’Application Signals pour vous aider à identifier les SLO qui risquent de ne pas être atteints, même s’ils sont actuellement sains.
Pour définir un seuil d’avertissement, saisissez la valeur du seuil dans Seuil d’avertissement. Lorsque le budget d’erreur du SLO est inférieur au seuil d’avertissement, le SLO est marqué d’un Avertissement sur plusieurs écrans d’Application Signals. Les seuils d’avertissement apparaissent également sur les graphiques du budget d’erreur. Vous pouvez également créer une Alarme d’avertissement SLO basée sur le seuil d’avertissement.
(Facultatif) Pour définir l’exclusion de la fenêtre temporelle du SLO, procédez comme suit :
Sous Exclure une fenêtre temporelle, définissez la fenêtre temporelle à exclure des métriques de performance du SLO.
Vous pouvez choisir Définir la fenêtre temporelle et entrer la Fenêtre de démarrage pour chaque heure ou chaque mois ou vous pouvez choisir Définir la fenêtre temporelle avec CRON et entrer l’expression CRON.
Sous Répéter, définissez si l’exclusion de la fenêtre temporelle est récurrente ou non.
(Facultatif) Sous Ajouter une raison, vous pouvez choisir de saisir une raison pour l’exclusion de la fenêtre temporelle. Par exemple, la maintenance planifiée.
Sélectionnez Ajouter une fenêtre temporelle pour ajouter jusqu’à 10 fenêtres d’exclusion temporelle.
Pour ajouter des tags à ce SLO, choisissez l’onglet Balises, puis choisissez Ajouter une nouvelle balise. Les balises peuvent vous aider à gérer, identifier, organiser, rechercher et filtrer des ressources. Pour plus d’informations sur le balisage, veuillez consulter la rubrique Tagging your AWS resources.
Note
Si l'application à laquelle cette SLO est associée est enregistrée AWS Service Catalog AppRegistry, vous pouvez utiliser la
awsApplicationbalise pour associer cette SLO à cette application AppRegistry. Pour plus d'informations, voir Qu'est-ce que c'est AppRegistry ?Choisissez Créer un SLO. Si vous avez également choisi de créer une ou plusieurs alarmes, le nom du bouton change en conséquence.
Créer un SLO basé sur les requêtes
Suivez la procédure suivante pour créer un SLO basé sur les requêtes.
Pour créer un SLO basé sur les requêtes
Ouvrez la CloudWatch console à l'adresse https://console.aws.amazon.com/cloudwatch/
. Dans le panneau de navigation, sélectionnez Objectifs de niveau de service (SLO).
Choisissez Créer un SLO.
Pour Définir un indicateur de niveau de service (SLI), procédez de l’une des manières suivantes :
Pour définir le SLO sur une opération de service, toutes les opérations ou la dépendance d'un service, en utilisant l'une des métriques d'application standard
LatencyouAvailability:Dans Type, choisissez Service.
Sélectionnez le service que ce SLO surveillera.
Pour Type, sélectionnez l'une des options suivantes :
Opérations de service : pour créer un SLO sur une opération de service, toutes les opérations ou un sous-ensemble d'opérations.
Dépendance du service : pour créer un SLO sur une dépendance du service.
Si vous avez choisi Service Operations, sélectionnez l'opération que ce SLO surveillera. Pour créer un SLO de niveau de service qui surveille l'état général de votre service dans toutes les opérations, sélectionnez Toutes les opérations. Sinon, sélectionnez une opération spécifique à surveiller.
Pour créer un SLO qui surveille un sous-ensemble d'opérations, voirCréation d'un SLO composite sur plusieurs opérations.
Si vous avez choisi Service Dependency, procédez comme suit :
Sous Sélectionner une opération, sélectionnez une opération spécifique ou sélectionnez Toutes les opérations pour utiliser les métriques de toutes les opérations de ce service qui appelle une dépendance.
Sous Sélectionnez une dépendance, recherchez et sélectionnez la dépendance requise dont vous souhaitez mesurer la fiabilité.
Après avoir sélectionné la dépendance, vous pouvez afficher le graphique mis à jour et les données historiques basées sur la dépendance.
Pour Sélectionner une méthode de calcul, sélectionnez Requêtes.
-
Les listes déroulantes Sélectionner un service et Sélectionner une opération contiennent les services et les opérations qui ont été actifs au cours des dernières 24 heures.
Choisissez Disponibilité ou Latence. Si vous choisissez Latence, définissez le seuil.
Pour définir le SLO sur une CloudWatch métrique ou une expression mathématique de CloudWatch métrique, procédez comme suit :
Dans Type, choisissez CloudWatch Metric.
-
Pour Définir les requêtes cibles, procédez comme suit :
Choisissez si vous voulez mesurer les bonnes requêtes ou les mauvaises requêtes.
-
Choisissez Sélectionner une CloudWatch métrique. Cette métrique sera le numérateur du rapport entre les requêtes cibles et les requêtes totales. Si vous utilisez une métrique de latence, utilisez les statistiques du nombre ajusté (TC). Si le seuil est de 9 ms et que vous utilisez l’opérateur de comparaison moins que (<), utilisez le seuil TC (:threshold - 1). Pour plus d’informations sur le TC, consultez Syntaxe.
L’écran Sélectionner une métrique apparaît. Utilisez les onglets Parcourir ou Requête pour trouver la métrique souhaitée, ou créez une expression mathématique de métrique.
-
Pour Définir le nombre total de demandes, choisissez la CloudWatch métrique que vous souhaitez utiliser pour la source. Cette métrique sera le dénominateur du rapport entre les requêtes de la cible et les requêtes totales.
L’écran Sélectionner une métrique apparaît. Utilisez les onglets Parcourir ou Requête pour trouver la métrique souhaitée, ou créez une expression mathématique de métrique.
Après avoir sélectionné la métrique souhaitée, choisissez l’onglet Graphiques des métriques et sélectionnez la Statistique et la Période à utiliser pour le SLO. Ensuite, choisissez Select metric (Sélectionner une métrique).
Si vous utilisez une métrique de latence qui émet un point de données par requête, utilisez les Statistiques de comptage d’échantillons pour compter le nombre de requêtes totales.
Pour plus d’informations sur ces écrans, veuillez consulter Représenter graphiquement une métrique et Ajouter une expression mathématique à un CloudWatch graphique.
Saisissez un nom pour le SLO. L’inclusion du nom d’un service ou d’une opération, ainsi que des mots clés appropriés tels que la latence ou la disponibilité, vous aidera à identifier rapidement ce que l’état du SLO indique lors du triage.
Définissez l’intervalle et l’objectif de réalisation pour le SLO. Pour plus d’informations sur les intervalles et les objectifs de réalisation et la manière dont ils fonctionnent ensemble, veuillez consulter.la rubrique Concepts SLO.
(Facultatif) Pour Définir les taux de consommation du SLO, procédez comme suit :
Définissez la durée (en minutes) de la fenêtre d’observation rétrospective du taux de consommation. Pour plus d’informations sur le choix de cette durée, consultez Démonstrations pour les alarmes de taux de consommation.
Pour créer d’autres taux de consommation pour ce SLO, sélectionnez Ajouter d’autres taux de consommation et définissez la fenêtre d’observation rétrospective pour les taux de consommation supplémentaires.
(Facultatif) Créez des alarmes de taux de consommation en procédant comme suit :
Sous Définir des alarmes de taux de consommation, cochez la case de chaque taux de consommation pour lequel vous voulez créer une alarme. Pour chacune de ces alarmes, procédez comme suit :
Spécifiez la rubrique Amazon SNS à utiliser pour les notifications lorsque l’alarme passe à l’état ALARME.
Définissez un seuil de taux de consommation ou indiquez le pourcentage du budget total estimé consommé dans la dernière fenêtre d’observation rétrospective que vous voulez rester en dessous. Si vous définissez le pourcentage du budget total estimé consommé, le seuil de taux de consommation est calculé pour vous et utilisé dans l’alarme. Pour décider du seuil à fixer ou pour comprendre comment cette option est utilisée pour calculer le seuil du taux de consommation, consultez Déterminer le seuil approprié pour une alarme de taux de consommation.
(Facultatif) Définissez une ou plusieurs CloudWatch alarmes ou un seuil d'avertissement pour le SLO.
CloudWatch les alarmes peuvent utiliser Amazon SNS pour vous avertir de manière proactive si une application est défectueuse en fonction de ses performances SLI.
Pour créer une alarme, cochez l’une des cases d’alarme et saisissez ou créez la rubrique Amazon SNS à utiliser pour les notifications lorsque l’alarme passe à l’état
ALARM. Pour plus d'informations sur les CloudWatch alarmes, consultezUtilisation des CloudWatch alarmes Amazon. La création d’alarmes entraîne des frais. Pour plus d'informations sur CloudWatch les tarifs, consultez Amazon CloudWatch Pricing. Si vous définissez un seuil d’avertissement, celui-ci apparaît dans les écrans d’Application Signals pour vous aider à identifier les SLO qui risquent de ne pas être atteints, même s’ils sont actuellement sains.
Pour définir un seuil d’avertissement, saisissez la valeur du seuil dans Seuil d’avertissement. Lorsque le budget d’erreur du SLO est inférieur au seuil d’avertissement, le SLO est marqué d’un Avertissement sur plusieurs écrans d’Application Signals. Les seuils d’avertissement apparaissent également sur les graphiques du budget d’erreur. Vous pouvez également créer une Alarme d’avertissement SLO basée sur le seuil d’avertissement.
(Facultatif) Pour définir l’exclusion de la fenêtre temporelle du SLO, procédez comme suit :
Sous Exclure une fenêtre temporelle, définissez la fenêtre temporelle à exclure des métriques de performance du SLO.
Vous pouvez choisir Définir la fenêtre temporelle et entrer la Fenêtre de démarrage pour chaque heure ou chaque mois ou vous pouvez choisir Définir la fenêtre temporelle avec CRON et entrer l’expression CRON.
Sous Répéter, définissez si l’exclusion de la fenêtre temporelle est récurrente ou non.
(Facultatif) Sous Ajouter une raison, vous pouvez choisir de saisir une raison pour l’exclusion de la fenêtre temporelle. Par exemple, la maintenance planifiée.
Sélectionnez Ajouter une fenêtre temporelle pour ajouter jusqu’à 10 fenêtres d’exclusion temporelle.
Pour ajouter des tags à ce SLO, choisissez l’onglet Balises, puis choisissez Ajouter une nouvelle balise. Les balises peuvent vous aider à gérer, identifier, organiser, rechercher et filtrer des ressources. Pour plus d’informations sur le balisage, veuillez consulter la rubrique Tagging your AWS resources.
Note
Si l'application à laquelle cette SLO est associée est enregistrée AWS Service Catalog AppRegistry, vous pouvez utiliser la
awsApplicationbalise pour associer cette SLO à cette application AppRegistry. Pour plus d'informations, voir Qu'est-ce que c'est AppRegistry ?Choisissez Créer un SLO. Si vous avez également choisi de créer une ou plusieurs alarmes, le nom du bouton change en conséquence.
Création d'un SLO sur le moniteur d'une application
Vous pouvez créer des SLO pour surveiller les performances de vos moniteurs d'applications CloudWatch RUM. Cela vous permet de suivre les indicateurs réels de l'expérience utilisateur et de vous assurer que vos applications Web et mobiles atteignent leurs objectifs de performance. Les SLO sur les moniteurs d'applications utilisent une évaluation basée sur les demandes, qui mesure le ratio entre les bonnes demandes et le nombre total de demandes.
Pour créer un SLO sur le moniteur d'une application
Ouvrez la CloudWatch console à l'adresse https://console.aws.amazon.com/cloudwatch/
. Dans le panneau de navigation, sélectionnez Objectifs de niveau de service (SLO).
Choisissez Créer un SLO.
Pour Définir l'indicateur de niveau de service (SLI), choisissez RUM AppMonitor.
Sélectionnez le moniteur d'application que ce SLO surveillera dans la liste déroulante. La liste indique le nom du moniteur de l'application ainsi que la plate-forme prise en charge (Web, iOS ou Android).
(Facultatif) Sélectionnez une page ou un écran spécifique à surveiller. Si vous ne sélectionnez aucune page, le SLO surveillera toutes les pages pour le moniteur de l'application.
Pour Sélectionner une métrique, choisissez la métrique à utiliser pour le SLI. Les métriques disponibles dépendent de la plateforme :
Pour les applications Web :
PerformanceNavigationDurationJSErrorCount,Http4xxCount, etHttp5xxCountPour les applications mobiles (iOS et Android) :
ScreenLoadTimeCrashCount,Http4xxCount, etHttp5xxCount
Pour Définir la condition, sélectionnez un opérateur de comparaison et un seuil que le SLO utilisera comme indicateur de réussite.
Saisissez un nom pour le SLO. L'inclusion du nom du moniteur de l'application et des mots clés appropriés vous aidera à identifier rapidement ce que l'état du SLO indique lors du triage.
Définissez l’intervalle et l’objectif de réalisation pour le SLO. Pour de plus amples informations, veuillez consulter Concepts SLO.
(Facultatif) Configurez les taux de combustion et les alarmes selon vos besoins. Pour de plus amples informations, veuillez consulter Calculer les taux de consommation et définir éventuellement des alarmes de taux de consommation.
(Facultatif) Définissez des exclusions de créneaux horaires si nécessaire.
(Facultatif) Ajoutez des balises pour aider à organiser et à identifier ce SLO.
Choisissez Créer un SLO.
Création d'un SLO sur un canari
Vous pouvez créer des SLO pour surveiller les performances de vos canaris CloudWatch Synthetics. Cela vous permet de suivre les résultats de surveillance synthétiques et de vous assurer que vos terminaux et vos API répondent aux objectifs de disponibilité et de performance. Les SLO sur les canaris utilisent une évaluation basée sur les périodes, où chaque course à canaris est traitée comme une période d'évaluation distincte.
Pour créer un SLO sur un canari
Ouvrez la CloudWatch console à l'adresse https://console.aws.amazon.com/cloudwatch/
. Dans le panneau de navigation, sélectionnez Objectifs de niveau de service (SLO).
Choisissez Créer un SLO.
Pour Set Service Level Indicator (SLI), choisissez Synthetics Canary.
Sélectionnez le canari que ce SLO surveillera dans la liste déroulante.
Pour Sélectionner une métrique, choisissez l'une
SuccessPercentdes optionsDurationsuivantes :SuccessPercentmesure le pourcentage de courses réussies dans les canarisDurationmesure le temps nécessaire à la réalisation de chaque course à canaris
Pour Définir la condition, sélectionnez un opérateur de comparaison et un seuil que le SLO utilisera comme indicateur de réussite.
Saisissez un nom pour le SLO. L'inclusion du nom du canari et des mots clés appropriés vous aidera à identifier rapidement ce que le statut du SLO indique lors du triage.
Définissez l’intervalle et l’objectif de réalisation pour le SLO. Pour de plus amples informations, veuillez consulter Concepts SLO.
(Facultatif) Configurez les taux de combustion et les alarmes selon vos besoins. Pour de plus amples informations, veuillez consulter Calculer les taux de consommation et définir éventuellement des alarmes de taux de consommation.
(Facultatif) Définissez des exclusions de créneaux horaires si nécessaire.
(Facultatif) Ajoutez des balises pour aider à organiser et à identifier ce SLO.
Choisissez Créer un SLO.
Création d'un SLO composite sur plusieurs opérations
Vous pouvez créer un SLO composite qui surveille la Availability métrique sur un sous-ensemble d'opérations pour un service. Cela est utile lorsque vous souhaitez suivre ensemble la fiabilité d'un groupe d'opérations connexes, plutôt que de surveiller une seule opération ou toutes les opérations.
Les SLO composites prennent en charge les évaluations basées à la fois sur les périodes et sur les demandes. Vous pouvez sélectionner entre 2 et 20 opérations à inclure. Vous pouvez sélectionner les opérations de deux manières :
Sélection explicite : sélectionnez manuellement des opérations individuelles dans la liste déroulante.
Correspondance de modèles : utilisez un préfixe ou une expression régulière pour associer automatiquement les opérations par leur nom.
Note
Les SLO composites ne prennent en charge que la Availability métrique. La Latency métrique n'est pas disponible pour les SLO composites.
Pour créer un SLO composite
Ouvrez la CloudWatch console à l'adresse https://console.aws.amazon.com/cloudwatch/
. Dans le panneau de navigation, sélectionnez Objectifs de niveau de service (SLO).
Choisissez Créer un SLO.
Pour Set Service Level Indicator (SLI), pour Type, choisissez Service.
Sélectionnez le service que ce SLO surveillera.
Dans Type, sélectionnez Service Operations.
Sélectionnez les opérations à inclure dans ce SLO composite. Effectuez l’une des actions suivantes :
Pour sélectionner manuellement des opérations, sélectionnez plusieurs opérations dans le menu déroulant Opérations. Vous pouvez sélectionner entre 2 et 20 opérations.
Les opérations sélectionnées apparaissent sous forme de jetons sous la liste déroulante. Vous pouvez supprimer une opération en cliquant sur l'icône de rejet figurant sur son jeton.
Pour sélectionner les opérations par modèle, cochez la case Utiliser le modèle correspondant. Ensuite, procédez comme suit :
Pour le type de modèle, choisissez Préfixe ou Expression régulière.
Le préfixe correspond à toutes les opérations dont le nom commence par le texte que vous entrez. Par exemple, la saisie
Invokecorrespond aux opérations nomméesInvokeFunctionInvokeAsync,, etc.L'expression régulière correspond à toutes les opérations dont le nom correspond au modèle d'expression régulière que vous entrez. Par exemple, la saisie
^Invoke.*correspond aux mêmes opérations que l'exemple de préfixe.
Entrez le modèle dans le champ Motif. La console affiche les opérations correspondantes sous forme de jetons sous le champ afin que vous puissiez vérifier les résultats.
Une fois que vous avez sélectionné les opérations, la métrique est automatiquement définie sur Disponibilité.
Pour Sélectionner une méthode de calcul, sélectionnez Périodes ou Demandes.
Si vous avez sélectionné Périodes, définissez la durée de la période et le seuil de disponibilité pour ce SLO.
Entrez un nom pour le SLO ou utilisez le nom généré automatiquement. Le nom généré automatiquement inclut le nom du service et le mot « composite » pour vous aider à l'identifier.
Définissez l’intervalle et l’objectif de réalisation pour le SLO. Pour plus d’informations sur les intervalles et les objectifs de réalisation et la manière dont ils fonctionnent ensemble, veuillez consulter.la rubrique Concepts SLO.
(Facultatif) Configurez les taux de combustion et les alarmes selon vos besoins. Pour de plus amples informations, veuillez consulter Calculer les taux de consommation et définir éventuellement des alarmes de taux de consommation.
(Facultatif) Définissez une ou plusieurs CloudWatch alarmes ou un seuil d'avertissement pour le SLO.
(Facultatif) Définissez des exclusions de créneaux horaires si nécessaire.
(Facultatif) Ajoutez des balises pour aider à organiser et à identifier ce SLO.
Choisissez Créer un SLO.
Utiliser les recommandations du SLO
Application Signals peut fournir des recommandations pour la configuration de votre SLO en fonction des données métriques historiques des 30 derniers jours. Lorsque vous fournissez des informations de base sur votre service et le type de SLO que vous souhaitez créer, Application Signals analyse vos données métriques et suggère des valeurs optimales pour le seuil métrique, l'objectif SLO et les fenêtres de taux de combustion.
Pour recevoir les recommandations du SLO, vous devez fournir les informations suivantes :
Choisissez Service Operation ou Service Dependency :
Pour le fonctionnement du service, spécifiez le service et le fonctionnement
Pour Service Dependency, spécifiez le service, l'opération (ou toutes les opérations) et la dépendance
Le type d'évaluation du SLO : basé sur la période ou sur la demande
Type de métrique d'application standard :
LatencysoitAvailability
Sur la base de ces informations et des données de performance historiques de votre service, Application Signals recommande les paramètres de configuration SLO suivants :
Seuil métrique : seuil de performance de votre SLI, calculé en fonction des performances réelles de votre service au cours des 30 derniers jours.
Objectif SLO : pourcentage d'objectif d'atteinte suggéré qui correspond à la fiabilité historique de votre service.
Fenêtres à taux de combustion : durées de fenêtre rétrospectives recommandées pour surveiller la rapidité avec laquelle votre service consomme son budget d'erreurs.
Vous pouvez accepter les valeurs recommandées ou les ajuster en fonction des besoins spécifiques de votre entreprise. Les recommandations fournissent un point de départ basé sur les données pour configurer des SLO qui reflètent les caractéristiques de performance réelles de votre service.
Afficher et trier le statut du SLO
Vous pouvez rapidement vérifier l'état de vos SLO à l'aide des objectifs de niveau de service ou des options de services de la CloudWatch console. La vue Services fournit une vue d’ensemble du taux de services non sains, calculé en fonction des SLO que vous avez définis. Pour plus d’informations sur l’utilisation de l’option Services, veuillez consulter la rubrique Surveillez l’état de fonctionnement de vos applications avec Application Signals.
La vue des Objectifs de niveau de service fournit une vue macro de votre organisation. Vous pouvez voir les SLO atteints et non atteints dans leur ensemble. Cela vous donne une idée du nombre de vos services et opérations qui répondent à vos attentes sur de longues périodes, en fonction des SLI que vous avez choisis.
Pour afficher tous vos SLO à l’aide de la vue Objectifs de niveau de service
-
Ouvrez la CloudWatch console à l'adresse https://console.aws.amazon.com/cloudwatch/
. Dans le panneau de navigation, sélectionnez Objectifs de niveau de service (SLO).
La liste des Objectifs de niveau de service (SLO) apparaît.
Vous pouvez rapidement voir l’état actuel de vos SLO dans la colonne État des SLI. Pour trier les SLO de manière à ce que tous ceux qui ne sont pas sains figurent en haut de la liste, choisissez la colonne État des SLI jusqu’à ce que les SLO non sains apparaissent tous en haut de la liste.
La table SLO comporte les colonnes par défaut suivantes. Vous pouvez ajuster les colonnes affichées en choisissant l’icône représentant un engrenage au-dessus de la liste. Pour plus d’informations sur les objectifs, les SLI, les résultats atteints et les intervalles, veuillez consulter la rubrique Concepts SLO.
Le nom du SLO.
La colonne Objectif affiche le pourcentage de périodes pendant chaque intervalle qui doivent atteindre le seuil SLI pour que l’objectif SLO soit atteint. Elle affiche également la durée de l’intervalle pour le SLO.
État du SLI indique si l’état de fonctionnement actuel de l’application est sain ou non. Si une période quelconque de l’intervalle de temps sélectionné n’était pas saine pour le SLO, État du SLI indique Non sain.
Si ce SLO est configuré pour surveiller une dépendance, les colonnes Dépendance et Opération à distance afficheront les détails de cette relation de dépendance.
Le Niveau final est le niveau de réalisation atteint à la fin de l’intervalle de temps sélectionné. Triez selon cette colonne pour voir les SLO les plus susceptibles de ne pas être atteints.
Le Delta d’atteinte est la différence de niveau de réalisation entre le début et la fin de l’intervalle de temps sélectionné. Un delta négatif signifie que la métrique suit une tendance à la baisse. Triez selon cette colonne pour voir les dernières tendances des SLO.
Le budget d’erreur de fin (%) est le pourcentage du temps total de la période pendant laquelle il peut y avoir des périodes non saines tout en atteignant le SLO avec succès. Si vous définissez ce paramètre sur 5 % et que le SLI est défectueux pendant 5 % ou moins des périodes restantes de l’intervalle, le SLO est toujours atteint avec succès.
Le Delta du budget d’erreur est la différence du budget d’erreur entre le début et la fin de l’intervalle de temps sélectionné. Un delta négatif signifie que la métrique suit une tendance défavorable.
Le Budget d’erreur de fin (temps) est la durée réelle au sein de l’intervalle qui peut être non saine tout en permettant d’atteindre le SLO avec succès. Par exemple, si ce délai est de 14 minutes, si le SLI est non sain pendant moins de 14 minutes pendant l’intervalle restant, le SLO sera toujours atteint avec succès.
-
Le budget de fin d’erreur (requêtes) est la quantité de requêtes dans l’intervalle qui peuvent être malsaines tout en permettant au SLO d’être atteint avec succès. Pour les SLO basés sur les requêtes, cette valeur est dynamique et peut fluctuer en fonction du nombre total cumulé de requêtes.
Les colonnes Service, Opération et Type affichent des informations sur le service et l’opération pour lesquels ce SLO est configuré.
Pour afficher les graphiques du budget d’atteinte et d’erreur pour un SLO, choisissez la case d’option en regard du nom du SLO.
Les graphiques en haut de la page indiquent le degré de réalisation du SLO et l’état du budget d’erreur. Un graphique concernant la métrique SLI associée à ce SLO est également affiché.
Pour effectuer un tri plus approfondi d’un SLO qui n’atteint pas son objectif, choisissez le nom du service, le nom de l’opération ou le nom de la dépendance associé à ce SLO. Vous êtes redirigé vers la page de détails où vous pouvez effectuer un tri plus approfondi. Pour de plus amples informations, veuillez consulter Afficher l’activité détaillée du service et l’état opérationnel à l’aide de la page de détails du service.
Pour modifier la plage temporelle des graphiques et des tableaux de la page, choisissez un nouvel intervalle de temps en haut de l’écran.
Modification d’un SLO existant
Suivez ces étapes pour modifier un SLO existant. Lorsque vous modifiez un SLO, vous ne pouvez modifier que le seuil, l’intervalle, l’objectif de réalisation et les balises. Pour modifier d’autres aspects tels que le service, le fonctionnement ou les métriques, créez un SLO au lieu d’en modifier un existant.
La modification d’une partie de la configuration de base d’un SLO, telle que la période ou le seuil, invalide tous les points de données et évaluations précédents concernant les résultats et l’état de santé. En réalité, cela supprime et recrée le SLO.
Note
Si vous modifiez un SLO, les alarmes associées à ce SLO ne sont pas automatiquement mises à jour. Vous devrez peut-être mettre à jour les alarmes pour qu’elles restent synchronisées avec le SLO.
Pour modifier un SLO existant
-
Ouvrez la CloudWatch console à l'adresse https://console.aws.amazon.com/cloudwatch/
. Dans le panneau de navigation, sélectionnez Objectifs de niveau de service (SLO).
Choisissez la case d’option en regard du SLO que vous souhaitez modifier, puis choisissez Actions, Modifier le SLO.
Effectuez les modifications, puis choisissez Enregistrer les modifications.
Suppression d’un SLO
Suivez ces étapes pour supprimer un SLO existant.
Note
Si vous supprimez un SLO, les alarmes associées à ce SLO ne sont pas automatiquement supprimées. Vous devrez les supprimer vous-même. Pour de plus amples informations, veuillez consulter Gérer les alarmes.
Pour supprimer un SLO
-
Ouvrez la CloudWatch console à l'adresse https://console.aws.amazon.com/cloudwatch/
. Dans le panneau de navigation, sélectionnez Objectifs de niveau de service (SLO).
Choisissez la case d’option en regard du SLO que vous souhaitez modifier, puis choisissez Actions, Supprimer le SLO.
Choisissez Confirmer.
